 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgenticSimLaw: A Juvenile Courtroom Multi-Agent Debate Simulation for Explainable High-Stakes Tabular Decision Making
Jan 29, 2026We introduce AgenticSimLaw, a role-structured, multi-agent debate framework that provides transparent and controllable test-time reasoning for high-stakes tabular decision-making tasks. Unlike black-box approaches, our courtroom-style orchestration explicitly defines agent roles (prosecutor, defense, judge), interaction protocols (7-turn structured debate), and private reasoning strategies, creating a fully auditable decision-making process. We benchmark this framework on young adult recidivism prediction using the NLSY97 dataset, comparing it against traditional chain-of-thought (CoT) prompting across almost 90 unique combinations of models and strategies. Our results demonstrate that structured multi-agent debate provides more stable and generalizable performance compared to single-agent reasoning, with stronger correlation between accuracy and F1-score metrics. Beyond performance improvements, AgenticSimLaw offers fine-grained control over reasoning steps, generates complete interaction transcripts for explainability, and enables systematic profiling of agent behaviors. While we instantiate this framework in the criminal justice domain to stress-test reasoning under ethical complexity, the approach generalizes to any deliberative, high-stakes decision task requiring transparency and human oversight. This work addresses key LLM-based multi-agent system challenges: organization through structured roles, observability through logged interactions, and responsibility through explicit non-deployment constraints for sensitive domains. Data, results, and code will be available on github.com under the MIT license.
The Paradox of Robustness: Decoupling Rule-Based Logic from Affective Noise in High-Stakes Decision-Making
Jan 29, 2026While Large Language Models (LLMs) are widely documented to be sensitive to minor prompt perturbations and prone to sycophantic alignment with user biases, their robustness in consequential, rule-bound decision-making remains under-explored. In this work, we uncover a striking "Paradox of Robustness": despite their known lexical brittleness, instruction-tuned LLMs exhibit a behavioral and near-total invariance to emotional framing effects. Using a novel controlled perturbation framework across three high-stakes domains (healthcare, law, and finance), we quantify a robustness gap where LLMs demonstrate 110-300 times greater resistance to narrative manipulation than human subjects. Specifically, we find a near-zero effect size for models (Cohen's h = 0.003) compared to the substantial biases observed in humans (Cohen's h in [0.3, 0.8]). This result is highly counterintuitive and suggests the mechanisms driving sycophancy and prompt sensitivity do not necessarily translate to a failure in logical constraint satisfaction. We show that this invariance persists across models with diverse training paradigms. Our findings show that while LLMs may be "brittle" to how a query is formatted, they are remarkably "stable" against why a decision should be biased. Our findings establish that instruction-tuned models can decouple logical rule-adherence from persuasive narratives, offering a source of decision stability that complements, and even potentially de-biases, human judgment in institutional contexts. We release the 162-scenario benchmark, code, and data to facilitate the rigorous evaluation of narrative-induced bias and robustness on GitHub.com.
When Prohibitions Become Permissions: Auditing Negation Sensitivity in Language Models
Jan 29, 2026When a user tells an AI system that someone "should not" take an action, the system ought to treat this as a prohibition. Yet many large language models do the opposite: they interpret negated instructions as affirmations. We audited 16 models across 14 ethical scenarios and found that open-source models endorse prohibited actions 77% of the time under simple negation and 100% under compound negation -- a 317% increase over affirmative framing. Commercial models fare better but still show swings of 19-128%. Agreement between models drops from 74% on affirmative prompts to 62% on negated ones, and financial scenarios prove twice as fragile as medical ones. These patterns hold under deterministic decoding, ruling out sampling noise. We present case studies showing how these failures play out in practice, propose the Negation Sensitivity Index (NSI) as a governance metric, and outline a tiered certification framework with domain-specific thresholds. The findings point to a gap between what current alignment techniques achieve and what safe deployment requires: models that cannot reliably distinguish "do X" from "do not X" should not be making autonomous decisions in high-stakes contexts.
Risks and Opportunities of Open-Source Generative AI
May 14, 2024



Applications of Generative AI (Gen AI) are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about the potential risks of the technology, and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open-source generative AI. Using a three-stage framework for Gen AI development (near, mid and long-term), we analyze the risks and opportunities of open-source generative AI models with similar capabilities to the ones currently available (near to mid-term) and with greater capabilities (long-term). We argue that, overall, the benefits of open-source Gen AI outweigh its risks. As such, we encourage the open sourcing of models, training and evaluation data, and provide a set of recommendations and best practices for managing risks associated with open-source generative AI.
Near to Mid-term Risks and Opportunities of Open Source Generative AI
Apr 25, 2024



In the next few years, applications of Generative AI are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about potential risks and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open source Generative AI. We argue for the responsible open sourcing of generative AI models in the near and medium term. To set the stage, we first introduce an AI openness taxonomy system and apply it to 40 current large language models. We then outline differential benefits and risks of open versus closed source AI and present potential risk mitigation, ranging from best practices to calls for technical and scientific contributions. We hope that this report will add a much needed missing voice to the current public discourse on near to mid-term AI safety and other societal impact.
SentimentArcs: A Novel Method for Self-Supervised Sentiment Analysis of Time Series Shows SOTA Transformers Can Struggle Finding Narrative Arcs
Oct 18, 2021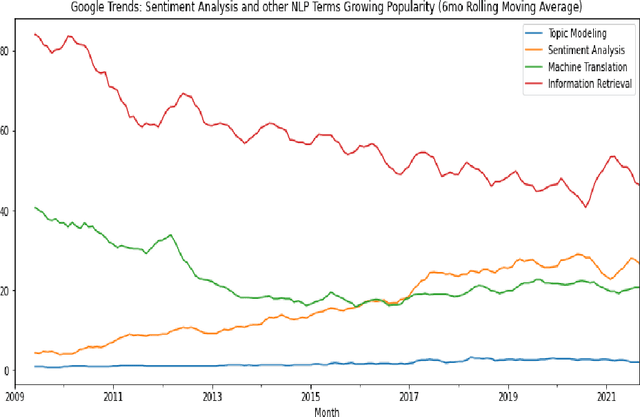
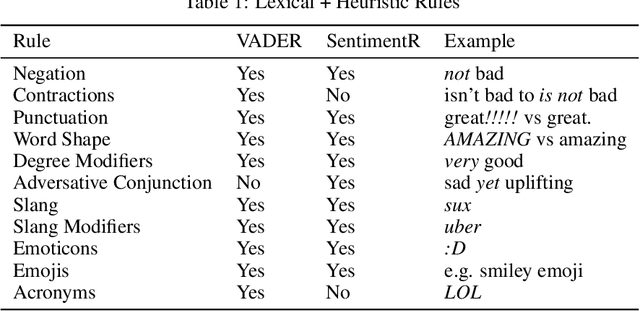
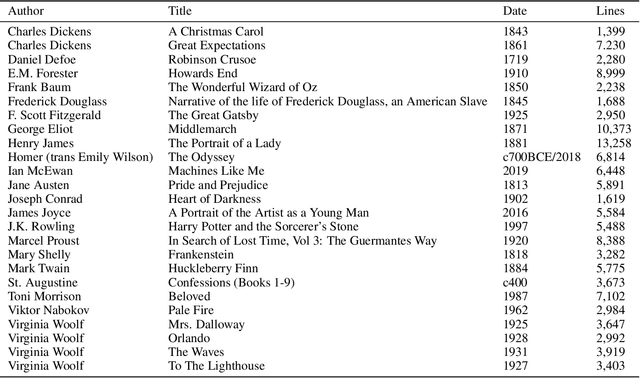
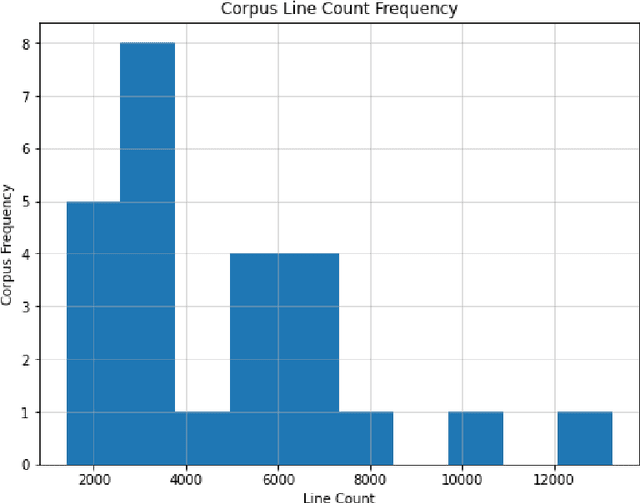
SOTA Transformer and DNN short text sentiment classifiers report over 97% accuracy on narrow domains like IMDB movie reviews. Real-world performance is significantly lower because traditional models overfit benchmarks and generalize poorly to different or more open domain texts. This paper introduces SentimentArcs, a new self-supervised time series sentiment analysis methodology that addresses the two main limitations of traditional supervised sentiment analysis: limited labeled training datasets and poor generalization. A large ensemble of diverse models provides a synthetic ground truth for self-supervised learning. Novel metrics jointly optimize an exhaustive search across every possible corpus:model combination. The joint optimization over both the corpus and model solves the generalization problem. Simple visualizations exploit the temporal structure in narratives so domain experts can quickly spot trends, identify key features, and note anomalies over hundreds of arcs and millions of data points. To our knowledge, this is the first self-supervised method for time series sentiment analysis and the largest survey directly comparing real-world model performance on long-form narratives.
Can Sentiment Analysis Reveal Structure in a Plotless Novel?
Aug 31, 2019Modernist novels are thought to break with traditional plot structure. In this paper, we test this theory by applying Sentiment Analysis to one of the most famous modernist novels, To the Lighthouse by Virginia Woolf. We first assess Sentiment Analysis in light of the critique that it cannot adequately account for literary language: we use a unique statistical comparison to demonstrate that even simple lexical approaches to Sentiment Analysis are surprisingly effective. We then use the Syuzhet.R package to explore similarities and differences across modeling methods. This comparative approach, when paired with literary close reading, can offer interpretive clues. To our knowledge, we are the first to undertake a hybrid model that fully leverages the strengths of both computational analysis and close reading. This hybrid model raises new questions for the literary critic, such as how to interpret relative versus absolute emotional valence and how to take into account subjective identification. Our finding is that while To the Lighthouse does not replicate a plot centered around a traditional hero, it does reveal an underlying emotional structure distributed between characters - what we term a distributed heroine model. This finding is innovative in the field of modernist and narrative studies and demonstrates that a hybrid method can yield significant discoveries.