 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Global Narratives: A Multilingual Twitter Dataset of News Media on the Russo-Ukrainian Conflict
Jun 22, 2023The ongoing Russo-Ukrainian conflict has been a subject of intense media coverage worldwide. Understanding the global narrative surrounding this topic is crucial for researchers that aim to gain insights into its multifaceted dimensions. In this paper, we present a novel dataset that focuses on this topic by collecting and processing tweets posted by news or media companies on social media across the globe. We collected tweets from February 2022 to May 2023 to acquire approximately 1.5 million tweets in 60 different languages. Each tweet in the dataset is accompanied by processed tags, allowing for the identification of entities, stances, concepts, and sentiments expressed. The availability of the dataset serves as a valuable resource for researchers aiming to investigate the global narrative surrounding the ongoing conflict from various aspects such as who are the prominent entities involved, what stances are taken, where do these stances originate, and how are the different concepts related to the event portrayed.
OEKG: The Open Event Knowledge Graph
Feb 28, 2023



Accessing and understanding contemporary and historical events of global impact such as the US elections and the Olympic Games is a major prerequisite for cross-lingual event analytics that investigate event causes, perception and consequences across country borders. In this paper, we present the Open Event Knowledge Graph (OEKG), a multilingual, event-centric, temporal knowledge graph composed of seven different data sets from multiple application domains, including question answering, entity recommendation and named entity recognition. These data sets are all integrated through an easy-to-use and robust pipeline and by linking to the event-centric knowledge graph EventKG. We describe their common schema and demonstrate the use of the OEKG at the example of three use cases: type-specific image retrieval, hybrid question answering over knowledge graphs and news articles, as well as language-specific event recommendation. The OEKG and its query endpoint are publicly available.
MM-Claims: A Dataset for Multimodal Claim Detection in Social Media
May 04, 2022
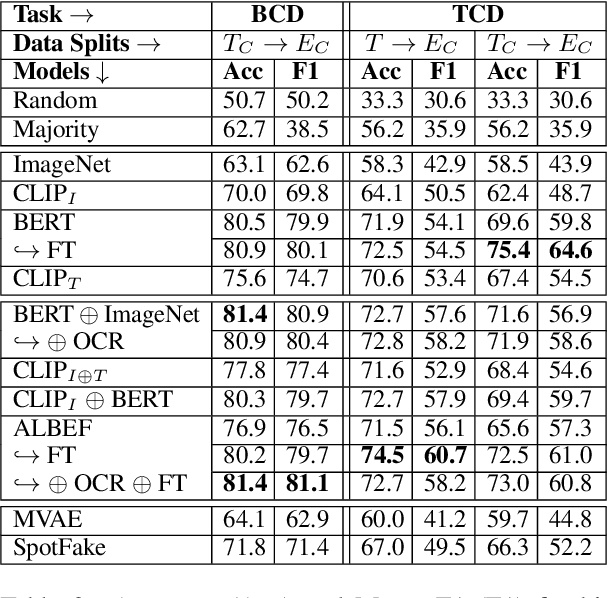
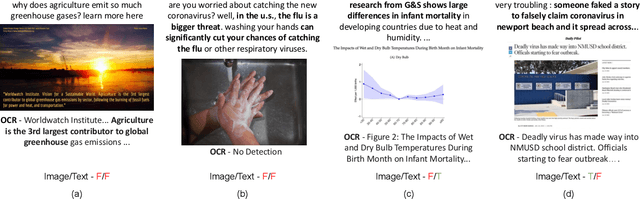
In recent years, the problem of misinformation on the web has become widespread across languages, countries, and various social media platforms. Although there has been much work on automated fake news detection, the role of images and their variety are not well explored. In this paper, we investigate the roles of image and text at an earlier stage of the fake news detection pipeline, called claim detection. For this purpose, we introduce a novel dataset, MM-Claims, which consists of tweets and corresponding images over three topics: COVID-19, Climate Change and broadly Technology. The dataset contains roughly 86000 tweets, out of which 3400 are labeled manually by multiple annotators for the training and evaluation of multimodal models. We describe the dataset in detail, evaluate strong unimodal and multimodal baselines, and analyze the potential and drawbacks of current models.
TIB-VA at SemEval-2022 Task 5: A Multimodal Architecture for the Detection and Classification of Misogynous Memes
Apr 13, 2022

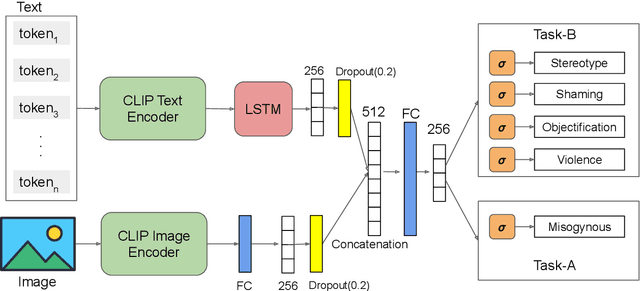
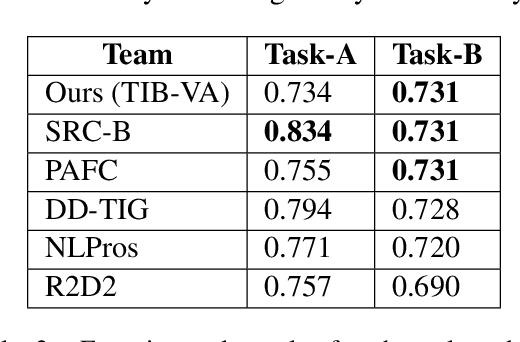
The detection of offensive, hateful content on social media is a challenging problem that affects many online users on a daily basis. Hateful content is often used to target a group of people based on ethnicity, gender, religion and other factors. The hate or contempt toward women has been increasing on social platforms. Misogynous content detection is especially challenging when textual and visual modalities are combined to form a single context, e.g., an overlay text embedded on top of an image, also known as meme. In this paper, we present a multimodal architecture that combines textual and visual features in order to detect misogynous meme content. The proposed architecture is evaluated in the SemEval-2022 Task 5: MAMI - Multimedia Automatic Misogyny Identification challenge under the team name TIB-VA. Our solution obtained the best result in the Task-B where the challenge is to classify whether a given document is misogynous and further identify the main sub-classes of shaming, stereotype, objectification, and violence.
A Fair and Comprehensive Comparison of Multimodal Tweet Sentiment Analysis Methods
Jun 16, 2021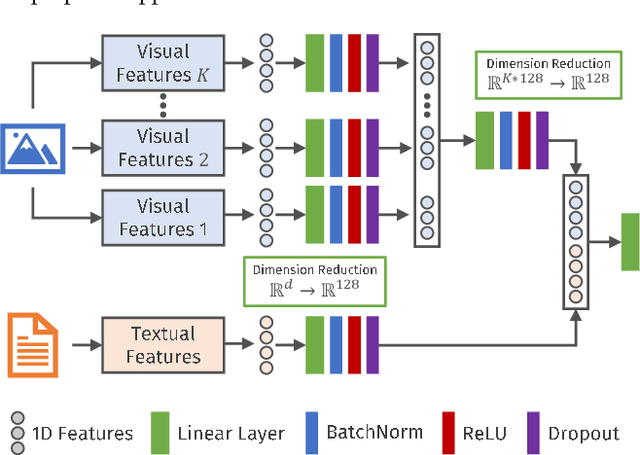
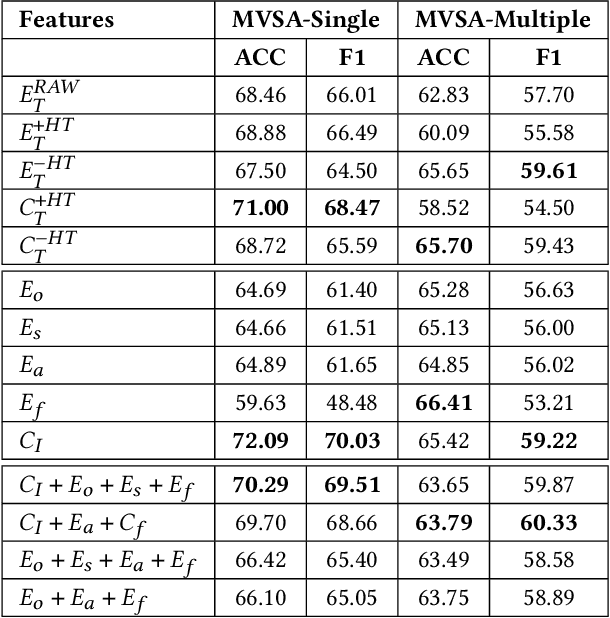
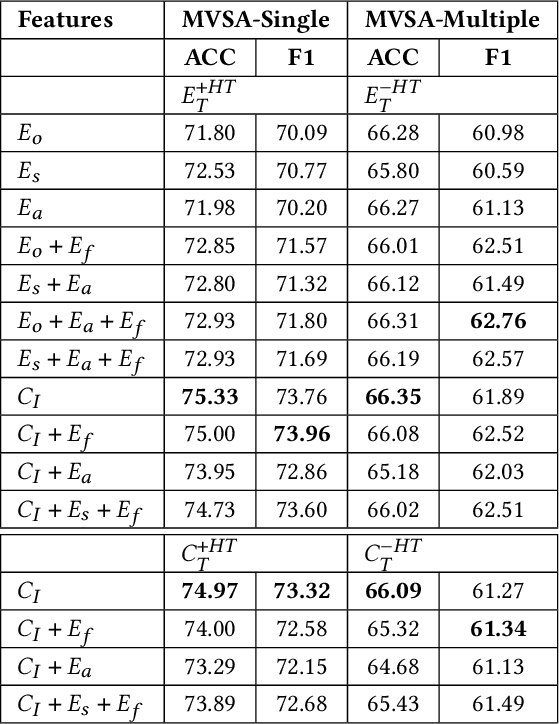
Opinion and sentiment analysis is a vital task to characterize subjective information in social media posts. In this paper, we present a comprehensive experimental evaluation and comparison with six state-of-the-art methods, from which we have re-implemented one of them. In addition, we investigate different textual and visual feature embeddings that cover different aspects of the content, as well as the recently introduced multimodal CLIP embeddings. Experimental results are presented for two different publicly available benchmark datasets of tweets and corresponding images. In contrast to the evaluation methodology of previous work, we introduce a reproducible and fair evaluation scheme to make results comparable. Finally, we conduct an error analysis to outline the limitations of the methods and possibilities for the future work.
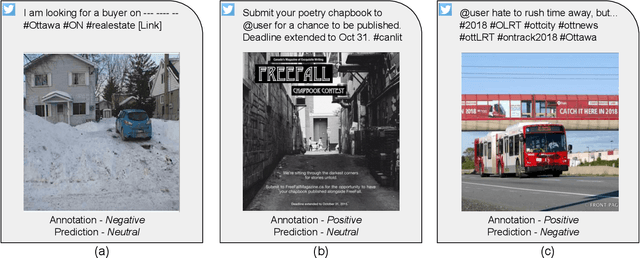
On the Role of Images for Analyzing Claims in Social Media
Mar 17, 2021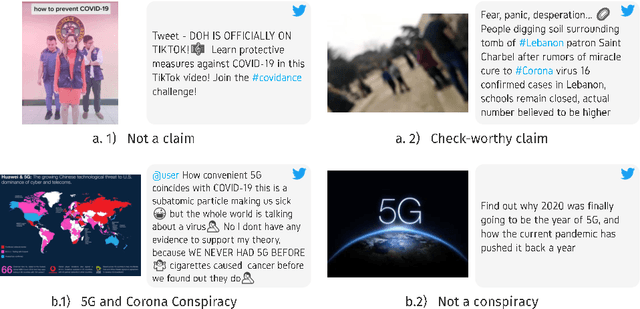
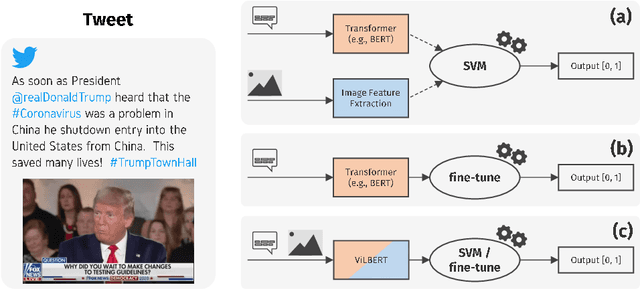
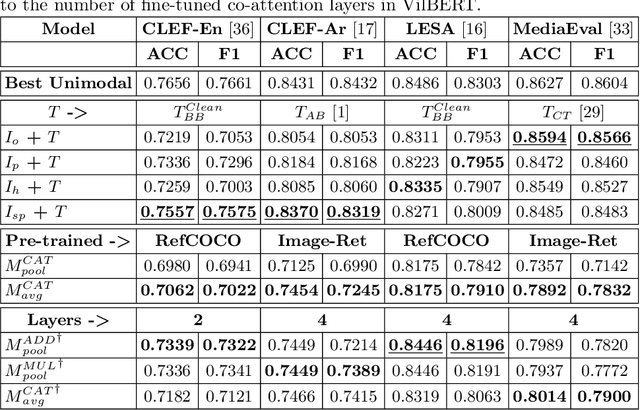
Fake news is a severe problem in social media. In this paper, we present an empirical study on visual, textual, and multimodal models for the tasks of claim, claim check-worthiness, and conspiracy detection, all of which are related to fake news detection. Recent work suggests that images are more influential than text and often appear alongside fake text. To this end, several multimodal models have been proposed in recent years that use images along with text to detect fake news on social media sites like Twitter. However, the role of images is not well understood for claim detection, specifically using transformer-based textual and multimodal models. We investigate state-of-the-art models for images, text (Transformer-based), and multimodal information for four different datasets across two languages to understand the role of images in the task of claim and conspiracy detection.
Check_square at CheckThat! 2020: Claim Detection in Social Media via Fusion of Transformer and Syntactic Features
Jul 21, 2020
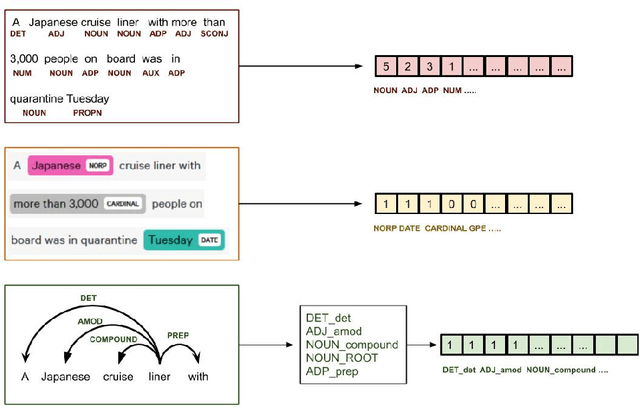
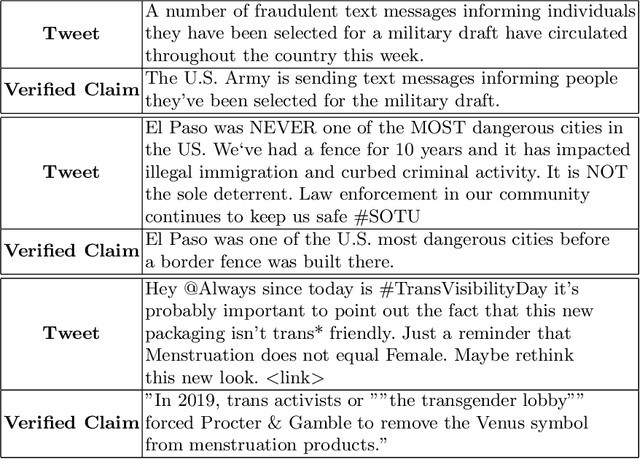
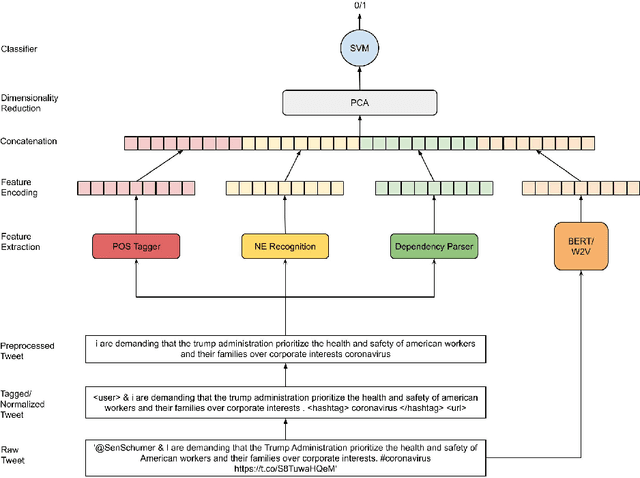
In this digital age of news consumption, a news reader has the ability to react, express and share opinions with others in a highly interactive and fast manner. As a consequence, fake news has made its way into our daily life because of very limited capacity to verify news on the Internet by large companies as well as individuals. In this paper, we focus on solving two problems which are part of the fact-checking ecosystem that can help to automate fact-checking of claims in an ever increasing stream of content on social media. For the first problem, claim check-worthiness prediction, we explore the fusion of syntactic features and deep transformer Bidirectional Encoder Representations from Transformers (BERT) embeddings, to classify check-worthiness of a tweet, i.e. whether it includes a claim or not. We conduct a detailed feature analysis and present our best performing models for English and Arabic tweets. For the second problem, claim retrieval, we explore the pre-trained embeddings from a Siamese network transformer model (sentence-transformers) specifically trained for semantic textual similarity, and perform KD-search to retrieve verified claims with respect to a query tweet.