 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Information Accuracy in Timeliness-Based Gossip Networks
Mar 02, 2026We investigate information accuracy in timeliness-based gossip networks where the source evolves according to a continuous-time Markov chain (CTMC) with $M$ states and disseminates status updates to a network of $n$ nodes. In addition to direct source updates, nodes exchange their locally stored packets via gossip and accept incoming packets solely based on whether the incoming packet is fresher than their local copy. As a result, a node can possess the freshest packet in the network while still not having the current source state. To quantify the amount of accurate information flowing in the network under such a gossiping scheme, we introduce two accuracy metrics, average accuracy, defined as the expected fraction of nodes carrying accurate information in any given subset, and freshness-based accuracy, defined as the accuracy of the freshest node in any given subset. Using a stochastic hybrid systems (SHS) framework, we first derive steady-state balance equations and obtain matrix-valued recursions that characterize these metrics in fully connected gossip networks under binary CTMCs. We then extend our analysis to the general multi-state information source using a joint CTMC approach. Finally, we quantify the fraction of nodes whose information is accurate due to direct source pushes versus gossip exchanges. We verify our findings with numerical analyses and provide asymptotic insights.
Don't Always Pick the Highest-Performing Model: An Information Theoretic View of LLM Ensemble Selection
Feb 08, 2026Large language models (LLMs) are often ensembled together to improve overall reliability and robustness, but in practice models are strongly correlated. This raises a fundamental question: which models should be selected when forming an LLM ensemble? We formulate budgeted ensemble selection as maximizing the mutual information between the true label and predictions of the selected models. Furthermore, to explain why performance can saturate even with many models, we model the correlated errors of the models using Gaussian-copula and show an information-theoretic error floor for the performance of the ensemble. Motivated by these, we propose a simple greedy mutual-information selection algorithm that estimates the required information terms directly from data and iteratively builds an ensemble under a query budget. We test our approach in two question answering datasets and one binary sentiment classification dataset: MEDMCQA, MMLU, and IMDB movie reviews. Across all datasets, we observe that our method consistently outperforms strong baselines under the same query budget.
Queueing-Aware Optimization of Reasoning Tokens for Accuracy-Latency Trade-offs in LLM Servers
Jan 15, 2026We consider a single large language model (LLM) server that serves a heterogeneous stream of queries belonging to $N$ distinct task types. Queries arrive according to a Poisson process, and each type occurs with a known prior probability. For each task type, the server allocates a fixed number of internal thinking tokens, which determines the computational effort devoted to that query. The token allocation induces an accuracy-latency trade-off: the service time follows an approximately affine function of the allocated tokens, while the probability of a correct response exhibits diminishing returns. Under a first-in, first-out (FIFO) service discipline, the system operates as an $M/G/1$ queue, and the mean system time depends on the first and second moments of the resulting service-time distribution. We formulate a constrained optimization problem that maximizes a weighted average accuracy objective penalized by the mean system time, subject to architectural token-budget constraints and queue-stability conditions. The objective function is shown to be strictly concave over the stability region, which ensures existence and uniqueness of the optimal token allocation. The first-order optimality conditions yield a coupled projected fixed-point characterization of the optimum, together with an iterative solution and an explicit sufficient condition for contraction. Moreover, a projected gradient method with a computable global step-size bound is developed to guarantee convergence beyond the contractive regime. Finally, integer-valued token allocations are attained via rounding of the continuous solution, and the resulting performance loss is evaluated in simulation results.
A Soft Inducement Framework for Incentive-Aided Steering of No-Regret Players
Aug 29, 2025In this work, we investigate a steering problem in a mediator-augmented two-player normal-form game, where the mediator aims to guide players toward a specific action profile through information and incentive design. We first characterize the games for which successful steering is possible. Moreover, we establish that steering players to any desired action profile is not always achievable with information design alone, nor when accompanied with sublinear payment schemes. Consequently, we derive a lower bound on the constant payments required per round to achieve this goal. To address these limitations incurred with information design, we introduce an augmented approach that involves a one-shot information design phase before the start of the repeated game, transforming the prior interaction into a Stackelberg game. Finally, we theoretically demonstrate that this approach improves the convergence rate of players' action profiles to the target point by a constant factor with high probability, and support it with empirical results.
Remote Estimation Games with Random Walk Processes: Stackelberg Equilibrium
Dec 01, 2024Remote estimation is a crucial element of real time monitoring of a stochastic process. While most of the existing works have concentrated on obtaining optimal sampling strategies, motivated by malicious attacks on cyber-physical systems, we model sensing under surveillance as a game between an attacker and a defender. This introduces strategic elements to conventional remote estimation problems. Additionally, inspired by increasing detection capabilities, we model an element of information leakage for each player. Parameterizing the game in terms of uncertainty on each side, information leakage, and cost of sampling, we consider the Stackelberg Equilibrium (SE) concept where one of the players acts as the leader and the other one as the follower. By focusing our attention on stationary probabilistic sampling policies, we characterize the SE of this game and provide simulations to show the efficacy of our results.
Optimizing Profitability in Timely Gossip Networks
May 01, 2024



We consider a communication system where a group of users, interconnected in a bidirectional gossip network, wishes to follow a time-varying source, e.g., updates on an event, in real-time. The users wish to maintain their expected version ages below a threshold, and can either rely on gossip from their neighbors or directly subscribe to a server publishing about the event, if the former option does not meet the timeliness requirements. The server wishes to maximize its profit by increasing subscriptions from users and minimizing event sampling frequency to reduce costs. This leads to a Stackelberg game between the server and the users where the sender is the leader deciding its sampling frequency and the users are the followers deciding their subscription strategies. We investigate equilibrium strategies for low-connectivity and high-connectivity topologies.
How to Make Money From Fresh Data: Subscription Strategies in Age-Based Systems
Apr 24, 2024



We consider a communication system consisting of a server that tracks and publishes updates about a time-varying data source or event, and a gossip network of users interested in closely tracking the event. The timeliness of the information is measured through the version age of information. The users wish to have their expected version ages remain below a threshold, and have the option to either rely on gossip from their neighbors or subscribe to the server directly to follow updates about the event if the former option does not meet the timeliness requirements. The server wishes to maximize its profit by increasing the number of subscribers and reducing costs associated with the frequent sampling of the event. We model the problem setup as a Stackelberg game between the server and the users, where the server commits to a frequency of sampling the event, and the users make decisions on whether to subscribe or not. As an initial work, we focus on directed networks with unidirectional flow of information and obtain the optimal equilibrium strategies for all the players. We provide simulation results to confirm the theoretical findings and provide additional insights.
Policy Optimization finds Nash Equilibrium in Regularized General-Sum LQ Games
Mar 25, 2024In this paper, we investigate the impact of introducing relative entropy regularization on the Nash Equilibria (NE) of General-Sum $N$-agent games, revealing the fact that the NE of such games conform to linear Gaussian policies. Moreover, it delineates sufficient conditions, contingent upon the adequacy of entropy regularization, for the uniqueness of the NE within the game. As Policy Optimization serves as a foundational approach for Reinforcement Learning (RL) techniques aimed at finding the NE, in this work we prove the linear convergence of a policy optimization algorithm which (subject to the adequacy of entropy regularization) is capable of provably attaining the NE. Furthermore, in scenarios where the entropy regularization proves insufficient, we present a $\delta$-augmentation technique, which facilitates the achievement of an $\epsilon$-NE within the game.
Learning How to Strategically Disclose Information
Mar 13, 2024Strategic information disclosure, in its simplest form, considers a game between an information provider (sender) who has access to some private information that an information receiver is interested in. While the receiver takes an action that affects the utilities of both players, the sender can design information (or modify beliefs) of the receiver through signal commitment, hence posing a Stackelberg game. However, obtaining a Stackelberg equilibrium for this game traditionally requires the sender to have access to the receiver's objective. In this work, we consider an online version of information design where a sender interacts with a receiver of an unknown type who is adversarially chosen at each round. Restricting attention to Gaussian prior and quadratic costs for the sender and the receiver, we show that $\mathcal{O}(\sqrt{T})$ regret is achievable with full information feedback, where $T$ is the total number of interactions between the sender and the receiver. Further, we propose a novel parametrization that allows the sender to achieve $\mathcal{O}(\sqrt{T})$ regret for a general convex utility function. We then consider the Bayesian Persuasion problem with an additional cost term in the objective function, which penalizes signaling policies that are more informative and obtain $\mathcal{O}(\log(T))$ regret. Finally, we establish a sublinear regret bound for the partial information feedback setting and provide simulations to support our theoretical results.
Using Timeliness in Tracking Infections
Mar 07, 2022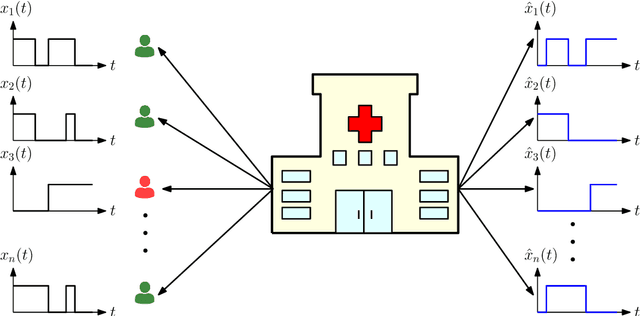
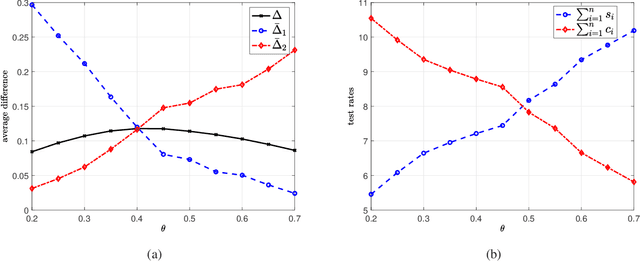
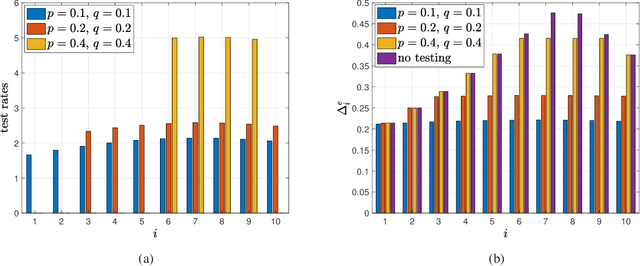
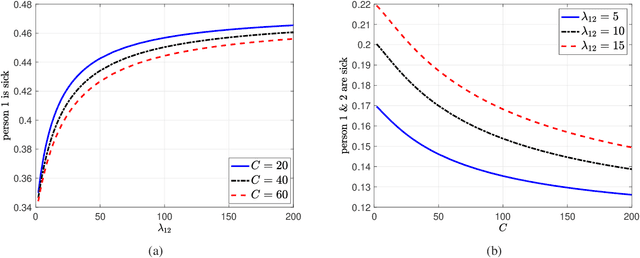
We consider real-time timely tracking of infection status (e.g., covid-19) of individuals in a population. In this work, a health care provider wants to detect infected people as well as people who have recovered from the disease as quickly as possible. In order to measure the timeliness of the tracking process, we use the long-term average difference between the actual infection status of the people and their real-time estimate by the health care provider based on the most recent test results. We first find an analytical expression for this average difference for given test rates, infection rates and recovery rates of people. Next, we propose an alternating minimization based algorithm to find the test rates that minimize the average difference. We observe that if the total test rate is limited, instead of testing all members of the population equally, only a portion of the population may be tested in unequal rates calculated based on their infection and recovery rates. Next, we characterize the average difference when the test measurements are erroneous (i.e., noisy). Further, we consider the case where the infection status of individuals may be dependent, which happens when an infected person spreads the disease to another person if they are not detected and isolated by the health care provider. Then, we consider an age of incorrect information based error metric where the staleness metric increases linearly over time as long as the health care provider does not detect the changes in the infection status of the people. In numerical results, we observe that an increased population size increases diversity of people with different infection and recovery rates which may be exploited to spend testing capacity more efficiently. Depending on the health care provider's preferences, test rate allocation can be adjusted to detect either the infected people or the recovered people more quickly.