 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text": models, code, and papers
On the application of Large Language Models for language teaching and assessment technology
Jul 17, 2023
The recent release of very large language models such as PaLM and GPT-4 has made an unprecedented impact in the popular media and public consciousness, giving rise to a mixture of excitement and fear as to their capabilities and potential uses, and shining a light on natural language processing research which had not previously received so much attention. The developments offer great promise for education technology, and in this paper we look specifically at the potential for incorporating large language models in AI-driven language teaching and assessment systems. We consider several research areas and also discuss the risks and ethical considerations surrounding generative AI in education technology for language learners. Overall we find that larger language models offer improvements over previous models in text generation, opening up routes toward content generation which had not previously been plausible. For text generation they must be prompted carefully and their outputs may need to be reshaped before they are ready for use. For automated grading and grammatical error correction, tasks whose progress is checked on well-known benchmarks, early investigations indicate that large language models on their own do not improve on state-of-the-art results according to standard evaluation metrics. For grading it appears that linguistic features established in the literature should still be used for best performance, and for error correction it may be that the models can offer alternative feedback styles which are not measured sensitively with existing methods. In all cases, there is work to be done to experiment with the inclusion of large language models in education technology for language learners, in order to properly understand and report on their capacities and limitations, and to ensure that foreseeable risks such as misinformation and harmful bias are mitigated.
TalkCLIP: Talking Head Generation with Text-Guided Expressive Speaking Styles
Apr 01, 2023
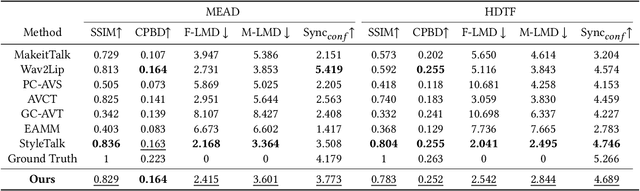
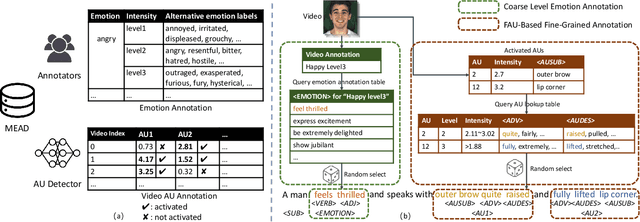
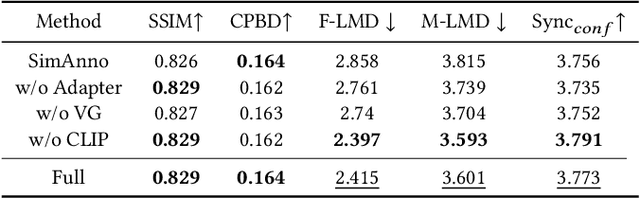
In order to produce facial-expression-specified talking head videos, previous audio-driven one-shot talking head methods need to use a reference video with a matching speaking style (i.e., facial expressions). However, finding videos with a desired style may not be easy, potentially restricting their application. In this work, we propose an expression-controllable one-shot talking head method, dubbed TalkCLIP, where the expression in a speech is specified by the natural language. This would significantly ease the difficulty of searching for a video with a desired speaking style. Here, we first construct a text-video paired talking head dataset, in which each video has alternative prompt-alike descriptions. Specifically, our descriptions involve coarse-level emotion annotations and facial action unit (AU) based fine-grained annotations. Then, we introduce a CLIP-based style encoder that first projects natural language descriptions to the CLIP text embedding space and then aligns the textual embeddings to the representations of speaking styles. As extensive textual knowledge has been encoded by CLIP, our method can even generalize to infer a speaking style whose description has not been seen during training. Extensive experiments demonstrate that our method achieves the advanced capability of generating photo-realistic talking heads with vivid facial expressions guided by text descriptions.
Factor Decomposed Generative Adversarial Networks for Text-to-Image Synthesis
Mar 24, 2023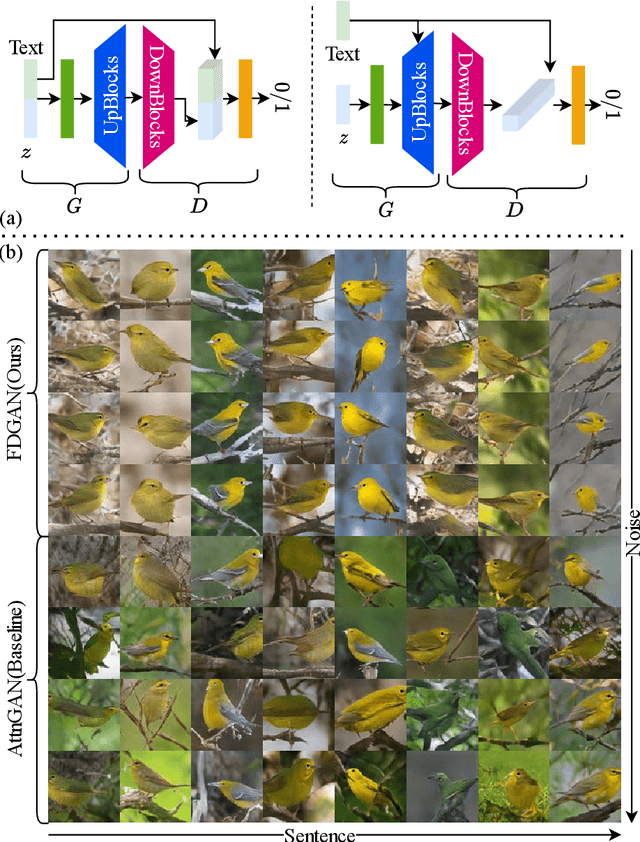
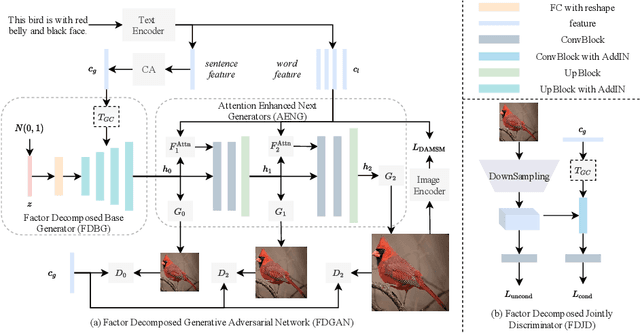
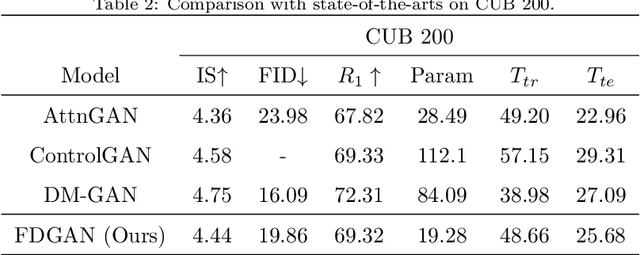
Prior works about text-to-image synthesis typically concatenated the sentence embedding with the noise vector, while the sentence embedding and the noise vector are two different factors, which control the different aspects of the generation. Simply concatenating them will entangle the latent factors and encumber the generative model. In this paper, we attempt to decompose these two factors and propose Factor Decomposed Generative Adversarial Networks~(FDGAN). To achieve this, we firstly generate images from the noise vector and then apply the sentence embedding in the normalization layer for both generator and discriminators. We also design an additive norm layer to align and fuse the text-image features. The experimental results show that decomposing the noise and the sentence embedding can disentangle latent factors in text-to-image synthesis, and make the generative model more efficient. Compared with the baseline, FDGAN can achieve better performance, while fewer parameters are used.
HeGeL: A Novel Dataset for Geo-Location from Hebrew Text
Jul 02, 2023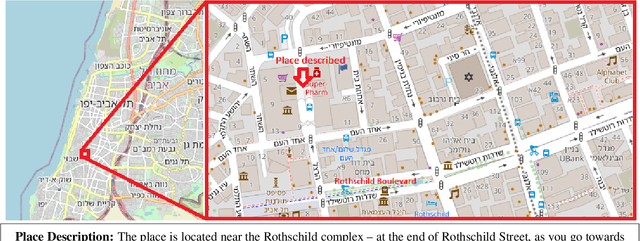
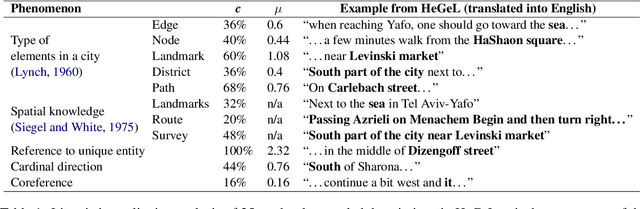
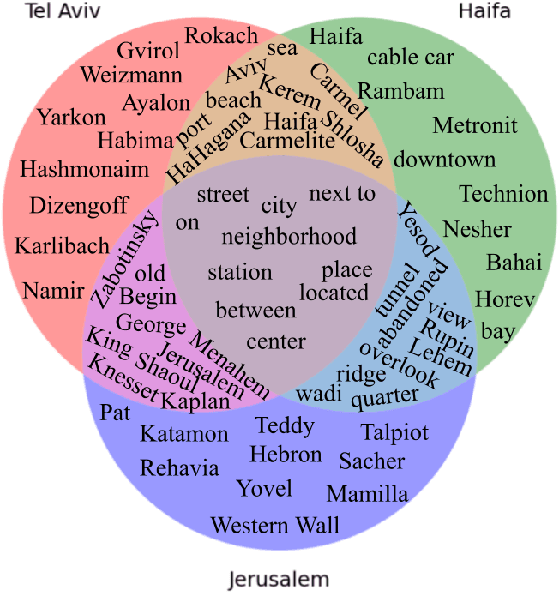
The task of textual geolocation - retrieving the coordinates of a place based on a free-form language description - calls for not only grounding but also natural language understanding and geospatial reasoning. Even though there are quite a few datasets in English used for geolocation, they are currently based on open-source data (Wikipedia and Twitter), where the location of the described place is mostly implicit, such that the location retrieval resolution is limited. Furthermore, there are no datasets available for addressing the problem of textual geolocation in morphologically rich and resource-poor languages, such as Hebrew. In this paper, we present the Hebrew Geo-Location (HeGeL) corpus, designed to collect literal place descriptions and analyze lingual geospatial reasoning. We crowdsourced 5,649 literal Hebrew place descriptions of various place types in three cities in Israel. Qualitative and empirical analysis show that the data exhibits abundant use of geospatial reasoning and requires a novel environmental representation.
Badgers: generating data quality deficits with Python
Jul 10, 2023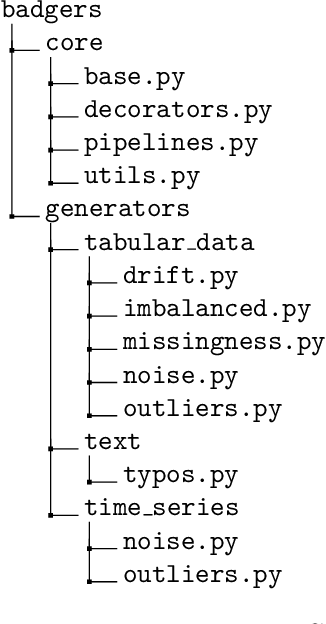
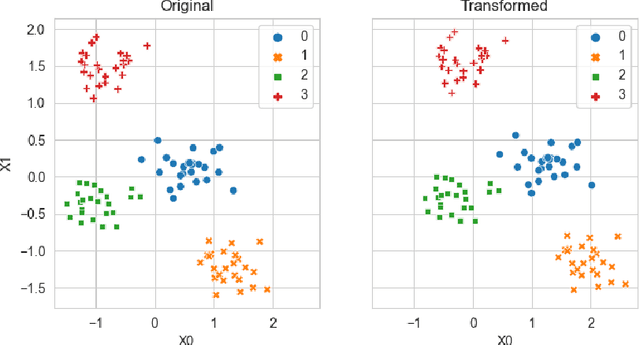
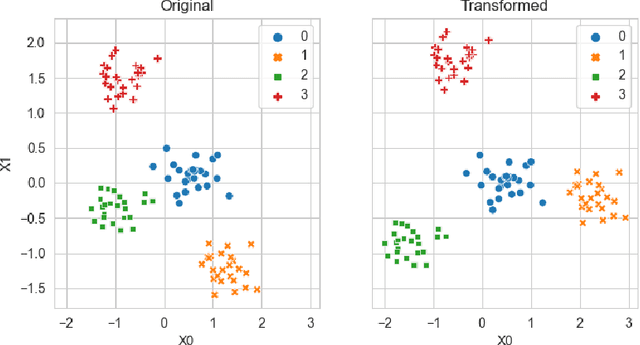
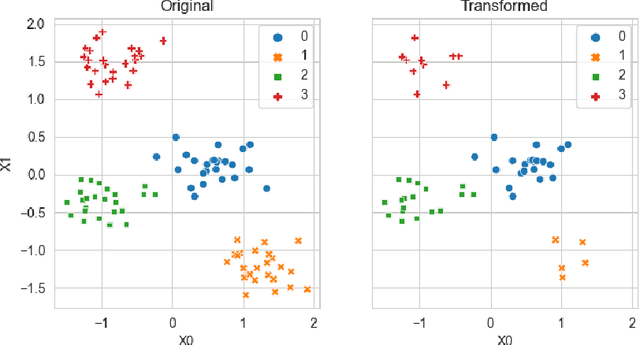
Generating context specific data quality deficits is necessary to experimentally assess data quality of data-driven (artificial intelligence (AI) or machine learning (ML)) applications. In this paper we present badgers, an extensible open-source Python library to generate data quality deficits (outliers, imbalanced data, drift, etc.) for different modalities (tabular data, time-series, text, etc.). The documentation is accessible at https://fraunhofer-iese.github.io/badgers/ and the source code at https://github.com/Fraunhofer-IESE/badgers
Fantasia3D: Disentangling Geometry and Appearance for High-quality Text-to-3D Content Creation
Mar 28, 2023

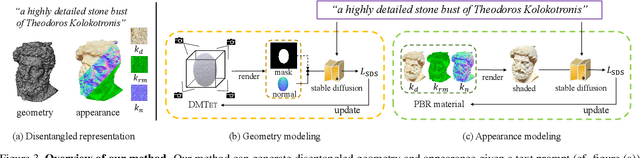
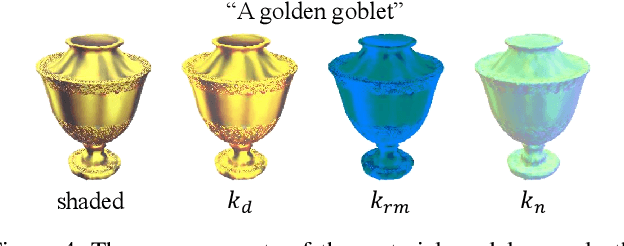
Automatic 3D content creation has achieved rapid progress recently due to the availability of pre-trained, large language models and image diffusion models, forming the emerging topic of text-to-3D content creation. Existing text-to-3D methods commonly use implicit scene representations, which couple the geometry and appearance via volume rendering and are suboptimal in terms of recovering finer geometries and achieving photorealistic rendering; consequently, they are less effective for generating high-quality 3D assets. In this work, we propose a new method of Fantasia3D for high-quality text-to-3D content creation. Key to Fantasia3D is the disentangled modeling and learning of geometry and appearance. For geometry learning, we rely on a hybrid scene representation, and propose to encode surface normal extracted from the representation as the input of the image diffusion model. For appearance modeling, we introduce the spatially varying bidirectional reflectance distribution function (BRDF) into the text-to-3D task, and learn the surface material for photorealistic rendering of the generated surface. Our disentangled framework is more compatible with popular graphics engines, supporting relighting, editing, and physical simulation of the generated 3D assets. We conduct thorough experiments that show the advantages of our method over existing ones under different text-to-3D task settings. Project page and source codes: https://fantasia3d.github.io/.
A Predictive Model of Digital Information Engagement: Forecasting User Engagement With English Words by Incorporating Cognitive Biases, Computational Linguistics and Natural Language Processing
Jul 26, 2023This study introduces and empirically tests a novel predictive model for digital information engagement (IE) - the READ model, an acronym for the four pivotal attributes of engaging information: Representativeness, Ease-of-use, Affect, and Distribution. Conceptualized within the theoretical framework of Cumulative Prospect Theory, the model integrates key cognitive biases with computational linguistics and natural language processing to develop a multidimensional perspective on information engagement. A rigorous testing protocol was implemented, involving 50 randomly selected pairs of synonymous words (100 words in total) from the WordNet database. These words' engagement levels were evaluated through a large-scale online survey (n = 80,500) to derive empirical IE metrics. The READ attributes for each word were then computed and their predictive efficacy examined. The findings affirm the READ model's robustness, accurately predicting a word's IE level and distinguishing the more engaging word from a pair of synonyms with an 84% accuracy rate. The READ model's potential extends across various domains, including business, education, government, and healthcare, where it could enhance content engagement and inform AI language model development and generative text work. Future research should address the model's scalability and adaptability across different domains and languages, thereby broadening its applicability and efficacy.
GPT-3 Models are Few-Shot Financial Reasoners
Jul 26, 2023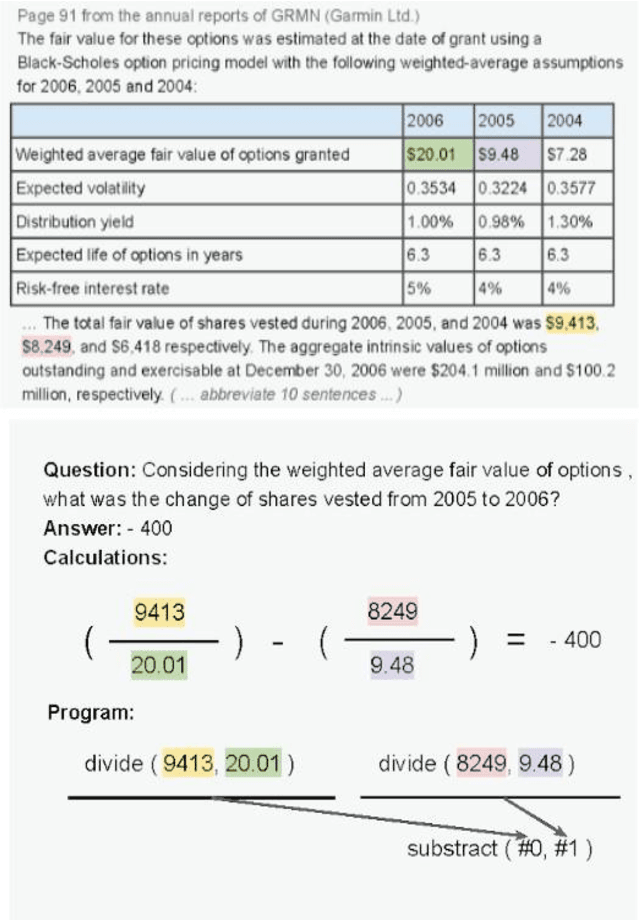

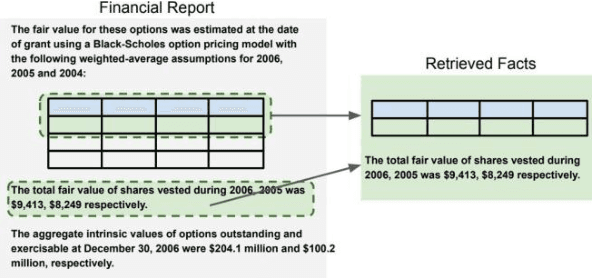

Financial analysis is an important tool for evaluating company performance. Practitioners work to answer financial questions to make profitable investment decisions, and use advanced quantitative analyses to do so. As a result, Financial Question Answering (QA) is a question answering task that requires deep reasoning about numbers. Furthermore, it is unknown how well pre-trained language models can reason in the financial domain. The current state-of-the-art requires a retriever to collect relevant facts about the financial question from the text and a generator to produce a valid financial program and a final answer. However, recently large language models like GPT-3 have achieved state-of-the-art performance on wide variety of tasks with just a few shot examples. We run several experiments with GPT-3 and find that a separate retrieval model and logic engine continue to be essential components to achieving SOTA performance in this task, particularly due to the precise nature of financial questions and the complex information stored in financial documents. With this understanding, our refined prompt-engineering approach on GPT-3 achieves near SOTA accuracy without any fine-tuning.
* 15 pages, 8 figures
Teaching Autonomous Vehicles to Express Interaction Intent during Unprotected Left Turns: A Human-Driving-Prior-Based Trajectory Planning Approach
Jul 29, 2023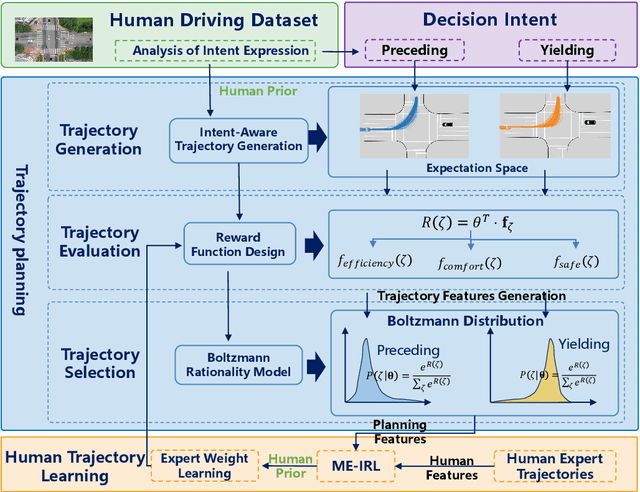
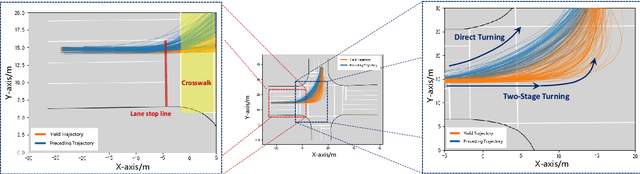

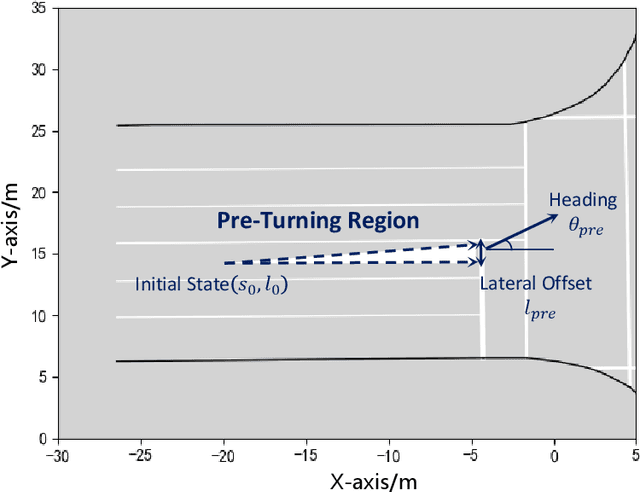
With the integration of Autonomous Vehicles (AVs) into our transportation systems, their harmonious coexistence with Human-driven Vehicles (HVs) in mixed traffic settings becomes a crucial focus of research. A vital component of this coexistence is the capability of AVs to mimic human-like interaction intentions within the traffic environment. To address this, we propose a novel framework for Unprotected left-turn trajectory planning for AVs, aiming to replicate human driving patterns and facilitate effective communication of social intent. Our framework comprises three stages: trajectory generation, evaluation, and selection. In the generation stage, we use real human-driving trajectory data to define constraints for an anticipated trajectory space, generating candidate motion trajectories that embody intent expression. The evaluation stage employs maximum entropy inverse reinforcement learning (ME-IRL) to assess human trajectory preferences, considering factors such as traffic efficiency, driving comfort, and interactive safety. In the selection stage, we apply a Boltzmann distribution-based method to assign rewards and probabilities to candidate trajectories, thereby facilitating human-like decision-making. We conduct validation of our proposed framework using a real trajectory dataset and perform a comparative analysis against several baseline methods. The results demonstrate the superior performance of our framework in terms of human-likeness, intent expression capability, and computational efficiency. Limited by the length of the text, more details of this research can be found at https://shorturl.at/jqu35
Text classification dataset and analysis for Uzbek language
Feb 28, 2023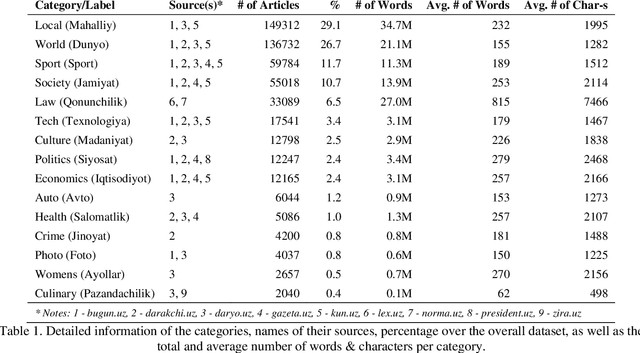
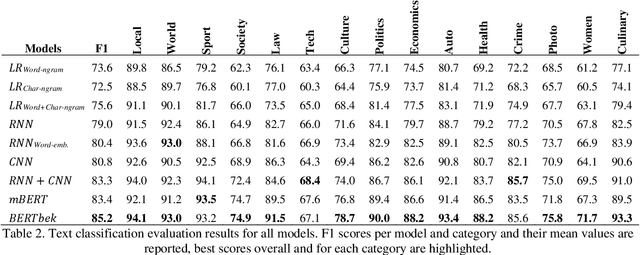
Text classification is an important task in Natural Language Processing (NLP), where the goal is to categorize text data into predefined classes. In this study, we analyse the dataset creation steps and evaluation techniques of multi-label news categorisation task as part of text classification. We first present a newly obtained dataset for Uzbek text classification, which was collected from 10 different news and press websites and covers 15 categories of news, press and law texts. We also present a comprehensive evaluation of different models, ranging from traditional bag-of-words models to deep learning architectures, on this newly created dataset. Our experiments show that the Recurrent Neural Network (RNN) and Convolutional Neural Network (CNN) based models outperform the rule-based models. The best performance is achieved by the BERTbek model, which is a transformer-based BERT model trained on the Uzbek corpus. Our findings provide a good baseline for further research in Uzbek text classification.