 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Bayesian Active Learning Approach to Comparative Judgement
Aug 25, 2023
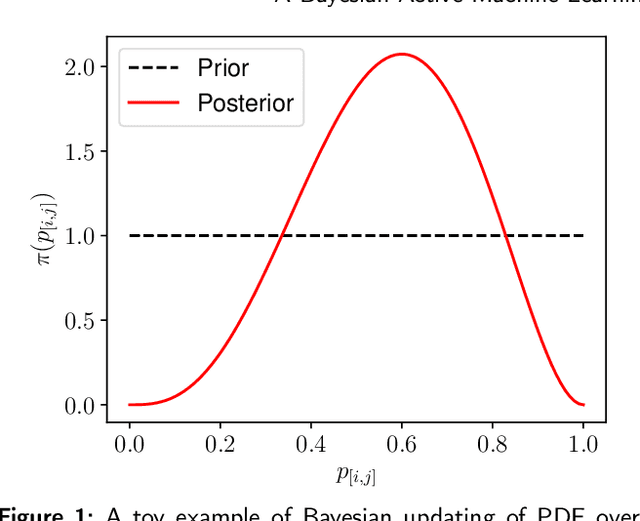
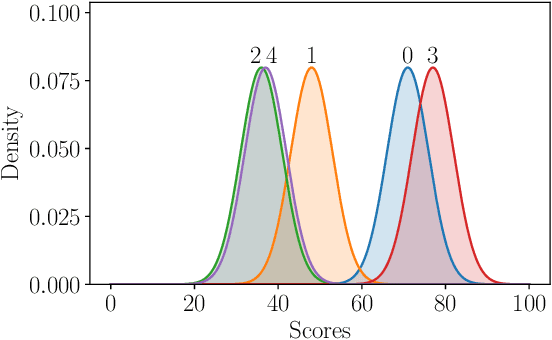
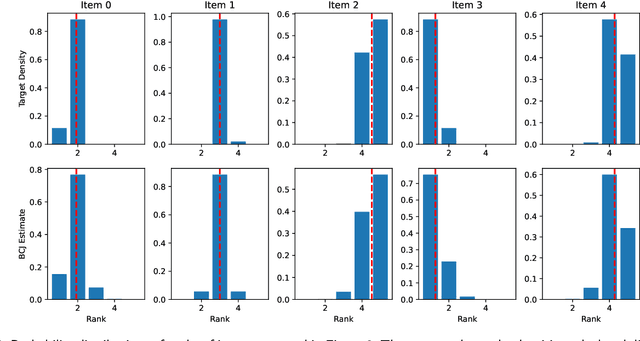
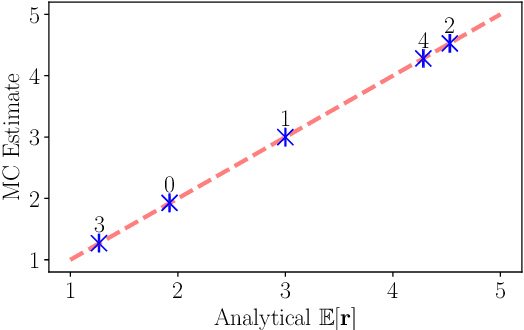
Assessment is a crucial part of education. Traditional marking is a source of inconsistencies and unconscious bias, placing a high cognitive load on the assessors. An approach to address these issues is comparative judgement (CJ). In CJ, the assessor is presented with a pair of items and is asked to select the better one. Following a series of comparisons, a rank is derived using a ranking model, for example, the BTM, based on the results. While CJ is considered a reliable method for marking, there are concerns around transparency, and the ideal number of pairwise comparisons to generate a reliable estimation of the rank order is not known. Additionally, there have been attempts to generate a method of selecting pairs that should be compared next in an informative manner, but some existing methods are known to have created their own bias within results inflating the reliability metric used. As a result, a random selection approach is usually deployed. We propose a novel Bayesian approach to CJ (BCJ) for determining the ranks of compared items alongside a new way to select the pairs to present to the marker(s) using active learning (AL), addressing the key shortcomings of traditional CJ. Furthermore, we demonstrate how the entire approach may provide transparency by providing the user insights into how it is making its decisions and, at the same time, being more efficient. Results from our experiments confirm that the proposed BCJ combined with entropy-driven AL pair-selection method is superior to other alternatives. We also find that the more comparisons done, the more accurate BCJ becomes, which solves the issue the current method has of the model deteriorating if too many comparisons are performed. As our approach can generate the complete predicted rank distribution for an item, we also show how this can be utilised in devising a predicted grade, guided by the assessor.
Revisiting and Exploring Efficient Fast Adversarial Training via LAW: Lipschitz Regularization and Auto Weight Averaging
Aug 22, 2023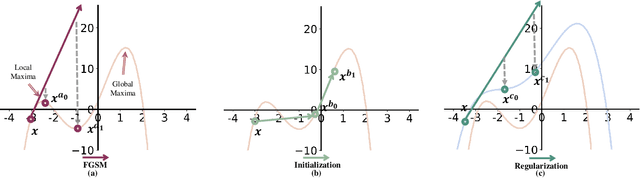
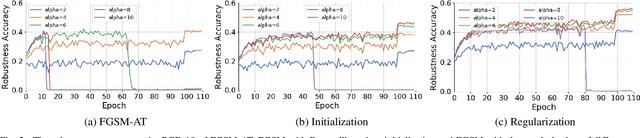
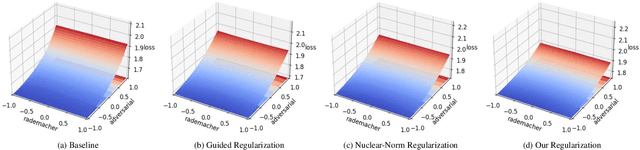
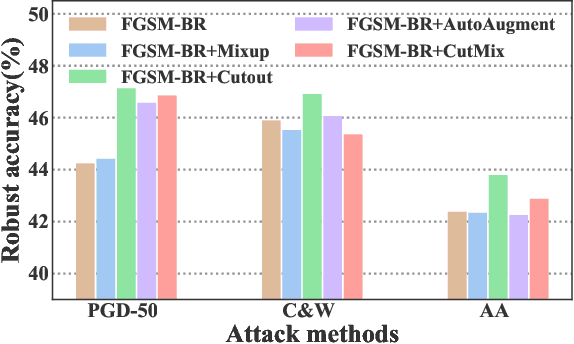
Fast Adversarial Training (FAT) not only improves the model robustness but also reduces the training cost of standard adversarial training. However, fast adversarial training often suffers from Catastrophic Overfitting (CO), which results in poor robustness performance. Catastrophic Overfitting describes the phenomenon of a sudden and significant decrease in robust accuracy during the training of fast adversarial training. Many effective techniques have been developed to prevent Catastrophic Overfitting and improve the model robustness from different perspectives. However, these techniques adopt inconsistent training settings and require different training costs, i.e, training time and memory costs, leading to unfair comparisons. In this paper, we conduct a comprehensive study of over 10 fast adversarial training methods in terms of adversarial robustness and training costs. We revisit the effectiveness and efficiency of fast adversarial training techniques in preventing Catastrophic Overfitting from the perspective of model local nonlinearity and propose an effective Lipschitz regularization method for fast adversarial training. Furthermore, we explore the effect of data augmentation and weight averaging in fast adversarial training and propose a simple yet effective auto weight averaging method to improve robustness further. By assembling these techniques, we propose a FGSM-based fast adversarial training method equipped with Lipschitz regularization and Auto Weight averaging, abbreviated as FGSM-LAW. Experimental evaluations on four benchmark databases demonstrate the superiority of the proposed method over state-of-the-art fast adversarial training methods and the advanced standard adversarial training methods.
Efficient View Synthesis with Neural Radiance Distribution Field
Aug 22, 2023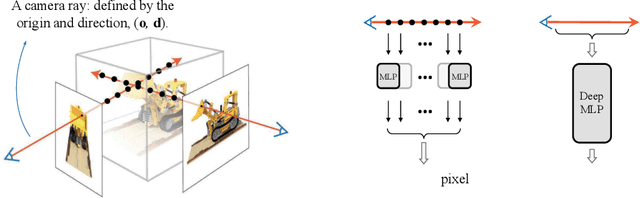

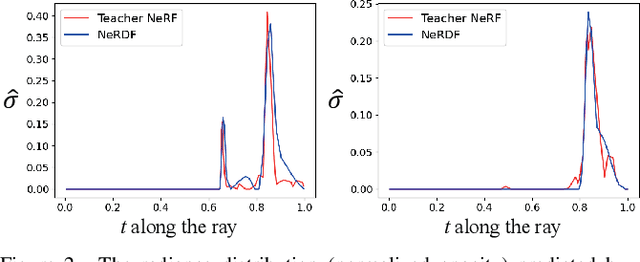
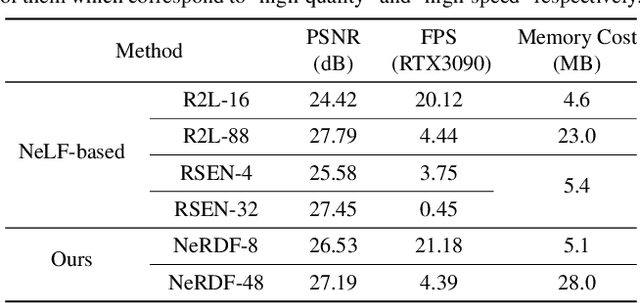
Recent work on Neural Radiance Fields (NeRF) has demonstrated significant advances in high-quality view synthesis. A major limitation of NeRF is its low rendering efficiency due to the need for multiple network forwardings to render a single pixel. Existing methods to improve NeRF either reduce the number of required samples or optimize the implementation to accelerate the network forwarding. Despite these efforts, the problem of multiple sampling persists due to the intrinsic representation of radiance fields. In contrast, Neural Light Fields (NeLF) reduce the computation cost of NeRF by querying only one single network forwarding per pixel. To achieve a close visual quality to NeRF, existing NeLF methods require significantly larger network capacities which limits their rendering efficiency in practice. In this work, we propose a new representation called Neural Radiance Distribution Field (NeRDF) that targets efficient view synthesis in real-time. Specifically, we use a small network similar to NeRF while preserving the rendering speed with a single network forwarding per pixel as in NeLF. The key is to model the radiance distribution along each ray with frequency basis and predict frequency weights using the network. Pixel values are then computed via volume rendering on radiance distributions. Experiments show that our proposed method offers a better trade-off among speed, quality, and network size than existing methods: we achieve a ~254x speed-up over NeRF with similar network size, with only a marginal performance decline. Our project page is at yushuang-wu.github.io/NeRDF.
G3Reg: Pyramid Graph-based Global Registration using Gaussian Ellipsoid Model
Aug 22, 2023This study introduces a novel framework, G3Reg, for fast and robust global registration of LiDAR point clouds. In contrast to conventional complex keypoints and descriptors, we extract fundamental geometric primitives including planes, clusters, and lines (PCL) from the raw point cloud to obtain low-level semantic segments. Each segment is formulated as a unified Gaussian Ellipsoid Model (GEM) by employing a probability ellipsoid to ensure the ground truth centers are encompassed with a certain degree of probability. Utilizing these GEMs, we then present a distrust-and-verify scheme based on a Pyramid Compatibility Graph for Global Registration (PAGOR). Specifically, we establish an upper bound, which can be traversed based on the confidence level for compatibility testing to construct the pyramid graph. Gradually, we solve multiple maximum cliques (MAC) for each level of the graph, generating numerous transformation candidates. In the verification phase, we adopt a precise and efficient metric for point cloud alignment quality, founded on geometric primitives, to identify the optimal candidate. The performance of the algorithm is extensively validated on three publicly available datasets and a self-collected multi-session dataset, without changing any parameter settings in the experimental evaluation. The results exhibit superior robustness and real-time performance of the G3Reg framework compared to state-of-the-art methods. Furthermore, we demonstrate the potential for integrating individual GEM and PAGOR components into other algorithmic frameworks to enhance their efficacy. To advance further research and promote community understanding, we have publicly shared the source code.
A Preliminary Investigation into Search and Matching for Tumour Discrimination in WHO Breast Taxonomy Using Deep Networks
Aug 22, 2023Breast cancer is one of the most common cancers affecting women worldwide. They include a group of malignant neoplasms with a variety of biological, clinical, and histopathological characteristics. There are more than 35 different histological forms of breast lesions that can be classified and diagnosed histologically according to cell morphology, growth, and architecture patterns. Recently, deep learning, in the field of artificial intelligence, has drawn a lot of attention for the computerized representation of medical images. Searchable digital atlases can provide pathologists with patch matching tools allowing them to search among evidently diagnosed and treated archival cases, a technology that may be regarded as computational second opinion. In this study, we indexed and analyzed the WHO breast taxonomy (Classification of Tumours 5th Ed.) spanning 35 tumour types. We visualized all tumour types using deep features extracted from a state-of-the-art deep learning model, pre-trained on millions of diagnostic histopathology images from the TCGA repository. Furthermore, we test the concept of a digital "atlas" as a reference for search and matching with rare test cases. The patch similarity search within the WHO breast taxonomy data reached over 88% accuracy when validating through "majority vote" and more than 91% accuracy when validating using top-n tumour types. These results show for the first time that complex relationships among common and rare breast lesions can be investigated using an indexed digital archive.
Multi-Objective Optimization for UAV Swarm-Assisted IoT with Virtual Antenna Arrays
Aug 03, 2023Unmanned aerial vehicle (UAV) network is a promising technology for assisting Internet-of-Things (IoT), where a UAV can use its limited service coverage to harvest and disseminate data from IoT devices with low transmission abilities. The existing UAV-assisted data harvesting and dissemination schemes largely require UAVs to frequently fly between the IoTs and access points, resulting in extra energy and time costs. To reduce both energy and time costs, a key way is to enhance the transmission performance of IoT and UAVs. In this work, we introduce collaborative beamforming into IoTs and UAVs simultaneously to achieve energy and time-efficient data harvesting and dissemination from multiple IoT clusters to remote base stations (BSs). Except for reducing these costs, another non-ignorable threat lies in the existence of the potential eavesdroppers, whereas the handling of eavesdroppers often increases the energy and time costs, resulting in a conflict with the minimization of the costs. Moreover, the importance of these goals may vary relatively in different applications. Thus, we formulate a multi-objective optimization problem (MOP) to simultaneously minimize the mission completion time, signal strength towards the eavesdropper, and total energy cost of the UAVs. We prove that the formulated MOP is an NP-hard, mixed-variable optimization, and large-scale optimization problem. Thus, we propose a swarm intelligence-based algorithm to find a set of candidate solutions with different trade-offs which can meet various requirements in a low computational complexity. We also show that swarm intelligence methods need to enhance solution initialization, solution update, and algorithm parameter update phases when dealing with mixed-variable optimization and large-scale problems. Simulation results demonstrate the proposed algorithm outperforms state-of-the-art swarm intelligence algorithms.
Change Point Detection With Conceptors
Aug 11, 2023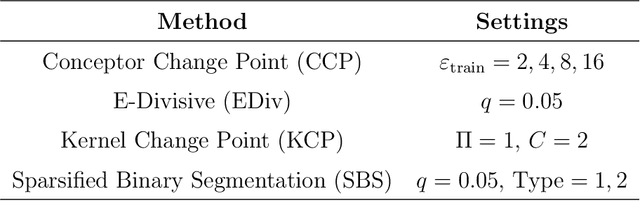
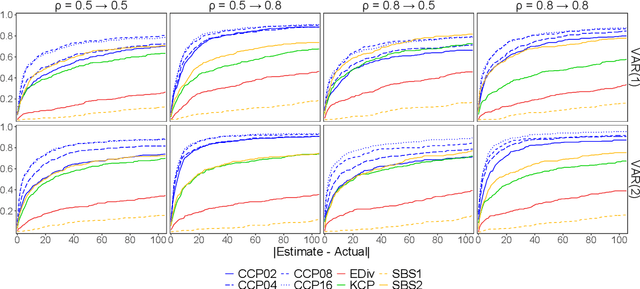
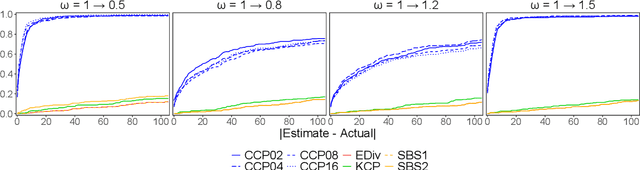
Offline change point detection seeks to identify points in a time series where the data generating process changes. This problem is well studied for univariate i.i.d. data, but becomes challenging with increasing dimension and temporal dependence. For the at most one change point problem, we propose the use of a conceptor matrix to learn the characteristic dynamics of a specified training window in a time series. The associated random recurrent neural network acts as a featurizer of the data, and change points are identified from a univariate quantification of the distance between the featurization and the space spanned by a representative conceptor matrix. This model agnostic method can suggest potential locations of interest that warrant further study. We prove that, under mild assumptions, the method provides a consistent estimate of the true change point, and quantile estimates for statistics are produced via a moving block bootstrap of the original data. The method is tested on simulations from several classes of processes, and we evaluate performance with clustering metrics, graphical methods, and observed Type 1 error control. We apply our method to publicly available neural data from rats experiencing bouts of non-REM sleep prior to exploration of a radial maze.
On the Learning of Digital Self-Interference Cancellation in Full-Duplex Radios
Aug 11, 2023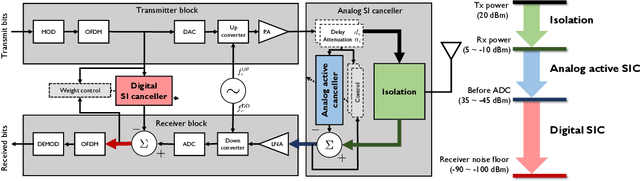
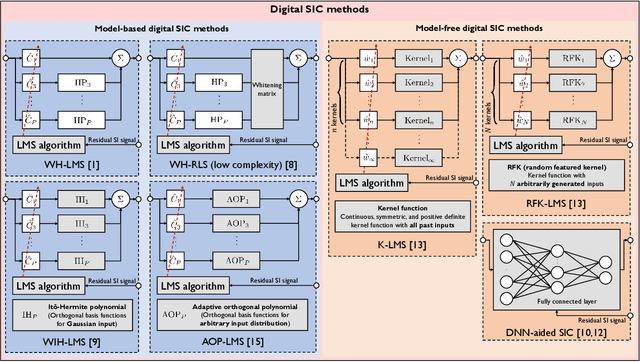
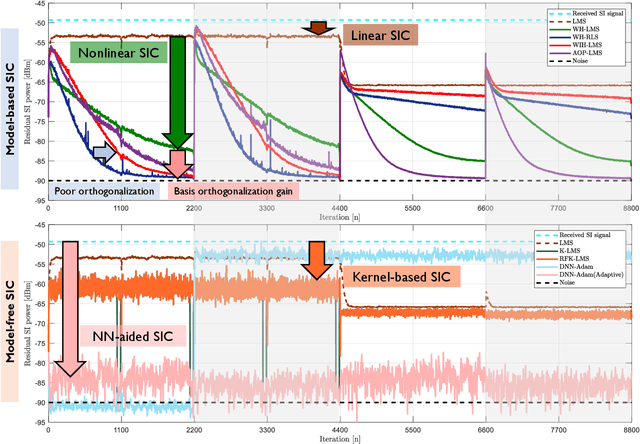

Full-duplex communication systems have the potential to achieve significantly higher data rates and lower latency compared to their half-duplex counterparts. This advantage stems from their ability to transmit and receive data simultaneously. However, to enable successful full-duplex operation, the primary challenge lies in accurately eliminating strong self-interference (SI). Overcoming this challenge involves addressing various issues, including the nonlinearity of power amplifiers, the time-varying nature of the SI channel, and the non-stationary transmit data distribution. In this article, we present a review of recent advancements in digital self-interference cancellation (SIC) algorithms. Our focus is on comparing the effectiveness of adaptable model-based SIC methods with their model-free counterparts that leverage data-driven machine learning techniques. Through our comparison study under practical scenarios, we demonstrate that the model-based SIC approach offers a more robust solution to the time-varying SI channel and the non-stationary transmission, achieving optimal SIC performance in terms of the convergence rate while maintaining low computational complexity. To validate our findings, we conduct experiments using a software-defined radio testbed that conforms to the IEEE 802.11a standards. The experimental results demonstrate the robustness of the model-based SIC methods, providing practical evidence of their effectiveness.
Greedy online change point detection
Aug 14, 2023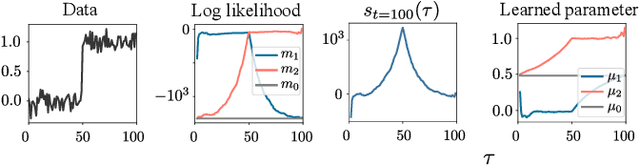
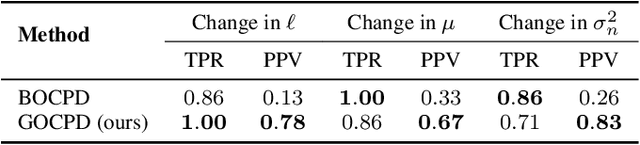
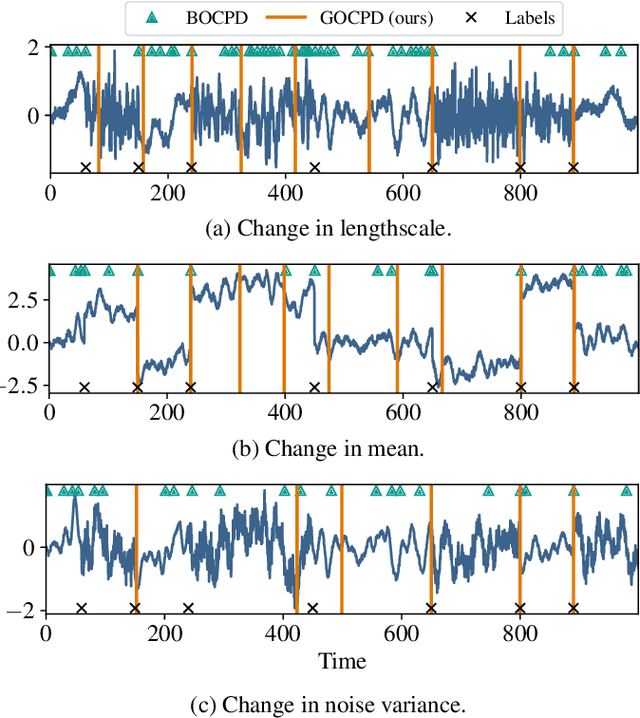
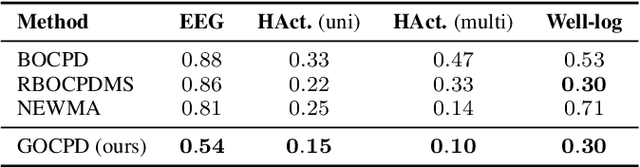
Standard online change point detection (CPD) methods tend to have large false discovery rates as their detections are sensitive to outliers. To overcome this drawback, we propose Greedy Online Change Point Detection (GOCPD), a computationally appealing method which finds change points by maximizing the probability of the data coming from the (temporal) concatenation of two independent models. We show that, for time series with a single change point, this objective is unimodal and thus CPD can be accelerated via ternary search with logarithmic complexity. We demonstrate the effectiveness of GOCPD on synthetic data and validate our findings on real-world univariate and multivariate settings.
Discrete-time Robust PD Controlled System with DOB/CDOB Compensation for High Speed Autonomous Vehicle Path Following
Jun 02, 2023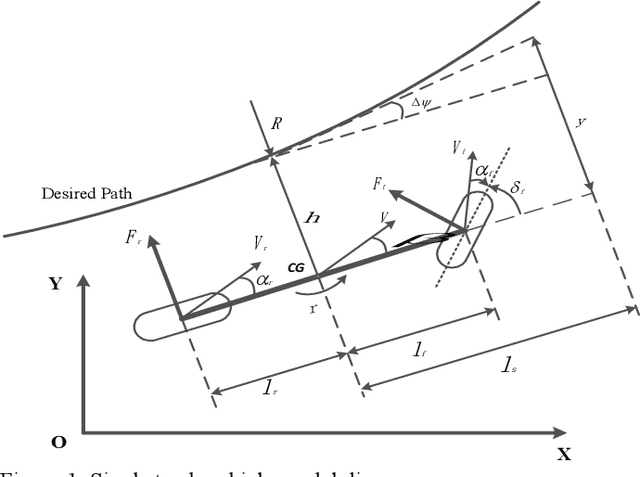
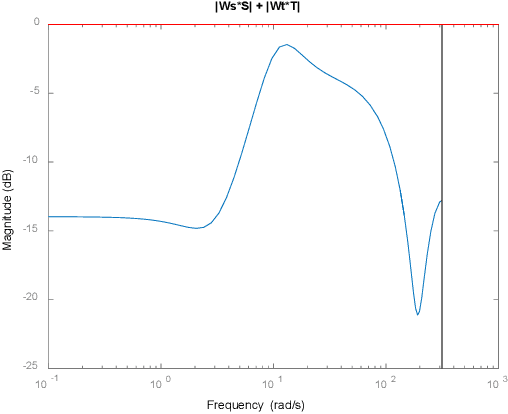
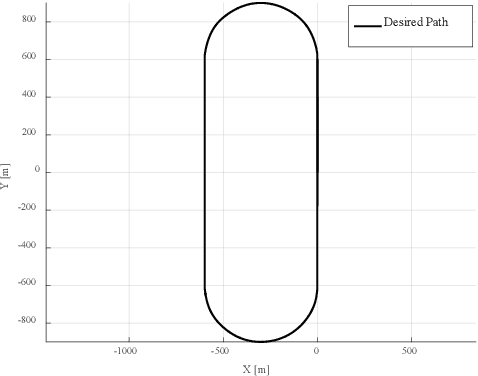
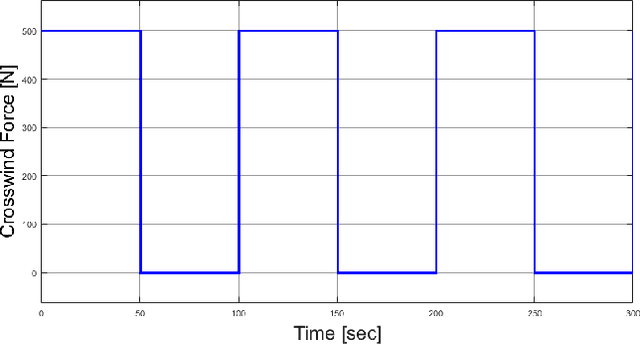
Autonomous vehicle path following performance is one of significant consideration. This paper presents discrete time design of robust PD controlled system with disturbance observer (DOB) and communication disturbance observer (CDOB) compensation to enhance autonomous vehicle path following performance. Although always implemented on digital devices, DOB and CDOB structure are usually designed in continuous time in the literature and also in our previous work. However, it requires high sampling rate for continuous-time design block diagram to automatically convert to corresponding discrete-time controller using rapid controller prototyping systems. In this paper, direct discrete time design is carried out. Digital PD feedback controller is designed based on the nominal plant using the proposed parameter space approach. Zero order hold method is applied to discretize the nominal plant, DOB and CDOB structure in continuous domain. Discrete time DOB is embedded into the steering to path following error loop for model regulation in the presence of uncertainty in vehicle parameters such as vehicle mass, vehicle speed and road-tire friction coefficient and rejecting external disturbance like crosswind force. On the other hand, time delay from CAN bus based sensor and actuator command interfaces results in degradation of system performance since large negative phase angles are added to the plant frequency response. Discrete time CDOB compensated control system can be used for time delay compensation where the accurate knowledge of delay time value is not necessary. A validated model of our lab Ford Fusion hybrid automated driving research vehicle is used for the simulation analysis while the vehicle is driving at high speed. Simulation results successfully demonstrate the improvement of autonomous vehicle path following performance with the proposed discrete time DOB and CDOB structure.