 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Conditional Meta-Learning of Linear Representations
Mar 30, 2021
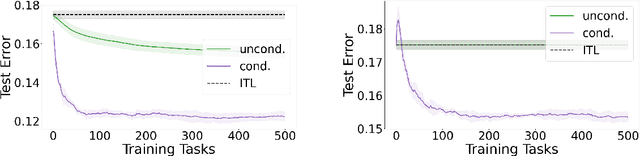
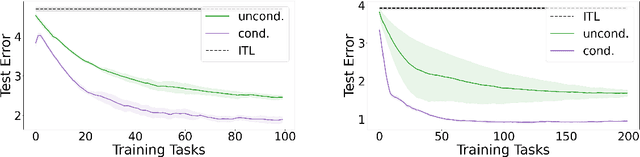
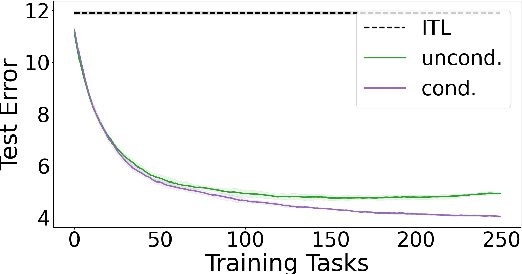
Standard meta-learning for representation learning aims to find a common representation to be shared across multiple tasks. The effectiveness of these methods is often limited when the nuances of the tasks' distribution cannot be captured by a single representation. In this work we overcome this issue by inferring a conditioning function, mapping the tasks' side information (such as the tasks' training dataset itself) into a representation tailored to the task at hand. We study environments in which our conditional strategy outperforms standard meta-learning, such as those in which tasks can be organized in separate clusters according to the representation they share. We then propose a meta-algorithm capable of leveraging this advantage in practice. In the unconditional setting, our method yields a new estimator enjoying faster learning rates and requiring less hyper-parameters to tune than current state-of-the-art methods. Our results are supported by preliminary experiments.
On Representation Learning for Scientific News Articles Using Heterogeneous Knowledge Graphs
Apr 12, 2021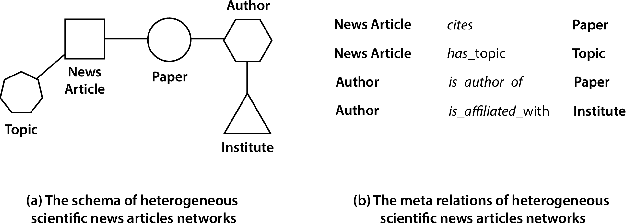
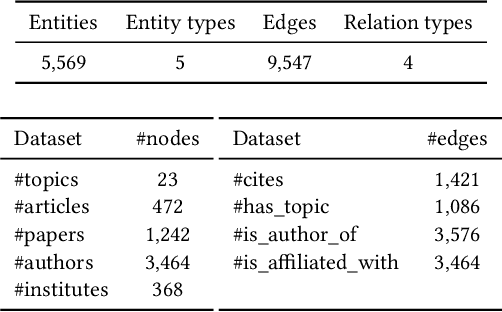
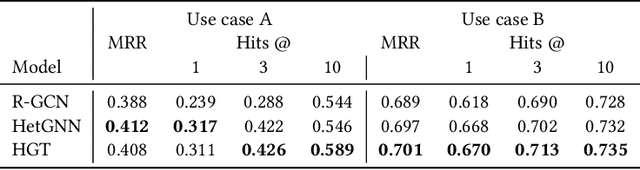
In the era of misinformation and information inflation, the credibility assessment of the produced news is of the essence. However, fact-checking can be challenging considering the limited references presented in the news. This challenge can be transcended by utilizing the knowledge graph that is related to the news articles. In this work, we present a methodology for creating scientific news article representations by modeling the directed graph between the scientific news articles and the cited scientific publications. The network used for the experiments is comprised of the scientific news articles, their topic, the cited research literature, and their corresponding authors. We implement and present three different approaches: 1) a baseline Relational Graph Convolutional Network (R-GCN), 2) a Heterogeneous Graph Neural Network (HetGNN) and 3) a Heterogeneous Graph Transformer (HGT). We test these models in the downstream task of link prediction on the: a) news article - paper links and b) news article - article topic links. The results show promising applications of graph neural network approaches in the domains of knowledge tracing and scientific news credibility assessment.
ASPER: Attention-based Approach to Extract Syntactic Patterns denoting Semantic Relations in Sentential Context
Apr 04, 2021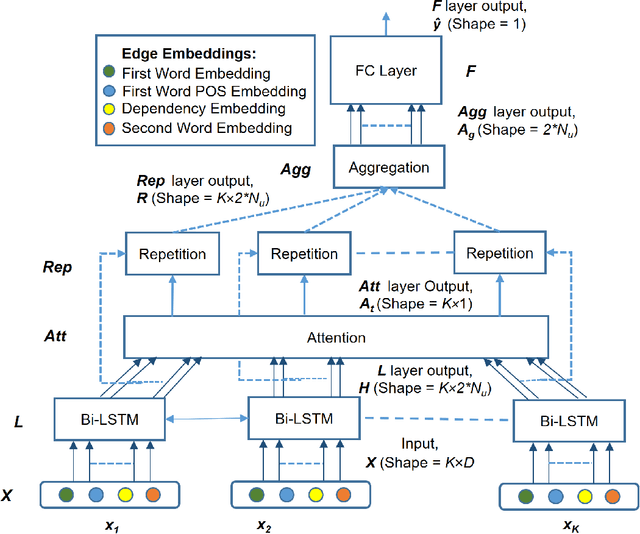
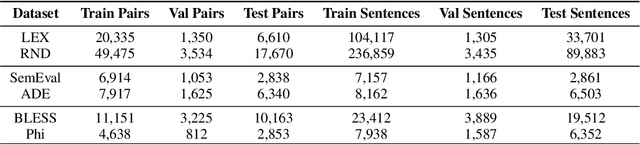

Semantic relationships, such as hyponym-hypernym, cause-effect, meronym-holonym etc. between a pair of entities in a sentence are usually reflected through syntactic patterns. Automatic extraction of such patterns benefits several downstream tasks, including, entity extraction, ontology building, and question answering. Unfortunately, automatic extraction of such patterns has not yet received much attention from NLP and information retrieval researchers. In this work, we propose an attention-based supervised deep learning model, ASPER, which extracts syntactic patterns between entities exhibiting a given semantic relation in the sentential context. We validate the performance of ASPER on three distinct semantic relations -- hyponym-hypernym, cause-effect, and meronym-holonym on six datasets. Experimental results show that for all these semantic relations, ASPER can automatically identify a collection of syntactic patterns reflecting the existence of such a relation between a pair of entities in a sentence. In comparison to the existing methodologies of syntactic pattern extraction, ASPER's performance is substantially superior.
On Mathews Correlation Coefficient and Improved Distance Map Loss for Automatic Glacier Calving Front Segmentation in SAR Imagery
Feb 16, 2021
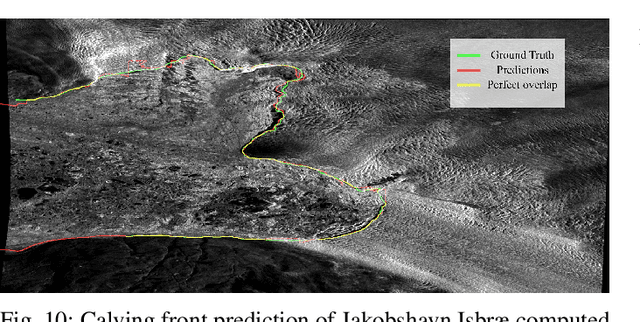
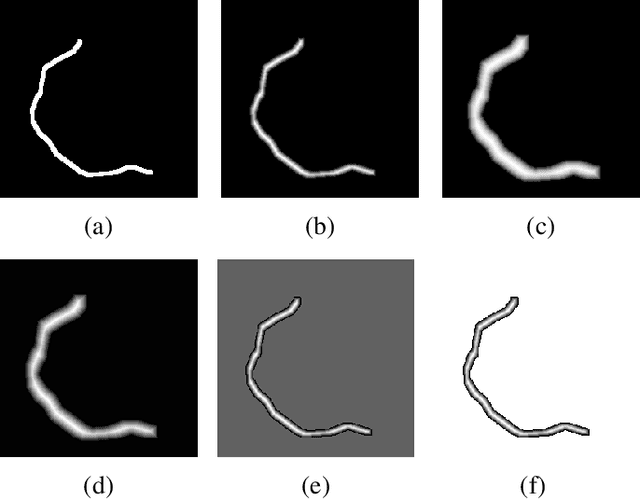

The vast majority of the outlet glaciers and ice streams of the polar ice sheets end in the ocean. Ice mass loss via calving of the glaciers into the ocean has increased over the last few decades. Information on the temporal variability of the calving front position provides fundamental information on the state of the glacier and ice stream, which can be exploited as calibration and validation data to enhance ice dynamics modeling. To identify the calving front position automatically, deep neural network-based semantic segmentation pipelines can be used to delineate the acquired SAR imagery. However, the extreme class imbalance is highly challenging for the accurate calving front segmentation in these images. Therefore, we propose the use of the Mathews correlation coefficient (MCC) as an early stopping criterion because of its symmetrical properties and its invariance towards class imbalance. Moreover, we propose an improvement to the distance map-based binary cross-entropy (BCE) loss function. The distance map adds context to the loss function about the important regions for segmentation and helps accounting for the imbalanced data. Using Mathews correlation coefficient as early stopping demonstrates an average 15% dice coefficient improvement compared to the commonly used BCE. The modified distance map loss further improves the segmentation performance by another 2%. These results are encouraging as they support the effectiveness of the proposed methods for segmentation problems suffering from extreme class imbalances.
UIT-HSE at WNUT-2020 Task 2: Exploiting CT-BERT for Identifying COVID-19 Information on the Twitter Social Network
Sep 07, 2020


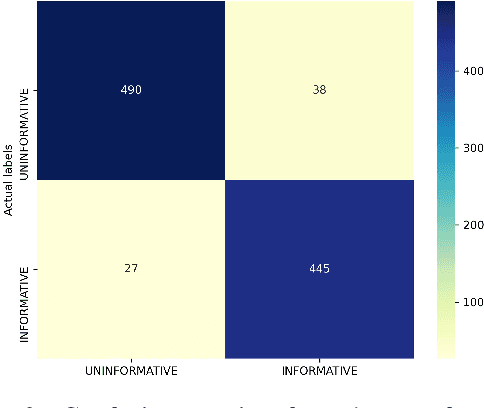
Recently, COVID-19 has affected a variety of real-life aspects of the world and led to dreadful consequences. More and more tweets about COVID-19 has been shared publicly on Twitter. However, the plurality of those Tweets are uninformative, which is challenging to build automatic systems to detect the informative ones for useful AI applications. In this paper, we present our results at the W-NUT 2020 Shared Task 2: Identification of Informative COVID-19 English Tweets. In particular, we propose our simple but effective approach using the transformer-based models based on COVID-Twitter-BERT (CT-BERT) with different fine-tuning techniques. As a result, we achieve the F1-Score of 90.94\% with the third place on the leaderboard of this task which attracted 56 submitted teams in total.
Reconstructing nodal pressures in water distribution systems with graph neural networks
Apr 28, 2021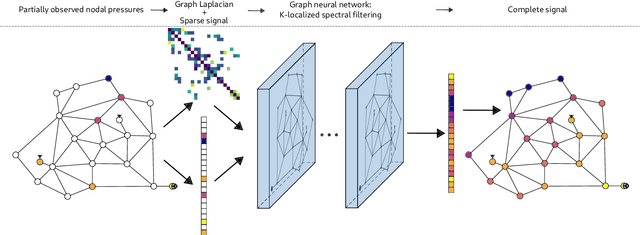
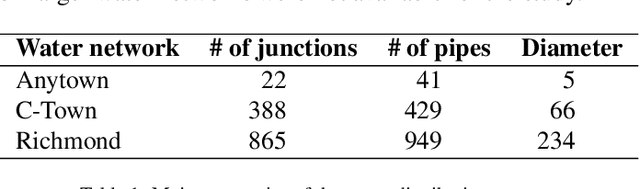
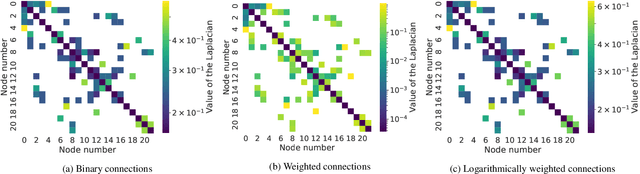

Knowing the pressure at all times in each node of a water distribution system (WDS) facilitates safe and efficient operation. Yet, complete measurement data cannot be collected due to the limited number of instruments in a real-life WDS. The data-driven methodology of reconstructing all the nodal pressures by observing only a limited number of nodes is presented in the paper. The reconstruction method is based on K-localized spectral graph filters, wherewith graph convolution on water networks is possible. The effect of the number of layers, layer depth and the degree of the Chebyshev-polynomial applied in the kernel is discussed taking into account the peculiarities of the application. In addition, a weighting method is shown, wherewith information on friction loss can be embed into the spectral graph filters through the adjacency matrix. The performance of the proposed model is presented on 3 WDSs at different number of nodes observed compared to the total number of nodes. The weighted connections prove no benefit over the binary connections, but the proposed model reconstructs the nodal pressure with at most 5% relative error on average at an observation ratio of 5% at least. The results are achieved with shallow graph neural networks by following the considerations discussed in the paper.
Paragraph-level Simplification of Medical Texts
Apr 12, 2021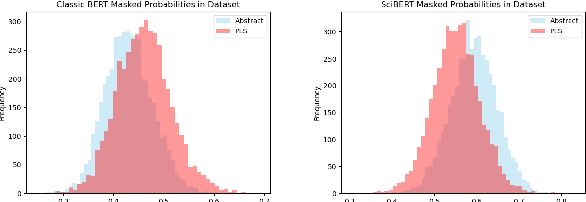
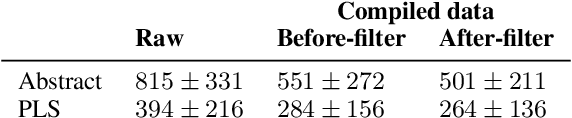
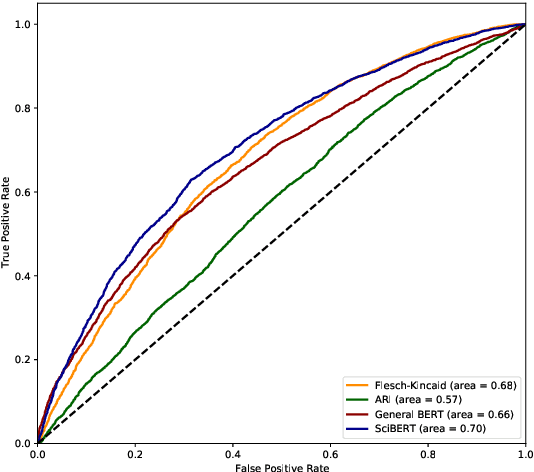

We consider the problem of learning to simplify medical texts. This is important because most reliable, up-to-date information in biomedicine is dense with jargon and thus practically inaccessible to the lay audience. Furthermore, manual simplification does not scale to the rapidly growing body of biomedical literature, motivating the need for automated approaches. Unfortunately, there are no large-scale resources available for this task. In this work we introduce a new corpus of parallel texts in English comprising technical and lay summaries of all published evidence pertaining to different clinical topics. We then propose a new metric based on likelihood scores from a masked language model pretrained on scientific texts. We show that this automated measure better differentiates between technical and lay summaries than existing heuristics. We introduce and evaluate baseline encoder-decoder Transformer models for simplification and propose a novel augmentation to these in which we explicitly penalize the decoder for producing "jargon" terms; we find that this yields improvements over baselines in terms of readability.
Lesion Segmentation and RECIST Diameter Prediction via Click-driven Attention and Dual-path Connection
May 05, 2021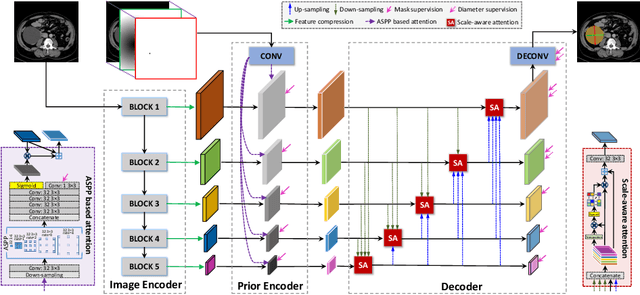
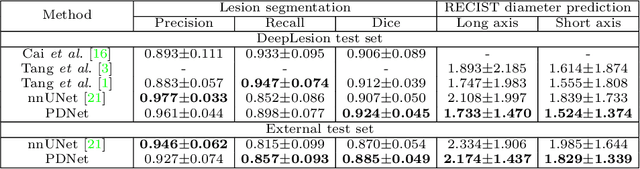
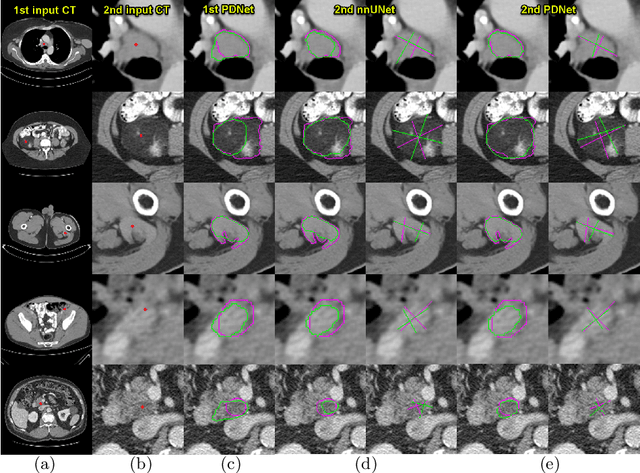
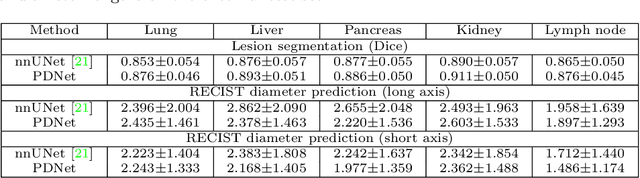
Measuring lesion size is an important step to assess tumor growth and monitor disease progression and therapy response in oncology image analysis. Although it is tedious and highly time-consuming, radiologists have to work on this task by using RECIST criteria (Response Evaluation Criteria In Solid Tumors) routinely and manually. Even though lesion segmentation may be the more accurate and clinically more valuable means, physicians can not manually segment lesions as now since much more heavy laboring will be required. In this paper, we present a prior-guided dual-path network (PDNet) to segment common types of lesions throughout the whole body and predict their RECIST diameters accurately and automatically. Similar to [1], a click guidance from radiologists is the only requirement. There are two key characteristics in PDNet: 1) Learning lesion-specific attention matrices in parallel from the click prior information by the proposed prior encoder, named click-driven attention; 2) Aggregating the extracted multi-scale features comprehensively by introducing top-down and bottom-up connections in the proposed decoder, named dual-path connection. Experiments show the superiority of our proposed PDNet in lesion segmentation and RECIST diameter prediction using the DeepLesion dataset and an external test set. PDNet learns comprehensive and representative deep image features for our tasks and produces more accurate results on both lesion segmentation and RECIST diameter prediction.
Semantic Grouping Network for Video Captioning
Feb 01, 2021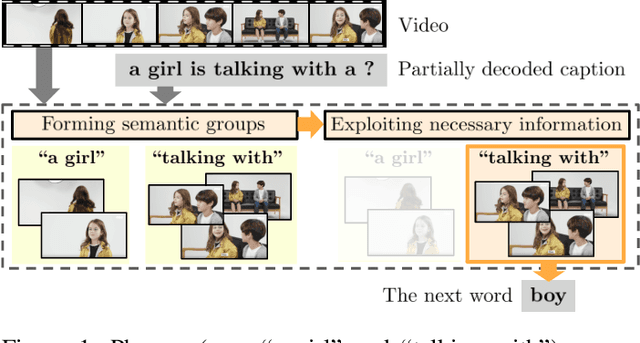
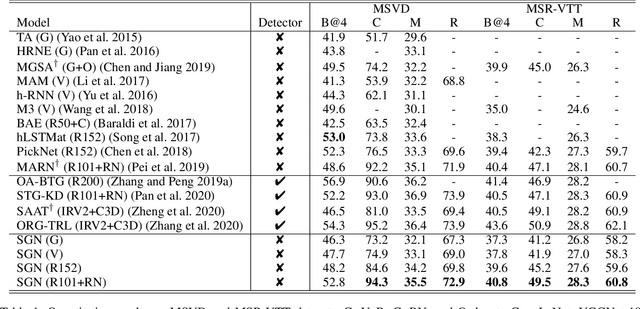

This paper considers a video caption generating network referred to as Semantic Grouping Network (SGN) that attempts (1) to group video frames with discriminating word phrases of partially decoded caption and then (2) to decode those semantically aligned groups in predicting the next word. As consecutive frames are not likely to provide unique information, prior methods have focused on discarding or merging repetitive information based only on the input video. The SGN learns an algorithm to capture the most discriminating word phrases of the partially decoded caption and a mapping that associates each phrase to the relevant video frames - establishing this mapping allows semantically related frames to be clustered, which reduces redundancy. In contrast to the prior methods, the continuous feedback from decoded words enables the SGN to dynamically update the video representation that adapts to the partially decoded caption. Furthermore, a contrastive attention loss is proposed to facilitate accurate alignment between a word phrase and video frames without manual annotations. The SGN achieves state-of-the-art performances by outperforming runner-up methods by a margin of 2.1%p and 2.4%p in a CIDEr-D score on MSVD and MSR-VTT datasets, respectively. Extensive experiments demonstrate the effectiveness and interpretability of the SGN.
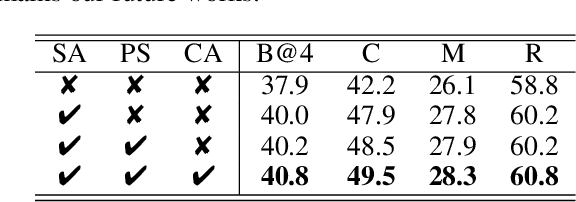
MatScIE: An automated tool for the generation of databases of methods and parameters used in the computational materials science literature
Sep 15, 2020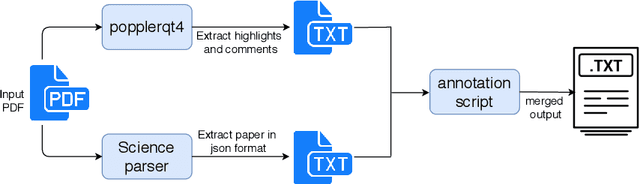
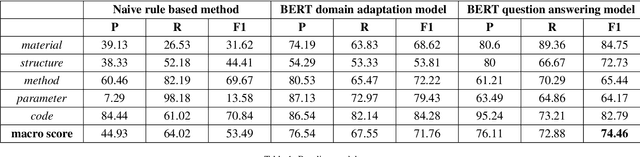
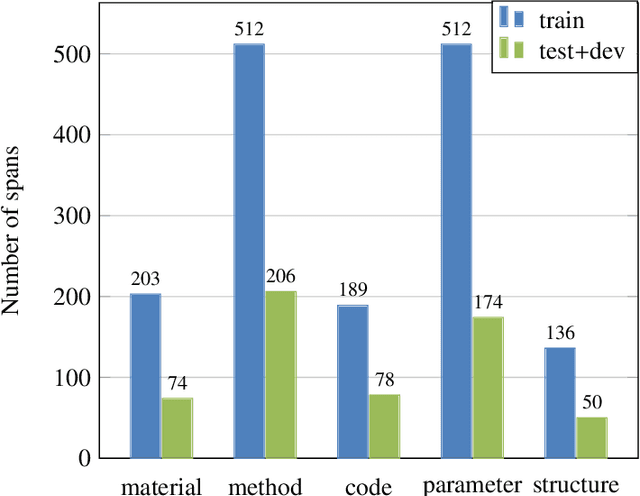
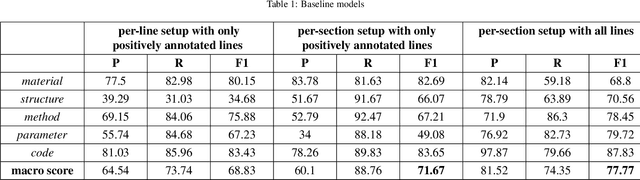
The number of published articles in the field of materials science is growing rapidly every year. This comparatively unstructured data source, which contains a large amount of information, has a restriction on its re-usability, as the information needed to carry out further calculations using the data in it must be extracted manually. It is very important to obtain valid and contextually correct information from the online (offline) data, as it can be useful not only to generate inputs for further calculations, but also to incorporate them into a querying framework. Retaining this context as a priority, we have developed an automated tool, MatScIE (Material Scince Information Extractor) that can extract relevant information from material science literature and make a structured database that is much easier to use for material simulations. Specifically, we extract the material details, methods, code, parameters, and structure from the various research articles. Finally, we created a web application where users can upload published articles and view/download the information obtained from this tool and can create their own databases for their personal uses.