 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Holistic Parking Slot Detection with Polygon-Shaped Representations
Oct 17, 2023
Current parking slot detection in advanced driver-assistance systems (ADAS) primarily relies on ultrasonic sensors. This method has several limitations such as the need to scan the entire parking slot before detecting it, the incapacity of detecting multiple slots in a row, and the difficulty of classifying them. Due to the complex visual environment, vehicles are equipped with surround view camera systems to detect vacant parking slots. Previous research works in this field mostly use image-domain models to solve the problem. These two-stage approaches separate the 2D detection and 3D pose estimation steps using camera calibration. In this paper, we propose one-step Holistic Parking Slot Network (HPS-Net), a tailor-made adaptation of the You Only Look Once (YOLO)v4 algorithm. This camera-based approach directly outputs the four vertex coordinates of the parking slot in topview domain, instead of a bounding box in raw camera images. Several visible points and shapes can be proposed from different angles. A novel regression loss function named polygon-corner Generalized Intersection over Union (GIoU) for polygon vertex position optimization is also proposed to manage the slot orientation and to distinguish the entrance line. Experiments show that HPS-Net can detect various vacant parking slots with a F1-score of 0.92 on our internal Valeo Parking Slots Dataset (VPSD) and 0.99 on the public dataset PS2.0. It provides a satisfying generalization and robustness in various parking scenarios, such as indoor (F1: 0.86) or paved ground (F1: 0.91). Moreover, it achieves a real-time detection speed of 17 FPS on Nvidia Drive AGX Xavier. A demo video can be found at https://streamable.com/75j7sj.
Sparse-DySta: Sparsity-Aware Dynamic and Static Scheduling for Sparse Multi-DNN Workloads
Oct 17, 2023
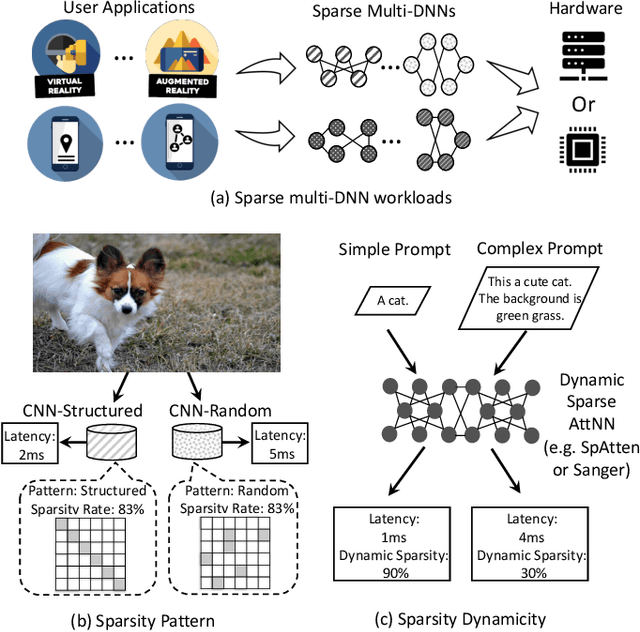


Running multiple deep neural networks (DNNs) in parallel has become an emerging workload in both edge devices, such as mobile phones where multiple tasks serve a single user for daily activities, and data centers, where various requests are raised from millions of users, as seen with large language models. To reduce the costly computational and memory requirements of these workloads, various efficient sparsification approaches have been introduced, resulting in widespread sparsity across different types of DNN models. In this context, there is an emerging need for scheduling sparse multi-DNN workloads, a problem that is largely unexplored in previous literature. This paper systematically analyses the use-cases of multiple sparse DNNs and investigates the opportunities for optimizations. Based on these findings, we propose Dysta, a novel bi-level dynamic and static scheduler that utilizes both static sparsity patterns and dynamic sparsity information for the sparse multi-DNN scheduling. Both static and dynamic components of Dysta are jointly designed at the software and hardware levels, respectively, to improve and refine the scheduling approach. To facilitate future progress in the study of this class of workloads, we construct a public benchmark that contains sparse multi-DNN workloads across different deployment scenarios, spanning from mobile phones and AR/VR wearables to data centers. A comprehensive evaluation on the sparse multi-DNN benchmark demonstrates that our proposed approach outperforms the state-of-the-art methods with up to 10% decrease in latency constraint violation rate and nearly 4X reduction in average normalized turnaround time. Our artifacts and code are publicly available at: https://github.com/SamsungLabs/Sparse-Multi-DNN-Scheduling.
Adaptive mitigation of time-varying quantum noise
Aug 16, 2023Current quantum computers suffer from non-stationary noise channels with high error rates, which undermines their reliability and reproducibility. We propose a Bayesian inference-based adaptive algorithm that can learn and mitigate quantum noise in response to changing channel conditions. Our study emphasizes the need for dynamic inference of critical channel parameters to improve program accuracy. We use the Dirichlet distribution to model the stochasticity of the Pauli channel. This allows us to perform Bayesian inference, which can improve the performance of probabilistic error cancellation (PEC) under time-varying noise. Our work demonstrates the importance of characterizing and mitigating temporal variations in quantum noise, which is crucial for developing more accurate and reliable quantum technologies. Our results show that Bayesian PEC can outperform non-adaptive approaches by a factor of 4.5x when measured using Hellinger distance from the ideal distribution.
Learning to Receive Help: Intervention-Aware Concept Embedding Models
Sep 29, 2023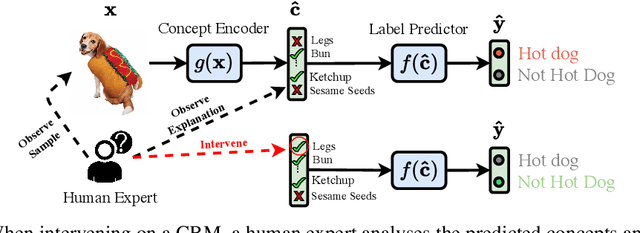
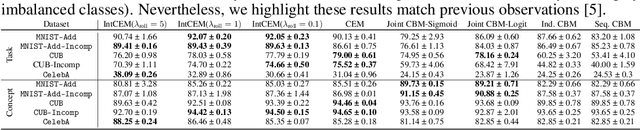
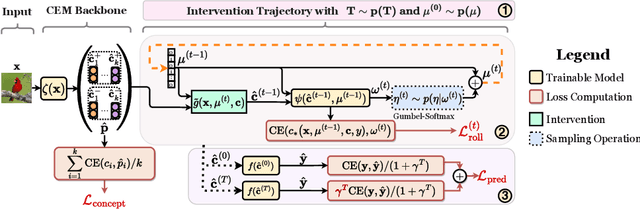
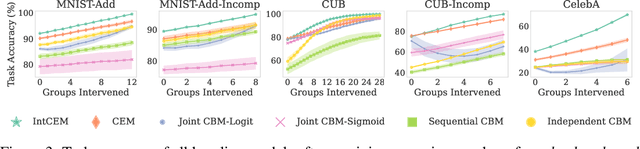
Concept Bottleneck Models (CBMs) tackle the opacity of neural architectures by constructing and explaining their predictions using a set of high-level concepts. A special property of these models is that they permit concept interventions, wherein users can correct mispredicted concepts and thus improve the model's performance. Recent work, however, has shown that intervention efficacy can be highly dependent on the order in which concepts are intervened on and on the model's architecture and training hyperparameters. We argue that this is rooted in a CBM's lack of train-time incentives for the model to be appropriately receptive to concept interventions. To address this, we propose Intervention-aware Concept Embedding models (IntCEMs), a novel CBM-based architecture and training paradigm that improves a model's receptiveness to test-time interventions. Our model learns a concept intervention policy in an end-to-end fashion from where it can sample meaningful intervention trajectories at train-time. This conditions IntCEMs to effectively select and receive concept interventions when deployed at test-time. Our experiments show that IntCEMs significantly outperform state-of-the-art concept-interpretable models when provided with test-time concept interventions, demonstrating the effectiveness of our approach.
Multidimensional Hopfield Networks for clustering
Oct 11, 2023We present the Multidimensional Hopfield Network (DHN), a natural generalisation of the Hopfield Network. In our theoretical investigations we focus on DHNs with a certain activation function and provide energy functions for them. We conclude that these DHNs are convergent in finite time, and are equivalent to greedy methods that aim to find graph clusterings of locally minimal cuts. We also show that the general framework of DHNs encapsulates several previously known algorithms used for generating graph embeddings and clusterings. Namely, the Cleora graph embedding algorithm, the Louvain method, and the Newmans method can be cast as DHNs with appropriate activation function and update rule. Motivated by these findings we provide a generalisation of Newmans method to the multidimensional case.
Learning bounded-degree polytrees with known skeleton
Oct 10, 2023We establish finite-sample guarantees for efficient proper learning of bounded-degree polytrees, a rich class of high-dimensional probability distributions and a subclass of Bayesian networks, a widely-studied type of graphical model. Recently, Bhattacharyya et al. (2021) obtained finite-sample guarantees for recovering tree-structured Bayesian networks, i.e., 1-polytrees. We extend their results by providing an efficient algorithm which learns $d$-polytrees in polynomial time and sample complexity for any bounded $d$ when the underlying undirected graph (skeleton) is known. We complement our algorithm with an information-theoretic sample complexity lower bound, showing that the dependence on the dimension and target accuracy parameters are nearly tight.
Recognition of Heat-Induced Food State Changes by Time-Series Use of Vision-Language Model for Cooking Robot
Sep 06, 2023Cooking tasks are characterized by large changes in the state of the food, which is one of the major challenges in robot execution of cooking tasks. In particular, cooking using a stove to apply heat to the foodstuff causes many special state changes that are not seen in other tasks, making it difficult to design a recognizer. In this study, we propose a unified method for recognizing changes in the cooking state of robots by using the vision-language model that can discriminate open-vocabulary objects in a time-series manner. We collected data on four typical state changes in cooking using a real robot and confirmed the effectiveness of the proposed method. We also compared the conditions and discussed the types of natural language prompts and the image regions that are suitable for recognizing the state changes.
Implementation of digital MemComputing using standard electronic components
Oct 03, 2023Digital MemComputing machines (DMMs), which employ nonlinear dynamical systems with memory (time non-locality), have proven to be a robust and scalable unconventional computing approach for solving a wide variety of combinatorial optimization problems. However, most of the research so far has focused on the numerical simulations of the equations of motion of DMMs. This inevitably subjects time to discretization, which brings its own (numerical) issues that would be absent in actual physical systems operating in continuous time. Although hardware realizations of DMMs have been previously suggested, their implementation would require materials and devices that are not so easy to integrate with traditional electronics. In this study, we propose a novel hardware design for DMMs that leverages only conventional electronic components. Our findings suggest that this design offers a marked improvement in speed compared to existing realizations of these machines, without requiring special materials or novel device concepts. We also show that these DMMs are robust against additive noise. Moreover, the absence of numerical noise promises enhanced stability over extended periods of the machines' operation, paving the way for addressing even more complex problems.
Improving style transfer in dynamic contrast enhanced MRI using a spatio-temporal approach
Oct 03, 2023Style transfer in DCE-MRI is a challenging task due to large variations in contrast enhancements across different tissues and time. Current unsupervised methods fail due to the wide variety of contrast enhancement and motion between the images in the series. We propose a new method that combines autoencoders to disentangle content and style with convolutional LSTMs to model predicted latent spaces along time and adaptive convolutions to tackle the localised nature of contrast enhancement. To evaluate our method, we propose a new metric that takes into account the contrast enhancement. Qualitative and quantitative analyses show that the proposed method outperforms the state of the art on two different datasets.
Towards Free Data Selection with General-Purpose Models
Oct 14, 2023

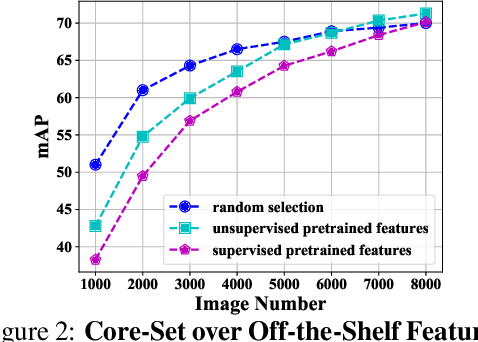
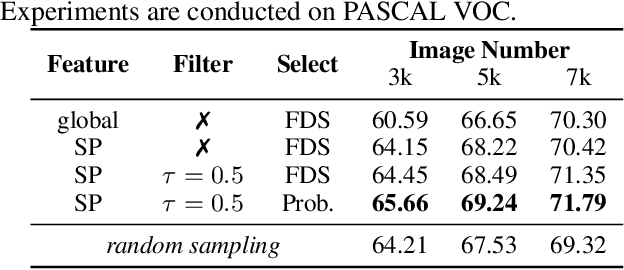
A desirable data selection algorithm can efficiently choose the most informative samples to maximize the utility of limited annotation budgets. However, current approaches, represented by active learning methods, typically follow a cumbersome pipeline that iterates the time-consuming model training and batch data selection repeatedly. In this paper, we challenge this status quo by designing a distinct data selection pipeline that utilizes existing general-purpose models to select data from various datasets with a single-pass inference without the need for additional training or supervision. A novel free data selection (FreeSel) method is proposed following this new pipeline. Specifically, we define semantic patterns extracted from inter-mediate features of the general-purpose model to capture subtle local information in each image. We then enable the selection of all data samples in a single pass through distance-based sampling at the fine-grained semantic pattern level. FreeSel bypasses the heavy batch selection process, achieving a significant improvement in efficiency and being 530x faster than existing active learning methods. Extensive experiments verify the effectiveness of FreeSel on various computer vision tasks. Our code is available at https://github.com/yichen928/FreeSel.