 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Human-AI Alignment in Large-Scale Multi-Player Games
Feb 05, 2024



Achieving human-AI alignment in complex multi-agent games is crucial for creating trustworthy AI agents that enhance gameplay. We propose a method to evaluate this alignment using an interpretable task-sets framework, focusing on high-level behavioral tasks instead of low-level policies. Our approach has three components. First, we analyze extensive human gameplay data from Xbox's Bleeding Edge (100K+ games), uncovering behavioral patterns in a complex task space. This task space serves as a basis set for a behavior manifold capturing interpretable axes: fight-flight, explore-exploit, and solo-multi-agent. Second, we train an AI agent to play Bleeding Edge using a Generative Pretrained Causal Transformer and measure its behavior. Third, we project human and AI gameplay to the proposed behavior manifold to compare and contrast. This allows us to interpret differences in policy as higher-level behavioral concepts, e.g., we find that while human players exhibit variability in fight-flight and explore-exploit behavior, AI players tend towards uniformity. Furthermore, AI agents predominantly engage in solo play, while humans often engage in cooperative and competitive multi-agent patterns. These stark differences underscore the need for interpretable evaluation, design, and integration of AI in human-aligned applications. Our study advances the alignment discussion in AI and especially generative AI research, offering a measurable framework for interpretable human-agent alignment in multiplayer gaming.
MEMEX: Detecting Explanatory Evidence for Memes via Knowledge-Enriched Contextualization
May 25, 2023



Memes are a powerful tool for communication over social media. Their affinity for evolving across politics, history, and sociocultural phenomena makes them an ideal communication vehicle. To comprehend the subtle message conveyed within a meme, one must understand the background that facilitates its holistic assimilation. Besides digital archiving of memes and their metadata by a few websites like knowyourmeme.com, currently, there is no efficient way to deduce a meme's context dynamically. In this work, we propose a novel task, MEMEX - given a meme and a related document, the aim is to mine the context that succinctly explains the background of the meme. At first, we develop MCC (Meme Context Corpus), a novel dataset for MEMEX. Further, to benchmark MCC, we propose MIME (MultImodal Meme Explainer), a multimodal neural framework that uses common sense enriched meme representation and a layered approach to capture the cross-modal semantic dependencies between the meme and the context. MIME surpasses several unimodal and multimodal systems and yields an absolute improvement of ~ 4% F1-score over the best baseline. Lastly, we conduct detailed analyses of MIME's performance, highlighting the aspects that could lead to optimal modeling of cross-modal contextual associations.
Types of Out-of-Distribution Texts and How to Detect Them
Sep 14, 2021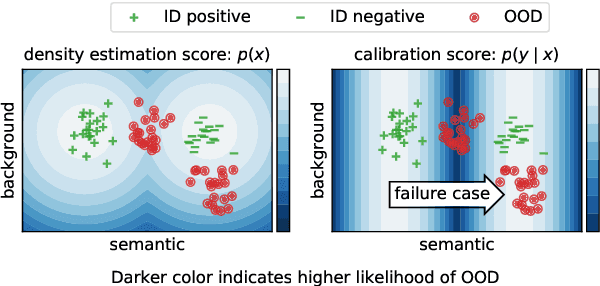
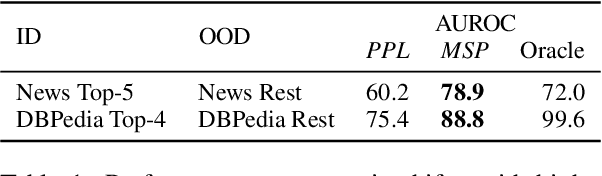
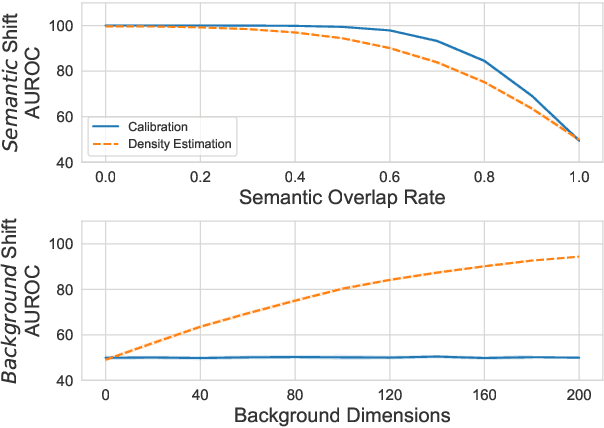
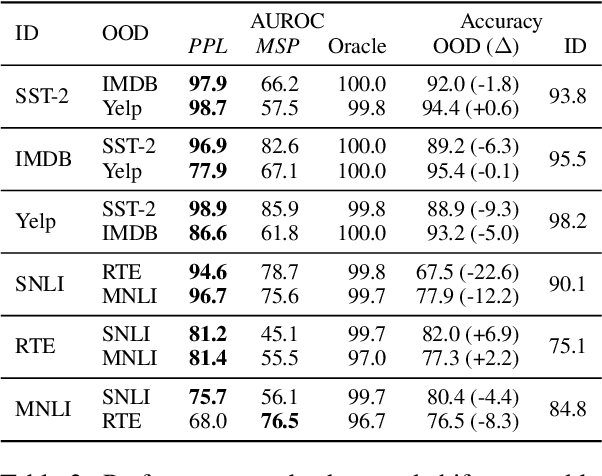
Despite agreement on the importance of detecting out-of-distribution (OOD) examples, there is little consensus on the formal definition of OOD examples and how to best detect them. We categorize these examples by whether they exhibit a background shift or a semantic shift, and find that the two major approaches to OOD detection, model calibration and density estimation (language modeling for text), have distinct behavior on these types of OOD data. Across 14 pairs of in-distribution and OOD English natural language understanding datasets, we find that density estimation methods consistently beat calibration methods in background shift settings, while performing worse in semantic shift settings. In addition, we find that both methods generally fail to detect examples from challenge data, highlighting a weak spot for current methods. Since no single method works well across all settings, our results call for an explicit definition of OOD examples when evaluating different detection methods.
MAST: Multimodal Abstractive Summarization with Trimodal Hierarchical Attention
Oct 15, 2020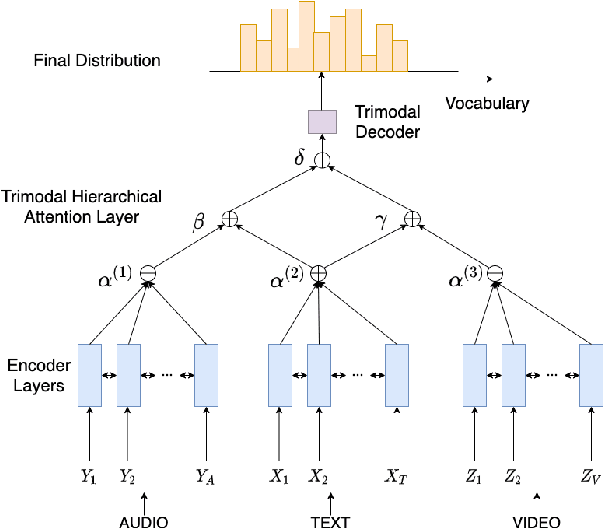
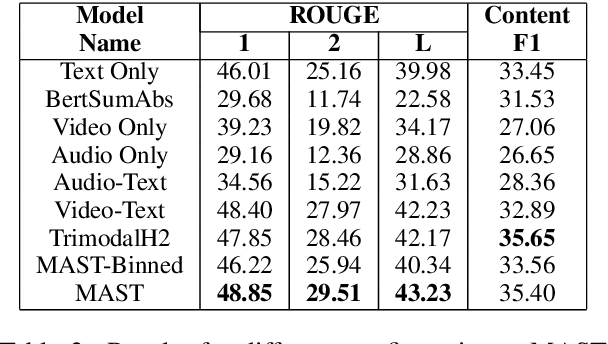
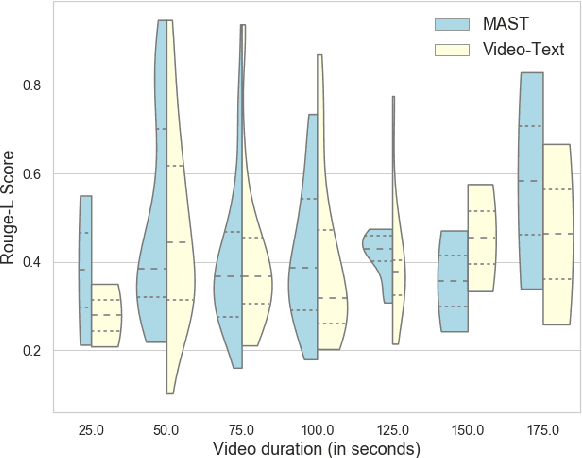
This paper presents MAST, a new model for Multimodal Abstractive Text Summarization that utilizes information from all three modalities -- text, audio and video -- in a multimodal video. Prior work on multimodal abstractive text summarization only utilized information from the text and video modalities. We examine the usefulness and challenges of deriving information from the audio modality and present a sequence-to-sequence trimodal hierarchical attention-based model that overcomes these challenges by letting the model pay more attention to the text modality. MAST outperforms the current state of the art model (video-text) by 2.51 points in terms of Content F1 score and 1.00 points in terms of Rouge-L score on the How2 dataset for multimodal language understanding.
Multitask Learning for Blackmarket Tweet Detection
Jul 09, 2019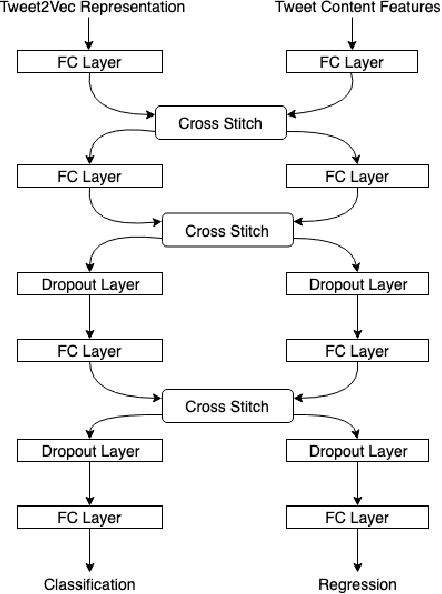
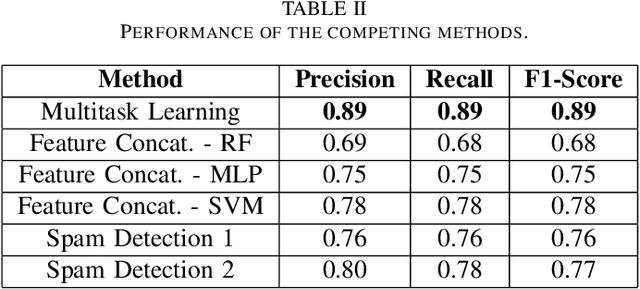
Online social media platforms have made the world more connected than ever before, thereby making it easier for everyone to spread their content across a wide variety of audiences. Twitter is one such popular platform where people publish tweets to spread their messages to everyone. Twitter allows users to Retweet other users' tweets in order to broadcast it to their network. The more retweets a particular tweet gets, the faster it spreads. This creates incentives for people to obtain artificial growth in the reach of their tweets by using certain blackmarket services to gain inorganic appraisals for their content. In this paper, we attempt to detect such tweets that have been posted on these blackmarket services in order to gain artificially boosted retweets. We use a multitask learning framework to leverage soft parameter sharing between a classification and a regression based task on separate inputs. This allows us to effectively detect tweets that have been posted to these blackmarket services, achieving an F1-score of 0.89 when classifying tweets as blackmarket or genuine.