 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time Series Analysis": models, code, and papers
Augmented Bilinear Network for Incremental Multi-Stock Time-Series Classification
Jul 23, 2022
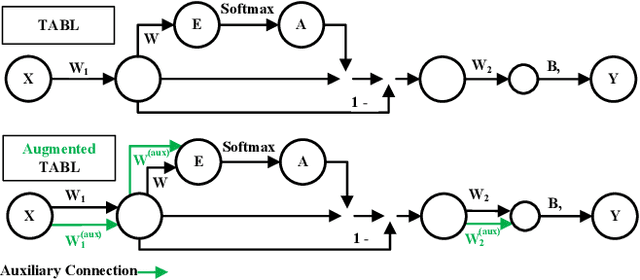
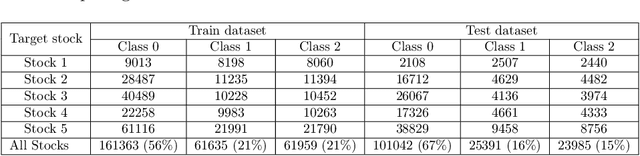
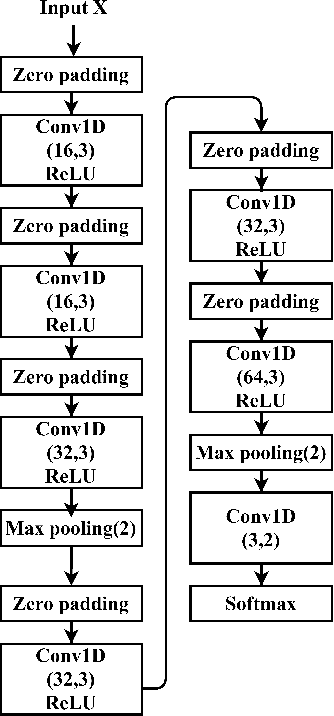
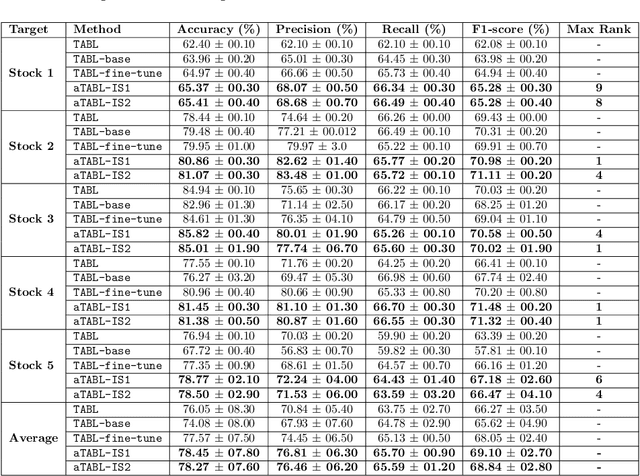
Deep Learning models have become dominant in tackling financial time-series analysis problems, overturning conventional machine learning and statistical methods. Most often, a model trained for one market or security cannot be directly applied to another market or security due to differences inherent in the market conditions. In addition, as the market evolves through time, it is necessary to update the existing models or train new ones when new data is made available. This scenario, which is inherent in most financial forecasting applications, naturally raises the following research question: How to efficiently adapt a pre-trained model to a new set of data while retaining performance on the old data, especially when the old data is not accessible? In this paper, we propose a method to efficiently retain the knowledge available in a neural network pre-trained on a set of securities and adapt it to achieve high performance in new ones. In our method, the prior knowledge encoded in a pre-trained neural network is maintained by keeping existing connections fixed, and this knowledge is adjusted for the new securities by a set of augmented connections, which are optimized using the new data. The auxiliary connections are constrained to be of low rank. This not only allows us to rapidly optimize for the new task but also reduces the storage and run-time complexity during the deployment phase. The efficiency of our approach is empirically validated in the stock mid-price movement prediction problem using a large-scale limit order book dataset. Experimental results show that our approach enhances prediction performance as well as reduces the overall number of network parameters.
Hierarchical Clustering using Auto-encoded Compact Representation for Time-series Analysis
Jan 11, 2021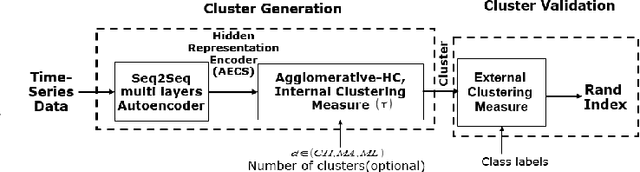
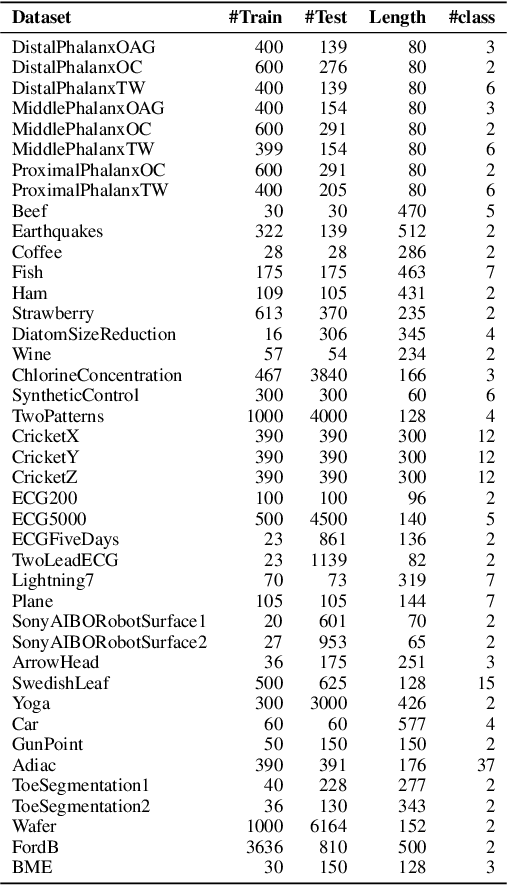
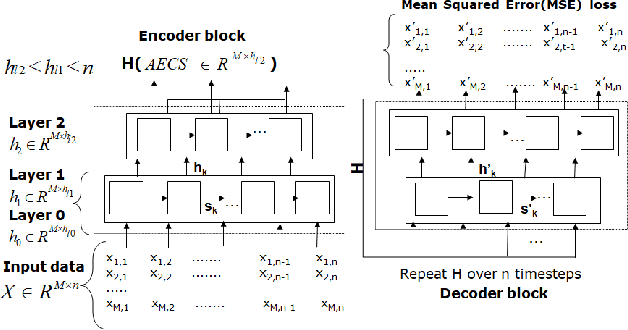
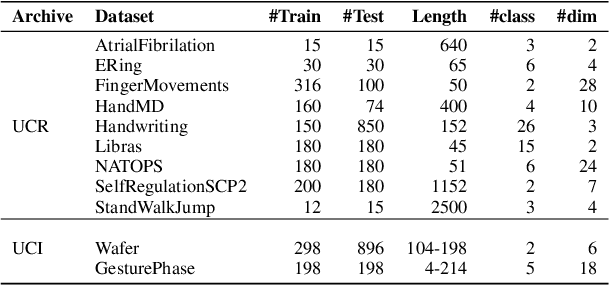
Getting a robust time-series clustering with best choice of distance measure and appropriate representation is always a challenge. We propose a novel mechanism to identify the clusters combining learned compact representation of time-series, Auto Encoded Compact Sequence (AECS) and hierarchical clustering approach. Proposed algorithm aims to address the large computing time issue of hierarchical clustering as learned latent representation AECS has a length much less than the original length of time-series and at the same time want to enhance its performance.Our algorithm exploits Recurrent Neural Network (RNN) based under complete Sequence to Sequence(seq2seq) autoencoder and agglomerative hierarchical clustering with a choice of best distance measure to recommend the best clustering. Our scheme selects the best distance measure and corresponding clustering for both univariate and multivariate time-series. We have experimented with real-world time-series from UCR and UCI archive taken from diverse application domains like health, smart-city, manufacturing etc. Experimental results show that proposed method not only produce close to benchmark results but also in some cases outperform the benchmark.
SentimentArcs: A Novel Method for Self-Supervised Sentiment Analysis of Time Series Shows SOTA Transformers Can Struggle Finding Narrative Arcs
Oct 18, 2021
SOTA Transformer and DNN short text sentiment classifiers report over 97% accuracy on narrow domains like IMDB movie reviews. Real-world performance is significantly lower because traditional models overfit benchmarks and generalize poorly to different or more open domain texts. This paper introduces SentimentArcs, a new self-supervised time series sentiment analysis methodology that addresses the two main limitations of traditional supervised sentiment analysis: limited labeled training datasets and poor generalization. A large ensemble of diverse models provides a synthetic ground truth for self-supervised learning. Novel metrics jointly optimize an exhaustive search across every possible corpus:model combination. The joint optimization over both the corpus and model solves the generalization problem. Simple visualizations exploit the temporal structure in narratives so domain experts can quickly spot trends, identify key features, and note anomalies over hundreds of arcs and millions of data points. To our knowledge, this is the first self-supervised method for time series sentiment analysis and the largest survey directly comparing real-world model performance on long-form narratives.
ASAT: Adaptively Scaled Adversarial Training in Time Series
Aug 20, 2021

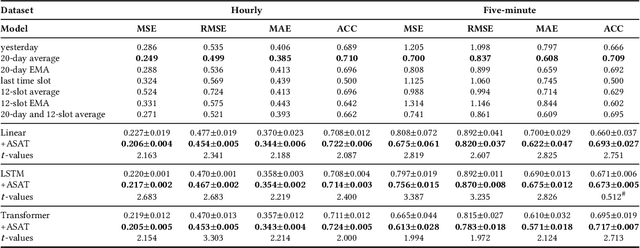

Adversarial training is a method for enhancing neural networks to improve the robustness against adversarial examples. Besides the security concerns of potential adversarial examples, adversarial training can also improve the performance of the neural networks, train robust neural networks, and provide interpretability for neural networks. In this work, we take the first step to introduce adversarial training in time series analysis by taking the finance field as an example. Rethinking existing researches of adversarial training, we propose the adaptively scaled adversarial training (ASAT) in time series analysis, by treating data at different time slots with time-dependent importance weights. Experimental results show that the proposed ASAT can improve both the accuracy and the adversarial robustness of neural networks. Besides enhancing neural networks, we also propose the dimension-wise adversarial sensitivity indicator to probe the sensitivities and importance of input dimensions. With the proposed indicator, we can explain the decision bases of black box neural networks.
Neural Ordinary Differential Equation Model for Evolutionary Subspace Clustering and Its Applications
Jul 22, 2021
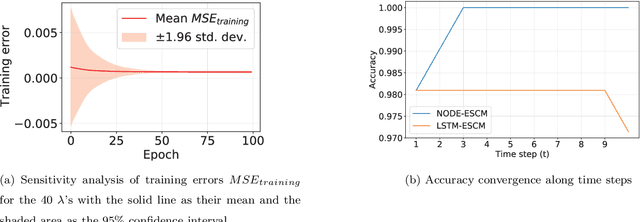
The neural ordinary differential equation (neural ODE) model has attracted increasing attention in time series analysis for its capability to process irregular time steps, i.e., data are not observed over equally-spaced time intervals. In multi-dimensional time series analysis, a task is to conduct evolutionary subspace clustering, aiming at clustering temporal data according to their evolving low-dimensional subspace structures. Many existing methods can only process time series with regular time steps while time series are unevenly sampled in many situations such as missing data. In this paper, we propose a neural ODE model for evolutionary subspace clustering to overcome this limitation and a new objective function with subspace self-expressiveness constraint is introduced. We demonstrate that this method can not only interpolate data at any time step for the evolutionary subspace clustering task, but also achieve higher accuracy than other state-of-the-art evolutionary subspace clustering methods. Both synthetic and real-world data are used to illustrate the efficacy of our proposed method.
Unsupervised Anomaly Detection in Time-series: An Extensive Evaluation and Analysis of State-of-the-art Methods
Dec 06, 2022
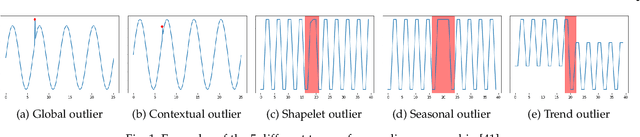
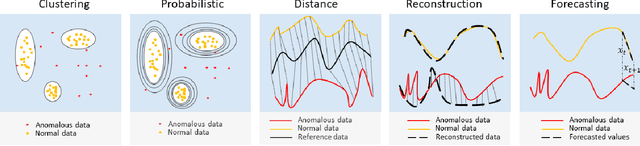
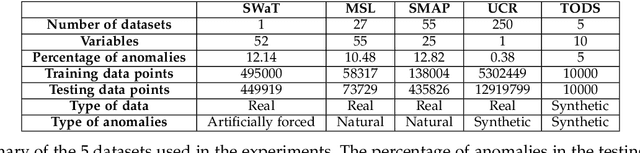
Unsupervised anomaly detection in time-series has been extensively investigated in the literature. Notwithstanding the relevance of this topic in numerous application fields, a complete and extensive evaluation of recent state-of-the-art techniques is still missing. Few efforts have been made to compare existing unsupervised time-series anomaly detection methods rigorously. However, only standard performance metrics, namely precision, recall, and F1-score are usually considered. Essential aspects for assessing their practical relevance are therefore neglected. This paper proposes an original and in-depth evaluation study of recent unsupervised anomaly detection techniques in time-series. Instead of relying solely on standard performance metrics, additional yet informative metrics and protocols are taken into account. In particular, (1) more elaborate performance metrics specifically tailored for time-series are used; (2) the model size and the model stability are studied; (3) an analysis of the tested approaches with respect to the anomaly type is provided; and (4) a clear and unique protocol is followed for all experiments. Overall, this extensive analysis aims to assess the maturity of state-of-the-art time-series anomaly detection, give insights regarding their applicability under real-world setups and provide to the community a more complete evaluation protocol.
pyWATTS: Python Workflow Automation Tool for Time Series
Jun 18, 2021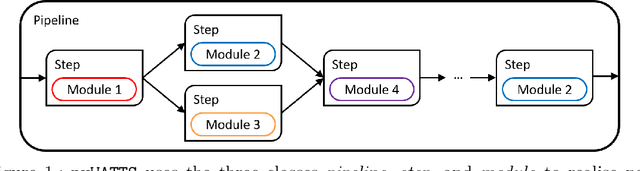
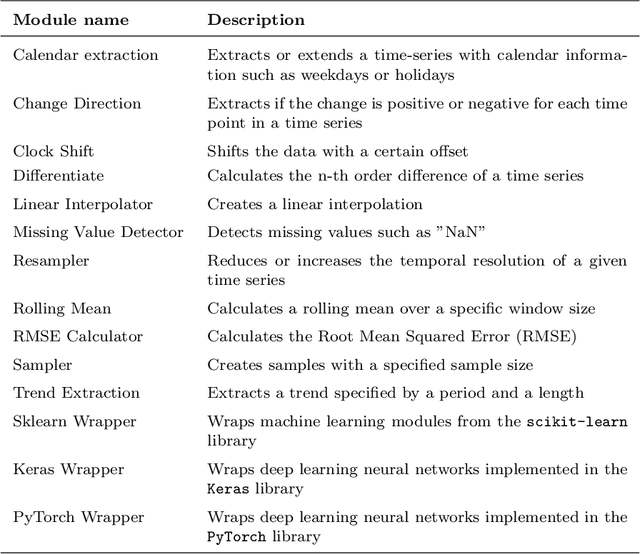
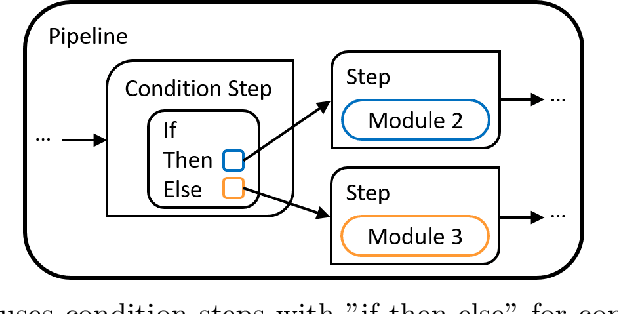
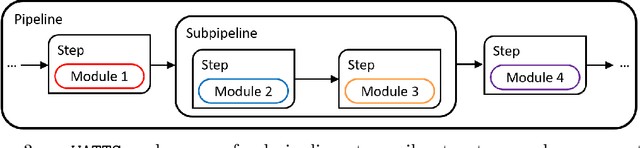
Time series data are fundamental for a variety of applications, ranging from financial markets to energy systems. Due to their importance, the number and complexity of tools and methods used for time series analysis is constantly increasing. However, due to unclear APIs and a lack of documentation, researchers struggle to integrate them into their research projects and replicate results. Additionally, in time series analysis there exist many repetitive tasks, which are often re-implemented for each project, unnecessarily costing time. To solve these problems we present \texttt{pyWATTS}, an open-source Python-based package that is a non-sequential workflow automation tool for the analysis of time series data. pyWATTS includes modules with clearly defined interfaces to enable seamless integration of new or existing methods, subpipelining to easily reproduce repetitive tasks, load and save functionality to simply replicate results, and native support for key Python machine learning libraries such as scikit-learn, PyTorch, and Keras.
Learning to Reconstruct Missing Data from Spatiotemporal Graphs with Sparse Observations
May 26, 2022
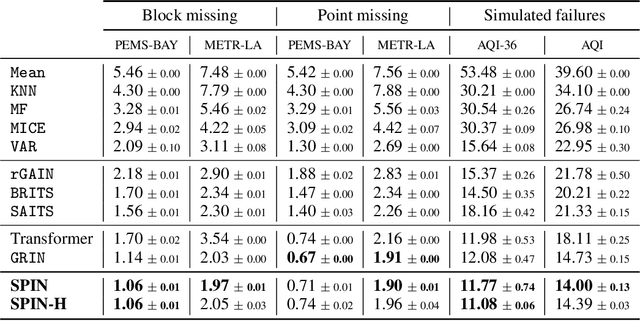
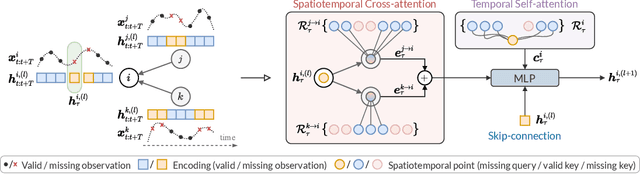
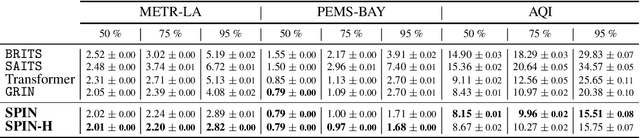
Modeling multivariate time series as temporal signals over a (possibly dynamic) graph is an effective representational framework that allows for developing models for time series analysis. In fact, discrete sequences of graphs can be processed by autoregressive graph neural networks to recursively learn representations at each discrete point in time and space. Spatiotemporal graphs are often highly sparse, with time series characterized by multiple, concurrent, and even long sequences of missing data, e.g., due to the unreliable underlying sensor network. In this context, autoregressive models can be brittle and exhibit unstable learning dynamics. The objective of this paper is, then, to tackle the problem of learning effective models to reconstruct, i.e., impute, missing data points by conditioning the reconstruction only on the available observations. In particular, we propose a novel class of attention-based architectures that, given a set of highly sparse discrete observations, learn a representation for points in time and space by exploiting a spatiotemporal diffusion architecture aligned with the imputation task. Representations are trained end-to-end to reconstruct observations w.r.t. the corresponding sensor and its neighboring nodes. Compared to the state of the art, our model handles sparse data without propagating prediction errors or requiring a bidirectional model to encode forward and backward time dependencies. Empirical results on representative benchmarks show the effectiveness of the proposed method.
Deep vs. Shallow Learning: A Benchmark Study in Low Magnitude Earthquake Detection
May 01, 2022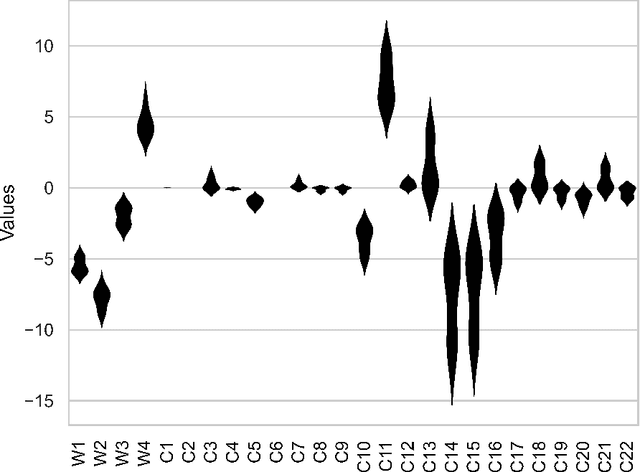

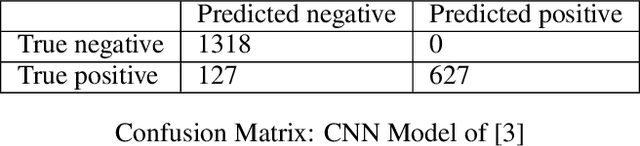

While deep learning models have seen recent high uptake in the geosciences, and are appealing in their ability to learn from minimally processed input data, as black box models they do not provide an easy means to understand how a decision is reached, which in safety-critical tasks especially can be problematical. An alternative route is to use simpler, more transparent white box models, in which task-specific feature construction replaces the more opaque feature discovery process performed automatically within deep learning models. Using data from the Groningen Gas Field in the Netherlands, we build on an existing logistic regression model by the addition of four further features discovered using elastic net driven data mining within the catch22 time series analysis package. We then evaluate the performance of the augmented logistic regression model relative to a deep (CNN) model, pre-trained on the Groningen data, on progressively increasing noise-to-signal ratios. We discover that, for each ratio, our logistic regression model correctly detects every earthquake, while the deep model fails to detect nearly 20 % of seismic events, thus justifying at least a degree of caution in the application of deep models, especially to data with higher noise-to-signal ratios.
Deep Unsupervised Domain Adaptation: A Review of Recent Advances and Perspectives
Aug 15, 2022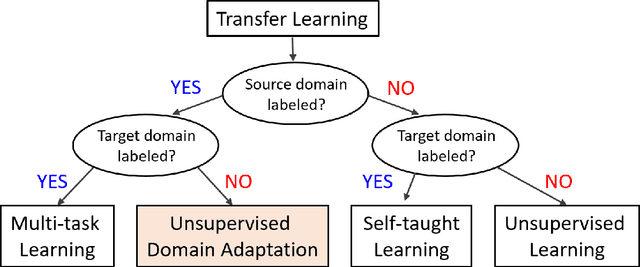

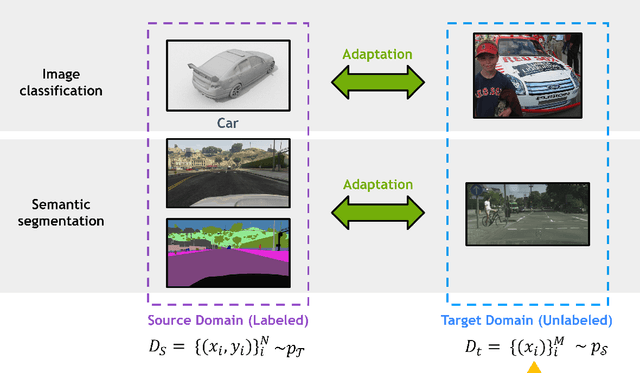
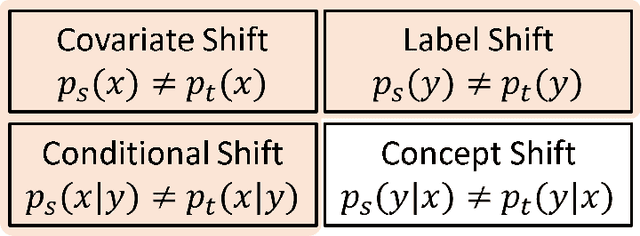
Deep learning has become the method of choice to tackle real-world problems in different domains, partly because of its ability to learn from data and achieve impressive performance on a wide range of applications. However, its success usually relies on two assumptions: (i) vast troves of labeled datasets are required for accurate model fitting, and (ii) training and testing data are independent and identically distributed. Its performance on unseen target domains, thus, is not guaranteed, especially when encountering out-of-distribution data at the adaptation stage. The performance drop on data in a target domain is a critical problem in deploying deep neural networks that are successfully trained on data in a source domain. Unsupervised domain adaptation (UDA) is proposed to counter this, by leveraging both labeled source domain data and unlabeled target domain data to carry out various tasks in the target domain. UDA has yielded promising results on natural image processing, video analysis, natural language processing, time-series data analysis, medical image analysis, etc. In this review, as a rapidly evolving topic, we provide a systematic comparison of its methods and applications. In addition, the connection of UDA with its closely related tasks, e.g., domain generalization and out-of-distribution detection, has also been discussed. Furthermore, deficiencies in current methods and possible promising directions are highlighted.