 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetermination Of Structural Cracks Using Deep Learning Frameworks
Jul 03, 2025Structural crack detection is a critical task for public safety as it helps in preventing potential structural failures that could endanger lives. Manual detection by inexperienced personnel can be slow, inconsistent, and prone to human error, which may compromise the reliability of assessments. The current study addresses these challenges by introducing a novel deep-learning architecture designed to enhance the accuracy and efficiency of structural crack detection. In this research, various configurations of residual U-Net models were utilized. These models, due to their robustness in capturing fine details, were further integrated into an ensemble with a meta-model comprising convolutional blocks. This unique combination aimed to boost prediction efficiency beyond what individual models could achieve. The ensemble's performance was evaluated against well-established architectures such as SegNet and the traditional U-Net. Results demonstrated that the residual U-Net models outperformed their predecessors, particularly with low-resolution imagery, and the ensemble model exceeded the performance of individual models, proving it as the most effective. The assessment was based on the Intersection over Union (IoU) metric and DICE coefficient. The ensemble model achieved the highest scores, signifying superior accuracy. This advancement suggests way for more reliable automated systems in structural defects monitoring tasks.
Adversarial Text Generation with Dynamic Contextual Perturbation
Jun 10, 2025Adversarial attacks on Natural Language Processing (NLP) models expose vulnerabilities by introducing subtle perturbations to input text, often leading to misclassification while maintaining human readability. Existing methods typically focus on word-level or local text segment alterations, overlooking the broader context, which results in detectable or semantically inconsistent perturbations. We propose a novel adversarial text attack scheme named Dynamic Contextual Perturbation (DCP). DCP dynamically generates context-aware perturbations across sentences, paragraphs, and documents, ensuring semantic fidelity and fluency. Leveraging the capabilities of pre-trained language models, DCP iteratively refines perturbations through an adversarial objective function that balances the dual objectives of inducing model misclassification and preserving the naturalness of the text. This comprehensive approach allows DCP to produce more sophisticated and effective adversarial examples that better mimic natural language patterns. Our experimental results, conducted on various NLP models and datasets, demonstrate the efficacy of DCP in challenging the robustness of state-of-the-art NLP systems. By integrating dynamic contextual analysis, DCP significantly enhances the subtlety and impact of adversarial attacks. This study highlights the critical role of context in adversarial attacks and lays the groundwork for creating more robust NLP systems capable of withstanding sophisticated adversarial strategies.
* This is the accepted version of the paper, which was presented at IEEE CALCON. The conference was organized at Jadavpur University, Kolkata, from December 14 to 15, 2025. The paper is six pages long, and it consists of six tables and six figures. This is not the final camera-ready version of the paper
Minimally Supervised Hierarchical Domain Intent Learning for CRS
May 04, 2025



Modeling domain intent within an evolving domain structure presents a significant challenge for domain-specific conversational recommendation systems (CRS). The conventional approach involves training an intent model using utterance-intent pairs. However, as new intents and patterns emerge, the model must be continuously updated while preserving existing relationships and maintaining efficient retrieval. This process leads to substantial growth in utterance-intent pairs, making manual labeling increasingly costly and impractical. In this paper, we propose an efficient solution for constructing a dynamic hierarchical structure that minimizes the number of user utterances required to achieve adequate domain knowledge coverage. To this end, we introduce a neural network-based attention-driven hierarchical clustering algorithm designed to optimize intent grouping using minimal data. The proposed method builds upon and integrates concepts from two existing flat clustering algorithms DEC and NAM, both of which utilize neural attention mechanisms. We apply our approach to a curated subset of 44,000 questions from the business food domain. Experimental results demonstrate that constructing the hierarchy using a stratified sampling strategy significantly reduces the number of questions needed to represent the evolving intent structure. Our findings indicate that this approach enables efficient coverage of dynamic domain knowledge without frequent retraining, thereby enhancing scalability and adaptability in domain-specific CSRs.
MISCON: A Mission-Driven Conversational Consultant for Pre-Venture Entrepreneurs in Food Deserts
Jan 24, 2025This work-in-progress report describes MISCON, a conversational consultant being developed for a public mission project called NOURISH. With MISCON, aspiring small business owners in a food-insecure region and their advisors in Community-based organizations would be able to get information, recommendation and analysis regarding setting up food businesses. MISCON conversations are modeled as state machine that uses a heterogeneous knowledge graph as well as several analytical tools and services including a variety of LLMs. In this short report, we present the functional architecture and some design considerations behind MISCON.
A Comparative Study of Hyperparameter Tuning Methods
Aug 29, 2024The study emphasizes the challenge of finding the optimal trade-off between bias and variance, especially as hyperparameter optimization increases in complexity. Through empirical analysis, three hyperparameter tuning algorithms Tree-structured Parzen Estimator (TPE), Genetic Search, and Random Search are evaluated across regression and classification tasks. The results show that nonlinear models, with properly tuned hyperparameters, significantly outperform linear models. Interestingly, Random Search excelled in regression tasks, while TPE was more effective for classification tasks. This suggests that there is no one-size-fits-all solution, as different algorithms perform better depending on the task and model type. The findings underscore the importance of selecting the appropriate tuning method and highlight the computational challenges involved in optimizing machine learning models, particularly as search spaces expand.
Detecting Car Speed using Object Detection and Depth Estimation: A Deep Learning Framework
Aug 08, 2024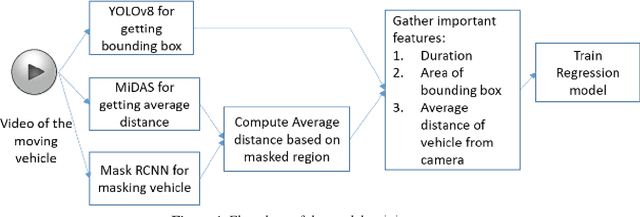
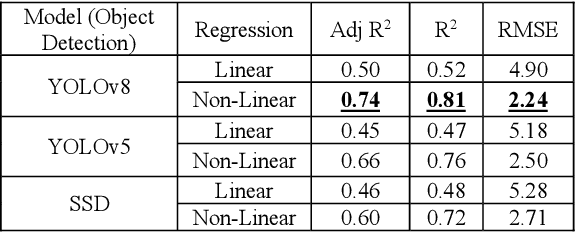


Road accidents are quite common in almost every part of the world, and, in majority, fatal accidents are attributed to over speeding of vehicles. The tendency to over speeding is usually tried to be controlled using check points at various parts of the road but not all traffic police have the device to check speed with existing speed estimating devices such as LIDAR based, or Radar based guns. The current project tries to address the issue of vehicle speed estimation with handheld devices such as mobile phones or wearable cameras with network connection to estimate the speed using deep learning frameworks.
Analyzing Consumer Reviews for Understanding Drivers of Hotels Ratings: An Indian Perspective
Aug 08, 2024



In the internet era, almost every business entity is trying to have its digital footprint in digital media and other social media platforms. For these entities, word of mouse is also very important. Particularly, this is quite crucial for the hospitality sector dealing with hotels, restaurants etc. Consumers do read other consumers reviews before making final decisions. This is where it becomes very important to understand which aspects are affecting most in the minds of the consumers while giving their ratings. The current study focuses on the consumer reviews of Indian hotels to extract aspects important for final ratings. The study involves gathering data using web scraping methods, analyzing the texts using Latent Dirichlet Allocation for topic extraction and sentiment analysis for aspect-specific sentiment mapping. Finally, it incorporates Random Forest to understand the importance of the aspects in predicting the final rating of a user.
Information Security and Privacy in the Digital World: Some Selected Topics
Mar 30, 2024



In the era of generative artificial intelligence and the Internet of Things, while there is explosive growth in the volume of data and the associated need for processing, analysis, and storage, several new challenges are faced in identifying spurious and fake information and protecting the privacy of sensitive data. This has led to an increasing demand for more robust and resilient schemes for authentication, integrity protection, encryption, non-repudiation, and privacy-preservation of data. The chapters in this book present some of the state-of-the-art research works in the field of cryptography and security in computing and communications.
V2CE: Video to Continuous Events Simulator
Sep 16, 2023



Dynamic Vision Sensor (DVS)-based solutions have recently garnered significant interest across various computer vision tasks, offering notable benefits in terms of dynamic range, temporal resolution, and inference speed. However, as a relatively nascent vision sensor compared to Active Pixel Sensor (APS) devices such as RGB cameras, DVS suffers from a dearth of ample labeled datasets. Prior efforts to convert APS data into events often grapple with issues such as a considerable domain shift from real events, the absence of quantified validation, and layering problems within the time axis. In this paper, we present a novel method for video-to-events stream conversion from multiple perspectives, considering the specific characteristics of DVS. A series of carefully designed losses helps enhance the quality of generated event voxels significantly. We also propose a novel local dynamic-aware timestamp inference strategy to accurately recover event timestamps from event voxels in a continuous fashion and eliminate the temporal layering problem. Results from rigorous validation through quantified metrics at all stages of the pipeline establish our method unquestionably as the current state-of-the-art (SOTA).
Portfolio Optimization: A Comparative Study
Jul 11, 2023



Portfolio optimization has been an area that has attracted considerable attention from the financial research community. Designing a profitable portfolio is a challenging task involving precise forecasting of future stock returns and risks. This chapter presents a comparative study of three portfolio design approaches, the mean-variance portfolio (MVP), hierarchical risk parity (HRP)-based portfolio, and autoencoder-based portfolio. These three approaches to portfolio design are applied to the historical prices of stocks chosen from ten thematic sectors listed on the National Stock Exchange (NSE) of India. The portfolios are designed using the stock price data from January 1, 2018, to December 31, 2021, and their performances are tested on the out-of-sample data from January 1, 2022, to December 31, 2022. Extensive results are analyzed on the performance of the portfolios. It is observed that the performance of the MVP portfolio is the best on the out-of-sample data for the risk-adjusted returns. However, the autoencoder portfolios outperformed their counterparts on annual returns.