 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
"What's The Context?" : Long Context NLM Adaptation for ASR Rescoring in Conversational Agents
Apr 21, 2021
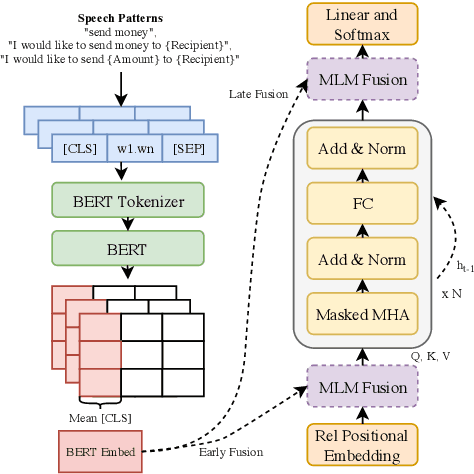

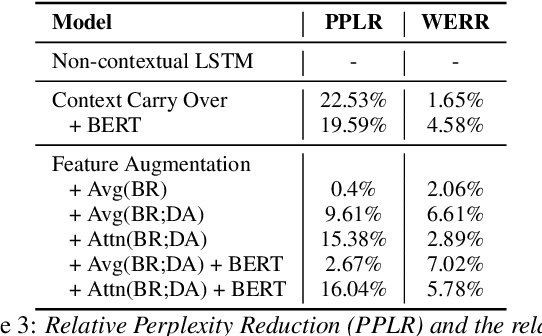
Neural Language Models (NLM), when trained and evaluated with context spanning multiple utterances, have been shown to consistently outperform both conventional n-gram language models and NLMs that use limited context. In this paper, we investigate various techniques to incorporate turn based context history into both recurrent (LSTM) and Transformer-XL based NLMs. For recurrent based NLMs, we explore context carry over mechanism and feature based augmentation, where we incorporate other forms of contextual information such as bot response and system dialogue acts as classified by a Natural Language Understanding (NLU) model. To mitigate the sharp nearby, fuzzy far away problem with contextual NLM, we propose the use of attention layer over lexical metadata to improve feature based augmentation. Additionally, we adapt our contextual NLM towards user provided on-the-fly speech patterns by leveraging encodings from a large pre-trained masked language model and performing fusion with a Transformer-XL based NLM. We test our proposed models using N-best rescoring of ASR hypotheses of task-oriented dialogues and also evaluate on downstream NLU tasks such as intent classification and slot labeling. The best performing model shows a relative WER between 1.6% and 9.1% and a slot labeling F1 score improvement of 4% over non-contextual baselines.
UniParma @ SemEval 2021 Task 5: Toxic Spans Detection Using CharacterBERT and Bag-of-Words Model
Mar 17, 2021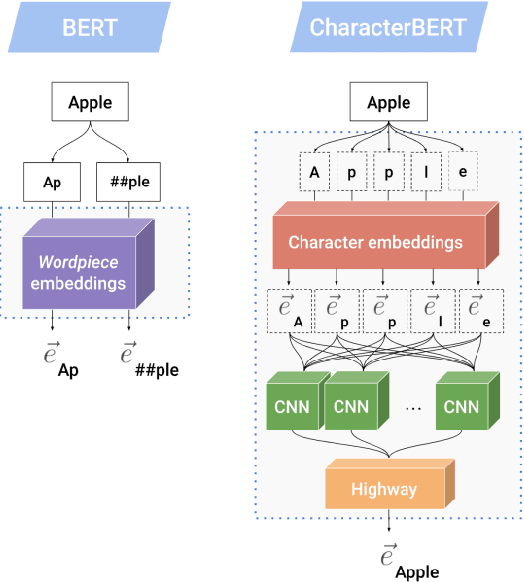

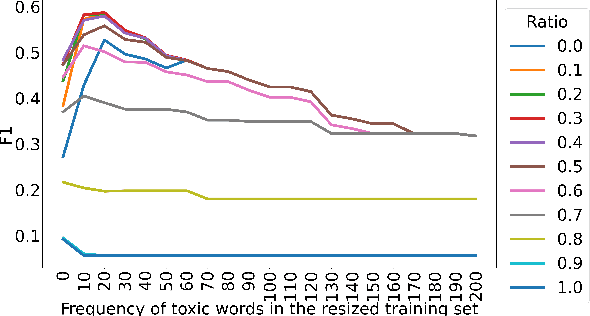
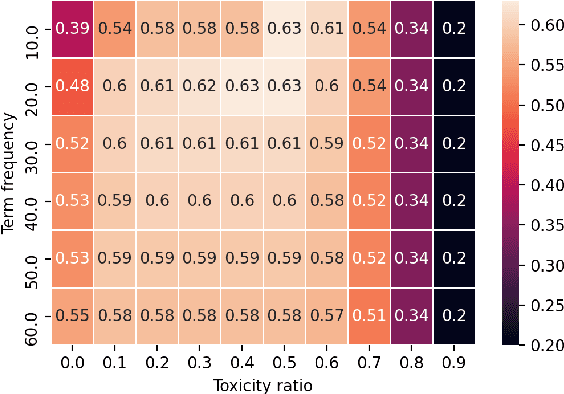
With the ever-increasing availability of digital information, toxic content is also on the rise. Therefore, the detection of this type of language is of paramount importance. We tackle this problem utilizing a combination of a state-of-the-art pre-trained language model (CharacterBERT) and a traditional bag-of-words technique. Since the content is full of toxic words that have not been written according to their dictionary spelling, attendance to individual characters is crucial. Therefore, we use CharacterBERT to extract features based on the word characters. It consists of a CharacterCNN module that learns character embeddings from the context. These are, then, fed into the well-known BERT architecture. The bag-of-words method, on the other hand, further improves upon that by making sure that some frequently used toxic words get labeled accordingly.
MAST: Multimodal Abstractive Summarization with Trimodal Hierarchical Attention
Oct 15, 2020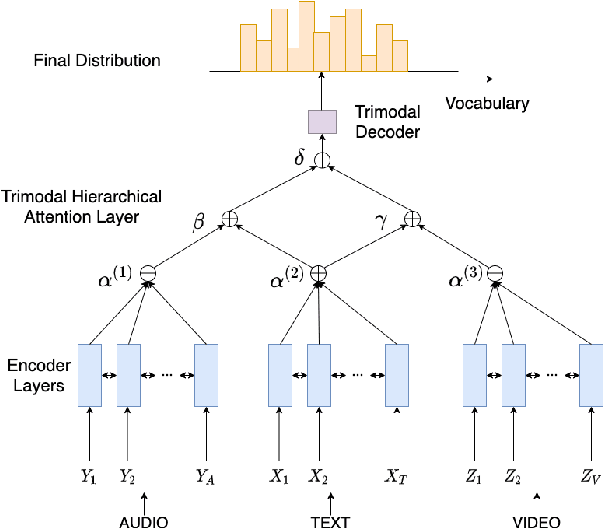
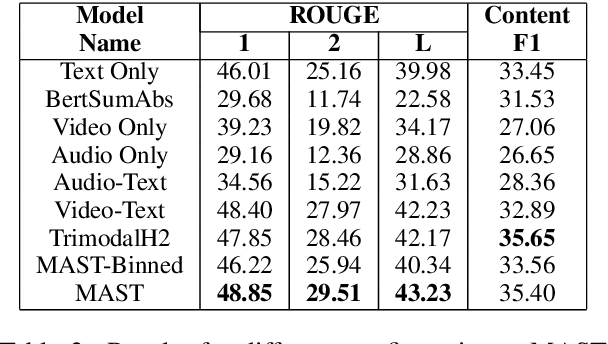
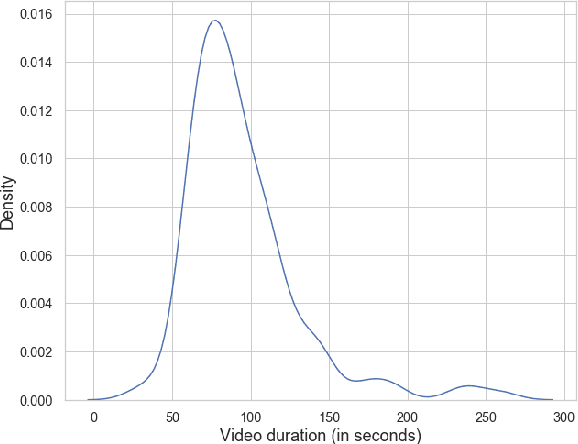
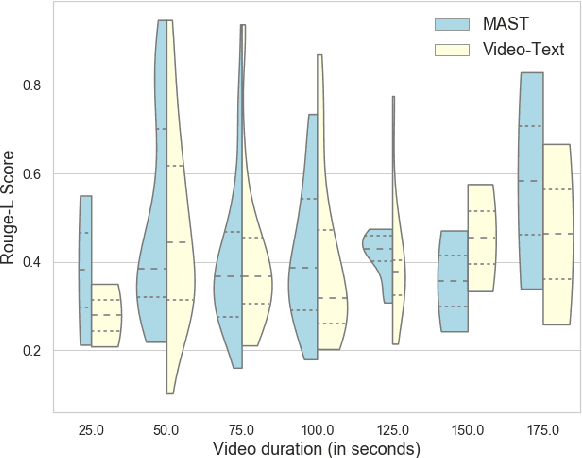
This paper presents MAST, a new model for Multimodal Abstractive Text Summarization that utilizes information from all three modalities -- text, audio and video -- in a multimodal video. Prior work on multimodal abstractive text summarization only utilized information from the text and video modalities. We examine the usefulness and challenges of deriving information from the audio modality and present a sequence-to-sequence trimodal hierarchical attention-based model that overcomes these challenges by letting the model pay more attention to the text modality. MAST outperforms the current state of the art model (video-text) by 2.51 points in terms of Content F1 score and 1.00 points in terms of Rouge-L score on the How2 dataset for multimodal language understanding.
Probing the Effect of Selection Bias on NN Generalization with a Thought Experiment
May 20, 2021
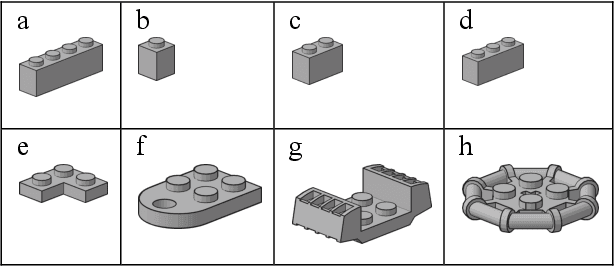

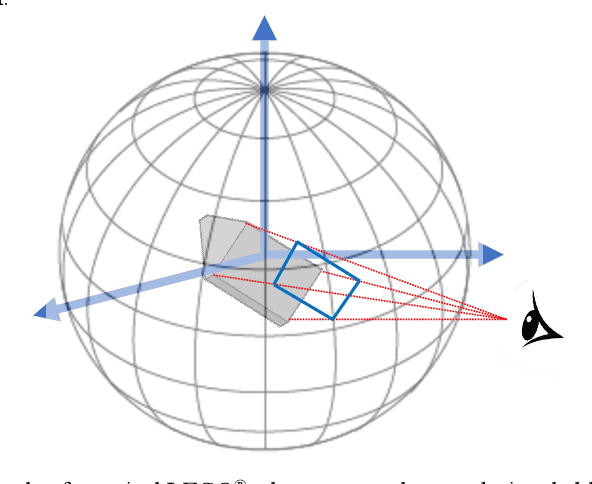
Learned networks in the domain of visual recognition and cognition impress in part because even though they are trained with datasets many orders of magnitude smaller than the full population of possible images, they exhibit sufficient generalization to be applicable to new and previously unseen data. Although many have examined issues regarding generalization from several perspectives, we wondered If a network is trained with a biased dataset that misses particular samples corresponding to some defining domain attribute, can it generalize to the full domain from which that training dataset was extracted? It is certainly true that in vision, no current training set fully captures all visual information and this may lead to Selection Bias. Here, we try a novel approach in the tradition of the Thought Experiment. We run this thought experiment on a real domain of visual objects that we can fully characterize and look at specific gaps in training data and their impact on performance requirements. Our thought experiment points to three conclusions: first, that generalization behavior is dependent on how sufficiently the particular dimensions of the domain are represented during training; second, that the utility of any generalization is completely dependent on the acceptable system error; and third, that specific visual features of objects, such as pose orientations out of the imaging plane or colours, may not be recoverable if not represented sufficiently in a training set. Any currently observed generalization in modern deep learning networks may be more the result of coincidental alignments and whose utility needs to be confirmed with respect to a system's performance specification. Our Thought Experiment Probe approach, coupled with the resulting Bias Breakdown can be very informative towards understanding the impact of biases.
On the Role of Images for Analyzing Claims in Social Media
Mar 17, 2021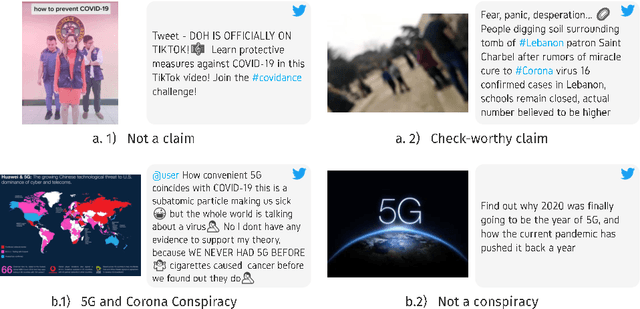
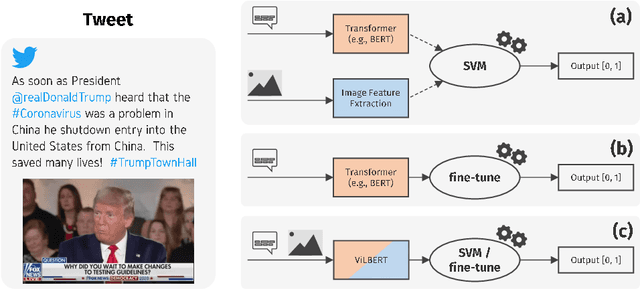
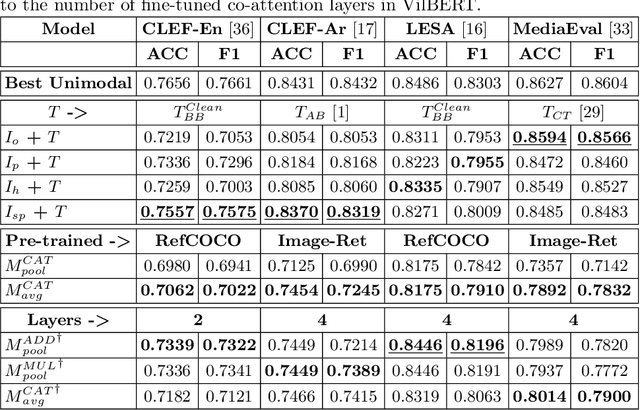
Fake news is a severe problem in social media. In this paper, we present an empirical study on visual, textual, and multimodal models for the tasks of claim, claim check-worthiness, and conspiracy detection, all of which are related to fake news detection. Recent work suggests that images are more influential than text and often appear alongside fake text. To this end, several multimodal models have been proposed in recent years that use images along with text to detect fake news on social media sites like Twitter. However, the role of images is not well understood for claim detection, specifically using transformer-based textual and multimodal models. We investigate state-of-the-art models for images, text (Transformer-based), and multimodal information for four different datasets across two languages to understand the role of images in the task of claim and conspiracy detection.
Citadel: Protecting Data Privacy and Model Confidentiality for Collaborative Learning with SGX
May 04, 2021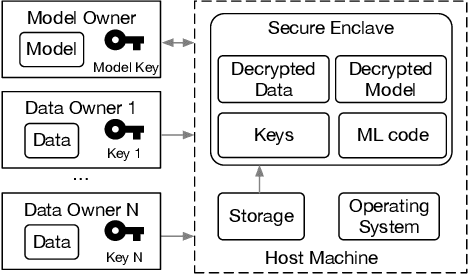
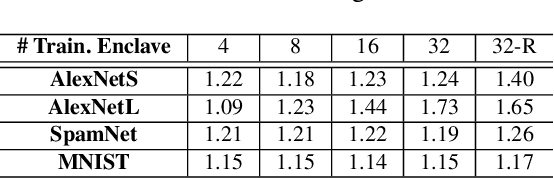
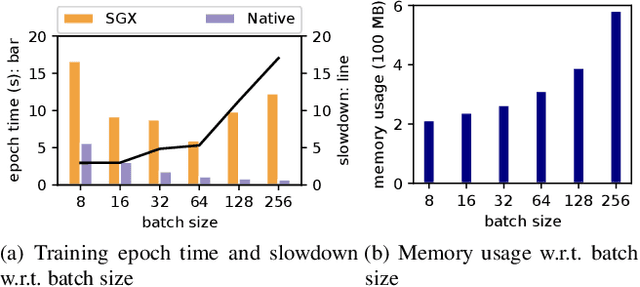
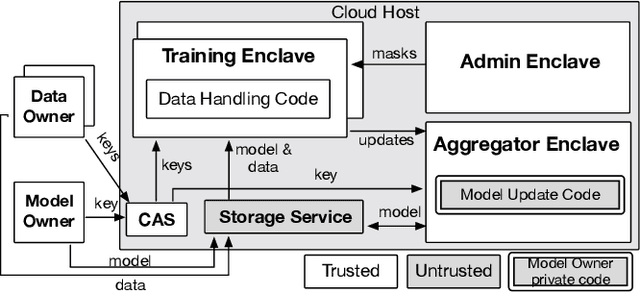
With the advancement of machine learning (ML) and its growing awareness, many organizations who own data but not ML expertise (data owner) would like to pool their data and collaborate with those who have expertise but need data from diverse sources to train truly generalizable models (model owner). In such collaborative ML, the data owner wants to protect the privacy of its training data, while the model owner desires the confidentiality of the model and the training method which may contain intellectual properties. However, existing private ML solutions, such as federated learning and split learning, cannot meet the privacy requirements of both data and model owners at the same time. This paper presents Citadel, a scalable collaborative ML system that protects the privacy of both data owner and model owner in untrusted infrastructures with the help of Intel SGX. Citadel performs distributed training across multiple training enclaves running on behalf of data owners and an aggregator enclave on behalf of the model owner. Citadel further establishes a strong information barrier between these enclaves by means of zero-sum masking and hierarchical aggregation to prevent data/model leakage during collaborative training. Compared with the existing SGX-protected training systems, Citadel enables better scalability and stronger privacy guarantees for collaborative ML. Cloud deployment with various ML models shows that Citadel scales to a large number of enclaves with less than 1.73X slowdown caused by SGX.
Improving Model Robustness by Adaptively Correcting Perturbation Levels with Active Queries
Mar 27, 2021
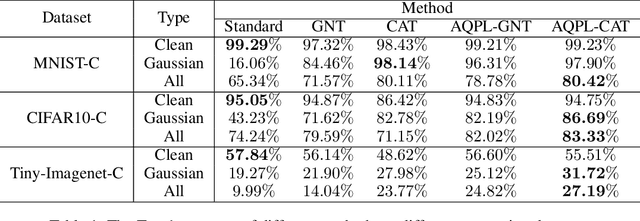
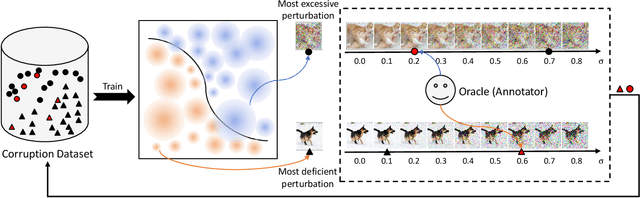
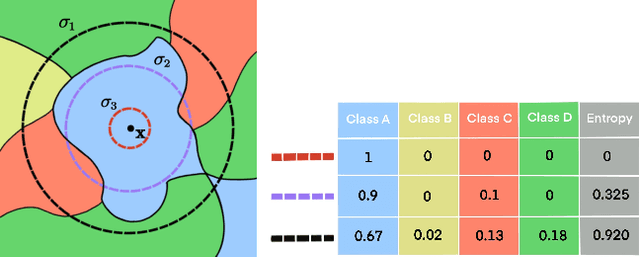
In addition to high accuracy, robustness is becoming increasingly important for machine learning models in various applications. Recently, much research has been devoted to improving the model robustness by training with noise perturbations. Most existing studies assume a fixed perturbation level for all training examples, which however hardly holds in real tasks. In fact, excessive perturbations may destroy the discriminative content of an example, while deficient perturbations may fail to provide helpful information for improving the robustness. Motivated by this observation, we propose to adaptively adjust the perturbation levels for each example in the training process. Specifically, a novel active learning framework is proposed to allow the model to interactively query the correct perturbation level from human experts. By designing a cost-effective sampling strategy along with a new query type, the robustness can be significantly improved with a few queries. Both theoretical analysis and experimental studies validate the effectiveness of the proposed approach.
Optical Flow Estimation via Motion Feature Recovery
Jan 16, 2021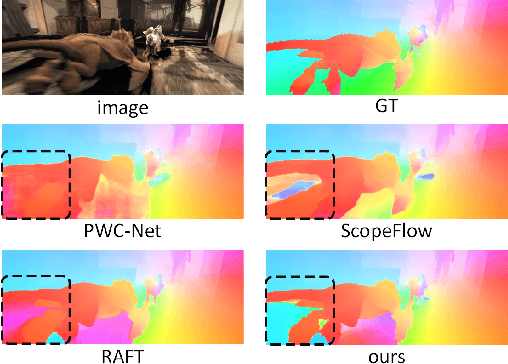
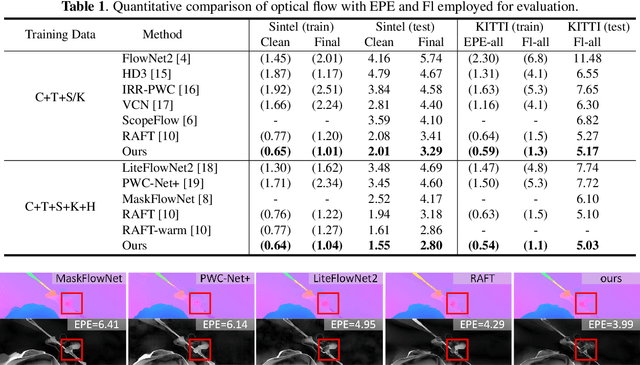
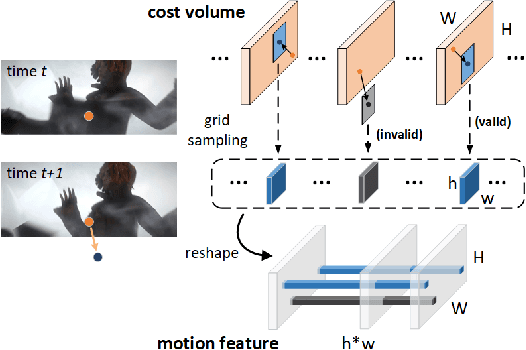
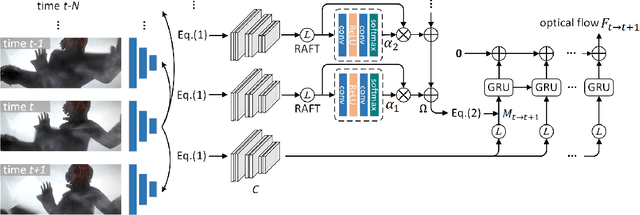
Optical flow estimation with occlusion or large displacement is a problematic challenge due to the lost of corresponding pixels between consecutive frames. In this paper, we discover that the lost information is related to a large quantity of motion features (more than 40%) computed from the popular discriminative cost-volume feature would completely vanish due to invalid sampling, leading to the low efficiency of optical flow learning. We call this phenomenon the Vanishing Cost Volume Problem. Inspired by the fact that local motion tends to be highly consistent within a short temporal window, we propose a novel iterative Motion Feature Recovery (MFR) method to address the vanishing cost volume via modeling motion consistency across multiple frames. In each MFR iteration, invalid entries from original motion features are first determined based on the current flow. Then, an efficient network is designed to adaptively learn the motion correlation to recover invalid features for lost-information restoration. The final optical flow is then decoded from the recovered motion features. Experimental results on Sintel and KITTI show that our method achieves state-of-the-art performances. In fact, MFR currently ranks second on Sintel public website.
Potential Convolution: Embedding Point Clouds into Potential Fields
Apr 05, 2021
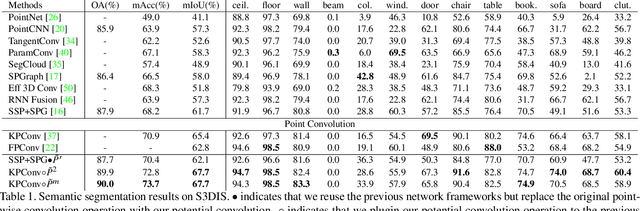
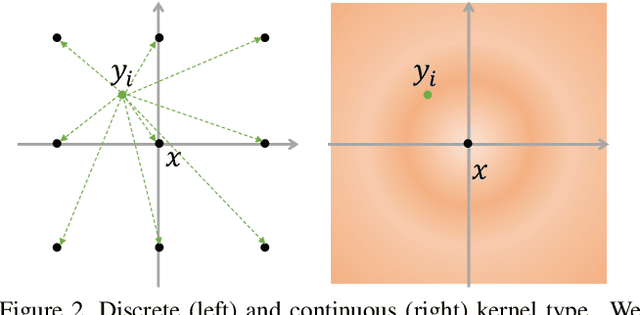
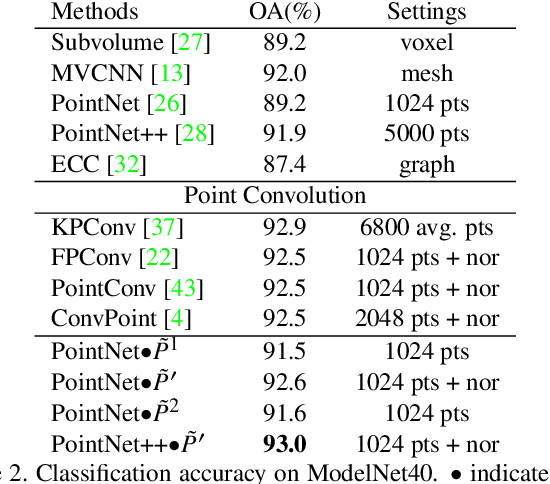
Recently, various convolutions based on continuous or discrete kernels for point cloud processing have been widely studied, and achieve impressive performance in many applications, such as shape classification, scene segmentation and so on. However, they still suffer from some drawbacks. For continuous kernels, the inaccurate estimation of the kernel weights constitutes a bottleneck for further improving the performance; while for discrete ones, the kernels represented as the points located in the 3D space are lack of rich geometry information. In this work, rather than defining a continuous or discrete kernel, we directly embed convolutional kernels into the learnable potential fields, giving rise to potential convolution. It is convenient for us to define various potential functions for potential convolution which can generalize well to a wide range of tasks. Specifically, we provide two simple yet effective potential functions via point-wise convolution operations. Comprehensive experiments demonstrate the effectiveness of our method, which achieves superior performance on the popular 3D shape classification and scene segmentation benchmarks compared with other state-of-the-art point convolution methods.
End-to-end One-shot Human Parsing
May 04, 2021
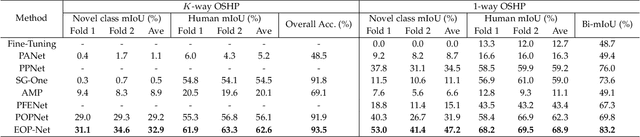
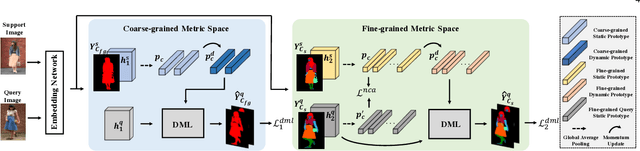
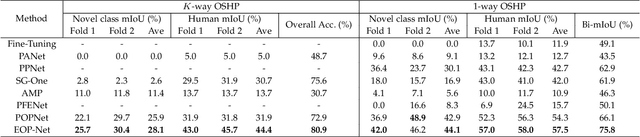
Previous human parsing models are limited to parsing humans into pre-defined classes, which is inflexible for applications that need to handle new classes. In this paper, we define a new one-shot human parsing (OSHP) task that requires parsing humans into an open set of classes defined by any test example. During training, only base classes are exposed, which only overlap with part of test-time classes. To address three main challenges in OSHP, i.e., small sizes, testing bias, and similar parts, we devise a novel End-to-end One-shot human Parsing Network (EOP-Net). Firstly, an end-to-end human parsing framework is proposed to mutually share semantic information with different granularities and help recognize the small-size human classes. Then, we devise two collaborative metric learning modules to learn representative prototypes for base classes, which can quickly adapt to unseen classes and mitigate the testing bias. Moreover, we empirically find that robust prototypes empower feature representations with higher transferability to the novel concepts, hence, we propose to adopt momentum-updated dynamic prototypes generated by gradually smoothing the training time prototypes and employ contrastive loss at the prototype level. Experiments on three popular benchmarks tailored for OSHP demonstrate that EOP-Net outperforms representative one-shot segmentation models by large margins, which serves as a strong benchmark for further research on this new task. The source code will be made publicly available.