 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Tempo estimation as fully self-supervised binary classification
Jan 17, 2024
This paper addresses the problem of global tempo estimation in musical audio. Given that annotating tempo is time-consuming and requires certain musical expertise, few publicly available data sources exist to train machine learning models for this task. Towards alleviating this issue, we propose a fully self-supervised approach that does not rely on any human labeled data. Our method builds on the fact that generic (music) audio embeddings already encode a variety of properties, including information about tempo, making them easily adaptable for downstream tasks. While recent work in self-supervised tempo estimation aimed to learn a tempo specific representation that was subsequently used to train a supervised classifier, we reformulate the task into the binary classification problem of predicting whether a target track has the same or a different tempo compared to a reference. While the former still requires labeled training data for the final classification model, our approach uses arbitrary unlabeled music data in combination with time-stretching for model training as well as a small set of synthetically created reference samples for predicting the final tempo. Evaluation of our approach in comparison with the state-of-the-art reveals highly competitive performance when the constraint of finding the precise tempo octave is relaxed.
LLMs Accelerate Annotation for Medical Information Extraction
Dec 04, 2023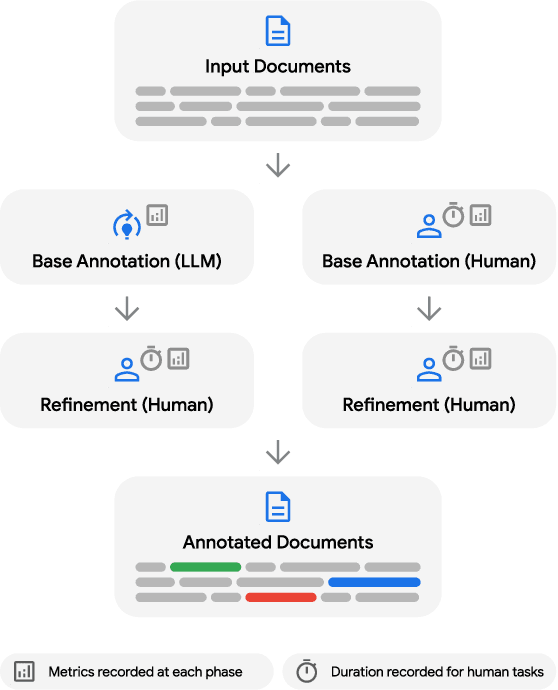
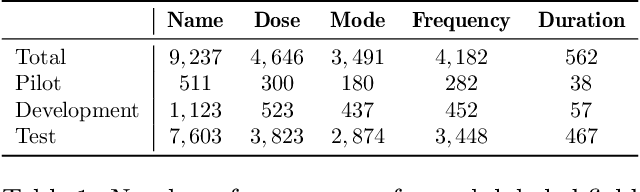
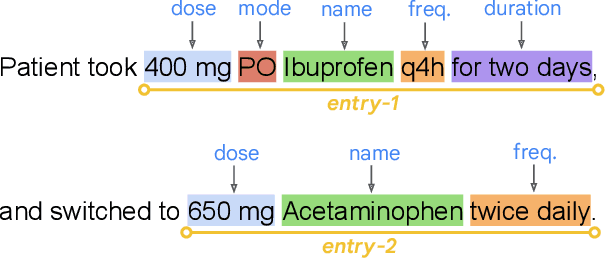
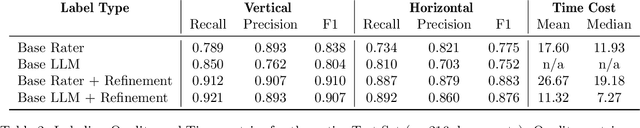
The unstructured nature of clinical notes within electronic health records often conceals vital patient-related information, making it challenging to access or interpret. To uncover this hidden information, specialized Natural Language Processing (NLP) models are required. However, training these models necessitates large amounts of labeled data, a process that is both time-consuming and costly when relying solely on human experts for annotation. In this paper, we propose an approach that combines Large Language Models (LLMs) with human expertise to create an efficient method for generating ground truth labels for medical text annotation. By utilizing LLMs in conjunction with human annotators, we significantly reduce the human annotation burden, enabling the rapid creation of labeled datasets. We rigorously evaluate our method on a medical information extraction task, demonstrating that our approach not only substantially cuts down on human intervention but also maintains high accuracy. The results highlight the potential of using LLMs to improve the utilization of unstructured clinical data, allowing for the swift deployment of tailored NLP solutions in healthcare.
An Autoregressive Text-to-Graph Framework for Joint Entity and Relation Extraction
Jan 15, 2024In this paper, we propose a novel method for joint entity and relation extraction from unstructured text by framing it as a conditional sequence generation problem. In contrast to conventional generative information extraction models that are left-to-right token-level generators, our approach is \textit{span-based}. It generates a linearized graph where nodes represent text spans and edges represent relation triplets. Our method employs a transformer encoder-decoder architecture with pointing mechanism on a dynamic vocabulary of spans and relation types. Our model can capture the structural characteristics and boundaries of entities and relations through span representations while simultaneously grounding the generated output in the original text thanks to the pointing mechanism. Evaluation on benchmark datasets validates the effectiveness of our approach, demonstrating competitive results. Code is available at https://github.com/urchade/ATG.
Any-Way Meta Learning
Jan 10, 2024Although meta-learning seems promising performance in the realm of rapid adaptability, it is constrained by fixed cardinality. When faced with tasks of varying cardinalities that were unseen during training, the model lacks its ability. In this paper, we address and resolve this challenge by harnessing `label equivalence' emerged from stochastic numeric label assignments during episodic task sampling. Questioning what defines ``true" meta-learning, we introduce the ``any-way" learning paradigm, an innovative model training approach that liberates model from fixed cardinality constraints. Surprisingly, this model not only matches but often outperforms traditional fixed-way models in terms of performance, convergence speed, and stability. This disrupts established notions about domain generalization. Furthermore, we argue that the inherent label equivalence naturally lacks semantic information. To bridge this semantic information gap arising from label equivalence, we further propose a mechanism for infusing semantic class information into the model. This would enhance the model's comprehension and functionality. Experiments conducted on renowned architectures like MAML and ProtoNet affirm the effectiveness of our method.
Automated Answer Validation using Text Similarity
Jan 13, 2024Automated answer validation can help improve learning outcomes by providing appropriate feedback to learners, and by making question answering systems and online learning solutions more widely available. There have been some works in science question answering which show that information retrieval methods outperform neural methods, especially in the multiple choice version of this problem. We implement Siamese neural network models and produce a generalised solution to this problem. We compare our supervised model with other text similarity based solutions.
ModelNet-O: A Large-Scale Synthetic Dataset for Occlusion-Aware Point Cloud Classification
Jan 16, 2024Recently, 3D point cloud classification has made significant progress with the help of many datasets. However, these datasets do not reflect the incomplete nature of real-world point clouds caused by occlusion, which limits the practical application of current methods. To bridge this gap, we propose ModelNet-O, a large-scale synthetic dataset of 123,041 samples that emulate real-world point clouds with self-occlusion caused by scanning from monocular cameras. ModelNet-O is 10 times larger than existing datasets and offers more challenging cases to evaluate the robustness of existing methods. Our observation on ModelNet-O reveals that well-designed sparse structures can preserve structural information of point clouds under occlusion, motivating us to propose a robust point cloud processing method that leverages a critical point sampling (CPS) strategy in a multi-level manner. We term our method PointMLS. Through extensive experiments, we demonstrate that our PointMLS achieves state-of-the-art results on ModelNet-O and competitive results on regular datasets, and it is robust and effective. More experiments also demonstrate the robustness and effectiveness of PointMLS.
SpecSTG: A Fast Spectral Diffusion Framework for Probabilistic Spatio-Temporal Traffic Forecasting
Jan 16, 2024Traffic forecasting, a crucial application of spatio-temporal graph (STG) learning, has traditionally relied on deterministic models for accurate point estimations. Yet, these models fall short of identifying latent risks of unexpected volatility in future observations. To address this gap, probabilistic methods, especially variants of diffusion models, have emerged as uncertainty-aware solutions. However, existing diffusion methods typically focus on generating separate future time series for individual sensors in the traffic network, resulting in insufficient involvement of spatial network characteristics in the probabilistic learning process. To better leverage spatial dependencies and systematic patterns inherent in traffic data, we propose SpecSTG, a novel spectral diffusion framework. Our method generates the Fourier representation of future time series, transforming the learning process into the spectral domain enriched with spatial information. Additionally, our approach incorporates a fast spectral graph convolution designed for Fourier input, alleviating the computational burden associated with existing models. Numerical experiments show that SpecSTG achieves outstanding performance with traffic flow and traffic speed datasets compared to state-of-the-art baselines. The source code for SpecSTG is available at https://anonymous.4open.science/r/SpecSTG.
SCoFT: Self-Contrastive Fine-Tuning for Equitable Image Generation
Jan 16, 2024Accurate representation in media is known to improve the well-being of the people who consume it. Generative image models trained on large web-crawled datasets such as LAION are known to produce images with harmful stereotypes and misrepresentations of cultures. We improve inclusive representation in generated images by (1) engaging with communities to collect a culturally representative dataset that we call the Cross-Cultural Understanding Benchmark (CCUB) and (2) proposing a novel Self-Contrastive Fine-Tuning (SCoFT) method that leverages the model's known biases to self-improve. SCoFT is designed to prevent overfitting on small datasets, encode only high-level information from the data, and shift the generated distribution away from misrepresentations encoded in a pretrained model. Our user study conducted on 51 participants from 5 different countries based on their self-selected national cultural affiliation shows that fine-tuning on CCUB consistently generates images with higher cultural relevance and fewer stereotypes when compared to the Stable Diffusion baseline, which is further improved with our SCoFT technique.
Reproducibility Analysis and Enhancements for Multi-Aspect Dense Retriever with Aspect Learning
Jan 16, 2024Multi-aspect dense retrieval aims to incorporate aspect information (e.g., brand and category) into dual encoders to facilitate relevance matching. As an early and representative multi-aspect dense retriever, MADRAL learns several extra aspect embeddings and fuses the explicit aspects with an implicit aspect "OTHER" for final representation. MADRAL was evaluated on proprietary data and its code was not released, making it challenging to validate its effectiveness on other datasets. We failed to reproduce its effectiveness on the public MA-Amazon data, motivating us to probe the reasons and re-examine its components. We propose several component alternatives for comparisons, including replacing "OTHER" with "CLS" and representing aspects with the first several content tokens. Through extensive experiments, we confirm that learning "OTHER" from scratch in aspect fusion is harmful. In contrast, our proposed variants can greatly enhance the retrieval performance. Our research not only sheds light on the limitations of MADRAL but also provides valuable insights for future studies on more powerful multi-aspect dense retrieval models. Code will be released at: https://github.com/sunxiaojie99/Reproducibility-for-MADRAL.
A Content-Based Novelty Measure for Scholarly Publications: A Proof of Concept
Jan 16, 2024Novelty, akin to gene mutation in evolution, opens possibilities for scholarly advancement. Although peer review remains the gold standard for evaluating novelty in scholarly communication and resource allocation, the vast volume of submissions necessitates an automated measure of scholarly novelty. Adopting a perspective that views novelty as the atypical combination of existing knowledge, we introduce an information-theoretic measure of novelty in scholarly publications. This measure quantifies the degree of 'surprise' perceived by a language model that represents the word distribution of scholarly discourse. The proposed measure is accompanied by face and construct validity evidence; the former demonstrates correspondence to scientific common sense, and the latter is endorsed through alignment with novelty evaluations from a select panel of domain experts. Additionally, characterized by its interpretability, fine granularity, and accessibility, this measure addresses gaps prevalent in existing methods. We believe this measure holds great potential to benefit editors, stakeholders, and policymakers, and it provides a reliable lens for examining the relationship between novelty and academic dynamics such as creativity, interdisciplinarity, and scientific advances.