 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fantastic Animals and Where to Find Them: Segment Any Marine Animal with Dual SAM
Apr 07, 2024
As an important pillar of underwater intelligence, Marine Animal Segmentation (MAS) involves segmenting animals within marine environments. Previous methods don't excel in extracting long-range contextual features and overlook the connectivity between discrete pixels. Recently, Segment Anything Model (SAM) offers a universal framework for general segmentation tasks. Unfortunately, trained with natural images, SAM does not obtain the prior knowledge from marine images. In addition, the single-position prompt of SAM is very insufficient for prior guidance. To address these issues, we propose a novel feature learning framework, named Dual-SAM for high-performance MAS. To this end, we first introduce a dual structure with SAM's paradigm to enhance feature learning of marine images. Then, we propose a Multi-level Coupled Prompt (MCP) strategy to instruct comprehensive underwater prior information, and enhance the multi-level features of SAM's encoder with adapters. Subsequently, we design a Dilated Fusion Attention Module (DFAM) to progressively integrate multi-level features from SAM's encoder. Finally, instead of directly predicting the masks of marine animals, we propose a Criss-Cross Connectivity Prediction (C$^3$P) paradigm to capture the inter-connectivity between discrete pixels. With dual decoders, it generates pseudo-labels and achieves mutual supervision for complementary feature representations, resulting in considerable improvements over previous techniques. Extensive experiments verify that our proposed method achieves state-of-the-art performances on five widely-used MAS datasets. The code is available at https://github.com/Drchip61/Dual_SAM.
SemGrasp: Semantic Grasp Generation via Language Aligned Discretization
Apr 04, 2024Generating natural human grasps necessitates consideration of not just object geometry but also semantic information. Solely depending on object shape for grasp generation confines the applications of prior methods in downstream tasks. This paper presents a novel semantic-based grasp generation method, termed SemGrasp, which generates a static human grasp pose by incorporating semantic information into the grasp representation. We introduce a discrete representation that aligns the grasp space with semantic space, enabling the generation of grasp postures in accordance with language instructions. A Multimodal Large Language Model (MLLM) is subsequently fine-tuned, integrating object, grasp, and language within a unified semantic space. To facilitate the training of SemGrasp, we have compiled a large-scale, grasp-text-aligned dataset named CapGrasp, featuring about 260k detailed captions and 50k diverse grasps. Experimental findings demonstrate that SemGrasp efficiently generates natural human grasps in alignment with linguistic intentions. Our code, models, and dataset are available publicly at: https://kailinli.github.io/SemGrasp.
FastHDRNet: A new efficient method for SDR-to-HDR Translation
Apr 06, 2024Modern displays nowadays possess the capability to render video content with a high dynamic range (HDR) and an extensive color gamut (WCG).However, the majority of available resources are still in standard dynamic range(SDR). Therefore, we need to identify an effective methodology for this objective.The existing deep neural network (DNN) based SDR(Standard dynamic range) to HDR (High dynamic range) conversion methods outperform conventional methods, but they are either too large to implement or generate some terrible artifacts. We propose a neural network for SDRTV to HDRTV conversion, termed "FastHDRNet". This network includes two parts, Adaptive Universal Color Transformation and Local Enhancement.The architecture is designed as a lightweight network that utilizes global statistics and local information with super high efficiency. After the experiment, we find that our proposed method achieve state-of-the-art performance in both quantitative comparisons and visual quality with a lightweight structure and a enhanced infer speed.
SCAResNet: A ResNet Variant Optimized for Tiny Object Detection in Transmission and Distribution Towers
Apr 05, 2024Traditional deep learning-based object detection networks often resize images during the data preprocessing stage to achieve a uniform size and scale in the feature map. Resizing is done to facilitate model propagation and fully connected classification. However, resizing inevitably leads to object deformation and loss of valuable information in the images. This drawback becomes particularly pronounced for tiny objects like distribution towers with linear shapes and few pixels. To address this issue, we propose abandoning the resizing operation. Instead, we introduce Positional-Encoding Multi-head Criss-Cross Attention. This allows the model to capture contextual information and learn from multiple representation subspaces, effectively enriching the semantics of distribution towers. Additionally, we enhance Spatial Pyramid Pooling by reshaping three pooled feature maps into a new unified one while also reducing the computational burden. This approach allows images of different sizes and scales to generate feature maps with uniform dimensions and can be employed in feature map propagation. Our SCAResNet incorporates these aforementioned improvements into the backbone network ResNet. We evaluated our SCAResNet using the Electric Transmission and Distribution Infrastructure Imagery dataset from Duke University. Without any additional tricks, we employed various object detection models with Gaussian Receptive Field based Label Assignment as the baseline. When incorporating the SCAResNet into the baseline model, we achieved a 2.1% improvement in mAPs. This demonstrates the advantages of our SCAResNet in detecting transmission and distribution towers and its value in tiny object detection. The source code is available at https://github.com/LisavilaLee/SCAResNet_mmdet.
A Unified Diffusion Framework for Scene-aware Human Motion Estimation from Sparse Signals
Apr 07, 2024Estimating full-body human motion via sparse tracking signals from head-mounted displays and hand controllers in 3D scenes is crucial to applications in AR/VR. One of the biggest challenges to this task is the one-to-many mapping from sparse observations to dense full-body motions, which endowed inherent ambiguities. To help resolve this ambiguous problem, we introduce a new framework to combine rich contextual information provided by scenes to benefit full-body motion tracking from sparse observations. To estimate plausible human motions given sparse tracking signals and 3D scenes, we develop $\text{S}^2$Fusion, a unified framework fusing \underline{S}cene and sparse \underline{S}ignals with a conditional dif\underline{Fusion} model. $\text{S}^2$Fusion first extracts the spatial-temporal relations residing in the sparse signals via a periodic autoencoder, and then produces time-alignment feature embedding as additional inputs. Subsequently, by drawing initial noisy motion from a pre-trained prior, $\text{S}^2$Fusion utilizes conditional diffusion to fuse scene geometry and sparse tracking signals to generate full-body scene-aware motions. The sampling procedure of $\text{S}^2$Fusion is further guided by a specially designed scene-penetration loss and phase-matching loss, which effectively regularizes the motion of the lower body even in the absence of any tracking signals, making the generated motion much more plausible and coherent. Extensive experimental results have demonstrated that our $\text{S}^2$Fusion outperforms the state-of-the-art in terms of estimation quality and smoothness.
Self-Supervised Learning for Medical Image Data with Anatomy-Oriented Imaging Planes
Apr 07, 2024Self-supervised learning has emerged as a powerful tool for pretraining deep networks on unlabeled data, prior to transfer learning of target tasks with limited annotation. The relevance between the pretraining pretext and target tasks is crucial to the success of transfer learning. Various pretext tasks have been proposed to utilize properties of medical image data (e.g., three dimensionality), which are more relevant to medical image analysis than generic ones for natural images. However, previous work rarely paid attention to data with anatomy-oriented imaging planes, e.g., standard cardiac magnetic resonance imaging views. As these imaging planes are defined according to the anatomy of the imaged organ, pretext tasks effectively exploiting this information can pretrain the networks to gain knowledge on the organ of interest. In this work, we propose two complementary pretext tasks for this group of medical image data based on the spatial relationship of the imaging planes. The first is to learn the relative orientation between the imaging planes and implemented as regressing their intersecting lines. The second exploits parallel imaging planes to regress their relative slice locations within a stack. Both pretext tasks are conceptually straightforward and easy to implement, and can be combined in multitask learning for better representation learning. Thorough experiments on two anatomical structures (heart and knee) and representative target tasks (semantic segmentation and classification) demonstrate that the proposed pretext tasks are effective in pretraining deep networks for remarkably boosted performance on the target tasks, and superior to other recent approaches.
DPFT: Dual Perspective Fusion Transformer for Camera-Radar-based Object Detection
Apr 03, 2024The perception of autonomous vehicles has to be efficient, robust, and cost-effective. However, cameras are not robust against severe weather conditions, lidar sensors are expensive, and the performance of radar-based perception is still inferior to the others. Camera-radar fusion methods have been proposed to address this issue, but these are constrained by the typical sparsity of radar point clouds and often designed for radars without elevation information. We propose a novel camera-radar fusion approach called Dual Perspective Fusion Transformer (DPFT), designed to overcome these limitations. Our method leverages lower-level radar data (the radar cube) instead of the processed point clouds to preserve as much information as possible and employs projections in both the camera and ground planes to effectively use radars with elevation information and simplify the fusion with camera data. As a result, DPFT has demonstrated state-of-the-art performance on the K-Radar dataset while showing remarkable robustness against adverse weather conditions and maintaining a low inference time. The code is made available as open-source software under https://github.com/TUMFTM/DPFT.
Learning How to Strategically Disclose Information
Mar 13, 2024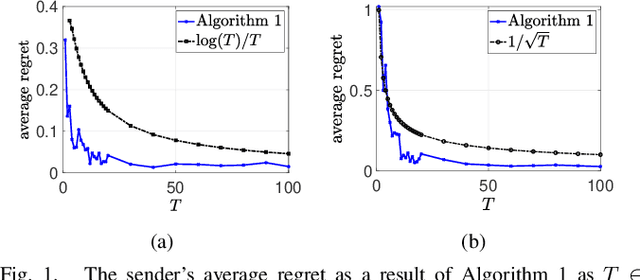
Strategic information disclosure, in its simplest form, considers a game between an information provider (sender) who has access to some private information that an information receiver is interested in. While the receiver takes an action that affects the utilities of both players, the sender can design information (or modify beliefs) of the receiver through signal commitment, hence posing a Stackelberg game. However, obtaining a Stackelberg equilibrium for this game traditionally requires the sender to have access to the receiver's objective. In this work, we consider an online version of information design where a sender interacts with a receiver of an unknown type who is adversarially chosen at each round. Restricting attention to Gaussian prior and quadratic costs for the sender and the receiver, we show that $\mathcal{O}(\sqrt{T})$ regret is achievable with full information feedback, where $T$ is the total number of interactions between the sender and the receiver. Further, we propose a novel parametrization that allows the sender to achieve $\mathcal{O}(\sqrt{T})$ regret for a general convex utility function. We then consider the Bayesian Persuasion problem with an additional cost term in the objective function, which penalizes signaling policies that are more informative and obtain $\mathcal{O}(\log(T))$ regret. Finally, we establish a sublinear regret bound for the partial information feedback setting and provide simulations to support our theoretical results.
DQ-DETR: DETR with Dynamic Query for Tiny Object Detection
Apr 04, 2024Despite previous DETR-like methods having performed successfully in generic object detection, tiny object detection is still a challenging task for them since the positional information of object queries is not customized for detecting tiny objects, whose scale is extraordinarily smaller than general objects. Also, DETR-like methods using a fixed number of queries make them unsuitable for aerial datasets, which only contain tiny objects, and the numbers of instances are imbalanced between different images. Thus, we present a simple yet effective model, named DQ-DETR, which consists of three different components: categorical counting module, counting-guided feature enhancement, and dynamic query selection to solve the above-mentioned problems. DQ-DETR uses the prediction and density maps from the categorical counting module to dynamically adjust the number of object queries and improve the positional information of queries. Our model DQ-DETR outperforms previous CNN-based and DETR-like methods, achieving state-of-the-art mAP 30.2% on the AI-TOD-V2 dataset, which mostly consists of tiny objects.
Galaxy 3D Shape Recovery using Mixture Density Network
Apr 06, 2024Since the turn of the century, astronomers have been exploiting the rich information afforded by combining stellar kinematic maps and imaging in an attempt to recover the intrinsic, three-dimensional (3D) shape of a galaxy. A common intrinsic shape recovery method relies on an expected monotonic relationship between the intrinsic misalignment of the kinematic and morphological axes and the triaxiality parameter. Recent studies have, however, cast doubt about underlying assumptions relating shape and intrinsic kinematic misalignment. In this work, we aim to recover the 3D shape of individual galaxies using their projected stellar kinematic and flux distributions using a supervised machine learning approach with mixture density network (MDN). Using a mock dataset of the EAGLE hydrodynamical cosmological simulation, we train the MDN model for a carefully selected set of common kinematic and photometric parameters. Compared to previous methods, we demonstrate potential improvements achieved with the MDN model to retrieve the 3D galaxy shape along with the uncertainties, especially for prolate and triaxial systems. We make specific recommendations for recovering galaxy intrinsic shapes relevant for current and future integral field spectroscopic galaxy surveys.