 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unraveling the Complexity of Splitting Sequential Data: Tackling Challenges in Video and Time Series Analysis
Jul 26, 2023
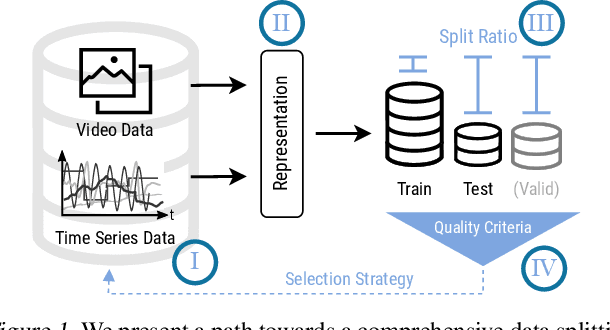
Splitting of sequential data, such as videos and time series, is an essential step in various data analysis tasks, including object tracking and anomaly detection. However, splitting sequential data presents a variety of challenges that can impact the accuracy and reliability of subsequent analyses. This concept article examines the challenges associated with splitting sequential data, including data acquisition, data representation, split ratio selection, setting up quality criteria, and choosing suitable selection strategies. We explore these challenges through two real-world examples: motor test benches and particle tracking in liquids.
Alleviating Video-Length Effect for Micro-video Recommendation
Aug 31, 2023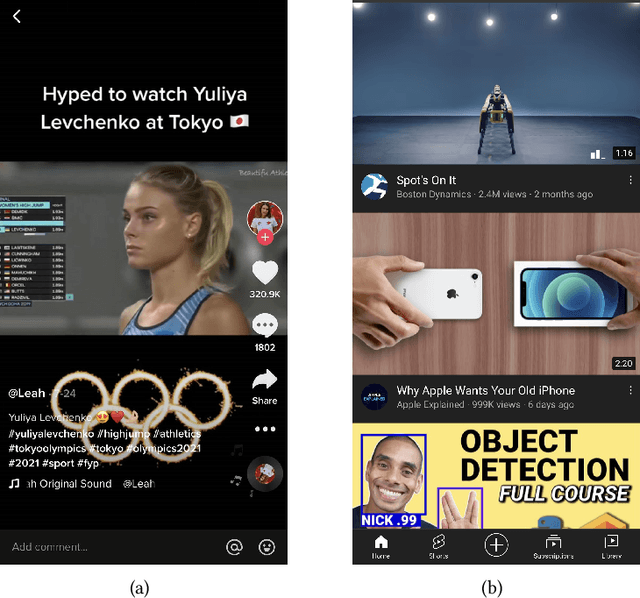

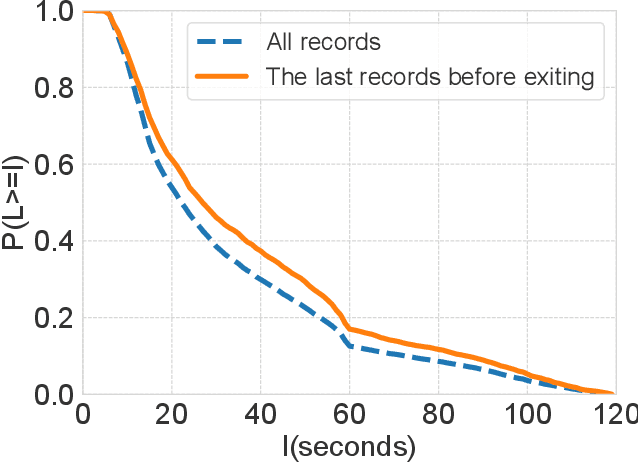
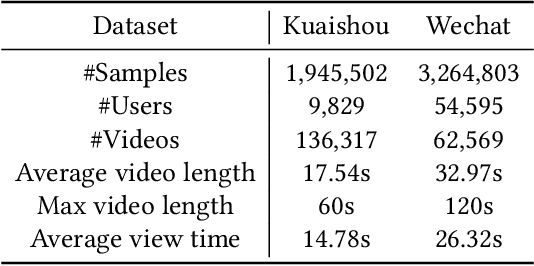
Micro-videos platforms such as TikTok are extremely popular nowadays. One important feature is that users no longer select interested videos from a set, instead they either watch the recommended video or skip to the next one. As a result, the time length of users' watching behavior becomes the most important signal for identifying preferences. However, our empirical data analysis has shown a video-length effect that long videos are easier to receive a higher value of average view time, thus adopting such view-time labels for measuring user preferences can easily induce a biased model that favors the longer videos. In this paper, we propose a Video Length Debiasing Recommendation (VLDRec) method to alleviate such an effect for micro-video recommendation. VLDRec designs the data labeling approach and the sample generation module that better capture user preferences in a view-time oriented manner. It further leverages the multi-task learning technique to jointly optimize the above samples with original biased ones. Extensive experiments show that VLDRec can improve the users' view time by 1.81% and 11.32% on two real-world datasets, given a recommendation list of a fixed overall video length, compared with the best baseline method. Moreover, VLDRec is also more effective in matching users' interests in terms of the video content.
Prototypes as Explanation for Time Series Anomaly Detection
Jul 04, 2023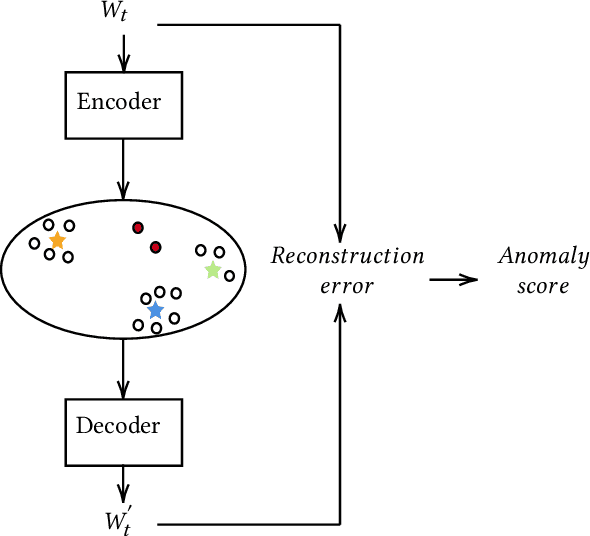
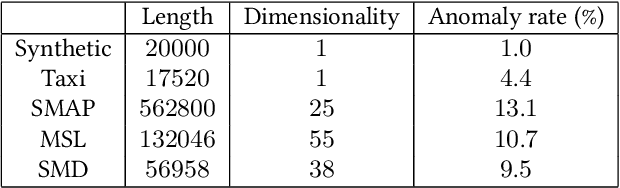
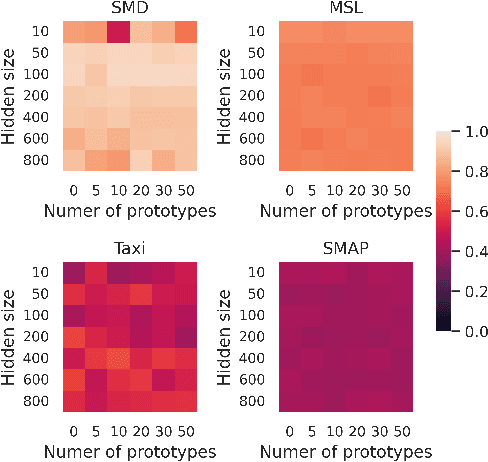
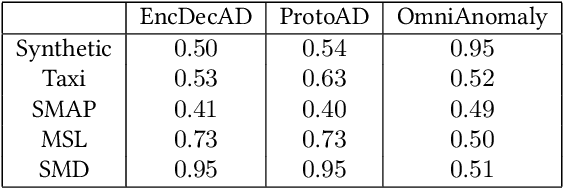
Detecting abnormal patterns that deviate from a certain regular repeating pattern in time series is essential in many big data applications. However, the lack of labels, the dynamic nature of time series data, and unforeseeable abnormal behaviors make the detection process challenging. Despite the success of recent deep anomaly detection approaches, the mystical mechanisms in such black-box models have become a new challenge in safety-critical applications. The lack of model transparency and prediction reliability hinders further breakthroughs in such domains. This paper proposes ProtoAD, using prototypes as the example-based explanation for the state of regular patterns during anomaly detection. Without significant impact on the detection performance, prototypes shed light on the deep black-box models and provide intuitive understanding for domain experts and stakeholders. We extend the widely used prototype learning in classification problems into anomaly detection. By visualizing both the latent space and input space prototypes, we intuitively demonstrate how regular data are modeled and why specific patterns are considered abnormal.
Structured Learning in Time-dependent Cox Models
Jun 21, 2023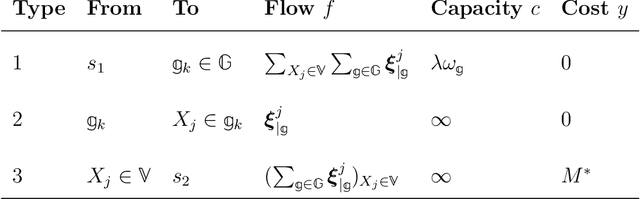
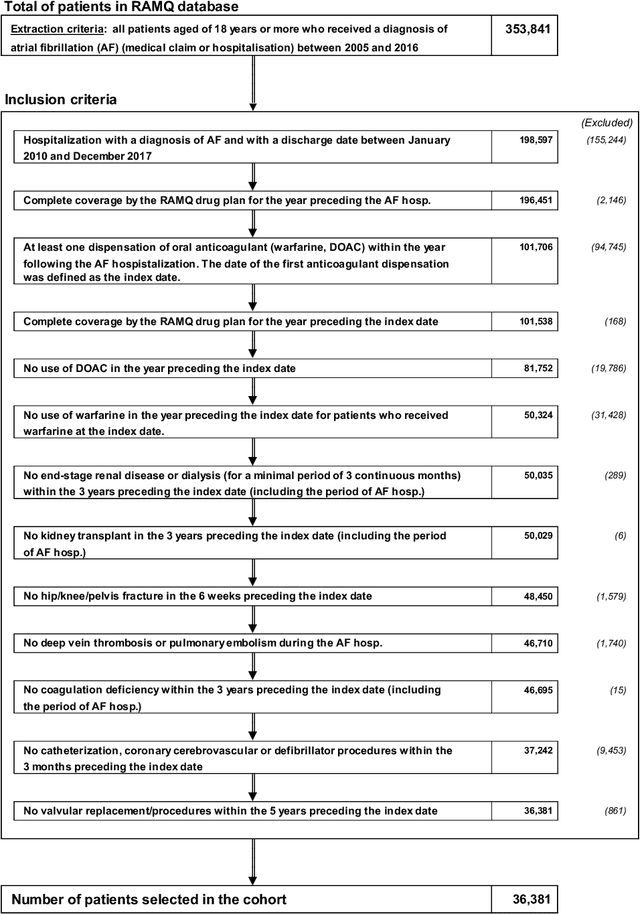

Cox models with time-dependent coefficients and covariates are widely used in survival analysis. In high-dimensional settings, sparse regularization techniques are employed for variable selection, but existing methods for time-dependent Cox models lack flexibility in enforcing specific sparsity patterns (i.e., covariate structures). We propose a flexible framework for variable selection in time-dependent Cox models, accommodating complex selection rules. Our method can adapt to arbitrary grouping structures, including interaction selection, temporal, spatial, tree, and directed acyclic graph structures. It achieves accurate estimation with low false alarm rates. We develop the sox package, implementing a network flow algorithm for efficiently solving models with complex covariate structures. Sox offers a user-friendly interface for specifying grouping structures and delivers fast computation. Through examples, including a case study on identifying predictors of time to all-cause death in atrial fibrillation patients, we demonstrate the practical application of our method with specific selection rules.
V2CE: Video to Continuous Events Simulator
Sep 16, 2023Dynamic Vision Sensor (DVS)-based solutions have recently garnered significant interest across various computer vision tasks, offering notable benefits in terms of dynamic range, temporal resolution, and inference speed. However, as a relatively nascent vision sensor compared to Active Pixel Sensor (APS) devices such as RGB cameras, DVS suffers from a dearth of ample labeled datasets. Prior efforts to convert APS data into events often grapple with issues such as a considerable domain shift from real events, the absence of quantified validation, and layering problems within the time axis. In this paper, we present a novel method for video-to-events stream conversion from multiple perspectives, considering the specific characteristics of DVS. A series of carefully designed losses helps enhance the quality of generated event voxels significantly. We also propose a novel local dynamic-aware timestamp inference strategy to accurately recover event timestamps from event voxels in a continuous fashion and eliminate the temporal layering problem. Results from rigorous validation through quantified metrics at all stages of the pipeline establish our method unquestionably as the current state-of-the-art (SOTA).
Triple Regression for Camera Agnostic Sim2Real Robot Grasping and Manipulation Tasks
Sep 16, 2023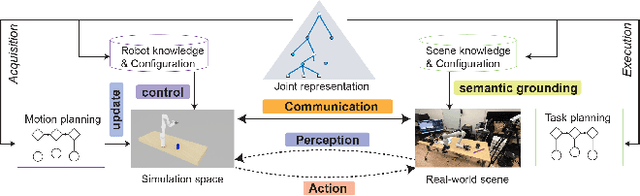
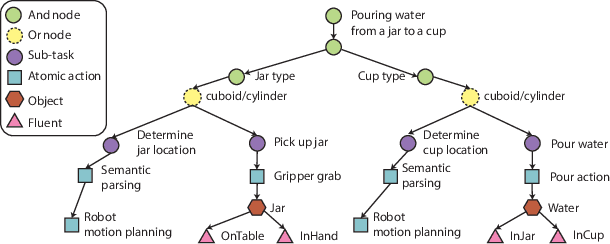
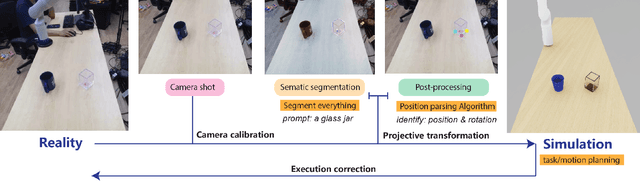

Sim2Real (Simulation to Reality) techniques have gained prominence in robotic manipulation and motion planning due to their ability to enhance success rates by enabling agents to test and evaluate various policies and trajectories. In this paper, we investigate the advantages of integrating Sim2Real into robotic frameworks. We introduce the Triple Regression Sim2Real framework, which constructs a real-time digital twin. This twin serves as a replica of reality to simulate and evaluate multiple plans before their execution in real-world scenarios. Our triple regression approach addresses the reality gap by: (1) mitigating projection errors between real and simulated camera perspectives through the first two regression models, and (2) detecting discrepancies in robot control using the third regression model. Experiments on 6-DoF grasp and manipulation tasks (where the gripper can approach from any direction) highlight the effectiveness of our framework. Remarkably, with only RGB input images, our method achieves state-of-the-art success rates. This research advances efficient robot training methods and sets the stage for rapid advancements in robotics and automation.
Graph-based Decentralized Task Allocation for Multi-Robot Target Localization
Sep 16, 2023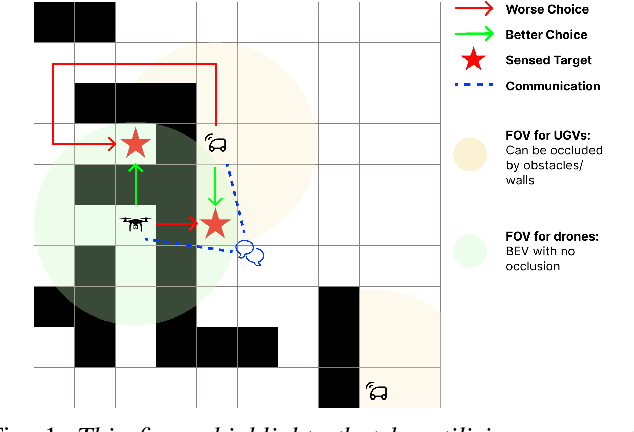
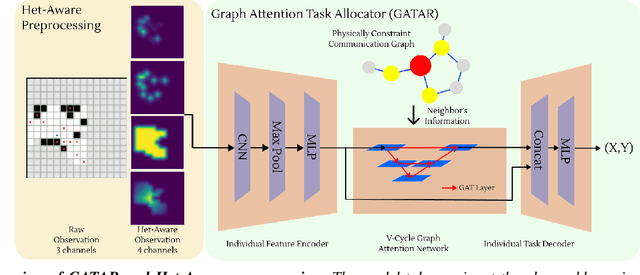

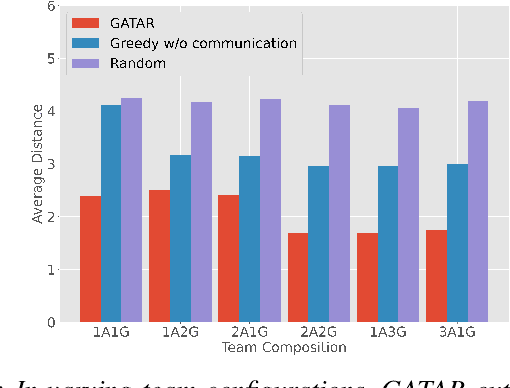
We introduce a new approach to address the task allocation problem in a system of heterogeneous robots comprising of Unmanned Ground Vehicles (UGVs) and Unmanned Aerial Vehicles (UAVs). The proposed model, \texttt{\method}, or \textbf{G}raph \textbf{A}ttention \textbf{T}ask \textbf{A}llocato\textbf{R} aggregates information from neighbors in the multi-robot system, with the aim of achieving joint optimality in the target localization efficiency.Being decentralized, our method is highly robust and adaptable to situations where collaborators may change over time, ensuring the continuity of the mission. We also proposed heterogeneity-aware preprocessing to let all the different types of robots collaborate with a uniform model.The experimental results demonstrate the effectiveness and scalability of the proposed approach in a range of simulated scenarios. The model can allocate targets' positions close to the expert algorithm's result, with a median spatial gap less than a unit length. This approach can be used in multi-robot systems deployed in search and rescue missions, environmental monitoring, and disaster response.
A Low-Latency FFT-IFFT Cascade Architecture
Sep 16, 2023This paper addresses the design of a partly-parallel cascaded FFT-IFFT architecture that does not require any intermediate buffer. Folding can be used to design partly-parallel architectures for FFT and IFFT. While many cascaded FFT-IFFT architectures can be designed using various folding sets for the FFT and the IFFT, for a specified folded FFT architecture, there exists a unique folding set to design the IFFT architecture that does not require an intermediate buffer. Such a folding set is designed by processing the output of the FFT as soon as possible (ASAP) in the folded IFFT. Elimination of the intermediate buffer reduces latency and saves area. The proposed approach is also extended to interleaved processing of multi-channel time-series. The proposed FFT-IFFT cascade architecture saves about N/2 memory elements and N/4 clock cycles of latency compared to a design with identical folding sets. For the 2-interleaved FFT-IFFT cascade, the memory and latency savings are, respectively, N/2 units and N/2 clock cycles, compared to a design with identical folding sets.
ExBluRF: Efficient Radiance Fields for Extreme Motion Blurred Images
Sep 16, 2023

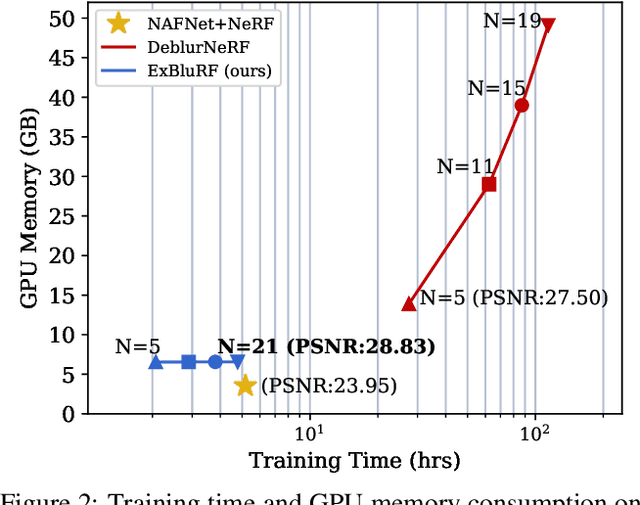
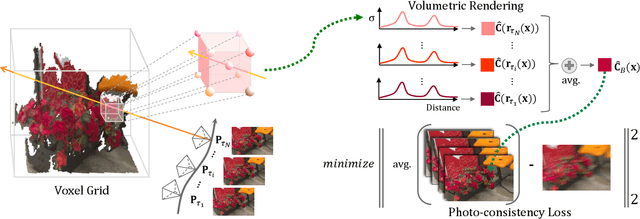
We present ExBluRF, a novel view synthesis method for extreme motion blurred images based on efficient radiance fields optimization. Our approach consists of two main components: 6-DOF camera trajectory-based motion blur formulation and voxel-based radiance fields. From extremely blurred images, we optimize the sharp radiance fields by jointly estimating the camera trajectories that generate the blurry images. In training, multiple rays along the camera trajectory are accumulated to reconstruct single blurry color, which is equivalent to the physical motion blur operation. We minimize the photo-consistency loss on blurred image space and obtain the sharp radiance fields with camera trajectories that explain the blur of all images. The joint optimization on the blurred image space demands painfully increasing computation and resources proportional to the blur size. Our method solves this problem by replacing the MLP-based framework to low-dimensional 6-DOF camera poses and voxel-based radiance fields. Compared with the existing works, our approach restores much sharper 3D scenes from challenging motion blurred views with the order of 10 times less training time and GPU memory consumption.
Inverse classification with logistic and softmax classifiers: efficient optimization
Sep 16, 2023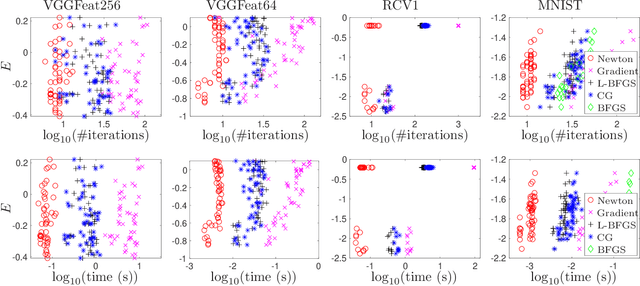
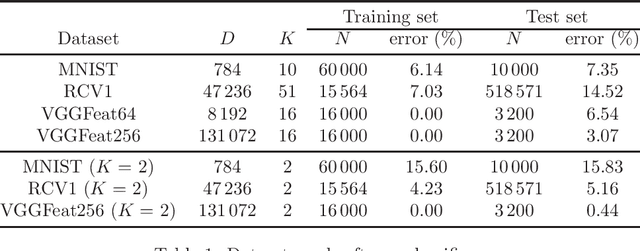
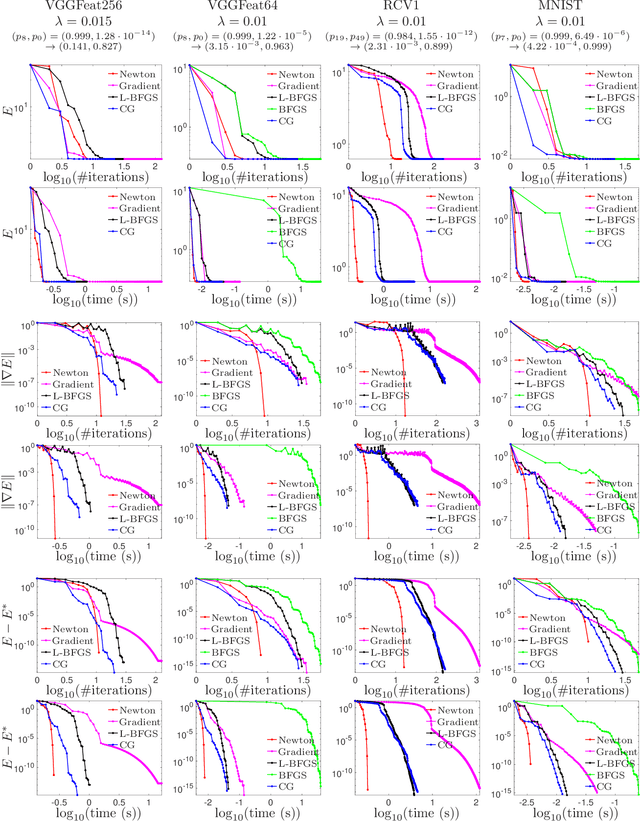
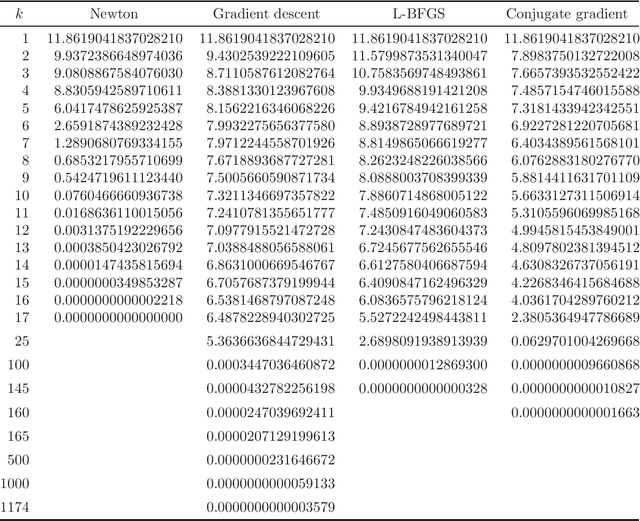
In recent years, a certain type of problems have become of interest where one wants to query a trained classifier. Specifically, one wants to find the closest instance to a given input instance such that the classifier's predicted label is changed in a desired way. Examples of these ``inverse classification'' problems are counterfactual explanations, adversarial examples and model inversion. All of them are fundamentally optimization problems over the input instance vector involving a fixed classifier, and it is of interest to achieve a fast solution for interactive or real-time applications. We focus on solving this problem efficiently for two of the most widely used classifiers: logistic regression and softmax classifiers. Owing to special properties of these models, we show that the optimization can be solved in closed form for logistic regression, and iteratively but extremely fast for the softmax classifier. This allows us to solve either case exactly (to nearly machine precision) in a runtime of milliseconds to around a second even for very high-dimensional instances and many classes.