 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The irruption of cryptocurrencies into Twitter cashtags: a classifying solution
Dec 14, 2023
There is a consensus about the good sensing characteristics of Twitter to mine and uncover knowledge in financial markets, being considered a relevant feeder for taking decisions about buying or holding stock shares and even for detecting stock manipulation. Although Twitter hashtags allow to aggregate topic-related content, a specific mechanism for financial information also exists: Cashtag. However, the irruption of cryptocurrencies has resulted in a significant degradation on the cashtag-based aggregation of posts. Unfortunately, Twitter' users may use homonym tickers to refer to cryptocurrencies and to companies in stock markets, which means that filtering by cashtag may result on both posts referring to stock companies and cryptocurrencies. This research proposes automated classifiers to distinguish conflicting cashtags and, so, their container tweets by analyzing the distinctive features of tweets referring to stock companies and cryptocurrencies. As experiment, this paper analyses the interference between cryptocurrencies and company tickers in the London Stock Exchange (LSE), specifically, companies in the main and alternative market indices FTSE-100 and AIM-100. Heuristic-based as well as supervised classifiers are proposed and their advantages and drawbacks, including their ability to self-adapt to Twitter usage changes, are discussed. The experiment confirms a significant distortion in collected data when colliding or homonym cashtags exist, i.e., the same \$ acronym to refer to company tickers and cryptocurrencies. According to our results, the distinctive features of posts including cryptocurrencies or company tickers support accurate classification of colliding tweets (homonym cashtags) and Independent Models, as the most detached classifiers from training data, have the potential to be trans-applicability (in different stock markets) while retaining performance.
Well-calibrated Confidence Measures for Multi-label Text Classification with a Large Number of Labels
Dec 14, 2023
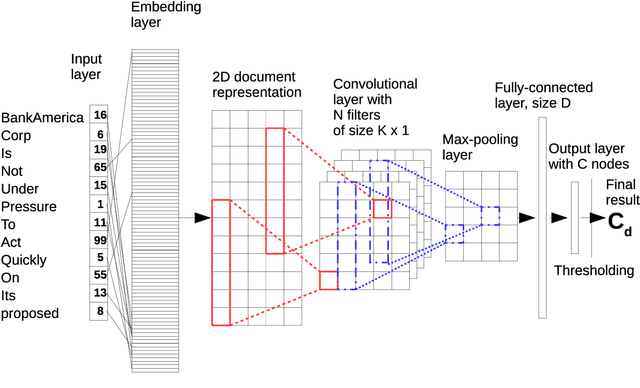
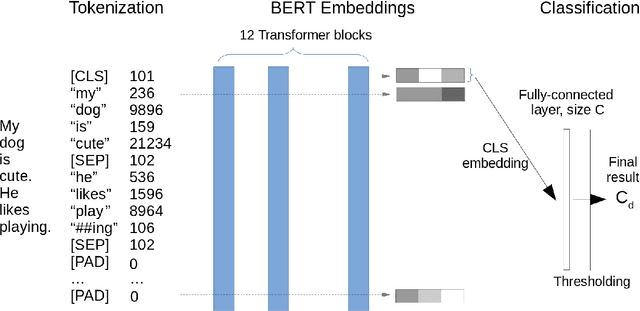
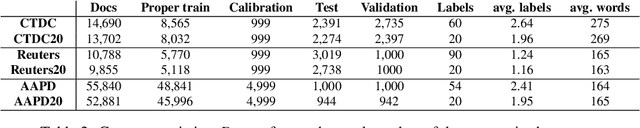
We extend our previous work on Inductive Conformal Prediction (ICP) for multi-label text classification and present a novel approach for addressing the computational inefficiency of the Label Powerset (LP) ICP, arrising when dealing with a high number of unique labels. We present experimental results using the original and the proposed efficient LP-ICP on two English and one Czech language data-sets. Specifically, we apply the LP-ICP on three deep Artificial Neural Network (ANN) classifiers of two types: one based on contextualised (bert) and two on non-contextualised (word2vec) word-embeddings. In the LP-ICP setting we assign nonconformity scores to label-sets from which the corresponding p-values and prediction-sets are determined. Our approach deals with the increased computational burden of LP by eliminating from consideration a significant number of label-sets that will surely have p-values below the specified significance level. This reduces dramatically the computational complexity of the approach while fully respecting the standard CP guarantees. Our experimental results show that the contextualised-based classifier surpasses the non-contextualised-based ones and obtains state-of-the-art performance for all data-sets examined. The good performance of the underlying classifiers is carried on to their ICP counterparts without any significant accuracy loss, but with the added benefits of ICP, i.e. the confidence information encapsulated in the prediction sets. We experimentally demonstrate that the resulting prediction sets can be tight enough to be practically useful even though the set of all possible label-sets contains more than $1e+16$ combinations. Additionally, the empirical error rates of the obtained prediction-sets confirm that our outputs are well-calibrated.
The performance of multiple language models in identifying offensive language on social media
Dec 10, 2023Text classification is an important topic in the field of natural language processing. It has been preliminarily applied in information retrieval, digital library, automatic abstracting, text filtering, word semantic discrimination and many other fields. The aim of this research is to use a variety of algorithms to test the ability to identify offensive posts and evaluate their performance against a variety of assessment methods. The motivation for this project is to reduce the harm of these languages to human censors by automating the screening of offending posts. The field is a new one, and despite much interest in the past two years, there has been no focus on the object of the offence. Through the experiment of this project, it should inspire future research on identification methods as well as identification content.
Transformer-based Selective Super-Resolution for Efficient Image Refinement
Dec 10, 2023Conventional super-resolution methods suffer from two drawbacks: substantial computational cost in upscaling an entire large image, and the introduction of extraneous or potentially detrimental information for downstream computer vision tasks during the refinement of the background. To solve these issues, we propose a novel transformer-based algorithm, Selective Super-Resolution (SSR), which partitions images into non-overlapping tiles, selects tiles of interest at various scales with a pyramid architecture, and exclusively reconstructs these selected tiles with deep features. Experimental results on three datasets demonstrate the efficiency and robust performance of our approach for super-resolution. Compared to the state-of-the-art methods, the FID score is reduced from 26.78 to 10.41 with 40% reduction in computation cost for the BDD100K dataset. The source code is available at https://github.com/destiny301/SSR.
LineConGraphs: Line Conversation Graphs for Effective Emotion Recognition using Graph Neural Networks
Dec 04, 2023Emotion Recognition in Conversations (ERC) is a critical aspect of affective computing, and it has many practical applications in healthcare, education, chatbots, and social media platforms. Earlier approaches for ERC analysis involved modeling both speaker and long-term contextual information using graph neural network architectures. However, it is ideal to deploy speaker-independent models for real-world applications. Additionally, long context windows can potentially create confusion in recognizing the emotion of an utterance in a conversation. To overcome these limitations, we propose novel line conversation graph convolutional network (LineConGCN) and graph attention (LineConGAT) models for ERC analysis. These models are speaker-independent and built using a graph construction strategy for conversations -- line conversation graphs (LineConGraphs). The conversational context in LineConGraphs is short-term -- limited to one previous and future utterance, and speaker information is not part of the graph. We evaluate the performance of our proposed models on two benchmark datasets, IEMOCAP and MELD, and show that our LineConGAT model outperforms the state-of-the-art methods with an F1-score of 64.58% and 76.50%. Moreover, we demonstrate that embedding sentiment shift information into line conversation graphs further enhances the ERC performance in the case of GCN models.
Augmenting Channel Charting with Classical Wireless Source Localization Techniques
Dec 04, 2023Channel Charting aims to construct a map of the radio environment by leveraging similarity relationships found in high-dimensional channel state information. Although resulting channel charts usually accurately represent local neighborhood relationships, even under conditions with strong multipath propagation, they often fall short in capturing global geometric features. On the other hand, classical model-based localization methods, such as triangulation and multilateration, can easily localize signal sources in the global coordinate frame. However, these methods rely heavily on the assumption of line-of-sight channels and distributed antenna deployments. Based on measured data, we compare classical source localization techniques to channel charts with respect to localization performance. We suggest and evaluate methods to enhance Channel Charting with model-based localization approaches: One approach involves using information derived from classical localization methods to map channel chart locations to physical positions after conventional training of the forward charting function. Foremost, though, we suggest to incorporate information from model-based approaches during the training of the forward charting function in what we call "augmented Channel Charting". We demonstrate that Channel Charting can outperform classical localization methods on the considered dataset.
neural concatenative singing voice conversion: rethinking concatenation-based approach for one-shot singing voice conversion
Dec 08, 2023Any-to-any singing voice conversion is confronted with a significant challenge of ``timbre leakage'' issue caused by inadequate disentanglement between the content and the speaker timbre. To address this issue, this study introduces a novel neural concatenative singing voice conversion (NeuCoSVC) framework. The NeuCoSVC framework comprises a self-supervised learning (SSL) representation extractor, a neural harmonic signal generator, and a waveform synthesizer. Specifically, the SSL extractor condenses the audio into a sequence of fixed-dimensional SSL features. The harmonic signal generator produces both raw and filtered harmonic signals as the pitch information by leveraging a linear time-varying (LTV) filter. Finally, the audio generator reconstructs the audio waveform based on the SSL features, as well as the harmonic signals and the loudness information. During inference, the system performs voice conversion by substituting source SSL features with their nearest counterparts from a matching pool, which comprises SSL representations extracted from the target audio, while the raw harmonic signals and the loudness are extracted from the source audio and are kept unchanged. Since the utilized SSL features in the conversion stage are directly from the target audio, the proposed framework has great potential to address the ``timbre leakage'' issue caused by previous disentanglement-based approaches. Experimental results confirm that the proposed system delivers much better performance than the speaker embedding approach (disentanglement-based) in the context of one-shot SVC across intra-language, cross-language, and cross-domain evaluations.
BESTMVQA: A Benchmark Evaluation System for Medical Visual Question Answering
Dec 13, 2023Medical Visual Question Answering (Med-VQA) is a very important task in healthcare industry, which answers a natural language question with a medical image. Existing VQA techniques in information systems can be directly applied to solving the task. However, they often suffer from (i) the data insufficient problem, which makes it difficult to train the state of the arts (SOTAs) for the domain-specific task, and (ii) the reproducibility problem, that many existing models have not been thoroughly evaluated in a unified experimental setup. To address these issues, this paper develops a Benchmark Evaluation SysTem for Medical Visual Question Answering, denoted by BESTMVQA. Given self-collected clinical data, our system provides a useful tool for users to automatically build Med-VQA datasets, which helps overcoming the data insufficient problem. Users also can conveniently select a wide spectrum of SOTA models from our model library to perform a comprehensive empirical study. With simple configurations, our system automatically trains and evaluates the selected models over a benchmark dataset, and reports the comprehensive results for users to develop new techniques or perform medical practice. Limitations of existing work are overcome (i) by the data generation tool, which automatically constructs new datasets from unstructured clinical data, and (ii) by evaluating SOTAs on benchmark datasets in a unified experimental setup. The demonstration video of our system can be found at https://youtu.be/QkEeFlu1x4A. Our code and data will be available soon.
CoRTEx: Contrastive Learning for Representing Terms via Explanations with Applications on Constructing Biomedical Knowledge Graphs
Dec 13, 2023Objective: Biomedical Knowledge Graphs play a pivotal role in various biomedical research domains. Concurrently, term clustering emerges as a crucial step in constructing these knowledge graphs, aiming to identify synonymous terms. Due to a lack of knowledge, previous contrastive learning models trained with Unified Medical Language System (UMLS) synonyms struggle at clustering difficult terms and do not generalize well beyond UMLS terms. In this work, we leverage the world knowledge from Large Language Models (LLMs) and propose Contrastive Learning for Representing Terms via Explanations (CoRTEx) to enhance term representation and significantly improves term clustering. Materials and Methods: The model training involves generating explanations for a cleaned subset of UMLS terms using ChatGPT. We employ contrastive learning, considering term and explanation embeddings simultaneously, and progressively introduce hard negative samples. Additionally, a ChatGPT-assisted BIRCH algorithm is designed for efficient clustering of a new ontology. Results: We established a clustering test set and a hard negative test set, where our model consistently achieves the highest F1 score. With CoRTEx embeddings and the modified BIRCH algorithm, we grouped 35,580,932 terms from the Biomedical Informatics Ontology System (BIOS) into 22,104,559 clusters with O(N) queries to ChatGPT. Case studies highlight the model's efficacy in handling challenging samples, aided by information from explanations. Conclusion: By aligning terms to their explanations, CoRTEx demonstrates superior accuracy over benchmark models and robustness beyond its training set, and it is suitable for clustering terms for large-scale biomedical ontologies.
STF: Spatial Temporal Fusion for Trajectory Prediction
Nov 29, 2023Trajectory prediction is a challenging task that aims to predict the future trajectory of vehicles or pedestrians over a short time horizon based on their historical positions. The main reason is that the trajectory is a kind of complex data, including spatial and temporal information, which is crucial for accurate prediction. Intuitively, the more information the model can capture, the more precise the future trajectory can be predicted. However, previous works based on deep learning methods processed spatial and temporal information separately, leading to inadequate spatial information capture, which means they failed to capture the complete spatial information. Therefore, it is of significance to capture information more fully and effectively on vehicle interactions. In this study, we introduced an integrated 3D graph that incorporates both spatial and temporal edges. Based on this, we proposed the integrated 3D graph, which considers the cross-time interaction information. In specific, we design a Spatial-Temporal Fusion (STF) model including Multi-layer perceptions (MLP) and Graph Attention (GAT) to capture the spatial and temporal information historical trajectories simultaneously on the 3D graph. Our experiment on the ApolloScape Trajectory Datasets shows that the proposed STF outperforms several baseline methods, especially on the long-time-horizon trajectory prediction.