 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BED: Bi-Encoder-Decoder Model for Canonical Relation Extraction
Dec 12, 2023

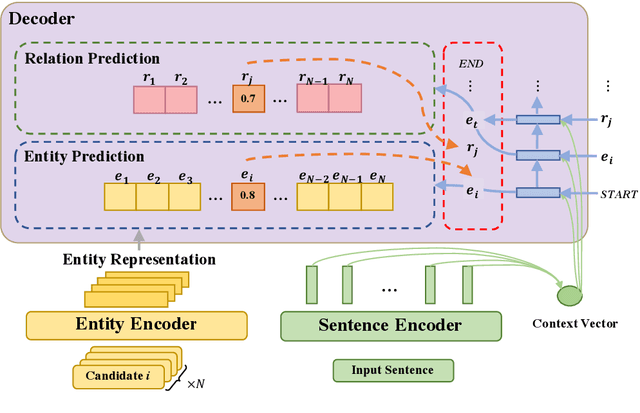
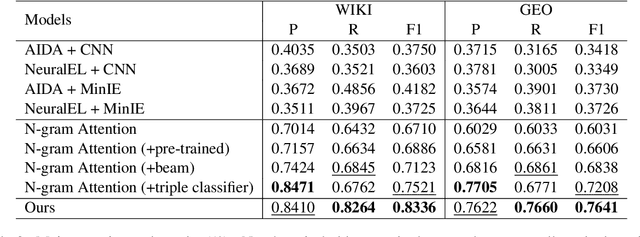
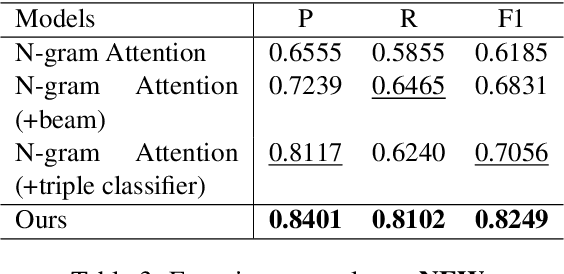
Canonical relation extraction aims to extract relational triples from sentences, where the triple elements (entity pairs and their relationship) are mapped to the knowledge base. Recently, methods based on the encoder-decoder architecture are proposed and achieve promising results. However, these methods cannot well utilize the entity information, which is merely used as augmented training data. Moreover, they are incapable of representing novel entities, since no embeddings have been learned for them. In this paper, we propose a novel framework, Bi-Encoder-Decoder (BED), to solve the above issues. Specifically, to fully utilize entity information, we employ an encoder to encode semantics of this information, leading to high-quality entity representations. For novel entities, given a trained entity encoder, their representations can be easily generated. Experimental results on two datasets show that, our method achieves a significant performance improvement over the previous state-of-the-art and handle novel entities well without retraining.
UnionDet: Union-Level Detector Towards Real-Time Human-Object Interaction Detection
Dec 19, 2023Recent advances in deep neural networks have achieved significant progress in detecting individual objects from an image. However, object detection is not sufficient to fully understand a visual scene. Towards a deeper visual understanding, the interactions between objects, especially humans and objects are essential. Most prior works have obtained this information with a bottom-up approach, where the objects are first detected and the interactions are predicted sequentially by pairing the objects. This is a major bottleneck in HOI detection inference time. To tackle this problem, we propose UnionDet, a one-stage meta-architecture for HOI detection powered by a novel union-level detector that eliminates this additional inference stage by directly capturing the region of interaction. Our one-stage detector for human-object interaction shows a significant reduction in interaction prediction time 4x~14x while outperforming state-of-the-art methods on two public datasets: V-COCO and HICO-DET.
ReRoGCRL: Representation-based Robustness in Goal-Conditioned Reinforcement Learning
Dec 19, 2023While Goal-Conditioned Reinforcement Learning (GCRL) has gained attention, its algorithmic robustness against adversarial perturbations remains unexplored. The attacks and robust representation training methods that are designed for traditional RL become less effective when applied to GCRL. To address this challenge, we first propose the Semi-Contrastive Representation attack, a novel approach inspired by the adversarial contrastive attack. Unlike existing attacks in RL, it only necessitates information from the policy function and can be seamlessly implemented during deployment. Then, to mitigate the vulnerability of existing GCRL algorithms, we introduce Adversarial Representation Tactics, which combines Semi-Contrastive Adversarial Augmentation with Sensitivity-Aware Regularizer to improve the adversarial robustness of the underlying RL agent against various types of perturbations. Extensive experiments validate the superior performance of our attack and defence methods across multiple state-of-the-art GCRL algorithms. Our tool ReRoGCRL is available at https://github.com/TrustAI/ReRoGCRL.
PhysRFANet: Physics-Guided Neural Network for Real-Time Prediction of Thermal Effect During Radiofrequency Ablation Treatment
Dec 21, 2023Radiofrequency ablation (RFA) is a widely used minimally invasive technique for ablating solid tumors. Achieving precise personalized treatment necessitates feedback information on in situ thermal effects induced by the RFA procedure. While computer simulation facilitates the prediction of electrical and thermal phenomena associated with RFA, its practical implementation in clinical settings is hindered by high computational demands. In this paper, we propose a physics-guided neural network model, named PhysRFANet, to enable real-time prediction of thermal effect during RFA treatment. The networks, designed for predicting temperature distribution and the corresponding ablation lesion, were trained using biophysical computational models that integrated electrostatics, bio-heat transfer, and cell necrosis, alongside magnetic resonance (MR) images of breast cancer patients. Validation of the computational model was performed through experiments on ex vivo bovine liver tissue. Our model demonstrated a 96% Dice score in predicting the lesion volume and an RMSE of 0.4854 for temperature distribution when tested with foreseen tumor images. Notably, even with unforeseen images, it achieved a 93% Dice score for the ablation lesion and an RMSE of 0.6783 for temperature distribution. All networks were capable of inferring results within 10 ms. The presented technique, applied to optimize the placement of the electrode for a specific target region, holds significant promise in enhancing the safety and efficacy of RFA treatments.
InfoVisDial: An Informative Visual Dialogue Dataset by Bridging Large Multimodal and Language Models
Dec 21, 2023In this paper, we build a visual dialogue dataset, named InfoVisDial, which provides rich informative answers in each round even with external knowledge related to the visual content. Different from existing datasets where the answer is compact and short, InfoVisDial contains long free-form answers with rich information in each round of dialogue. For effective data collection, the key idea is to bridge the large-scale multimodal model (e.g., GIT) and the language models (e.g., GPT-3). GIT can describe the image content even with scene text, while GPT-3 can generate informative dialogue based on the image description and appropriate prompting techniques. With such automatic pipeline, we can readily generate informative visual dialogue data at scale. Then, we ask human annotators to rate the generated dialogues to filter the low-quality conversations.Human analyses show that InfoVisDial covers informative and diverse dialogue topics: $54.4\%$ of the dialogue rounds are related to image scene texts, and $36.7\%$ require external knowledge. Each round's answer is also long and open-ended: $87.3\%$ of answers are unique with an average length of $8.9$, compared with $27.37\%$ and $2.9$ in VisDial. Last, we propose a strong baseline by adapting the GIT model for the visual dialogue task and fine-tune the model on InfoVisDial. Hopefully, our work can motivate more effort on this direction.
Robust Active Measuring under Model Uncertainty
Dec 18, 2023Partial observability and uncertainty are common problems in sequential decision-making that particularly impede the use of formal models such as Markov decision processes (MDPs). However, in practice, agents may be able to employ costly sensors to measure their environment and resolve partial observability by gathering information. Moreover, imprecise transition functions can capture model uncertainty. We combine these concepts and extend MDPs to robust active-measuring MDPs (RAM-MDPs). We present an active-measure heuristic to solve RAM-MDPs efficiently and show that model uncertainty can, counterintuitively, let agents take fewer measurements. We propose a method to counteract this behavior while only incurring a bounded additional cost. We empirically compare our methods to several baselines and show their superior scalability and performance.
Generative AI Beyond LLMs: System Implications of Multi-Modal Generation
Dec 22, 2023As the development of large-scale Generative AI models evolve beyond text (1D) generation to include image (2D) and video (3D) generation, processing spatial and temporal information presents unique challenges to quality, performance, and efficiency. We present the first work towards understanding this new system design space for multi-modal text-to-image (TTI) and text-to-video (TTV) generation models. Current model architecture designs are bifurcated into 2 categories: Diffusion- and Transformer-based models. Our systematic performance characterization on a suite of eight representative TTI/TTV models shows that after state-of-the-art optimization techniques such as Flash Attention are applied, Convolution accounts for up to 44% of execution time for Diffusion-based TTI models, while Linear layers consume up to 49% of execution time for Transformer-based models. We additionally observe that Diffusion-based TTI models resemble the Prefill stage of LLM inference, and benefit from 1.1-2.5x greater speedup from Flash Attention than Transformer-based TTI models that resemble the Decode phase. Since optimizations designed for LLMs do not map directly onto TTI/TTV models, we must conduct a thorough characterization of these workloads to gain insights for new optimization opportunities. In doing so, we define sequence length in the context of TTI/TTV models and observe sequence length can vary up to 4x in Diffusion model inference. We additionally observe temporal aspects of TTV workloads pose unique system bottlenecks, with Temporal Attention accounting for over 60% of total Attention time. Overall, our in-depth system performance characterization is a critical first step towards designing efficient and deployable systems for emerging TTI/TTV workloads.
Latents2Semantics: Leveraging the Latent Space of Generative Models for Localized Style Manipulation of Face Images
Dec 22, 2023With the metaverse slowly becoming a reality and given the rapid pace of developments toward the creation of digital humans, the need for a principled style editing pipeline for human faces is bound to increase manifold. We cater to this need by introducing the Latents2Semantics Autoencoder (L2SAE), a Generative Autoencoder model that facilitates highly localized editing of style attributes of several Regions of Interest (ROIs) in face images. The L2SAE learns separate latent representations for encoded images' structure and style information. Thus, allowing for structure-preserving style editing of the chosen ROIs. The encoded structure representation is a multichannel 2D tensor with reduced spatial dimensions, which captures both local and global structure properties. The style representation is a 1D tensor that captures global style attributes. In our framework, we slice the structure representation to build strong and disentangled correspondences with different ROIs. Consequentially, style editing of the chosen ROIs amounts to a simple combination of (a) the ROI-mask generated from the sliced structure representation and (b) the decoded image with global style changes, generated from the manipulated (using Gaussian noise) global style and unchanged structure tensor. Style editing sans additional human supervision is a significant win over SOTA style editing pipelines because most existing works require additional human effort (supervision) post-training for attributing semantic meaning to style edits. We also do away with iterative-optimization-based inversion or determining controllable latent directions post-training, which requires additional computationally expensive operations. We provide qualitative and quantitative results for the same over multiple applications, such as selective style editing and swapping using test images sampled from several datasets.
AdaSub: Stochastic Optimization Using Second-Order Information in Low-Dimensional Subspaces
Nov 06, 2023We introduce AdaSub, a stochastic optimization algorithm that computes a search direction based on second-order information in a low-dimensional subspace that is defined adaptively based on available current and past information. Compared to first-order methods, second-order methods exhibit better convergence characteristics, but the need to compute the Hessian matrix at each iteration results in excessive computational expenses, making them impractical. To address this issue, our approach enables the management of computational expenses and algorithm efficiency by enabling the selection of the subspace dimension for the search. Our code is freely available on GitHub, and our preliminary numerical results demonstrate that AdaSub surpasses popular stochastic optimizers in terms of time and number of iterations required to reach a given accuracy.
Dual Branch Network Towards Accurate Printed Mathematical Expression Recognition
Dec 14, 2023Over the past years, Printed Mathematical Expression Recognition (PMER) has progressed rapidly. However, due to the insufficient context information captured by Convolutional Neural Networks, some mathematical symbols might be incorrectly recognized or missed. To tackle this problem, in this paper, a Dual Branch transformer-based Network (DBN) is proposed to learn both local and global context information for accurate PMER. In our DBN, local and global features are extracted simultaneously, and a Context Coupling Module (CCM) is developed to complement the features between the global and local contexts. CCM adopts an interactive manner so that the coupled context clues are highly correlated to each expression symbol. Additionally, we design a Dynamic Soft Target (DST) strategy to utilize the similarities among symbol categories for reasonable label generation. Our experimental results have demonstrated that DBN can accurately recognize mathematical expressions and has achieved state-of-the-art performance.