 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VersaGNN: a Versatile accelerator for Graph neural networks
May 04, 2021
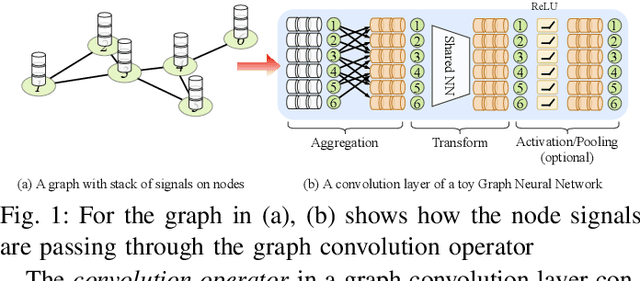
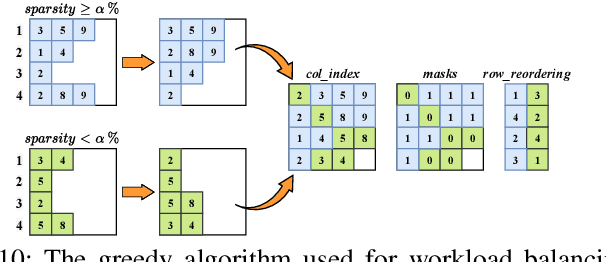
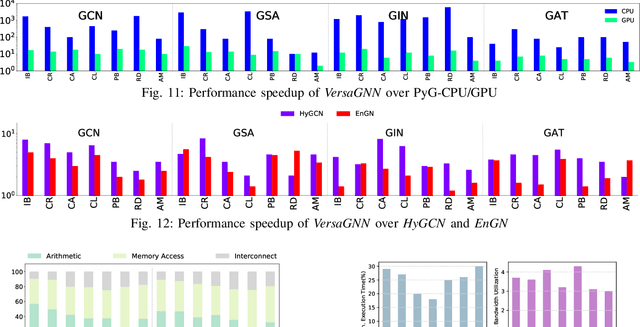
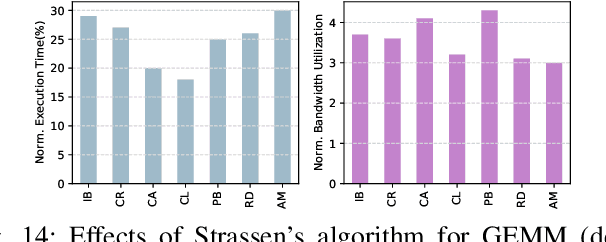
\textit{Graph Neural Network} (GNN) is a promising approach for analyzing graph-structured data that tactfully captures their dependency information via node-level message passing. It has achieved state-of-the-art performances in many tasks, such as node classification, graph matching, clustering, and graph generation. As GNNs operate on non-Euclidean data, their irregular data access patterns cause considerable computational costs and overhead on conventional architectures, such as GPU and CPU. Our analysis shows that GNN adopts a hybrid computing model. The \textit{Aggregation} (or \textit{Message Passing}) phase performs vector additions where vectors are fetched with irregular strides. The \textit{Transformation} (or \textit{Node Embedding}) phase can be either dense or sparse-dense matrix multiplication. In this work, We propose \textit{VersaGNN}, an ultra-efficient, systolic-array-based versatile hardware accelerator that unifies dense and sparse matrix multiplication. By applying this single optimized systolic array to both aggregation and transformation phases, we have significantly reduced chip sizes and energy consumption. We then divide the computing engine into blocked systolic arrays to support the \textit{Strassen}'s algorithm for dense matrix multiplication, dramatically scaling down the number of multiplications and enabling high-throughput computation of GNNs. To balance the workload of sparse-dense matrix multiplication, we also introduced a greedy algorithm to combine sparse sub-matrices of compressed format into condensed ones to reduce computational cycles. Compared with current state-of-the-art GNN software frameworks, \textit{VersaGNN} achieves on average 3712$\times$ speedup with 1301.25$\times$ energy reduction on CPU, and 35.4$\times$ speedup with 17.66$\times$ energy reduction on GPU.
CSIT-Free Federated Edge Learning via Reconfigurable Intelligent Surface
Feb 22, 2021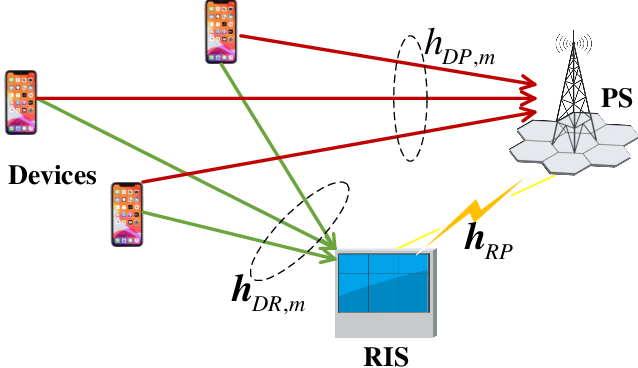
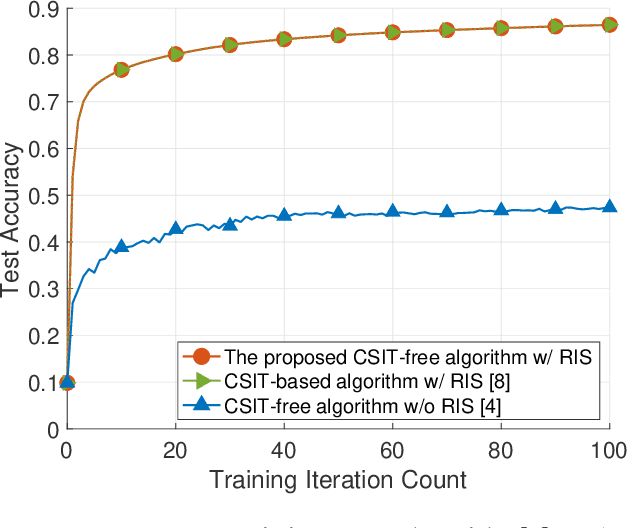
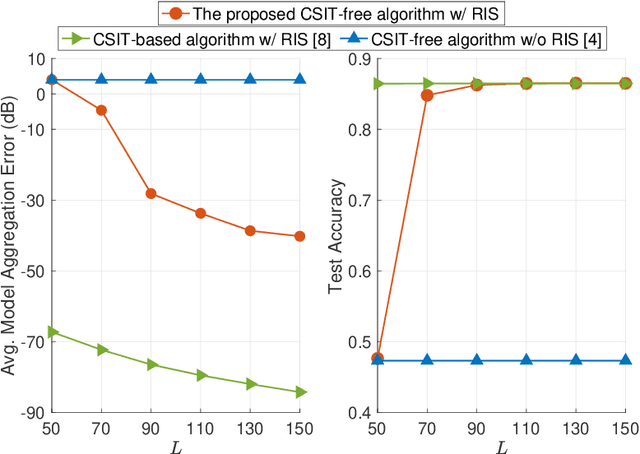

We study over-the-air model aggregation in federated edge learning (FEEL) systems, where channel state information at the transmitters (CSIT) is assumed to be unavailable. We leverage the reconfigurable intelligent surface (RIS) technology to align the cascaded channel coefficients for CSIT-free model aggregation. To this end, we jointly optimize the RIS and the receiver by minimizing the aggregation error under the channel alignment constraint. We then develop a difference-of-convex algorithm for the resulting non-convex optimization. Numerical experiments on image classification show that the proposed method is able to achieve a similar learning accuracy as the state-of-the-art CSIT-based solution, demonstrating the efficiency of our approach in combating the lack of CSIT.
From Weakly Supervised Learning to Biquality Learning, a brief introduction
Dec 16, 2020


The field of Weakly Supervised Learning (WSL) has recently seen a surge of popularity, with numerous papers addressing different types of "supervision deficiencies". In WSL use cases, a variety of situations exists where the collected "information" is imperfect. The paradigm of WSL attempts to list and cover these problems with associated solutions. In this paper, we review the research progress on WSL with the aim to make it as a brief introduction to this field. We present the three axis of WSL cube and an overview of most of all the elements of their facets. We propose three measurable quantities that acts as coordinates in the previously defined cube namely: Quality, Adaptability and Quantity of information. Thus we suggest that Biquality Learning framework can be defined as a plan of the WSL cube and propose to re-discover previously unrelated patches in WSL literature as a unified Biquality Learning literature.
A fast and accurate similarity-constrained subspace clustering algorithm for land cover segmentation
Apr 14, 2021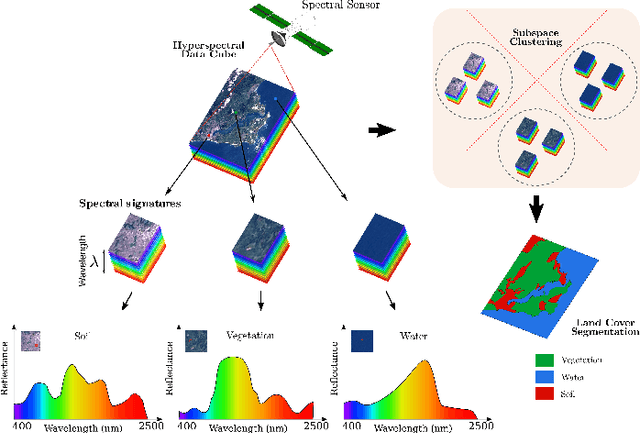
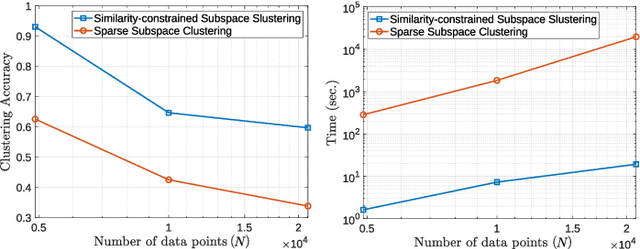
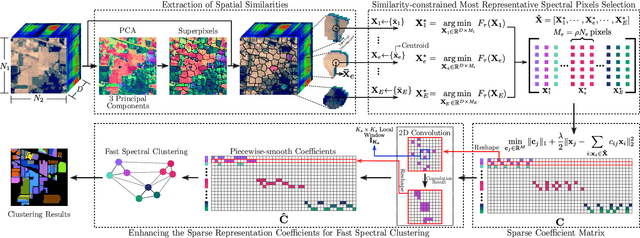
Accurate land cover segmentation of spectral images is challenging and has drawn widespread attention in remote sensing due to its inherent complexity. Although significant efforts have been made for developing a variety of methods, most of them rely on supervised strategies. Subspace clustering methods, such as Sparse Subspace Clustering (SSC), have become a popular tool for unsupervised learning due to their high performance. However, the computational complexity of SSC methods prevents their use on large spectral remotely sensed datasets. Furthermore, since SSC ignores the spatial information in the spectral images, its discrimination capability is limited, hampering the clustering results' spatial homogeneity. To address these two relevant issues, in this paper, we propose a fast algorithm that obtains a sparse representation coefficient matrix by first selecting a small set of pixels that best represent their neighborhood. Then, it performs spatial filtering to enforce the connectivity of neighboring pixels and uses fast spectral clustering to get the final segmentation. Extensive simulations with our method demonstrate its effectiveness in land cover segmentation, obtaining remarkable high clustering performance compared with state-of-the-art SSC-based algorithms and even novel unsupervised-deep-learning-based methods. Besides, the proposed method is up to three orders of magnitude faster than SSC when clustering more than 2x10^4 spectral pixels.
MRI brain tumor segmentation and uncertainty estimation using 3D-UNet architectures
Dec 30, 2020
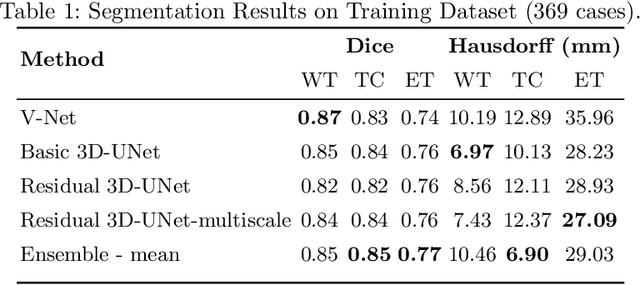
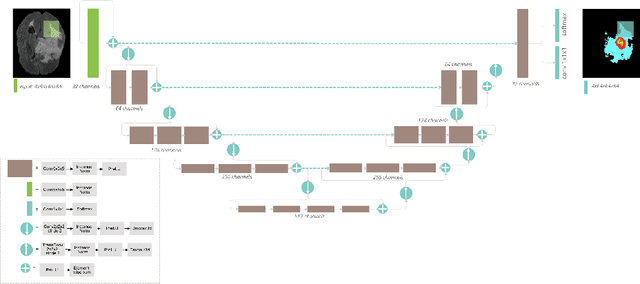
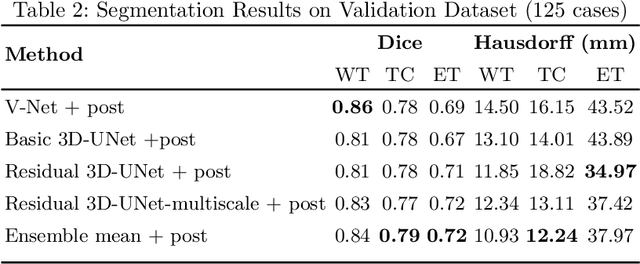
Automation of brain tumor segmentation in 3D magnetic resonance images (MRIs) is key to assess the diagnostic and treatment of the disease. In recent years, convolutional neural networks (CNNs) have shown improved results in the task. However, high memory consumption is still a problem in 3D-CNNs. Moreover, most methods do not include uncertainty information, which is especially critical in medical diagnosis. This work studies 3D encoder-decoder architectures trained with patch-based techniques to reduce memory consumption and decrease the effect of unbalanced data. The different trained models are then used to create an ensemble that leverages the properties of each model, thus increasing the performance. We also introduce voxel-wise uncertainty information, both epistemic and aleatoric using test-time dropout (TTD) and data-augmentation (TTA) respectively. In addition, a hybrid approach is proposed that helps increase the accuracy of the segmentation. The model and uncertainty estimation measurements proposed in this work have been used in the BraTS'20 Challenge for task 1 and 3 regarding tumor segmentation and uncertainty estimation.
The Surprising Performance of Simple Baselines for Misinformation Detection
Apr 14, 2021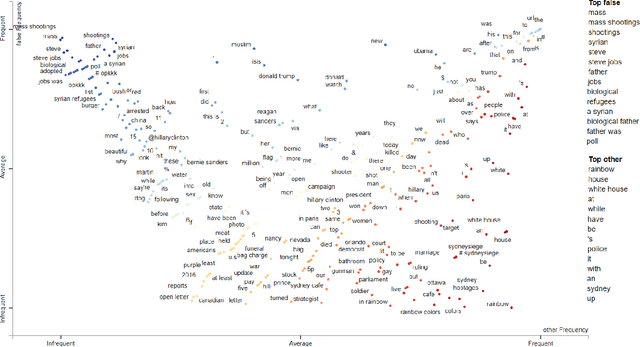
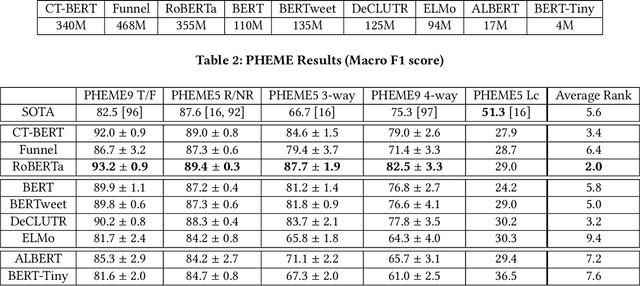
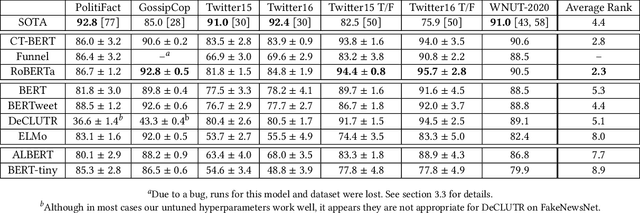
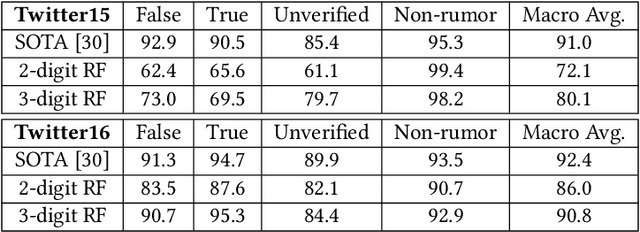
As social media becomes increasingly prominent in our day to day lives, it is increasingly important to detect informative content and prevent the spread of disinformation and unverified rumours. While many sophisticated and successful models have been proposed in the literature, they are often compared with older NLP baselines such as SVMs, CNNs, and LSTMs. In this paper, we examine the performance of a broad set of modern transformer-based language models and show that with basic fine-tuning, these models are competitive with and can even significantly outperform recently proposed state-of-the-art methods. We present our framework as a baseline for creating and evaluating new methods for misinformation detection. We further study a comprehensive set of benchmark datasets, and discuss potential data leakage and the need for careful design of the experiments and understanding of datasets to account for confounding variables. As an extreme case example, we show that classifying only based on the first three digits of tweet ids, which contain information on the date, gives state-of-the-art performance on a commonly used benchmark dataset for fake news detection --Twitter16. We provide a simple tool to detect this problem and suggest steps to mitigate it in future datasets.
Revisiting Light Field Rendering with Deep Anti-Aliasing Neural Network
Apr 28, 2021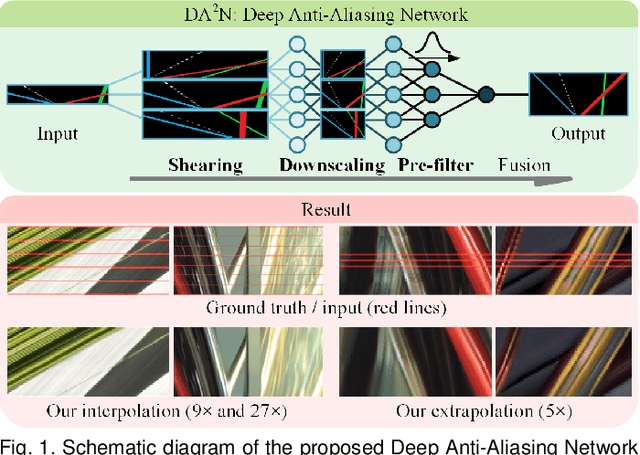

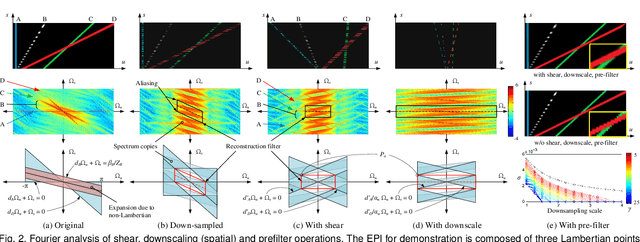
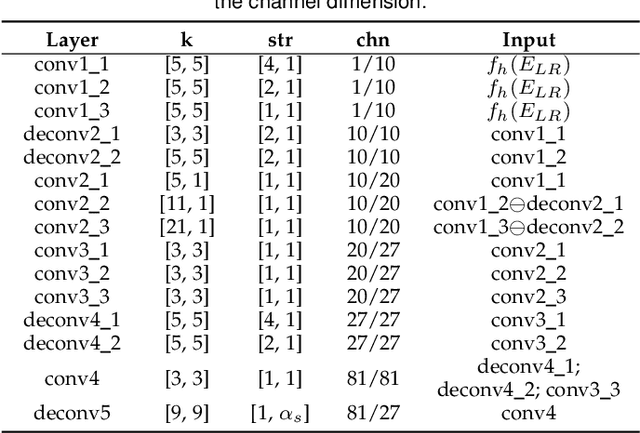
The light field (LF) reconstruction is mainly confronted with two challenges, large disparity and the non-Lambertian effect. Typical approaches either address the large disparity challenge using depth estimation followed by view synthesis or eschew explicit depth information to enable non-Lambertian rendering, but rarely solve both challenges in a unified framework. In this paper, we revisit the classic LF rendering framework to address both challenges by incorporating it with advanced deep learning techniques. First, we analytically show that the essential issue behind the large disparity and non-Lambertian challenges is the aliasing problem. Classic LF rendering approaches typically mitigate the aliasing with a reconstruction filter in the Fourier domain, which is, however, intractable to implement within a deep learning pipeline. Instead, we introduce an alternative framework to perform anti-aliasing reconstruction in the image domain and analytically show comparable efficacy on the aliasing issue. To explore the full potential, we then embed the anti-aliasing framework into a deep neural network through the design of an integrated architecture and trainable parameters. The network is trained through end-to-end optimization using a peculiar training set, including regular LFs and unstructured LFs. The proposed deep learning pipeline shows a substantial superiority in solving both the large disparity and the non-Lambertian challenges compared with other state-of-the-art approaches. In addition to the view interpolation for an LF, we also show that the proposed pipeline also benefits light field view extrapolation.
* 15 pages, 12 figures. Accepted by IEEE TPAMI
An Attention and Prediction Guided Visual System for Small Target Motion Detection in Complex Natural Environments
Apr 28, 2021
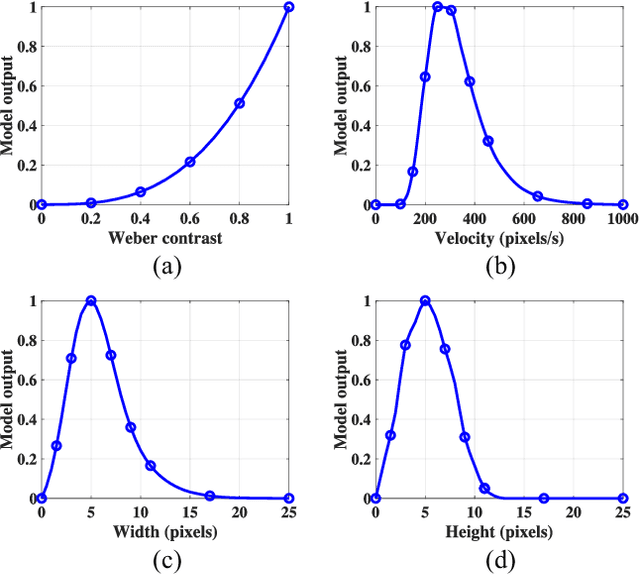
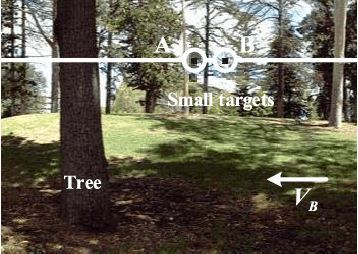
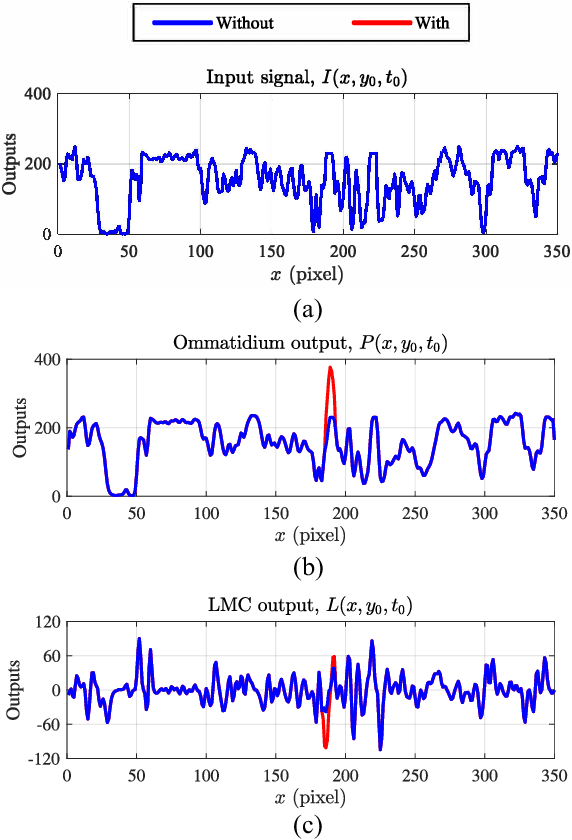
Small target motion detection within complex natural environment is an extremely challenging task for autonomous robots. Surprisingly, visual systems of insects have evolved to be highly efficient in detecting mates and tracking prey, even though targets are as small as a few pixels in visual field. The excellent sensitivity to small target motion relies on a class of specialized neurons called small target motion detectors (STMDs). However, existing STMD-based models are heavily dependent on visual contrast and perform poorly in complex natural environment where small targets always exhibit extremely low contrast to neighboring backgrounds. In this paper, we propose an attention and prediction guided visual system to overcome this limitation. The proposed visual system mainly consists of three subsystems, including an attention module, a STMD-based neural network, and a prediction module. The attention module searches for potential small targets in the predicted areas of input image and enhances their contrast to complex background. The STMD-based neural network receives the contrast-enhanced image and discriminates small moving targets from background false positives. The prediction module foresees future positions of the detected targets and generates a prediction map for the attention module. The three subsystems are connected in a recurrent architecture allowing information processed sequentially to activate specific areas for small target detection. Extensive experiments on synthetic and real-world datasets demonstrate the effectiveness and superiority of the proposed visual system for detecting small, low-contrast moving targets against complex natural environment.
Learning non-Gaussian graphical models via Hessian scores and triangular transport
Jan 08, 2021
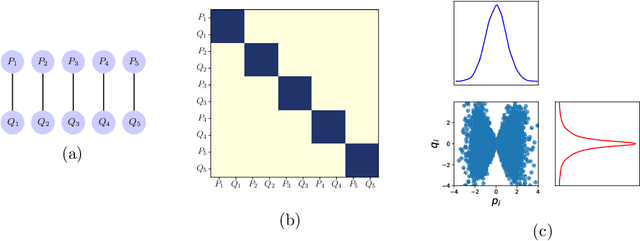
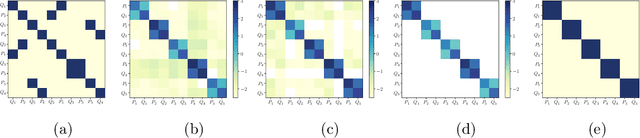
Undirected probabilistic graphical models represent the conditional dependencies, or Markov properties, of a collection of random variables. Knowing the sparsity of such a graphical model is valuable for modeling multivariate distributions and for efficiently performing inference. While the problem of learning graph structure from data has been studied extensively for certain parametric families of distributions, most existing methods fail to consistently recover the graph structure for non-Gaussian data. Here we propose an algorithm for learning the Markov structure of continuous and non-Gaussian distributions. To characterize conditional independence, we introduce a score based on integrated Hessian information from the joint log-density, and we prove that this score upper bounds the conditional mutual information for a general class of distributions. To compute the score, our algorithm SING estimates the density using a deterministic coupling, induced by a triangular transport map, and iteratively exploits sparse structure in the map to reveal sparsity in the graph. For certain non-Gaussian datasets, we show that our algorithm recovers the graph structure even with a biased approximation to the density. Among other examples, we apply sing to learn the dependencies between the states of a chaotic dynamical system with local interactions.
Hypothesis-driven Stream Learning with Augmented Memory
Apr 07, 2021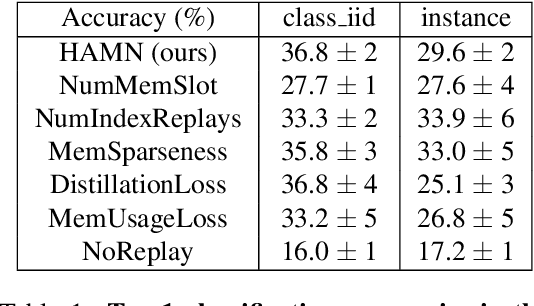
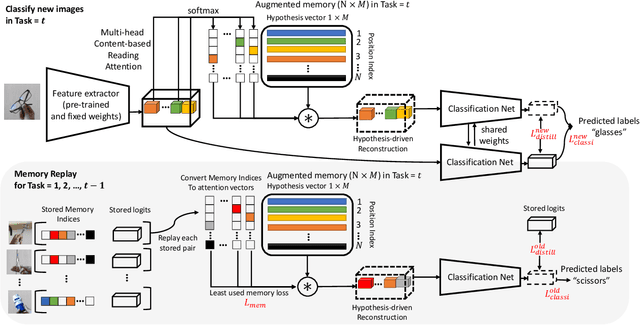
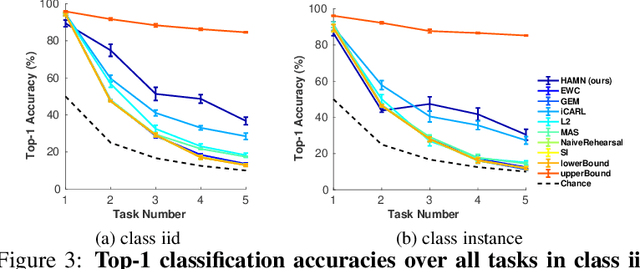
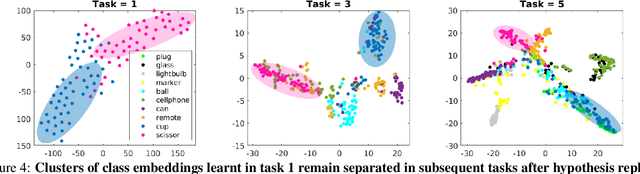
Stream learning refers to the ability to acquire and transfer knowledge across a continuous stream of data without forgetting and without repeated passes over the data. A common way to avoid catastrophic forgetting is to intersperse new examples with replays of old examples stored as image pixels or reproduced by generative models. Here, we considered stream learning in image classification tasks and proposed a novel hypotheses-driven Augmented Memory Network, which efficiently consolidates previous knowledge with a limited number of hypotheses in the augmented memory and replays relevant hypotheses to avoid catastrophic forgetting. The advantages of hypothesis-driven replay over image pixel replay and generative replay are two-fold. First, hypothesis-based knowledge consolidation avoids redundant information in the image pixel space and makes memory usage more efficient. Second, hypotheses in the augmented memory can be re-used for learning new tasks, improving generalization and transfer learning ability. We evaluated our method on three stream learning object recognition datasets. Our method performs comparably well or better than SOTA methods, while offering more efficient memory usage. All source code and data are publicly available https://github.com/kreimanlab/AugMem.