 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Network Creation Games with Local Information and Edge Swaps
Nov 12, 2019
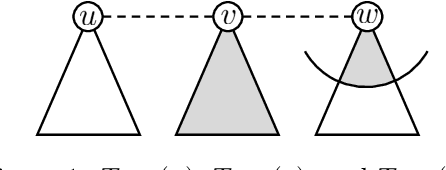
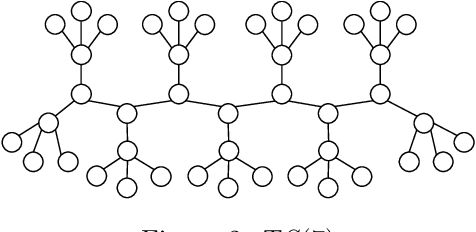
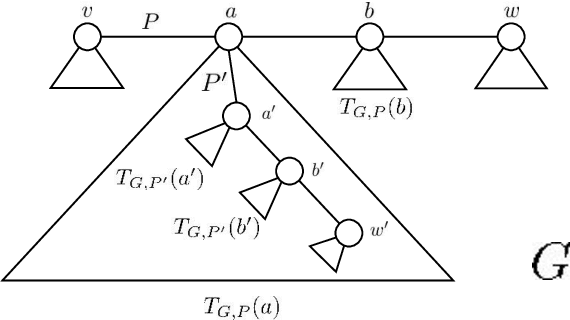
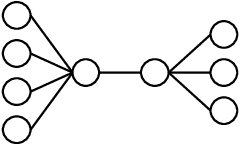
In the swap game (SG) selfish players, each of which is associated to a vertex, form a graph by edge swaps, i.e., a player changes its strategy by simultaneously removing an adjacent edge and forming a new edge (Alon et al., 2013). The cost of a player considers the average distance to all other players or the maximum distance to other players. Any SG by $n$ players starting from a tree converges to an equilibrium with a constant Price of Anarchy (PoA) within $O(n^3)$ edge swaps (Lenzner, 2011). We focus on SGs where each player knows the subgraph induced by players within distance $k$. Therefore, each player cannot compute its cost nor a best response. We first consider pessimistic players who consider the worst-case global graph. We show that any SG starting from a tree (i) always converges to an equilibrium within $O(n^3)$ edge swaps irrespective of the value of $k$, (ii) the PoA is $\Theta(n)$ for $k=1,2,3$, and (iii) the PoA is constant for $k \geq 4$. We then introduce weakly pessimistic players and optimistic players and show that these less pessimistic players achieve constant PoA for $k \leq 3$ at the cost of best response cycles.
SpikE: spike-based embeddings for multi-relational graph data
Apr 27, 2021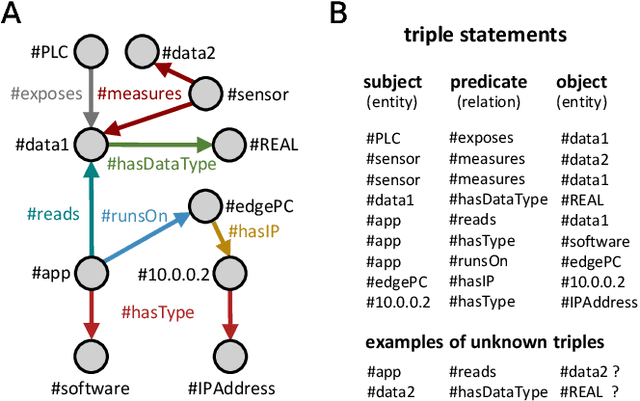
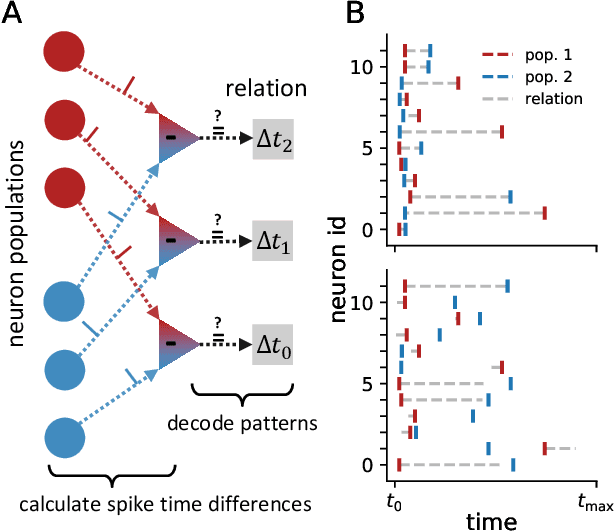
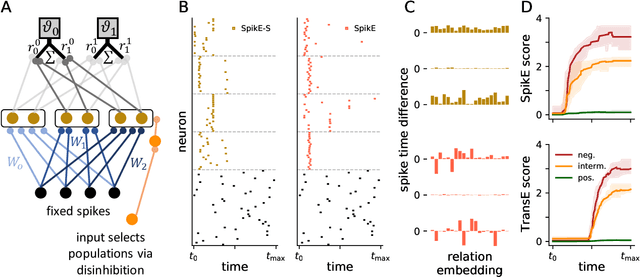
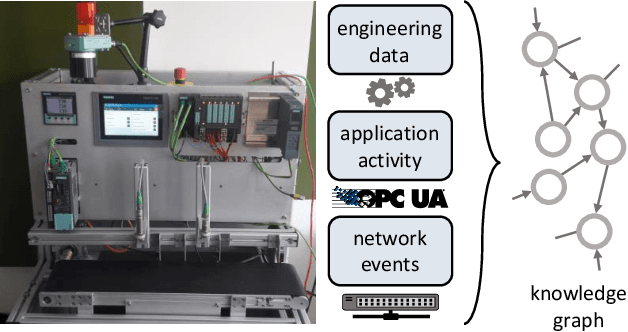
Despite the recent success of reconciling spike-based coding with the error backpropagation algorithm, spiking neural networks are still mostly applied to tasks stemming from sensory processing, operating on traditional data structures like visual or auditory data. A rich data representation that finds wide application in industry and research is the so-called knowledge graph - a graph-based structure where entities are depicted as nodes and relations between them as edges. Complex systems like molecules, social networks and industrial factory systems can be described using the common language of knowledge graphs, allowing the usage of graph embedding algorithms to make context-aware predictions in these information-packed environments. We propose a spike-based algorithm where nodes in a graph are represented by single spike times of neuron populations and relations as spike time differences between populations. Learning such spike-based embeddings only requires knowledge about spike times and spike time differences, compatible with recently proposed frameworks for training spiking neural networks. The presented model is easily mapped to current neuromorphic hardware systems and thereby moves inference on knowledge graphs into a domain where these architectures thrive, unlocking a promising industrial application area for this technology.
Online POMDP Planning via Simplification
May 11, 2021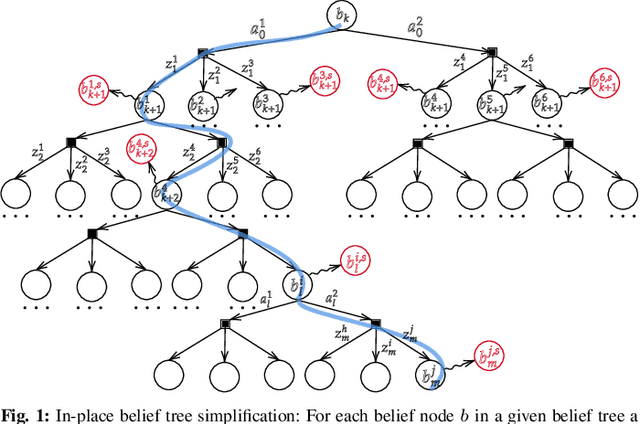
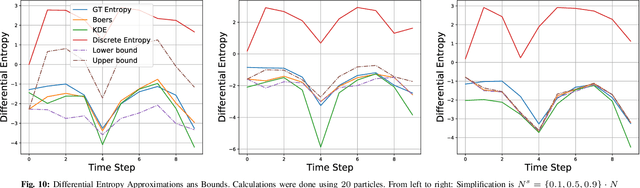

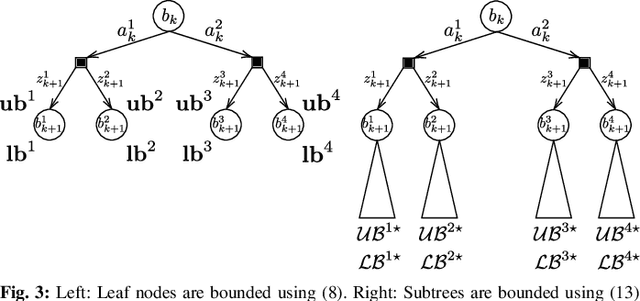
In this paper, we consider online planning in partially observable domains. Solving the corresponding POMDP problem is a very challenging task, particularly in an online setting. Our key contribution is a novel algorithmic approach, Simplified Information Theoretic Belief Space Planning (SITH-BSP), which aims to speed-up POMDP planning considering belief-dependent rewards, without compromising on the solution's accuracy. We do so by mathematically relating the simplified elements of the problem to the corresponding counterparts of the original problem. Specifically, we focus on belief simplification and use it to formulate bounds on the corresponding original belief-dependent rewards. These bounds in turn are used to perform branch pruning over the belief tree, in the process of calculating the optimal policy. We further introduce the notion of adaptive simplification, while re-using calculations between different simplification levels and exploit it to prune, at each level in the belief tree, all branches but one. Therefore, our approach is guaranteed to find the optimal solution of the original problem but with substantial speedup. As a second key contribution, we derive novel analytical bounds for differential entropy, considering a sampling-based belief representation, which we believe are of interest on their own. We validate our approach in simulation using these bounds and where simplification corresponds to reducing the number of samples, exhibiting a significant computational speedup while yielding the optimal solution.
Speaker activity driven neural speech extraction
Jan 14, 2021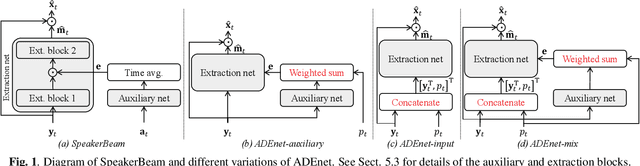

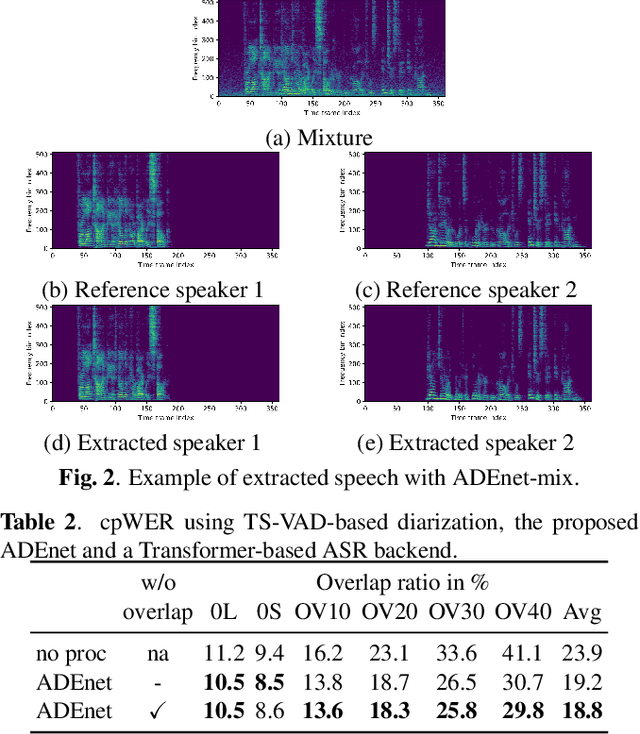
Target speech extraction, which extracts the speech of a target speaker in a mixture given auxiliary speaker clues, has recently received increased interest. Various clues have been investigated such as pre-recorded enrollment utterances, direction information, or video of the target speaker. In this paper, we explore the use of speaker activity information as an auxiliary clue for single-channel neural network-based speech extraction. We propose a speaker activity driven speech extraction neural network (ADEnet) and show that it can achieve performance levels competitive with enrollment-based approaches, without the need for pre-recordings. We further demonstrate the potential of the proposed approach for processing meeting-like recordings, where speaker activity obtained from a diarization system is used as a speaker clue for ADEnet. We show that this simple yet practical approach can successfully extract speakers after diarization, which leads to improved ASR performance when using a single microphone, especially in high overlapping conditions, with a relative word error rate reduction of up to 25 %.
Asymptotic Risk of Overparameterized Likelihood Models: Double Descent Theory for Deep Neural Networks
Mar 15, 2021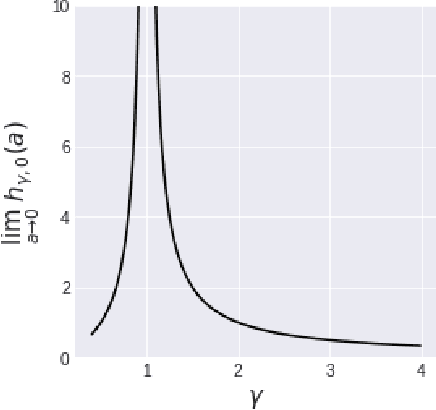
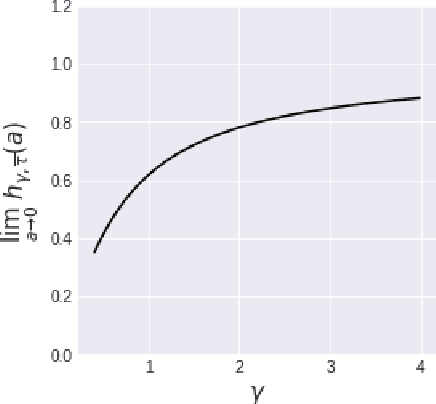
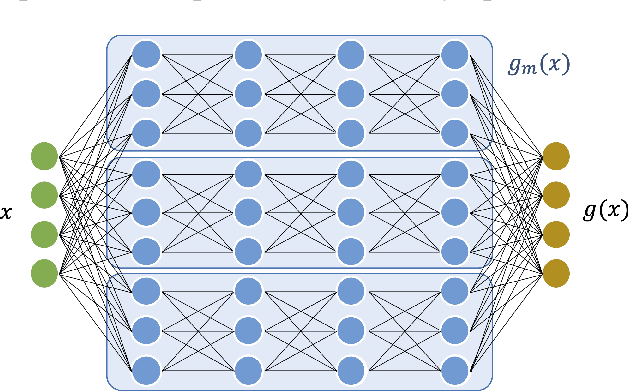
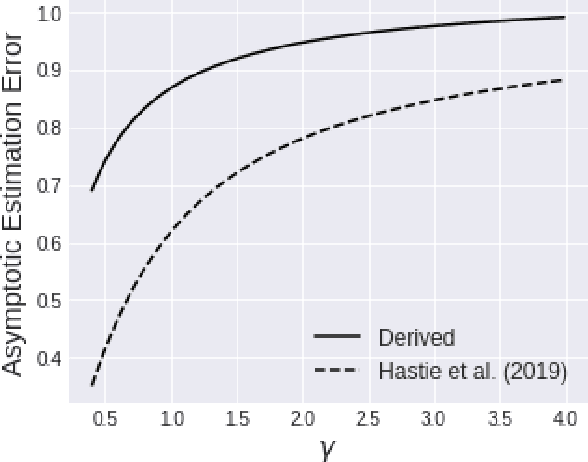
We investigate the asymptotic risk of a general class of overparameterized likelihood models, including deep models. The recent empirical success of large-scale models has motivated several theoretical studies to investigate a scenario wherein both the number of samples, $n$, and parameters, $p$, diverge to infinity and derive an asymptotic risk at the limit. However, these theorems are only valid for linear-in-feature models, such as generalized linear regression, kernel regression, and shallow neural networks. Hence, it is difficult to investigate a wider class of nonlinear models, including deep neural networks with three or more layers. In this study, we consider a likelihood maximization problem without the model constraints and analyze the upper bound of an asymptotic risk of an estimator with penalization. Technically, we combine a property of the Fisher information matrix with an extended Marchenko-Pastur law and associate the combination with empirical process techniques. The derived bound is general, as it describes both the double descent and the regularized risk curves, depending on the penalization. Our results are valid without the linear-in-feature constraints on models and allow us to derive the general spectral distributions of a Fisher information matrix from the likelihood. We demonstrate that several explicit models, such as parallel deep neural networks, ensemble learning, and residual networks, are in agreement with our theory. This result indicates that even large and deep models have a small asymptotic risk if they exhibit a specific structure, such as divisibility. To verify this finding, we conduct a real-data experiment with parallel deep neural networks. Our results expand the applicability of the asymptotic risk analysis, and may also contribute to the understanding and application of deep learning.
Heuristic Weakly Supervised 3D Human Pose Estimation in Novel Contexts without Any 3D Pose Ground Truth
May 23, 2021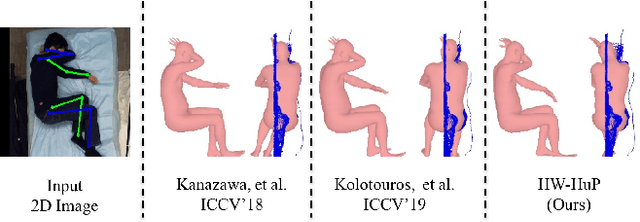
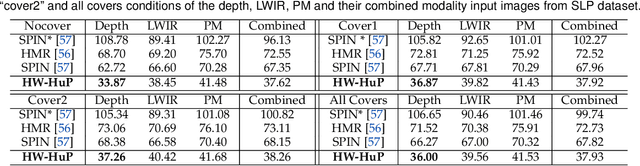
Monocular 3D human pose estimation from a single RGB image has received a lot attentions in the past few year. Pose inference models with competitive performance however require supervision with 3D pose ground truth data or at least known pose priors in their target domain. Yet, these data requirements in many real-world applications with data collection constraints may not be achievable. In this paper, we present a heuristic weakly supervised solution, called HW-HuP to estimate 3D human pose in contexts that no ground truth 3D data is accessible, even for fine-tuning. HW-HuP learns partial pose priors from public 3D human pose datasets and uses easy-to-access observations from the target domain to iteratively estimate 3D human pose and shape in an optimization and regression hybrid cycle. In our design, depth data as an auxiliary information is employed as weak supervision during training, yet it is not needed for the inference. We evaluate HW-HuP performance qualitatively on datasets of both in-bed human and infant poses, where no ground truth 3D pose is provided neither any target prior. We also test HW-HuP performance quantitatively on a publicly available motion capture dataset against the 3D ground truth. HW-HuP is also able to be extended to other input modalities for pose estimation tasks especially under adverse vision conditions, such as occlusion or full darkness. On the Human3.6M benchmark, HW-HuP shows 104.1mm in MPJPE and 50.4mm in PA MPJPE, comparable to the existing state-of-the-art approaches that benefit from full 3D pose supervision.
A Multi-Task Deep Learning Framework for Building Footprint Segmentation
Apr 19, 2021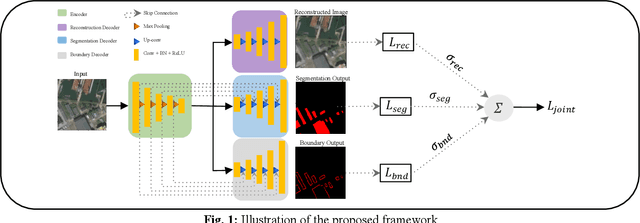
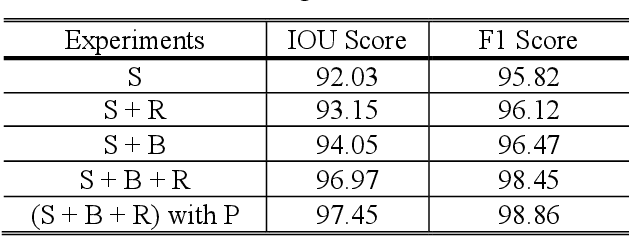

The task of building footprint segmentation has been well-studied in the context of remote sensing (RS) as it provides valuable information in many aspects, however, difficulties brought by the nature of RS images such as variations in the spatial arrangements and in-consistent constructional patterns require studying further, since it often causes poorly classified segmentation maps. We address this need by designing a joint optimization scheme for the task of building footprint delineation and introducing two auxiliary tasks; image reconstruction and building footprint boundary segmentation with the intent to reveal the common underlying structure to advance the classification accuracy of a single task model under the favor of auxiliary tasks. In particular, we propose a deep multi-task learning (MTL) based unified fully convolutional framework which operates in an end-to-end manner by making use of joint loss function with learnable loss weights considering the homoscedastic uncertainty of each task loss. Experimental results conducted on the SpaceNet6 dataset demonstrate the potential of the proposed MTL framework as it improves the classification accuracy considerably compared to single-task and lesser compounded tasks.
Quantum Machine Learning for Power System Stability Assessment
Apr 10, 2021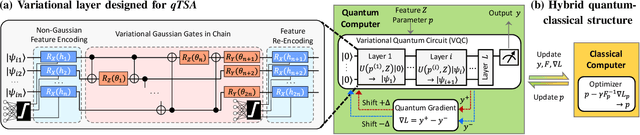
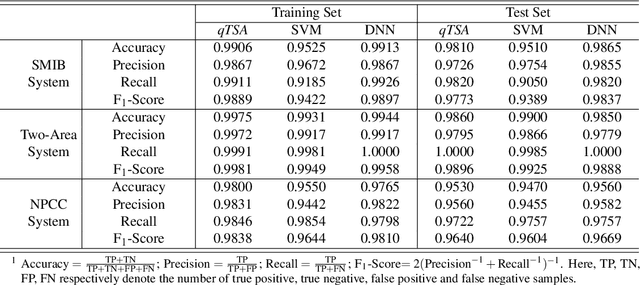
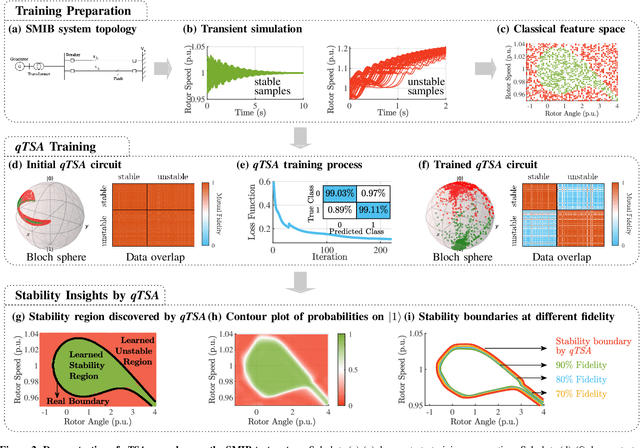
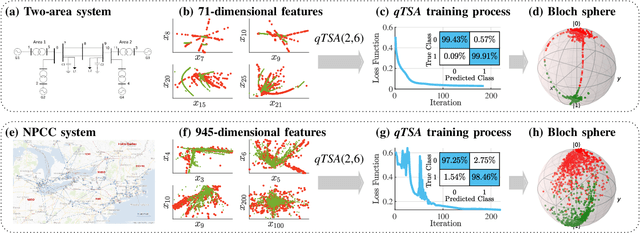
Transient stability assessment (TSA), a cornerstone for resilient operations of today's interconnected power grids, is a grand challenge yet to be addressed since the genesis of electric power systems. This paper is a confluence of quantum computing, data science and machine learning to potentially resolve the aforementioned challenge caused by high dimensionality, non-linearity and uncertainty. We devise a quantum TSA (qTSA) method, a low-depth, high expressibility quantum neural network, to enable scalable and efficient data-driven transient stability prediction for bulk power systems. qTSA renders the intractable TSA straightforward and effortless in the Hilbert space, and provides rich information that enables unprecedentedly resilient and secure power system operations. Extensive experiments on quantum simulators and real quantum computers verify the accuracy, noise-resilience, scalability and universality of qTSA. qTSA underpins a solid foundation of a quantum-enabled, ultra-resilient power grid which will benefit the people as well as various commercial and industrial sectors.
Interpretable Time-series Representation Learning With Multi-Level Disentanglement
May 17, 2021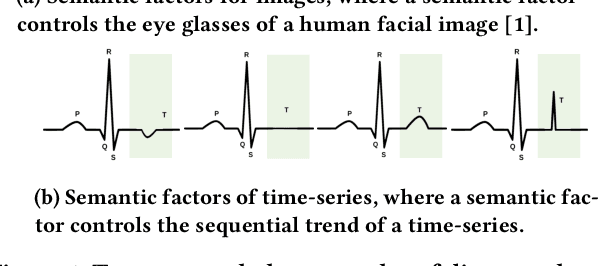
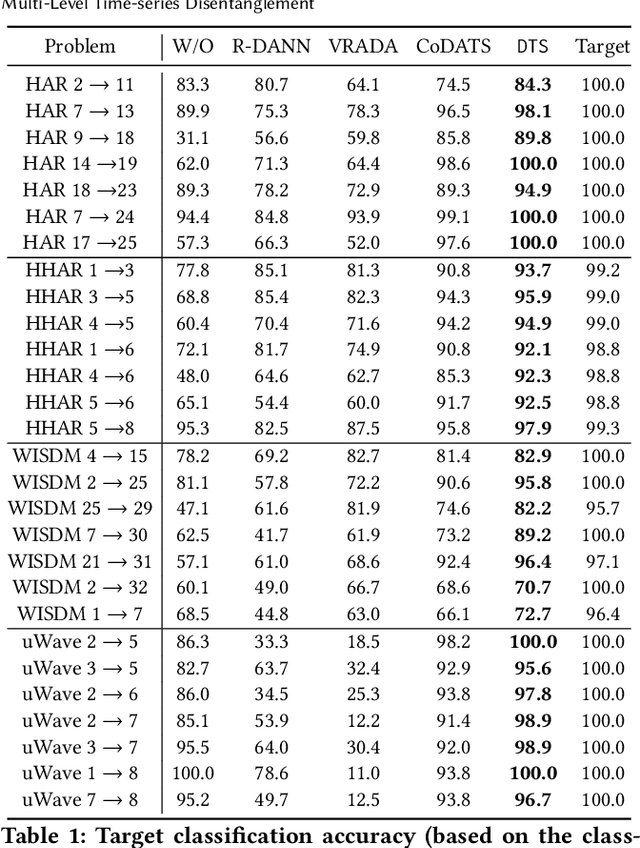
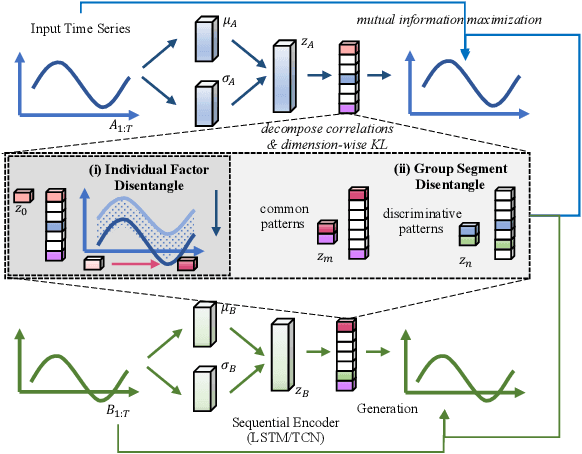
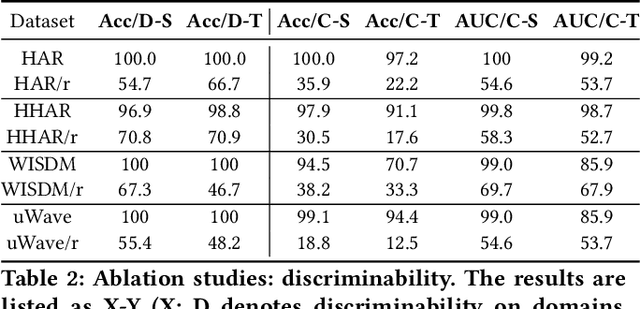
Time-series representation learning is a fundamental task for time-series analysis. While significant progress has been made to achieve accurate representations for downstream applications, the learned representations often lack interpretability and do not expose semantic meanings. Different from previous efforts on the entangled feature space, we aim to extract the semantic-rich temporal correlations in the latent interpretable factorized representation of the data. Motivated by the success of disentangled representation learning in computer vision, we study the possibility of learning semantic-rich time-series representations, which remains unexplored due to three main challenges: 1) sequential data structure introduces complex temporal correlations and makes the latent representations hard to interpret, 2) sequential models suffer from KL vanishing problem, and 3) interpretable semantic concepts for time-series often rely on multiple factors instead of individuals. To bridge the gap, we propose Disentangle Time Series (DTS), a novel disentanglement enhancement framework for sequential data. Specifically, to generate hierarchical semantic concepts as the interpretable and disentangled representation of time-series, DTS introduces multi-level disentanglement strategies by covering both individual latent factors and group semantic segments. We further theoretically show how to alleviate the KL vanishing problem: DTS introduces a mutual information maximization term, while preserving a heavier penalty on the total correlation and the dimension-wise KL to keep the disentanglement property. Experimental results on various real-world benchmark datasets demonstrate that the representations learned by DTS achieve superior performance in downstream applications, with high interpretability of semantic concepts.
Texture for Colors: Natural Representations of Colors Using Variable Bit-Depth Textures
May 04, 2021
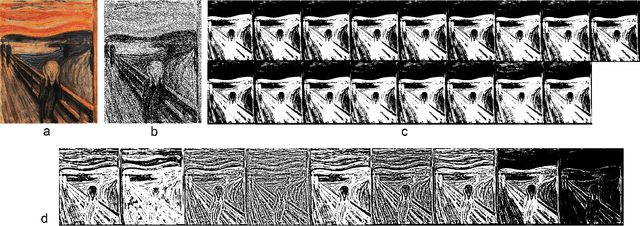
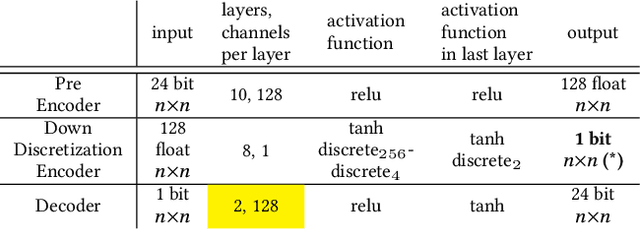

Numerous methods have been proposed to transform color and grayscale images to their single bit-per-pixel binary counterparts. Commonly, the goal is to enhance specific attributes of the original image to make it more amenable for analysis. However, when the resulting binarized image is intended for human viewing, aesthetics must also be considered. Binarization techniques, such as half-toning, stippling, and hatching, have been widely used for modeling the original image's intensity profile. We present an automated method to transform an image to a set of binary textures that represent not only the intensities, but also the colors of the original. The foundation of our method is information preservation: creating a set of textures that allows for the reconstruction of the original image's colors solely from the binarized representation. We present techniques to ensure that the textures created are not visually distracting, preserve the intensity profile of the images, and are natural in that they map sets of colors that are perceptually similar to patterns that are similar. The approach uses deep-neural networks and is entirely self-supervised; no examples of good vs. bad binarizations are required. The system yields aesthetically pleasing binary images when tested on a variety of image sources.