 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Application of frozen large-scale models to multimodal task-oriented dialogue
Oct 02, 2023
In this study, we use the existing Large Language Models ENnhanced to See Framework (LENS Framework) to test the feasibility of multimodal task-oriented dialogues. The LENS Framework has been proposed as a method to solve computer vision tasks without additional training and with fixed parameters of pre-trained models. We used the Multimodal Dialogs (MMD) dataset, a multimodal task-oriented dialogue benchmark dataset from the fashion field, and for the evaluation, we used the ChatGPT-based G-EVAL, which only accepts textual modalities, with arrangements to handle multimodal data. Compared to Transformer-based models in previous studies, our method demonstrated an absolute lift of 10.8% in fluency, 8.8% in usefulness, and 5.2% in relevance and coherence. The results show that using large-scale models with fixed parameters rather than using models trained on a dataset from scratch improves performance in multimodal task-oriented dialogues. At the same time, we show that Large Language Models (LLMs) are effective for multimodal task-oriented dialogues. This is expected to lead to efficient applications to existing systems.
Scalable Multiuser Immersive Communications with Multi-numerology and Mini-slot
Sep 16, 2023This paper studies multiuser immersive communications networks in which different user equipment may demand various extended reality (XR) services. In such heterogeneous networks, time-frequency resource allocation needs to be more adaptive since XR services are usually multi-modal and latency-sensitive. To this end, we develop a scalable time-frequency resource allocation method based on multi-numerology and mini-slot. To appropriately determining the discrete parameters of multi-numerology and mini-slot for multiuser immersive communications, the proposed method first presents a novel flexible time-frequency resource block configuration, then it leverages the deep reinforcement learning to maximize the total quality-of-experience (QoE) under different users' QoE constraints. The results confirm the efficiency and scalability of the proposed time-frequency resource allocation method.
All Sizes Matter: Improving Volumetric Brain Segmentation on Small Lesions
Oct 04, 2023

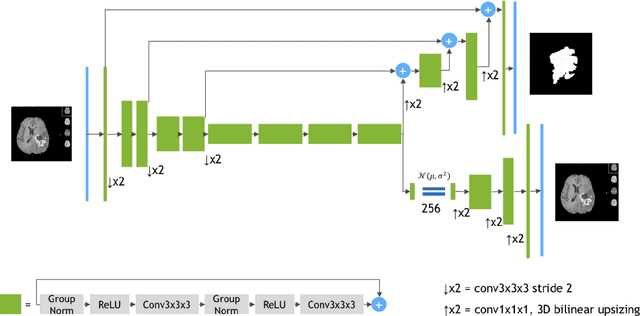

Brain metastases (BMs) are the most frequently occurring brain tumors. The treatment of patients having multiple BMs with stereo tactic radiosurgery necessitates accurate localization of the metastases. Neural networks can assist in this time-consuming and costly task that is typically performed by human experts. Particularly challenging is the detection of small lesions since they are often underrepresented in exist ing approaches. Yet, lesion detection is equally important for all sizes. In this work, we develop an ensemble of neural networks explicitly fo cused on detecting and segmenting small BMs. To accomplish this task, we trained several neural networks focusing on individual aspects of the BM segmentation problem: We use blob loss that specifically addresses the imbalance of lesion instances in terms of size and texture and is, therefore, not biased towards larger lesions. In addition, a model using a subtraction sequence between the T1 and T1 contrast-enhanced sequence focuses on low-contrast lesions. Furthermore, we train additional models only on small lesions. Our experiments demonstrate the utility of the ad ditional blob loss and the subtraction sequence. However, including the specialized small lesion models in the ensemble deteriorates segmentation results. We also find domain-knowledge-inspired postprocessing steps to drastically increase our performance in most experiments. Our approach enables us to submit a competitive challenge entry to the ASNR-MICCAI BraTS Brain Metastasis Challenge 2023.
Progressive reduced order modeling: empowering data-driven modeling with selective knowledge transfer
Oct 04, 2023Data-driven modeling can suffer from a constant demand for data, leading to reduced accuracy and impractical for engineering applications due to the high cost and scarcity of information. To address this challenge, we propose a progressive reduced order modeling framework that minimizes data cravings and enhances data-driven modeling's practicality. Our approach selectively transfers knowledge from previously trained models through gates, similar to how humans selectively use valuable knowledge while ignoring unuseful information. By filtering relevant information from previous models, we can create a surrogate model with minimal turnaround time and a smaller training set that can still achieve high accuracy. We have tested our framework in several cases, including transport in porous media, gravity-driven flow, and finite deformation in hyperelastic materials. Our results illustrate that retaining information from previous models and utilizing a valuable portion of that knowledge can significantly improve the accuracy of the current model. We have demonstrated the importance of progressive knowledge transfer and its impact on model accuracy with reduced training samples. For instance, our framework with four parent models outperforms the no-parent counterpart trained on data nine times larger. Our research unlocks data-driven modeling's potential for practical engineering applications by mitigating the data scarcity issue. Our proposed framework is a significant step toward more efficient and cost-effective data-driven modeling, fostering advancements across various fields.
Practical, Private Assurance of the Value of Collaboration
Oct 04, 2023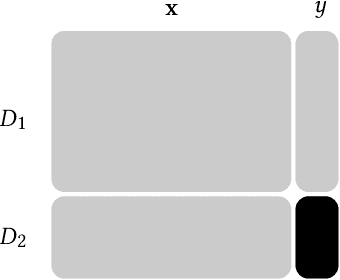
Two parties wish to collaborate on their datasets. However, before they reveal their datasets to each other, the parties want to have the guarantee that the collaboration would be fruitful. We look at this problem from the point of view of machine learning, where one party is promised an improvement on its prediction model by incorporating data from the other party. The parties would only wish to collaborate further if the updated model shows an improvement in accuracy. Before this is ascertained, the two parties would not want to disclose their models and datasets. In this work, we construct an interactive protocol for this problem based on the fully homomorphic encryption scheme over the Torus (TFHE) and label differential privacy, where the underlying machine learning model is a neural network. Label differential privacy is used to ensure that computations are not done entirely in the encrypted domain, which is a significant bottleneck for neural network training according to the current state-of-the-art FHE implementations. We prove the security of our scheme in the universal composability framework assuming honest-but-curious parties, but where one party may not have any expertise in labelling its initial dataset. Experiments show that we can obtain the output, i.e., the accuracy of the updated model, with time many orders of magnitude faster than a protocol using entirely FHE operations.
HappyFeat -- An interactive and efficient BCI framework for clinical applications
Oct 04, 2023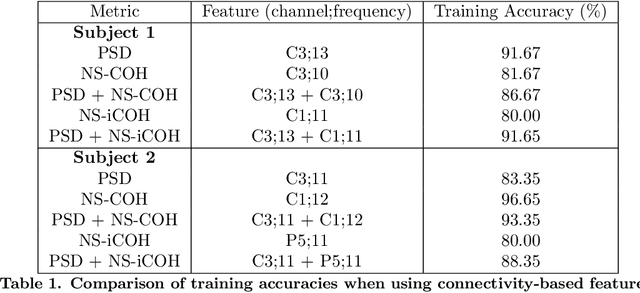
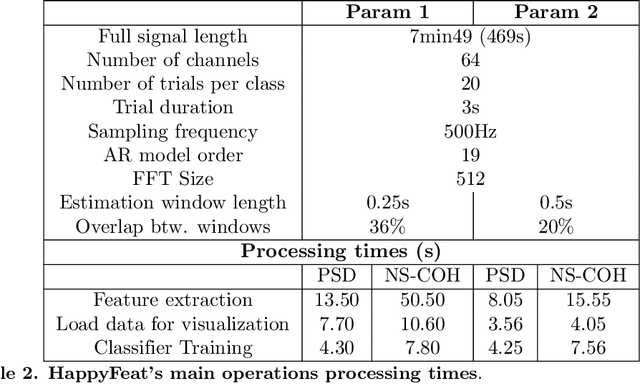
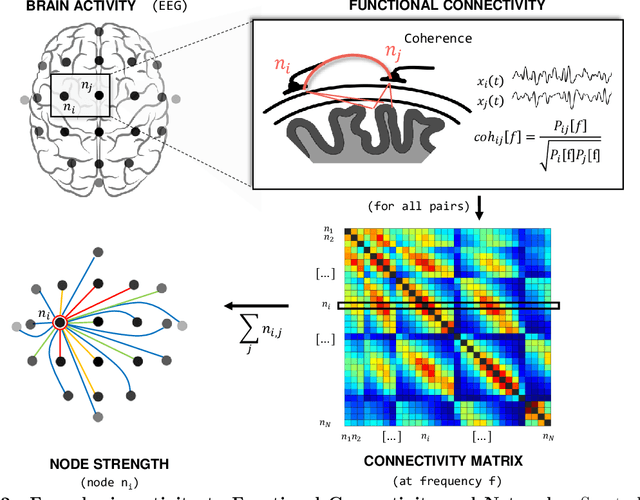
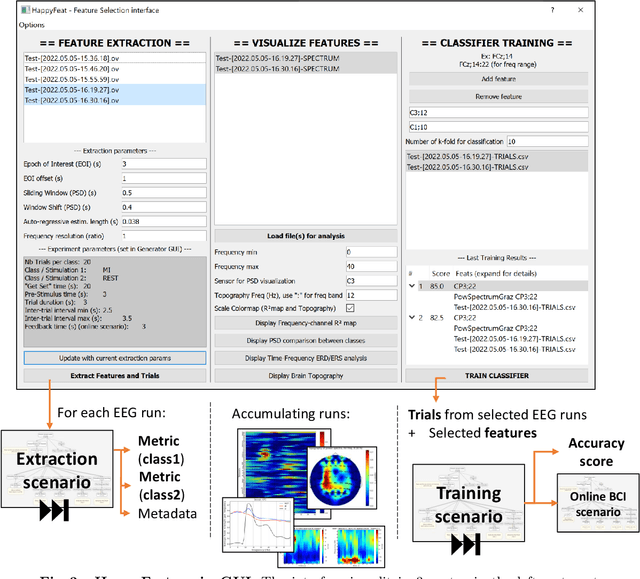
Brain-Computer Interface (BCI) systems allow users to perform actions by translating their brain activity into commands. Such systems usually need a training phase, consisting in training a classification algorithm to discriminate between mental states using specific features from the recorded signals. This phase of feature selection and training is crucial for BCI performance and presents specific constraints to be met in a clinical context, such as post-stroke rehabilitation. In this paper, we present HappyFeat, a software making Motor Imagery (MI) based BCI experiments easier, by gathering all necessary manipulations and analysis in a single convenient GUI and via automation of experiment or analysis parameters. The resulting workflow allows for effortlessly selecting the best features, helping to achieve good BCI performance in time-constrained environments. Alternative features based on Functional Connectivity can be used and compared or combined with Power Spectral Density, allowing a network-oriented approach. We then give details of HappyFeat's main mechanisms, and a review of its performances in typical use cases. We also show that it can be used as an efficient tool for comparing different metrics extracted from the signals, to train the classification algorithm. To this end, we show a comparison between the commonly-used Power Spectral Density and network metrics based on Functional Connectivity. HappyFeat is available as an open-source project which can be freely downloaded on GitHub.
Unwieldy Object Delivery with Nonholonomic Mobile Base: A Stable Pushing Approach
Sep 25, 2023
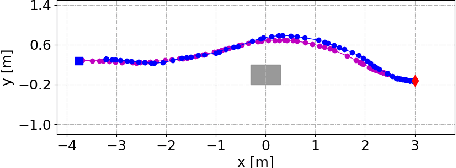


This paper addresses the problem of pushing manipulation with nonholonomic mobile robots. Pushing is a fundamental skill that enables robots to move unwieldy objects that cannot be grasped. We propose a stable pushing method that maintains stiff contact between the robot and the object to avoid consuming repositioning actions. We prove that a line contact, rather than a single point contact, is necessary for nonholonomic robots to achieve stable pushing. We also show that the stable pushing constraint and the nonholonomic constraint of the robot can be simplified as a concise linear motion constraint. Then the pushing planning problem can be formulated as a constrained optimization problem using nonlinear model predictive control (NMPC). According to the experiments, our NMPC-based planner outperforms a reactive pushing strategy in terms of efficiency, reducing the robot's traveled distance by 23.8\% and time by 77.4\%. Furthermore, our method requires four fewer hyperparameters and decision variables than the Linear Time-Varying (LTV) MPC approach, making it easier to implement. Real-world experiments are carried out to validate the proposed method with two differential-drive robots, Husky and Boxer, under different friction conditions.
OceanNet: A principled neural operator-based digital twin for regional oceans
Oct 01, 2023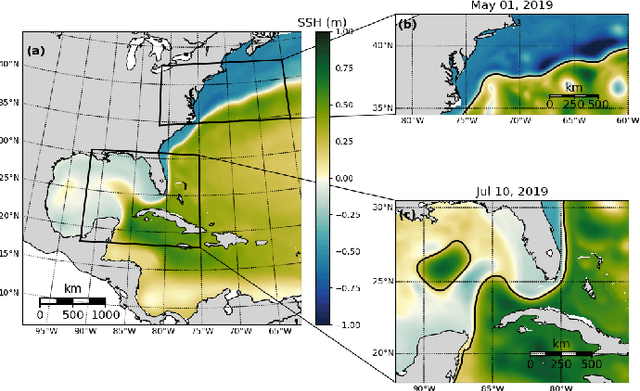
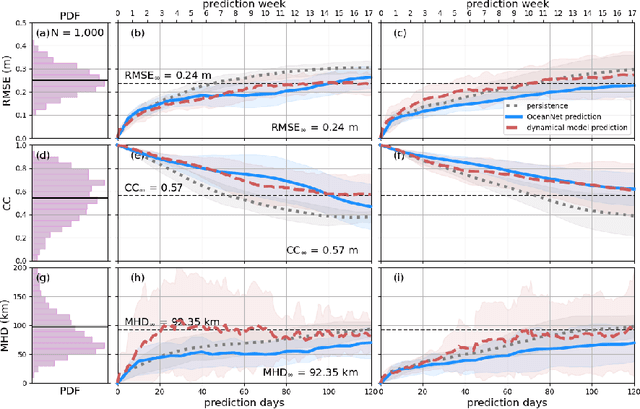
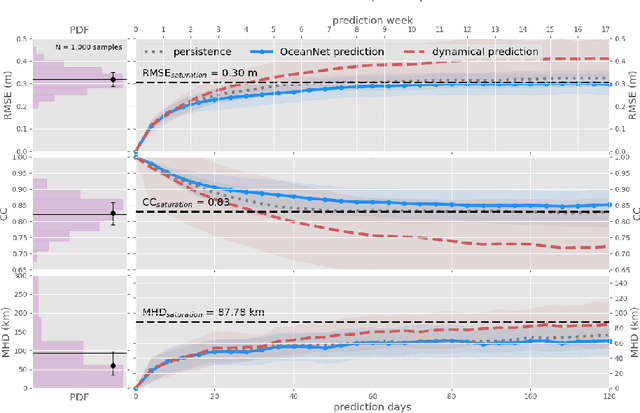
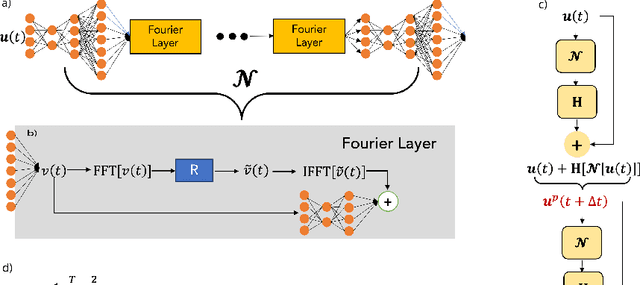
While data-driven approaches demonstrate great potential in atmospheric modeling and weather forecasting, ocean modeling poses distinct challenges due to complex bathymetry, land, vertical structure, and flow non-linearity. This study introduces OceanNet, a principled neural operator-based digital twin for ocean circulation. OceanNet uses a Fourier neural operator and predictor-evaluate-corrector integration scheme to mitigate autoregressive error growth and enhance stability over extended time scales. A spectral regularizer counteracts spectral bias at smaller scales. OceanNet is applied to the northwest Atlantic Ocean western boundary current (the Gulf Stream), focusing on the task of seasonal prediction for Loop Current eddies and the Gulf Stream meander. Trained using historical sea surface height (SSH) data, OceanNet demonstrates competitive forecast skill by outperforming SSH predictions by an uncoupled, state-of-the-art dynamical ocean model forecast, reducing computation by 500,000 times. These accomplishments demonstrate the potential of physics-inspired deep neural operators as cost-effective alternatives to high-resolution numerical ocean models.
Quantum generative adversarial learning in photonics
Oct 01, 2023Quantum Generative Adversarial Networks (QGANs), an intersection of quantum computing and machine learning, have attracted widespread attention due to their potential advantages over classical analogs. However, in the current era of Noisy Intermediate-Scale Quantum (NISQ) computing, it is essential to investigate whether QGANs can perform learning tasks on near-term quantum devices usually affected by noise and even defects. In this Letter, using a programmable silicon quantum photonic chip, we experimentally demonstrate the QGAN model in photonics for the first time, and investigate the effects of noise and defects on its performance. Our results show that QGANs can generate high-quality quantum data with a fidelity higher than 90\%, even under conditions where up to half of the generator's phase shifters are damaged, or all of the generator and discriminator's phase shifters are subjected to phase noise up to 0.04$\pi$. Our work sheds light on the feasibility of implementing QGANs on NISQ-era quantum hardware.
Identifying Representations for Intervention Extrapolation
Oct 06, 2023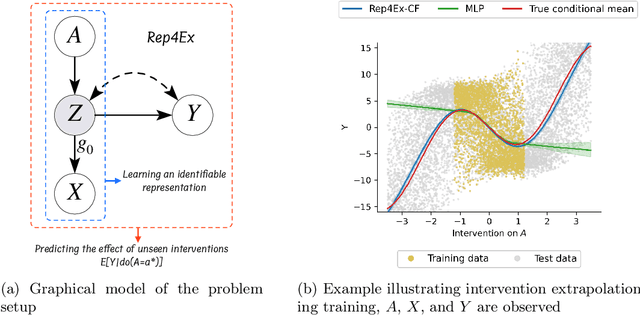
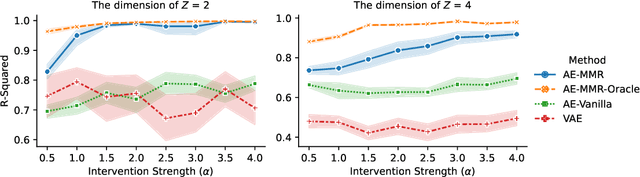
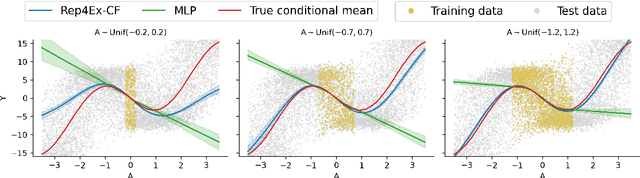
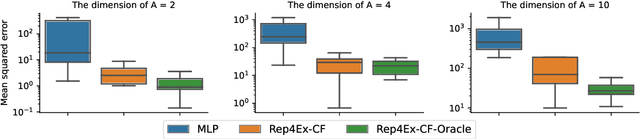
The premise of identifiable and causal representation learning is to improve the current representation learning paradigm in terms of generalizability or robustness. Despite recent progress in questions of identifiability, more theoretical results demonstrating concrete advantages of these methods for downstream tasks are needed. In this paper, we consider the task of intervention extrapolation: predicting how interventions affect an outcome, even when those interventions are not observed at training time, and show that identifiable representations can provide an effective solution to this task even if the interventions affect the outcome non-linearly. Our setup includes an outcome Y, observed features X, which are generated as a non-linear transformation of latent features Z, and exogenous action variables A, which influence Z. The objective of intervention extrapolation is to predict how interventions on A that lie outside the training support of A affect Y. Here, extrapolation becomes possible if the effect of A on Z is linear and the residual when regressing Z on A has full support. As Z is latent, we combine the task of intervention extrapolation with identifiable representation learning, which we call Rep4Ex: we aim to map the observed features X into a subspace that allows for non-linear extrapolation in A. We show using Wiener's Tauberian theorem that the hidden representation is identifiable up to an affine transformation in Z-space, which is sufficient for intervention extrapolation. The identifiability is characterized by a novel constraint describing the linearity assumption of A on Z. Based on this insight, we propose a method that enforces the linear invariance constraint and can be combined with any type of autoencoder. We validate our theoretical findings through synthetic experiments and show that our approach succeeds in predicting the effects of unseen interventions.