 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Relation Clustering in Narrative Knowledge Graphs
Nov 27, 2020


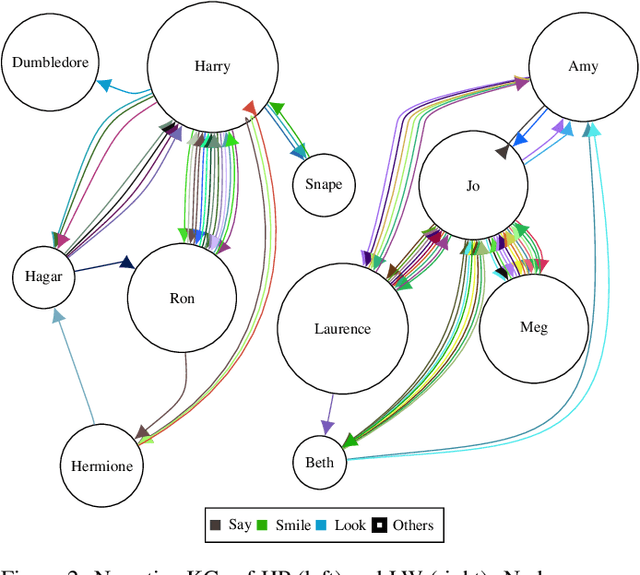
When coping with literary texts such as novels or short stories, the extraction of structured information in the form of a knowledge graph might be hindered by the huge number of possible relations between the entities corresponding to the characters in the novel and the consequent hurdles in gathering supervised information about them. Such issue is addressed here as an unsupervised task empowered by transformers: relational sentences in the original text are embedded (with SBERT) and clustered in order to merge together semantically similar relations. All the sentences in the same cluster are finally summarized (with BART) and a descriptive label extracted from the summary. Preliminary tests show that such clustering might successfully detect similar relations, and provide a valuable preprocessing for semi-supervised approaches.
A Location-Sensitive Local Prototype Network for Few-Shot Medical Image Segmentation
Mar 18, 2021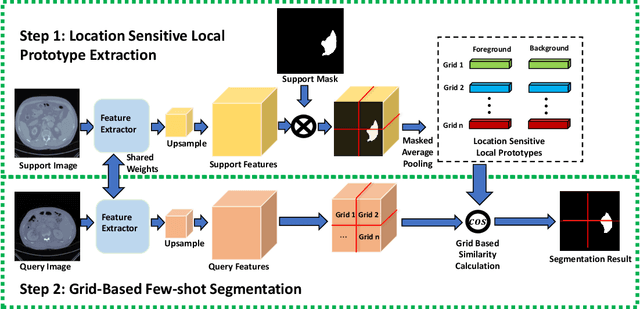
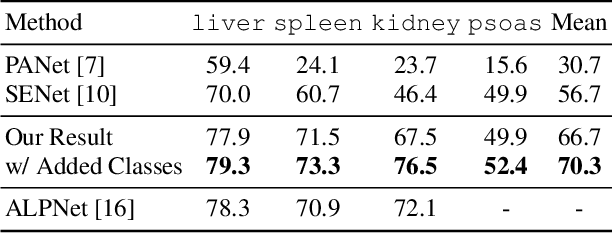
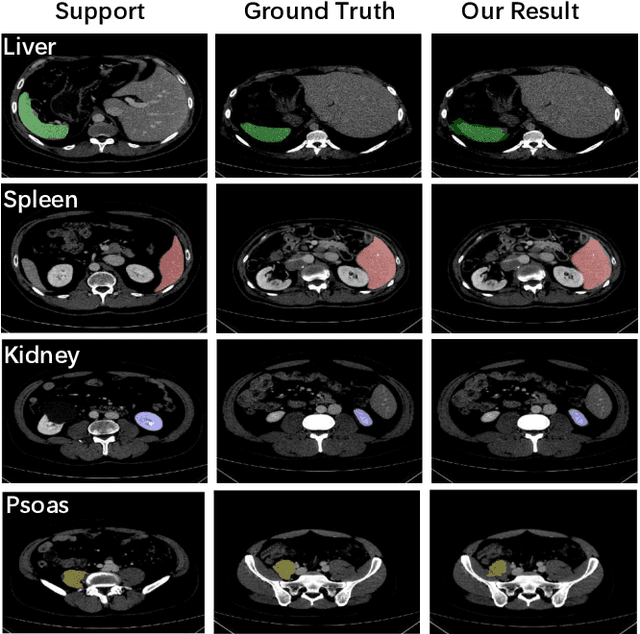
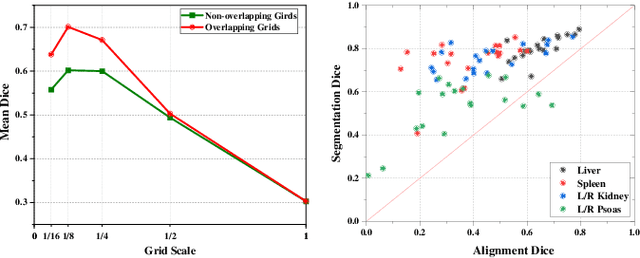
Despite the tremendous success of deep neural networks in medical image segmentation, they typically require a large amount of costly, expert-level annotated data. Few-shot segmentation approaches address this issue by learning to transfer knowledge from limited quantities of labeled examples. Incorporating appropriate prior knowledge is critical in designing high-performance few-shot segmentation algorithms. Since strong spatial priors exist in many medical imaging modalities, we propose a prototype-based method -- namely, the location-sensitive local prototype network -- that leverages spatial priors to perform few-shot medical image segmentation. Our approach divides the difficult problem of segmenting the entire image with global prototypes into easily solvable subproblems of local region segmentation with local prototypes. For organ segmentation experiments on the VISCERAL CT image dataset, our method outperforms the state-of-the-art approaches by 10% in the mean Dice coefficient. Extensive ablation studies demonstrate the substantial benefits of incorporating spatial information and confirm the effectiveness of our approach.
Temporal Bilinear Encoding Network of Audio-Visual Features at Low Sampling Rates
Dec 18, 2020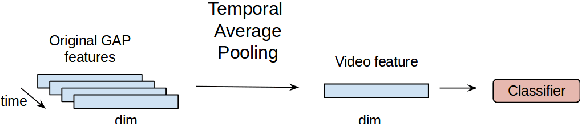

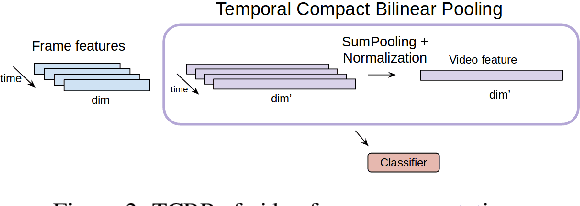
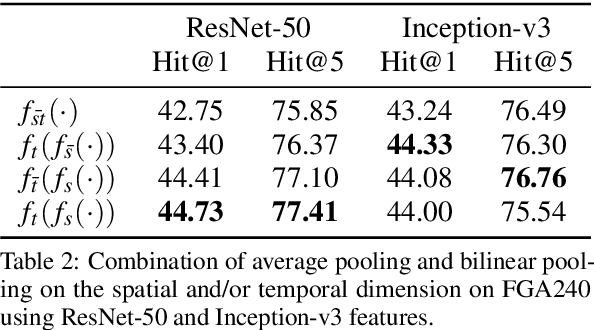
Current deep learning based video classification architectures are typically trained end-to-end on large volumes of data and require extensive computational resources. This paper aims to exploit audio-visual information in video classification with a 1 frame per second sampling rate. We propose Temporal Bilinear Encoding Networks (TBEN) for encoding both audio and visual long range temporal information using bilinear pooling and demonstrate bilinear pooling is better than average pooling on the temporal dimension for videos with low sampling rate. We also embed the label hierarchy in TBEN to further improve the robustness of the classifier. Experiments on the FGA240 fine-grained classification dataset using TBEN achieve a new state-of-the-art (hit@1=47.95%). We also exploit the possibility of incorporating TBEN with multiple decoupled modalities like visual semantic and motion features: experiments on UCF101 sampled at 1 FPS achieve close to state-of-the-art accuracy (hit@1=91.03%) while requiring significantly less computational resources than competing approaches for both training and prediction.
Self-Paced Uncertainty Estimation for One-shot Person Re-Identification
Apr 19, 2021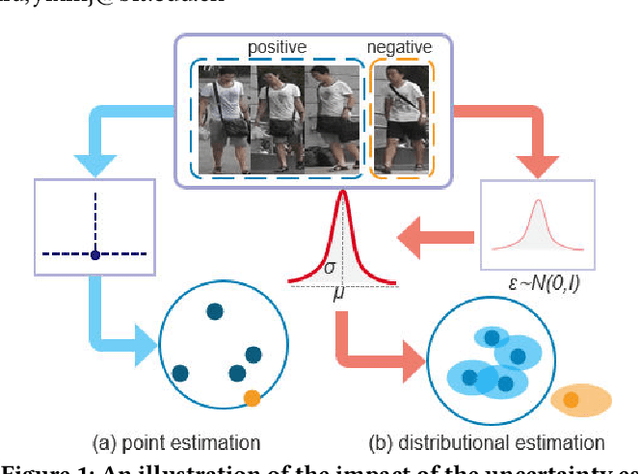
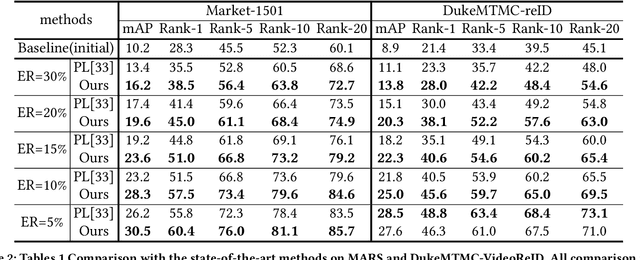
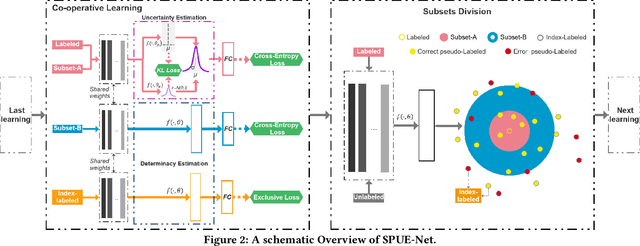
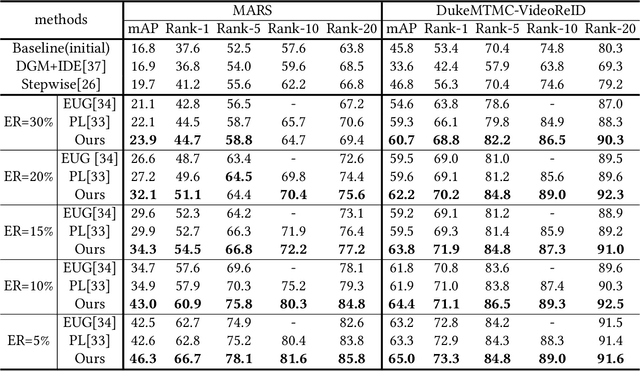
The one-shot Person Re-ID scenario faces two kinds of uncertainties when constructing the prediction model from $X$ to $Y$. The first is model uncertainty, which captures the noise of the parameters in DNNs due to a lack of training data. The second is data uncertainty, which can be divided into two sub-types: one is image noise, where severe occlusion and the complex background contain irrelevant information about the identity; the other is label noise, where mislabeled affects visual appearance learning. In this paper, to tackle these issues, we propose a novel Self-Paced Uncertainty Estimation Network (SPUE-Net) for one-shot Person Re-ID. By introducing a self-paced sampling strategy, our method can estimate the pseudo-labels of unlabeled samples iteratively to expand the labeled samples gradually and remove model uncertainty without extra supervision. We divide the pseudo-label samples into two subsets to make the use of training samples more reasonable and effective. In addition, we apply a Co-operative learning method of local uncertainty estimation combined with determinacy estimation to achieve better hidden space feature mining and to improve the precision of selected pseudo-labeled samples, which reduces data uncertainty. Extensive comparative evaluation experiments on video-based and image-based datasets show that SPUE-Net has significant advantages over the state-of-the-art methods.
Graph-based Facial Affect Analysis: A Review of Methods, Applications and Challenges
Apr 12, 2021
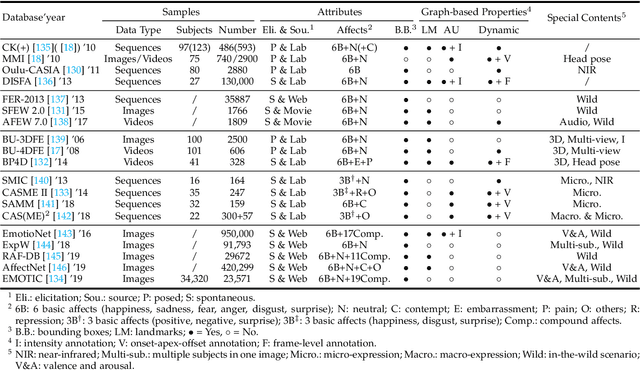
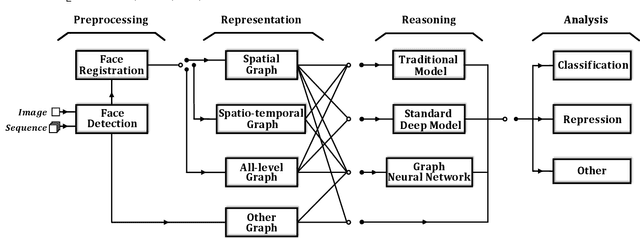
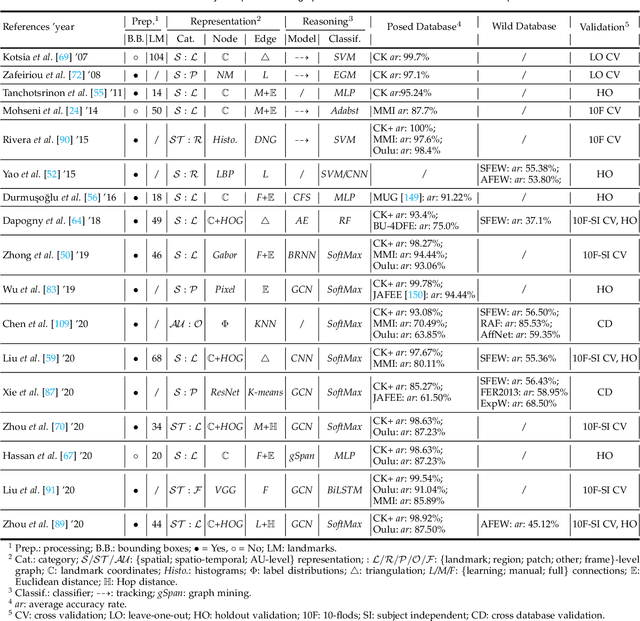
Facial affect analysis (FAA) using visual signals is a key step in human-computer interactions. Early methods mainly focus on extracting appearance and geometry features associated with human affects, while ignore the latent semantic information among individual facial changes, leading to limited performance and generalization. Recent trends attempt to establish a graph-based representation to model these semantic relationships and develop learning frameworks to leverage it for different FAA tasks. In this paper, we provide a comprehensive review of graph-based FAA, including the evolution of algorithms and their applications. First, we introduce the background knowledge of facial affect analysis, especially on the role of graph. We then discuss approaches that are widely used for graph-based affective representation in literatures and show a trend towards graph construction. For the relational reasoning in graph-based FAA, we categorize the existing studies according to their usage of traditional methods or deep models, with a special emphasis on latest graph neural networks. Experimental comparisons of the state-of-the-art on standard FAA problems are also summarized. Finally, we discuss the challenges and potential directions. As far as we know, this is the first survey of graph-based FAA methods, and our findings can serve as a reference point for future research in this field.
Unsupervised Classification for Polarimetric SAR Data Using Variational Bayesian Wishart Mixture Model with Inverse Gamma-Gamma Prior
Apr 04, 2021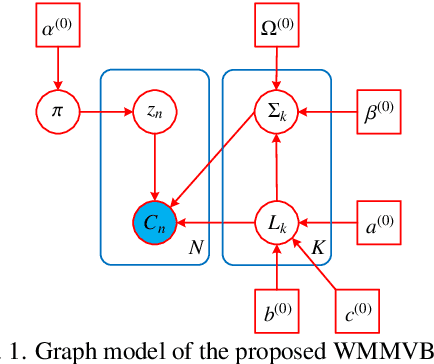
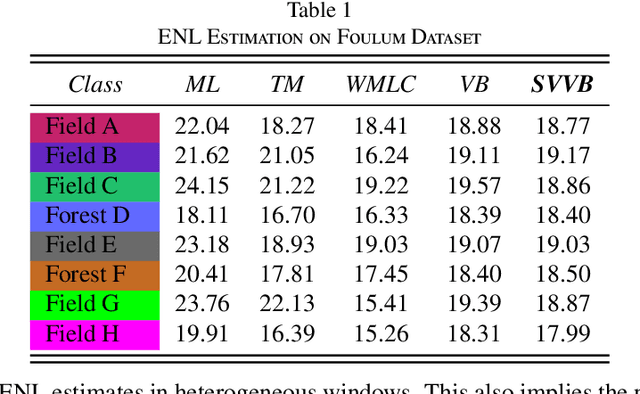
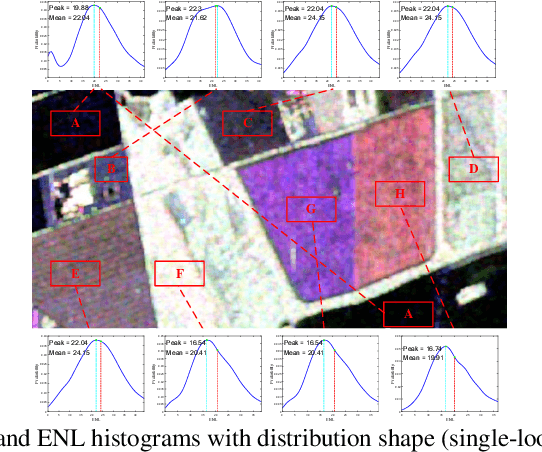
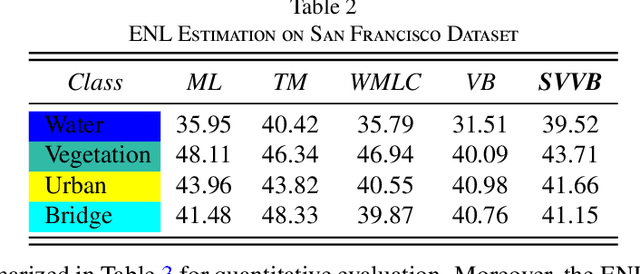
Although various clustering methods have been successfully applied to polarimetric synthetic aperture radar (PolSAR) image clustering tasks, most of the available approaches fail to realize automatic determination of cluster number, nor have they derived an exact distribution for the number of looks. To overcome these limitations and achieve robust unsupervised classification of PolSAR images, this paper proposes the variational Bayesian Wishart mixture model (VBWMM), where variational Bayesian expectation maximization (VBEM) technique is applied to estimate the variational posterior distribution of model parameters iteratively. Besides, covariance matrix similarity and geometric similarity are combined to incorporate spatial information of PolSAR images. Furthermore, we derive a new distribution named inverse gamma-gamma (IGG) prior that originates from the log-likelihood function of proposed model to enable efficient handling of number of looks. As a result, we obtain a closed-form variational lower bound, which can be used to evaluate the convergence of proposed model. We validate the superiority of proposed method in clustering performance on four real-measured datasets and demonstrate significant improvements towards conventional methods. As a by-product, the experiments show that our proposed IGG prior is effective in estimating the number of looks.
Class-Balanced Distillation for Long-Tailed Visual Recognition
Apr 12, 2021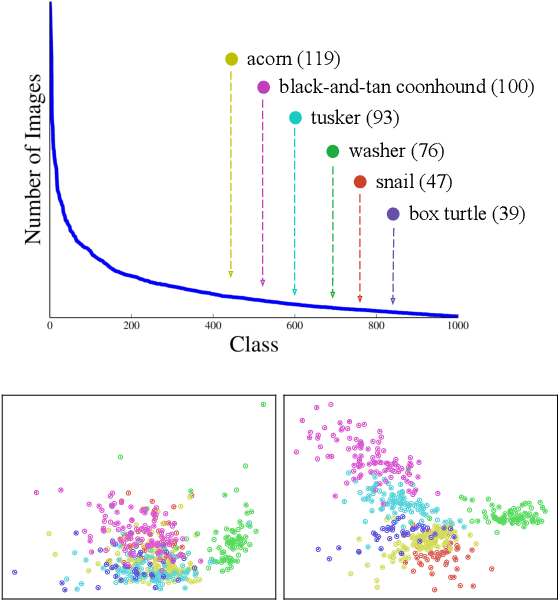

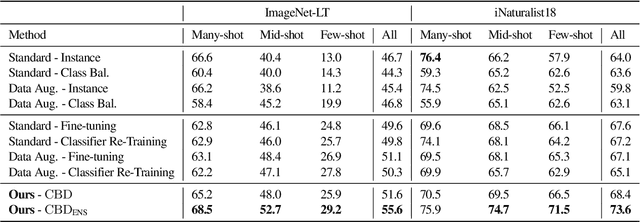
Real-world imagery is often characterized by a significant imbalance of the number of images per class, leading to long-tailed distributions. An effective and simple approach to long-tailed visual recognition is to learn feature representations and a classifier separately, with instance and class-balanced sampling, respectively. In this work, we introduce a new framework, by making the key observation that a feature representation learned with instance sampling is far from optimal in a long-tailed setting. Our main contribution is a new training method, referred to as Class-Balanced Distillation (CBD), that leverages knowledge distillation to enhance feature representations. CBD allows the feature representation to evolve in the second training stage, guided by the teacher learned in the first stage. The second stage uses class-balanced sampling, in order to focus on under-represented classes. This framework can naturally accommodate the usage of multiple teachers, unlocking the information from an ensemble of models to enhance recognition capabilities. Our experiments show that the proposed technique consistently outperforms the state of the art on long-tailed recognition benchmarks such as ImageNet-LT, iNaturalist17 and iNaturalist18. The experiments also show that our method does not sacrifice the accuracy of head classes to improve the performance of tail classes, unlike most existing work.
From Point to Space: 3D Moving Human Pose Estimation Using Commodity WiFi
Dec 28, 2020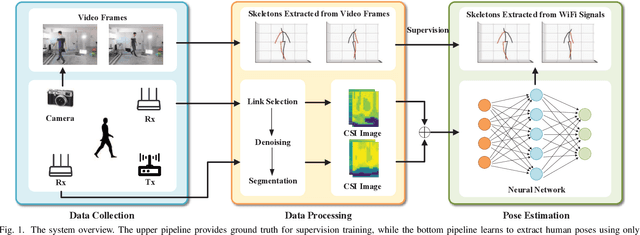

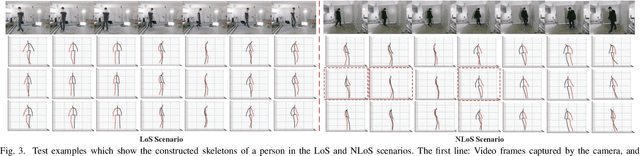
In this paper, we present Wi-Mose, the first 3D moving human pose estimation system using commodity WiFi. Previous WiFi-based works have achieved 2D and 3D pose estimation. These solutions either capture poses from one perspective or construct poses of people who are at a fixed point, preventing their wide adoption in daily scenarios. To reconstruct 3D poses of people who move throughout the space rather than a fixed point, we fuse the amplitude and phase into Channel State Information (CSI) images which can provide both pose and position information. Besides, we design a neural network to extract features that are only associated with poses from CSI images and then convert the features into key-point coordinates. Experimental results show that Wi-Mose can localize key-point with 29.7mm and 37.8mm Procrustes analysis Mean Per Joint Position Error (P-MPJPE) in the Line of Sight (LoS) and Non-Line of Sight (NLoS) scenarios, respectively, achieving higher performance than the state-of-the-art method. The results indicate that Wi-Mose can capture high-precision 3D human poses throughout the space.
Factual Probing Is [MASK]: Learning vs. Learning to Recall
Apr 12, 2021![Figure 1 for Factual Probing Is [MASK]: Learning vs. Learning to Recall](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F319ec14e78fee69ba754a652bf43329c58d2a2b9%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for Factual Probing Is [MASK]: Learning vs. Learning to Recall](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F319ec14e78fee69ba754a652bf43329c58d2a2b9%2F3-Table1-1.png&w=640&q=75)
![Figure 3 for Factual Probing Is [MASK]: Learning vs. Learning to Recall](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F319ec14e78fee69ba754a652bf43329c58d2a2b9%2F4-Table2-1.png&w=640&q=75)
![Figure 4 for Factual Probing Is [MASK]: Learning vs. Learning to Recall](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F319ec14e78fee69ba754a652bf43329c58d2a2b9%2F6-Figure2-1.png&w=640&q=75)
Petroni et al. (2019) demonstrated that it is possible to retrieve world facts from a pre-trained language model by expressing them as cloze-style prompts and interpret the model's prediction accuracy as a lower bound on the amount of factual information it encodes. Subsequent work has attempted to tighten the estimate by searching for better prompts, using a disjoint set of facts as training data. In this work, we make two complementary contributions to better understand these factual probing techniques. First, we propose OptiPrompt, a novel and efficient method which directly optimizes in continuous embedding space. We find this simple method is able to predict an additional 6.4% of facts in the LAMA benchmark. Second, we raise a more important question: Can we really interpret these probing results as a lower bound? Is it possible that these prompt-search methods learn from the training data too? We find, somewhat surprisingly, that the training data used by these methods contains certain regularities of the underlying fact distribution, and all the existing prompt methods, including ours, are able to exploit them for better fact prediction. We conduct a set of control experiments to disentangle "learning" from "learning to recall", providing a more detailed picture of what different prompts can reveal about pre-trained language models.
Self-Supervised Adaptation for Video Super-Resolution
Mar 18, 2021
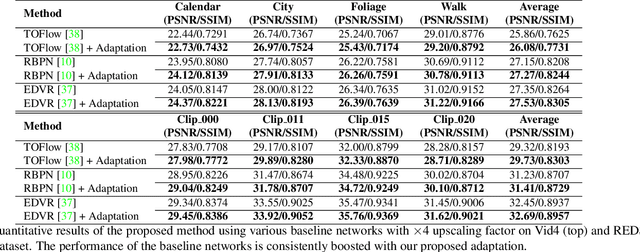
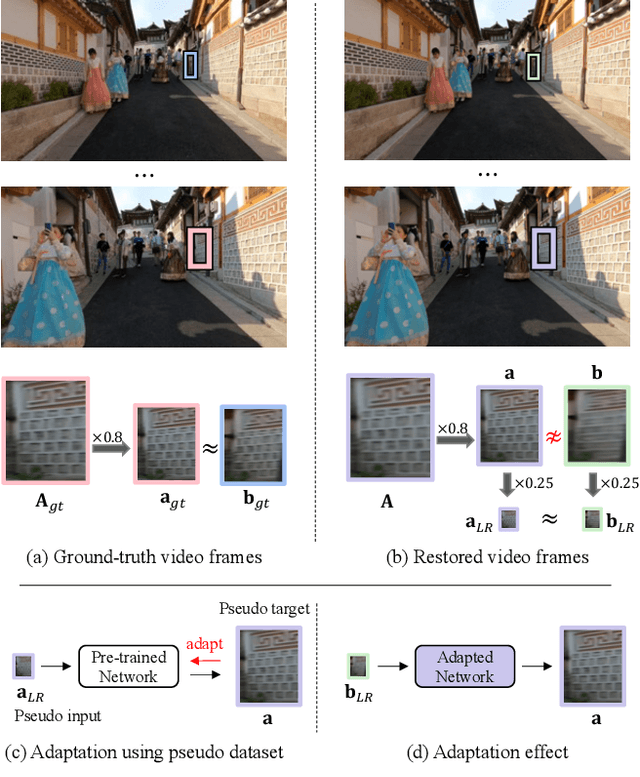
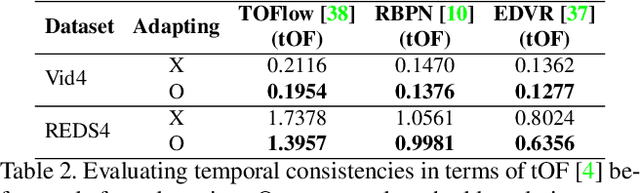
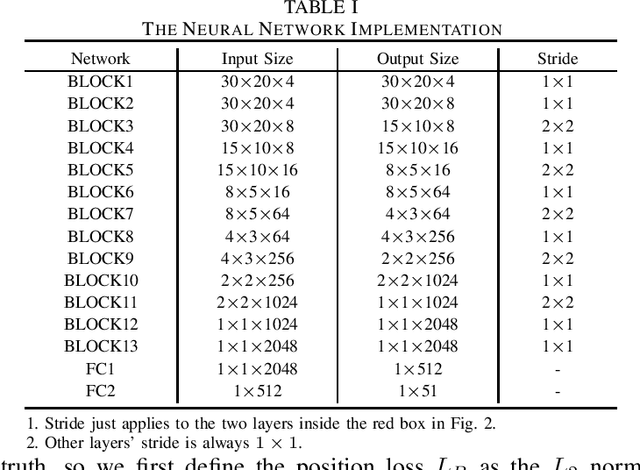
Recent single-image super-resolution (SISR) networks, which can adapt their network parameters to specific input images, have shown promising results by exploiting the information available within the input data as well as large external datasets. However, the extension of these self-supervised SISR approaches to video handling has yet to be studied. Thus, we present a new learning algorithm that allows conventional video super-resolution (VSR) networks to adapt their parameters to test video frames without using the ground-truth datasets. By utilizing many self-similar patches across space and time, we improve the performance of fully pre-trained VSR networks and produce temporally consistent video frames. Moreover, we present a test-time knowledge distillation technique that accelerates the adaptation speed with less hardware resources. In our experiments, we demonstrate that our novel learning algorithm can fine-tune state-of-the-art VSR networks and substantially elevate performance on numerous benchmark datasets.