 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the application of Large Language Models for language teaching and assessment technology
Jul 17, 2023The recent release of very large language models such as PaLM and GPT-4 has made an unprecedented impact in the popular media and public consciousness, giving rise to a mixture of excitement and fear as to their capabilities and potential uses, and shining a light on natural language processing research which had not previously received so much attention. The developments offer great promise for education technology, and in this paper we look specifically at the potential for incorporating large language models in AI-driven language teaching and assessment systems. We consider several research areas and also discuss the risks and ethical considerations surrounding generative AI in education technology for language learners. Overall we find that larger language models offer improvements over previous models in text generation, opening up routes toward content generation which had not previously been plausible. For text generation they must be prompted carefully and their outputs may need to be reshaped before they are ready for use. For automated grading and grammatical error correction, tasks whose progress is checked on well-known benchmarks, early investigations indicate that large language models on their own do not improve on state-of-the-art results according to standard evaluation metrics. For grading it appears that linguistic features established in the literature should still be used for best performance, and for error correction it may be that the models can offer alternative feedback styles which are not measured sensitively with existing methods. In all cases, there is work to be done to experiment with the inclusion of large language models in education technology for language learners, in order to properly understand and report on their capacities and limitations, and to ensure that foreseeable risks such as misinformation and harmful bias are mitigated.
Annotation of Soft Onsets in String Ensemble Recordings
Nov 16, 2022



Onset detection is the process of identifying the start points of musical note events within an audio recording. While the detection of percussive onsets is often considered a solved problem, soft onsets-as found in string instrument recordings-still pose a significant challenge for state-of-the-art algorithms. The problem is further exacerbated by a paucity of data containing expert annotations and research related to best practices for curating soft onset annotations for string instruments. To this end, we investigate inter-annotator agreement between 24 participants, extend an algorithm for determining the most consistent annotator, and compare the performance of human annotators and state-of-the-art onset detection algorithms. Experimental results reveal a positive trend between musical experience and both inter-annotator agreement and performance in comparison with automated systems. Additionally, onsets produced by changes in fingering as well as those from the cello were found to be particularly challenging for both human annotators and automatic approaches. To promote research in best practices for annotation of soft onsets, we have made all experimental data associated with this study publicly available. In addition, we publish the ARME Virtuoso Strings dataset, consisting of over 144 recordings of professional performances of an excerpt from Haydn's string quartet Op. 74 No. 1 Finale, each with corresponding individual instrumental onset annotations.
Uncertainty-Aware Training for Cardiac Resynchronisation Therapy Response Prediction
Sep 22, 2021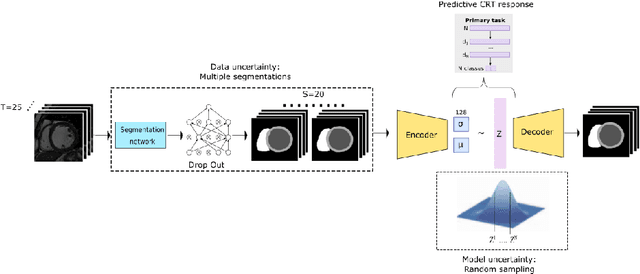
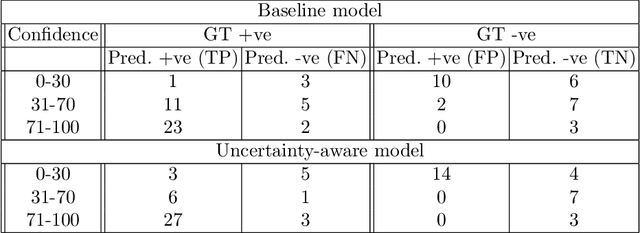
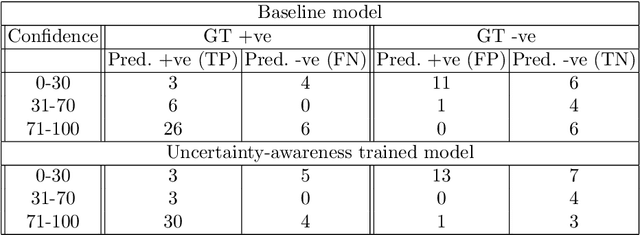
Evaluation of predictive deep learning (DL) models beyond conventional performance metrics has become increasingly important for applications in sensitive environments like healthcare. Such models might have the capability to encode and analyse large sets of data but they often lack comprehensive interpretability methods, preventing clinical trust in predictive outcomes. Quantifying uncertainty of a prediction is one way to provide such interpretability and promote trust. However, relatively little attention has been paid to how to include such requirements into the training of the model. In this paper we: (i) quantify the data (aleatoric) and model (epistemic) uncertainty of a DL model for Cardiac Resynchronisation Therapy response prediction from cardiac magnetic resonance images, and (ii) propose and perform a preliminary investigation of an uncertainty-aware loss function that can be used to retrain an existing DL image-based classification model to encourage confidence in correct predictions and reduce confidence in incorrect predictions. Our initial results are promising, showing a significant increase in the (epistemic) confidence of true positive predictions, with some evidence of a reduction in false negative confidence.
Interpretable Deep Models for Cardiac Resynchronisation Therapy Response Prediction
Jul 09, 2020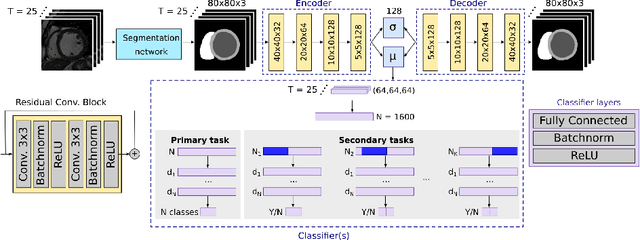

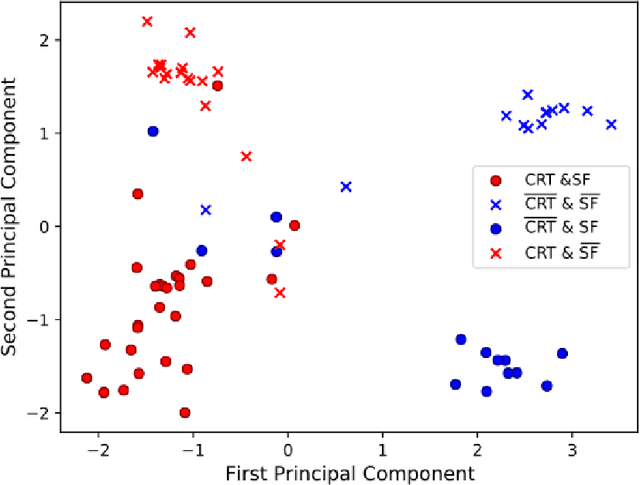

Advances in deep learning (DL) have resulted in impressive accuracy in some medical image classification tasks, but often deep models lack interpretability. The ability of these models to explain their decisions is important for fostering clinical trust and facilitating clinical translation. Furthermore, for many problems in medicine there is a wealth of existing clinical knowledge to draw upon, which may be useful in generating explanations, but it is not obvious how this knowledge can be encoded into DL models - most models are learnt either from scratch or using transfer learning from a different domain. In this paper we address both of these issues. We propose a novel DL framework for image-based classification based on a variational autoencoder (VAE). The framework allows prediction of the output of interest from the latent space of the autoencoder, as well as visualisation (in the image domain) of the effects of crossing the decision boundary, thus enhancing the interpretability of the classifier. Our key contribution is that the VAE disentangles the latent space based on `explanations' drawn from existing clinical knowledge. The framework can predict outputs as well as explanations for these outputs, and also raises the possibility of discovering new biomarkers that are separate (or disentangled) from the existing knowledge. We demonstrate our framework on the problem of predicting response of patients with cardiomyopathy to cardiac resynchronization therapy (CRT) from cine cardiac magnetic resonance images. The sensitivity and specificity of the proposed model on the task of CRT response prediction are 88.43% and 84.39% respectively, and we showcase the potential of our model in enhancing understanding of the factors contributing to CRT response.