 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Path Signatures for Seizure Forecasting
Aug 18, 2023
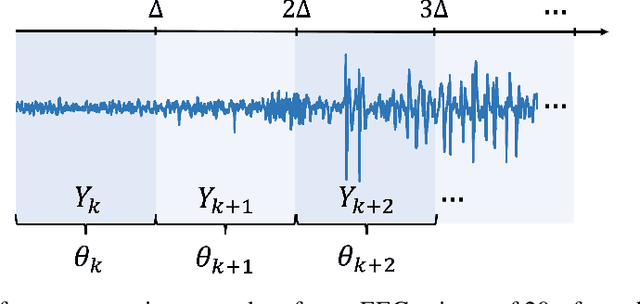
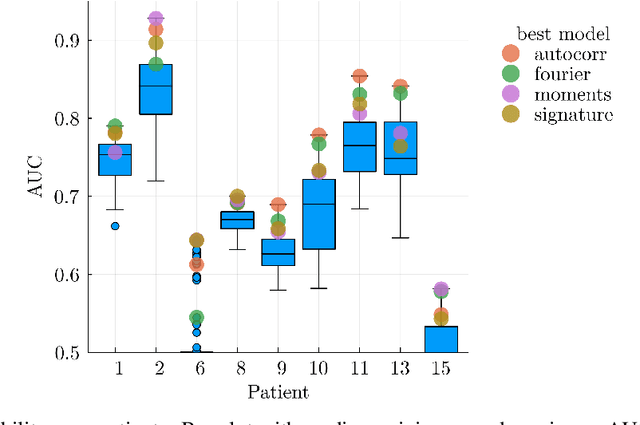
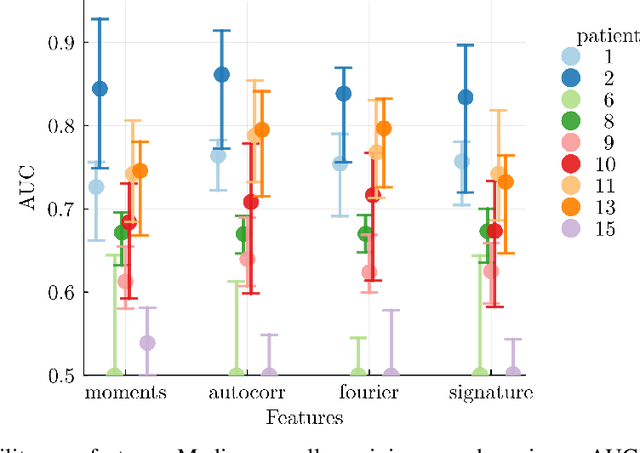
Forecasting the state of a system from an observed time series is the subject of research in many domains, such as computational neuroscience. Here, the prediction of epileptic seizures from brain measurements is an unresolved problem. There are neither complete models describing underlying brain dynamics, nor do individual patients exhibit a single seizure onset pattern, which complicates the development of a `one-size-fits-all' solution. Based on a longitudinal patient data set, we address the automated discovery and quantification of statistical features (biomarkers) that can be used to forecast seizures in a patient-specific way. We use existing and novel feature extraction algorithms, in particular the path signature, a recent development in time series analysis. Of particular interest is how this set of complex, nonlinear features performs compared to simpler, linear features on this task. Our inference is based on statistical classification algorithms with in-built subset selection to discern time series with and without an impending seizure while selecting only a small number of relevant features. This study may be seen as a step towards a generalisable pattern recognition pipeline for time series in a broader context.
Probabilistic load forecasting with Reservoir Computing
Aug 24, 2023Some applications of deep learning require not only to provide accurate results but also to quantify the amount of confidence in their prediction. The management of an electric power grid is one of these cases: to avoid risky scenarios, decision-makers need both precise and reliable forecasts of, for example, power loads. For this reason, point forecasts are not enough hence it is necessary to adopt methods that provide an uncertainty quantification. This work focuses on reservoir computing as the core time series forecasting method, due to its computational efficiency and effectiveness in predicting time series. While the RC literature mostly focused on point forecasting, this work explores the compatibility of some popular uncertainty quantification methods with the reservoir setting. Both Bayesian and deterministic approaches to uncertainty assessment are evaluated and compared in terms of their prediction accuracy, computational resource efficiency and reliability of the estimated uncertainty, based on a set of carefully chosen performance metrics.
Optimizing Neural Network Scale for ECG Classification
Aug 24, 2023
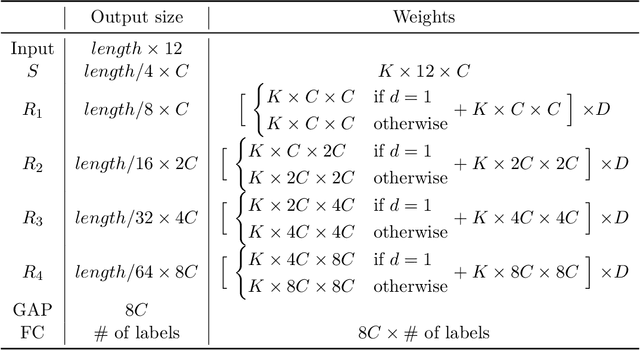
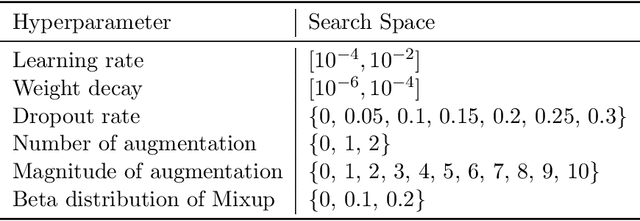
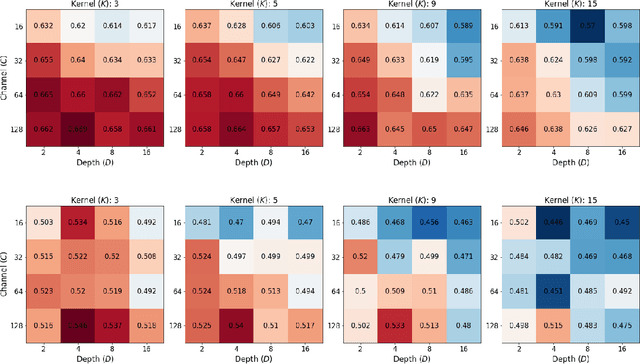
We study scaling convolutional neural networks (CNNs), specifically targeting Residual neural networks (ResNet), for analyzing electrocardiograms (ECGs). Although ECG signals are time-series data, CNN-based models have been shown to outperform other neural networks with different architectures in ECG analysis. However, most previous studies in ECG analysis have overlooked the importance of network scaling optimization, which significantly improves performance. We explored and demonstrated an efficient approach to scale ResNet by examining the effects of crucial parameters, including layer depth, the number of channels, and the convolution kernel size. Through extensive experiments, we found that a shallower network, a larger number of channels, and smaller kernel sizes result in better performance for ECG classifications. The optimal network scale might differ depending on the target task, but our findings provide insight into obtaining more efficient and accurate models with fewer computing resources or less time. In practice, we demonstrate that a narrower search space based on our findings leads to higher performance.
SparseBEV: High-Performance Sparse 3D Object Detection from Multi-Camera Videos
Sep 05, 2023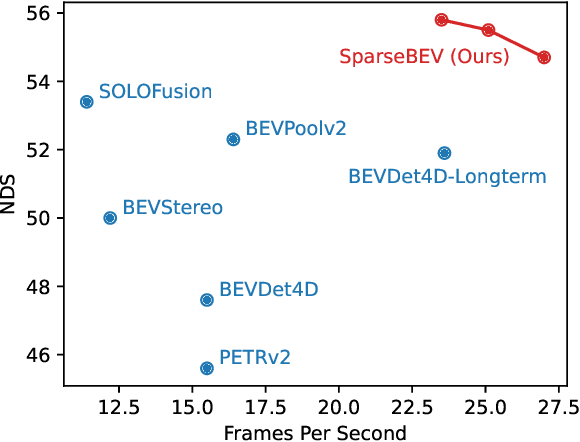
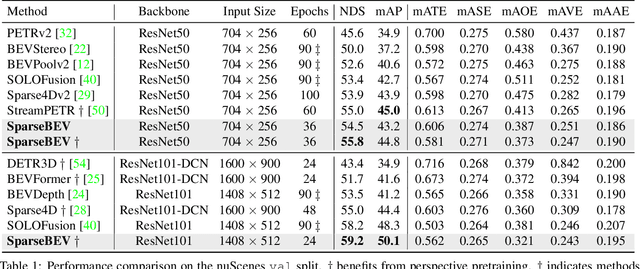
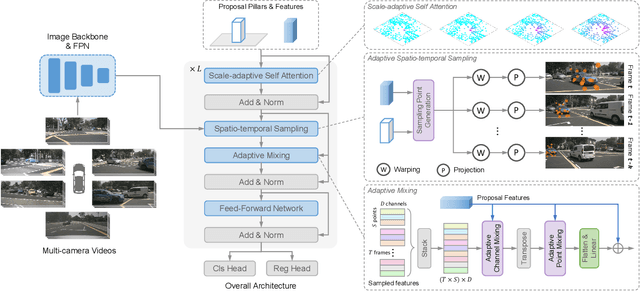
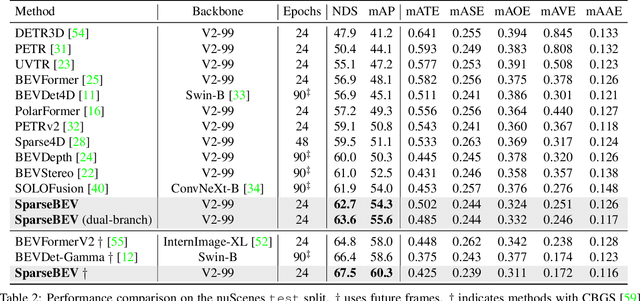
Camera-based 3D object detection in BEV (Bird's Eye View) space has drawn great attention over the past few years. Dense detectors typically follow a two-stage pipeline by first constructing a dense BEV feature and then performing object detection in BEV space, which suffers from complex view transformations and high computation cost. On the other side, sparse detectors follow a query-based paradigm without explicit dense BEV feature construction, but achieve worse performance than the dense counterparts. In this paper, we find that the key to mitigate this performance gap is the adaptability of the detector in both BEV and image space. To achieve this goal, we propose SparseBEV, a fully sparse 3D object detector that outperforms the dense counterparts. SparseBEV contains three key designs, which are (1) scale-adaptive self attention to aggregate features with adaptive receptive field in BEV space, (2) adaptive spatio-temporal sampling to generate sampling locations under the guidance of queries, and (3) adaptive mixing to decode the sampled features with dynamic weights from the queries. On the test split of nuScenes, SparseBEV achieves the state-of-the-art performance of 67.5 NDS. On the val split, SparseBEV achieves 55.8 NDS while maintaining a real-time inference speed of 23.5 FPS. Code is available at https://github.com/MCG-NJU/SparseBEV.
On the Complexity of Differentially Private Best-Arm Identification with Fixed Confidence
Sep 05, 2023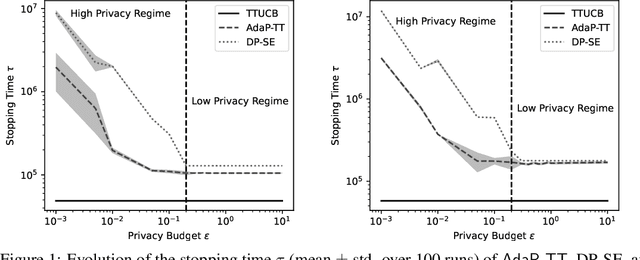
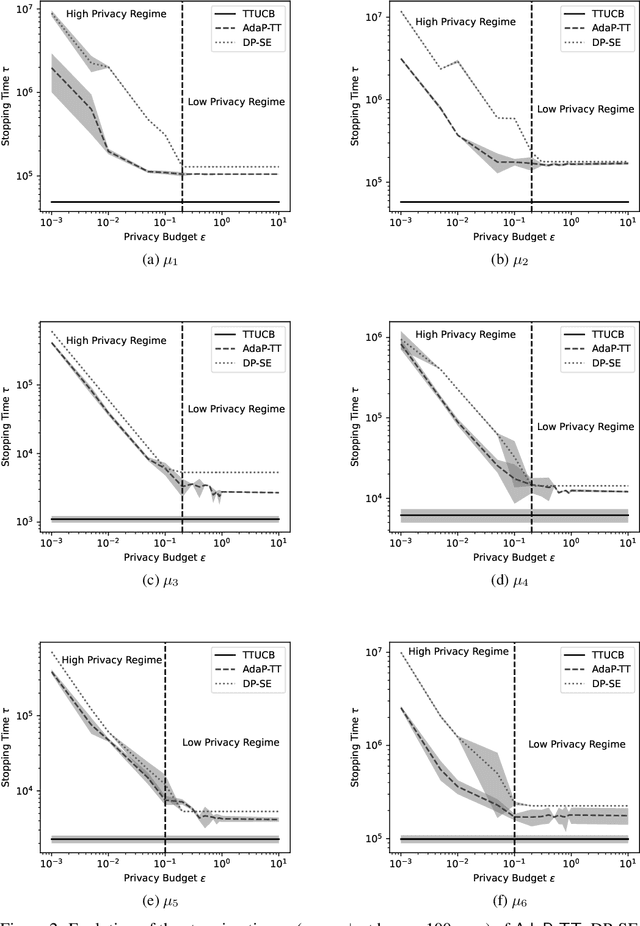
Best Arm Identification (BAI) problems are progressively used for data-sensitive applications, such as designing adaptive clinical trials, tuning hyper-parameters, and conducting user studies to name a few. Motivated by the data privacy concerns invoked by these applications, we study the problem of BAI with fixed confidence under $\epsilon$-global Differential Privacy (DP). First, to quantify the cost of privacy, we derive a lower bound on the sample complexity of any $\delta$-correct BAI algorithm satisfying $\epsilon$-global DP. Our lower bound suggests the existence of two privacy regimes depending on the privacy budget $\epsilon$. In the high-privacy regime (small $\epsilon$), the hardness depends on a coupled effect of privacy and a novel information-theoretic quantity, called the Total Variation Characteristic Time. In the low-privacy regime (large $\epsilon$), the sample complexity lower bound reduces to the classical non-private lower bound. Second, we propose AdaP-TT, an $\epsilon$-global DP variant of the Top Two algorithm. AdaP-TT runs in arm-dependent adaptive episodes and adds Laplace noise to ensure a good privacy-utility trade-off. We derive an asymptotic upper bound on the sample complexity of AdaP-TT that matches with the lower bound up to multiplicative constants in the high-privacy regime. Finally, we provide an experimental analysis of AdaP-TT that validates our theoretical results.
Domain Adaptation for Satellite-Borne Hyperspectral Cloud Detection
Sep 05, 2023


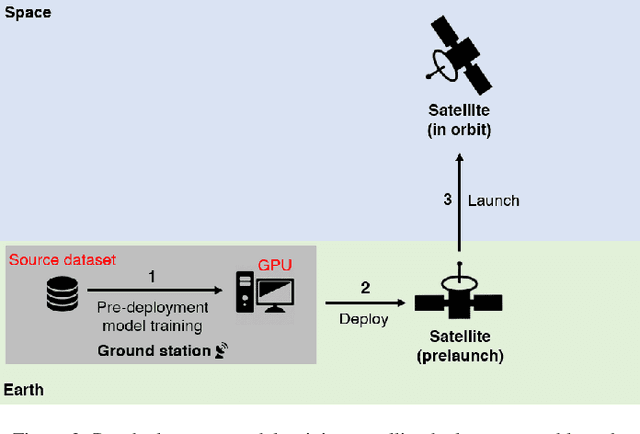
The advent of satellite-borne machine learning hardware accelerators has enabled the on-board processing of payload data using machine learning techniques such as convolutional neural networks (CNN). A notable example is using a CNN to detect the presence of clouds in hyperspectral data captured on Earth observation (EO) missions, whereby only clear sky data is downlinked to conserve bandwidth. However, prior to deployment, new missions that employ new sensors will not have enough representative datasets to train a CNN model, while a model trained solely on data from previous missions will underperform when deployed to process the data on the new missions. This underperformance stems from the domain gap, i.e., differences in the underlying distributions of the data generated by the different sensors in previous and future missions. In this paper, we address the domain gap problem in the context of on-board hyperspectral cloud detection. Our main contributions lie in formulating new domain adaptation tasks that are motivated by a concrete EO mission, developing a novel algorithm for bandwidth-efficient supervised domain adaptation, and demonstrating test-time adaptation algorithms on space deployable neural network accelerators. Our contributions enable minimal data transmission to be invoked (e.g., only 1% of the weights in ResNet50) to achieve domain adaptation, thereby allowing more sophisticated CNN models to be deployed and updated on satellites without being hampered by domain gap and bandwidth limitations.
Graph-Based Interaction-Aware Multimodal 2D Vehicle Trajectory Prediction using Diffusion Graph Convolutional Networks
Sep 05, 2023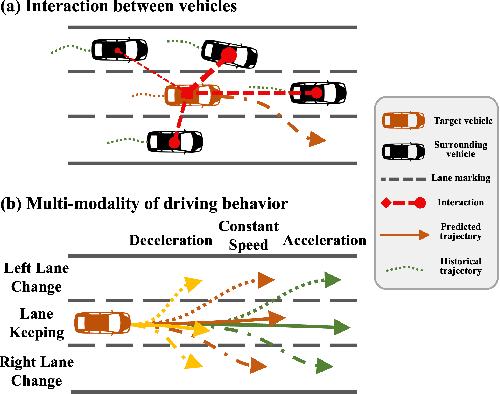
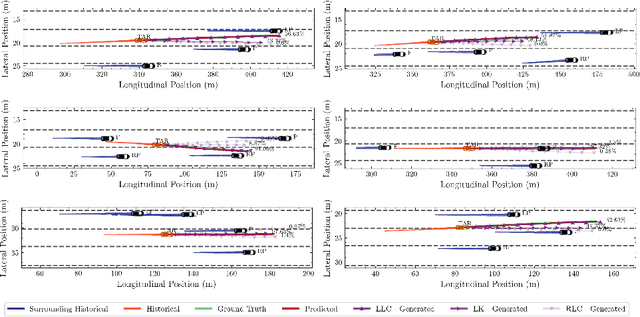
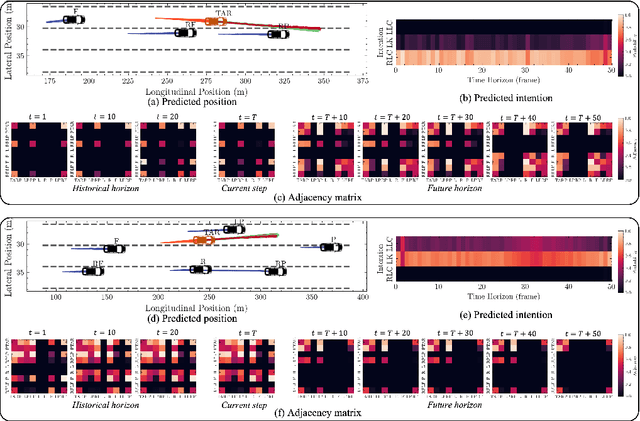
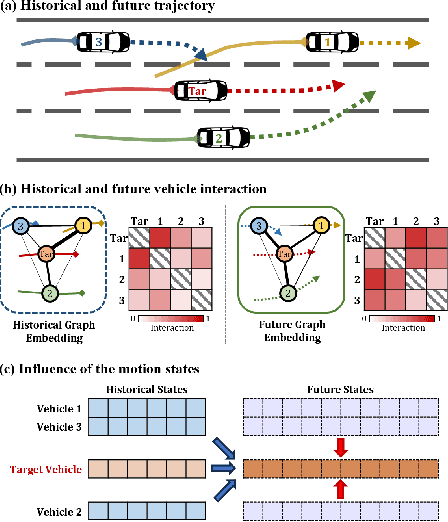
Predicting vehicle trajectories is crucial for ensuring automated vehicle operation efficiency and safety, particularly on congested multi-lane highways. In such dynamic environments, a vehicle's motion is determined by its historical behaviors as well as interactions with surrounding vehicles. These intricate interactions arise from unpredictable motion patterns, leading to a wide range of driving behaviors that warrant in-depth investigation. This study presents the Graph-based Interaction-aware Multi-modal Trajectory Prediction (GIMTP) framework, designed to probabilistically predict future vehicle trajectories by effectively capturing these interactions. Within this framework, vehicles' motions are conceptualized as nodes in a time-varying graph, and the traffic interactions are represented by a dynamic adjacency matrix. To holistically capture both spatial and temporal dependencies embedded in this dynamic adjacency matrix, the methodology incorporates the Diffusion Graph Convolutional Network (DGCN), thereby providing a graph embedding of both historical states and future states. Furthermore, we employ a driving intention-specific feature fusion, enabling the adaptive integration of historical and future embeddings for enhanced intention recognition and trajectory prediction. This model gives two-dimensional predictions for each mode of longitudinal and lateral driving behaviors and offers probabilistic future paths with corresponding probabilities, addressing the challenges of complex vehicle interactions and multi-modality of driving behaviors. Validation using real-world trajectory datasets demonstrates the efficiency and potential.
Hawkes Processes with Delayed Granger Causality
Aug 11, 2023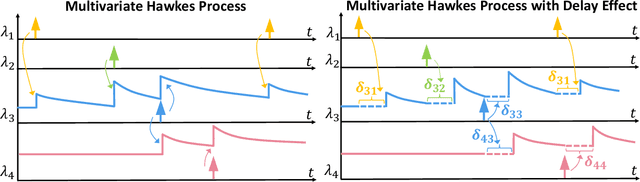
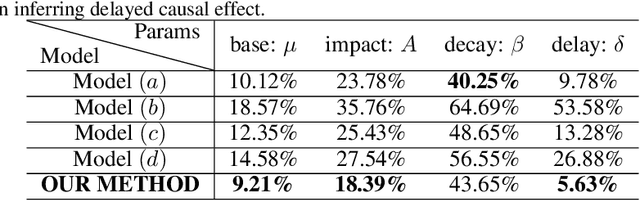
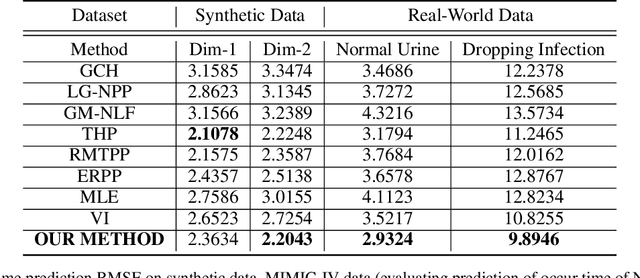
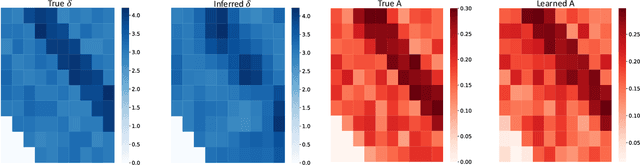
We aim to explicitly model the delayed Granger causal effects based on multivariate Hawkes processes. The idea is inspired by the fact that a causal event usually takes some time to exert an effect. Studying this time lag itself is of interest. Given the proposed model, we first prove the identifiability of the delay parameter under mild conditions. We further investigate a model estimation method under a complex setting, where we want to infer the posterior distribution of the time lags and understand how this distribution varies across different scenarios. We treat the time lags as latent variables and formulate a Variational Auto-Encoder (VAE) algorithm to approximate the posterior distribution of the time lags. By explicitly modeling the time lags in Hawkes processes, we add flexibility to the model. The inferred time-lag posterior distributions are of scientific meaning and help trace the original causal time that supports the root cause analysis. We empirically evaluate our model's event prediction and time-lag inference accuracy on synthetic and real data, achieving promising results.
Conversational Swarm Intelligence, a Pilot Study
Aug 31, 2023Conversational Swarm Intelligence (CSI) is a new method for enabling large human groups to hold real-time networked conversations using a technique modeled on the dynamics of biological swarms. Through the novel use of conversational agents powered by Large Language Models (LLMs), the CSI structure simultaneously enables local dialog among small deliberative groups and global propagation of conversational content across a larger population. In this way, CSI combines the benefits of small-group deliberative reasoning and large-scale collective intelligence. In this pilot study, participants deliberating in conversational swarms (via text chat) (a) produced 30% more contributions (p<0.05) than participants deliberating in a standard centralized chat room and (b) demonstrated 7.2% less variance in contribution quantity. These results indicate that users contributed more content and participated more evenly when using the CSI structure.
Simple LLM Prompting is State-of-the-Art for Robust and Multilingual Dialogue Evaluation
Aug 31, 2023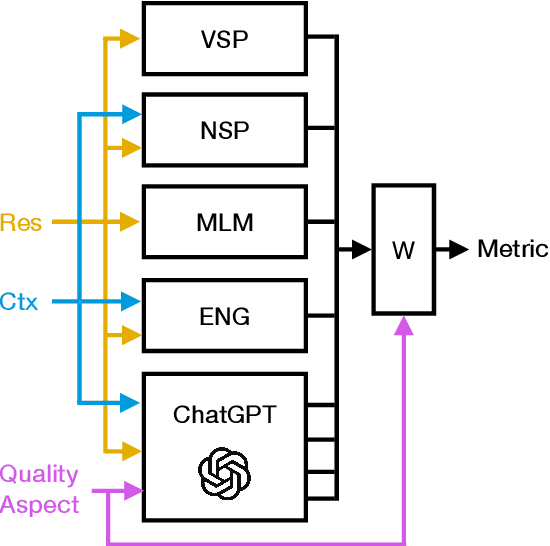
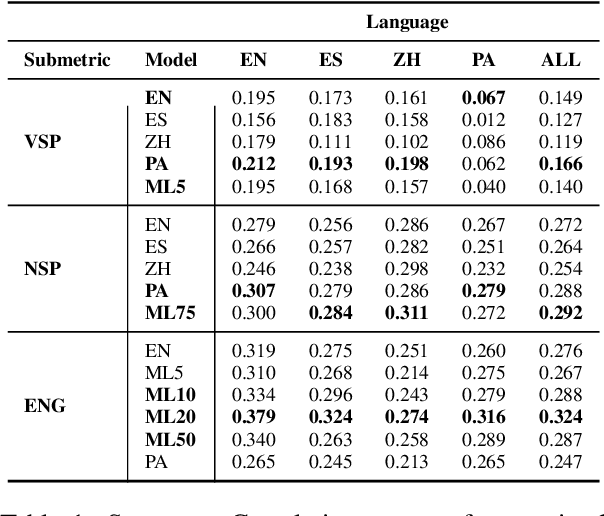

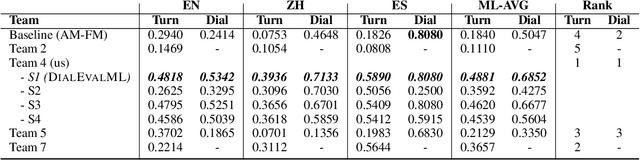
Despite significant research effort in the development of automatic dialogue evaluation metrics, little thought is given to evaluating dialogues other than in English. At the same time, ensuring metrics are invariant to semantically similar responses is also an overlooked topic. In order to achieve the desired properties of robustness and multilinguality for dialogue evaluation metrics, we propose a novel framework that takes advantage of the strengths of current evaluation models with the newly-established paradigm of prompting Large Language Models (LLMs). Empirical results show our framework achieves state of the art results in terms of mean Spearman correlation scores across several benchmarks and ranks first place on both the Robust and Multilingual tasks of the DSTC11 Track 4 "Automatic Evaluation Metrics for Open-Domain Dialogue Systems", proving the evaluation capabilities of prompted LLMs.