 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Multi-Event Temporal Grounding in Long-Form Video
Jun 13, 2026Multimodal large language models have made rapid progress in video temporal grounding, yet real-world applications routinely require localizing every event that satisfies compositional temporal and spatial conditions. Existing benchmarks fall short: they localize only a single moment per query, count without temporal conditions, or treat grounding and counting as disjoint tasks. We introduce CoMET-Bench for Conditional Multi-Event Temporal Grounding in long-form video, comprising 2789 queries over 600 videos averaging 33.8 minutes across five real-world domains, with each query composed from 4 temporal conditions, 3 spatial conditions, and a dedicated negative-query subset. We further propose a unified evaluation protocol jointly measuring counting, grounding, and negative-query recognition, including a new Rejection-F1 metric that prevents trivial gaming by lazy "always-empty" models. Benchmarking a broad suite of MLLMs, agent-based, and grounding-specialized methods reveals that existing approaches remain far from solving this task. Building on these findings, we propose CoMET-Agent, a training-free agentic framework that reformulates the task as structured search-and-aggregate, improving F1@0.5 by 6.1% over GPT-5 purely through structural reasoning. Failure analysis further surfaces three open directions: fine-grained entity tracking, position-uniform retrieval, and causal event pairing.
Latent Bridge: Feature Delta Prediction for Efficient Dual-System Vision-Language-Action Model Inference
May 04, 2026Dual-system Vision-Language-Action (VLA) models achieve state-of-the-art robotic manipulation but are bottlenecked by the VLM backbone, which must execute at every control step while producing temporally redundant features. We propose Latent Bridge, a lightweight model that predicts VLM output deltas between timesteps, enabling the action head to operate on predicted outputs while the expensive VLM backbone is called only periodically. We instantiate Latent Bridge on two architecturally distinct VLAs: GR00T-N1.6 (feature-space bridge) and π0.5 (KV-cache bridge), demonstrating that the approach generalizes across VLA designs. Our task-agnostic DAgger training pipeline transfers across benchmarks without modification. Across four LIBERO suites, 24 RoboCasa kitchen tasks, and the ALOHA sim transfer-cube task, Latent Bridge achieves 95-100% performance retention while reducing VLM calls by 50-75%, yielding 1.65-1.73x net per-episode speedup.
Prior-Aware Synthetic Data to the Rescue: Animal Pose Estimation with Very Limited Real Data
Aug 30, 2022
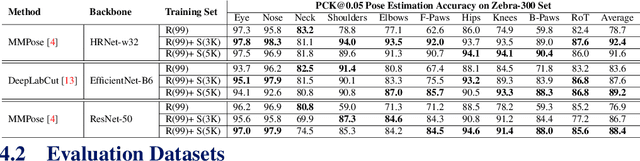
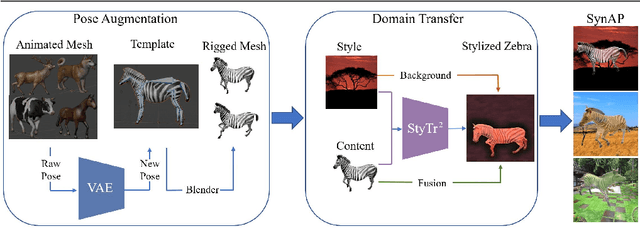
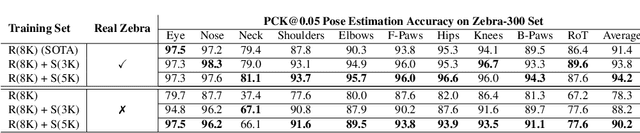
Accurately annotated image datasets are essential components for studying animal behaviors from their poses. Compared to the number of species we know and may exist, the existing labeled pose datasets cover only a small portion of them, while building comprehensive large-scale datasets is prohibitively expensive. Here, we present a very data efficient strategy targeted for pose estimation in quadrupeds that requires only a small amount of real images from the target animal. It is confirmed that fine-tuning a backbone network with pretrained weights on generic image datasets such as ImageNet can mitigate the high demand for target animal pose data and shorten the training time by learning the the prior knowledge of object segmentation and keypoint estimation in advance. However, when faced with serious data scarcity (i.e., $<10^2$ real images), the model performance stays unsatisfactory, particularly for limbs with considerable flexibility and several comparable parts. We therefore introduce a prior-aware synthetic animal data generation pipeline called PASyn to augment the animal pose data essential for robust pose estimation. PASyn generates a probabilistically-valid synthetic pose dataset, SynAP, through training a variational generative model on several animated 3D animal models. In addition, a style transfer strategy is utilized to blend the synthetic animal image into the real backgrounds. We evaluate the improvement made by our approach with three popular backbone networks and test their pose estimation accuracy on publicly available animal pose images as well as collected from real animals in a zoo.
Pressure Eye: In-bed Contact Pressure Estimation via Contact-less Imaging
Jan 27, 2022
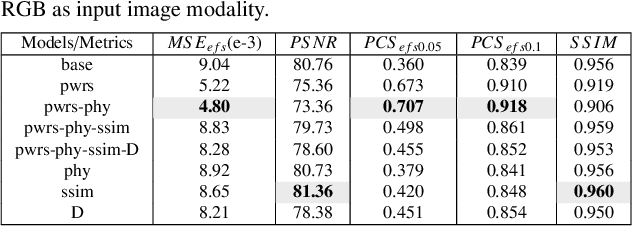
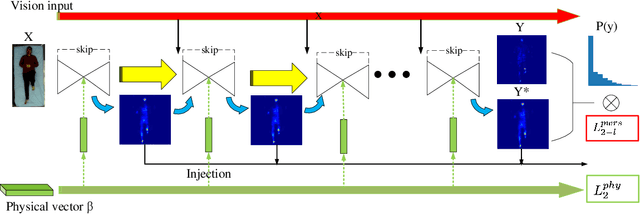
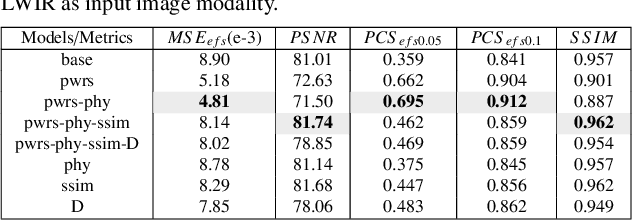
Computer vision has achieved great success in interpreting semantic meanings from images, yet estimating underlying (non-visual) physical properties of an object is often limited to their bulk values rather than reconstructing a dense map. In this work, we present our pressure eye (PEye) approach to estimate contact pressure between a human body and the surface she is lying on with high resolution from vision signals directly. PEye approach could ultimately enable the prediction and early detection of pressure ulcers in bed-bound patients, that currently depends on the use of expensive pressure mats. Our PEye network is configured in a dual encoding shared decoding form to fuse visual cues and some relevant physical parameters in order to reconstruct high resolution pressure maps (PMs). We also present a pixel-wise resampling approach based on Naive Bayes assumption to further enhance the PM regression performance. A percentage of correct sensing (PCS) tailored for sensing estimation accuracy evaluation is also proposed which provides another perspective for performance evaluation under varying error tolerances. We tested our approach via a series of extensive experiments using multimodal sensing technologies to collect data from 102 subjects while lying on a bed. The individual's high resolution contact pressure data could be estimated from their RGB or long wavelength infrared (LWIR) images with 91.8% and 91.2% estimation accuracies in $PCS_{efs0.1}$ criteria, superior to state-of-the-art methods in the related image regression/translation tasks.
Heuristic Weakly Supervised 3D Human Pose Estimation in Novel Contexts without Any 3D Pose Ground Truth
May 23, 2021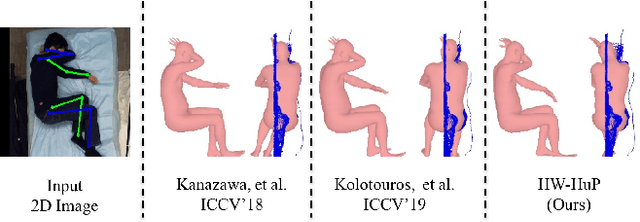
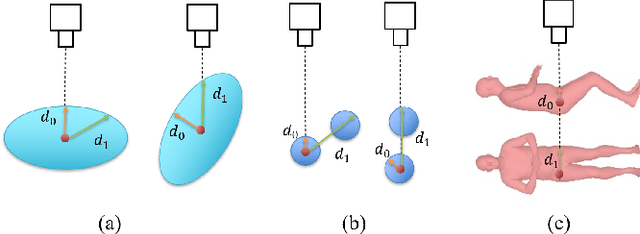
Monocular 3D human pose estimation from a single RGB image has received a lot attentions in the past few year. Pose inference models with competitive performance however require supervision with 3D pose ground truth data or at least known pose priors in their target domain. Yet, these data requirements in many real-world applications with data collection constraints may not be achievable. In this paper, we present a heuristic weakly supervised solution, called HW-HuP to estimate 3D human pose in contexts that no ground truth 3D data is accessible, even for fine-tuning. HW-HuP learns partial pose priors from public 3D human pose datasets and uses easy-to-access observations from the target domain to iteratively estimate 3D human pose and shape in an optimization and regression hybrid cycle. In our design, depth data as an auxiliary information is employed as weak supervision during training, yet it is not needed for the inference. We evaluate HW-HuP performance qualitatively on datasets of both in-bed human and infant poses, where no ground truth 3D pose is provided neither any target prior. We also test HW-HuP performance quantitatively on a publicly available motion capture dataset against the 3D ground truth. HW-HuP is also able to be extended to other input modalities for pose estimation tasks especially under adverse vision conditions, such as occlusion or full darkness. On the Human3.6M benchmark, HW-HuP shows 104.1mm in MPJPE and 50.4mm in PA MPJPE, comparable to the existing state-of-the-art approaches that benefit from full 3D pose supervision.
Adapted Human Pose: Monocular 3D Human Pose Estimation with Zero Real 3D Pose Data
May 23, 2021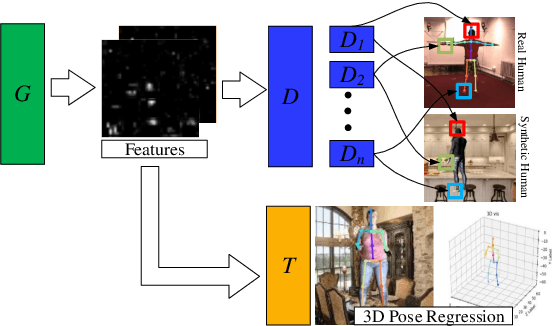
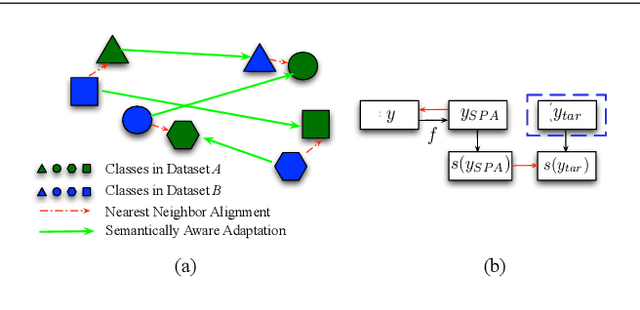
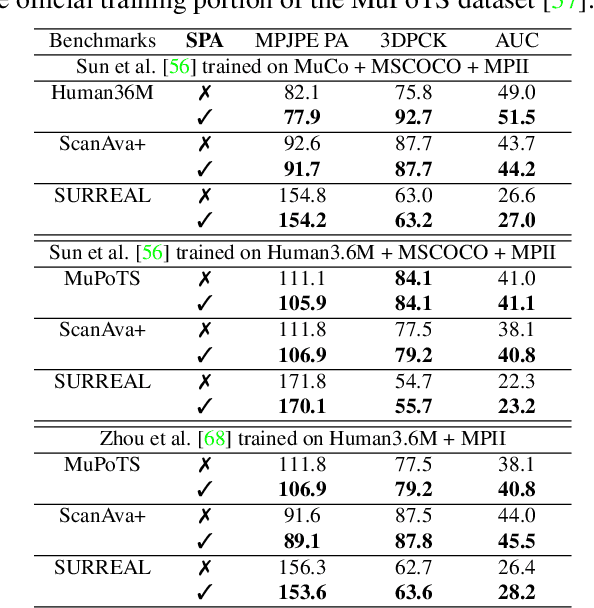
The ultimate goal for an inference model is to be robust and functional in real life applications. However, training vs. test data domain gaps often negatively affect model performance. This issue is especially critical for the monocular 3D human pose estimation problem, in which 3D human data is often collected in a controlled lab setting. In this paper, we focus on alleviating the negative effect of domain shift by presenting our adapted human pose (AHuP) approach that addresses adaptation problems in both appearance and pose spaces. AHuP is built around a practical assumption that in real applications, data from target domain could be inaccessible or only limited information can be acquired. We illustrate the 3D pose estimation performance of AHuP in two scenarios. First, when source and target data differ significantly in both appearance and pose spaces, in which we learn from synthetic 3D human data (with zero real 3D human data) and show comparable performance with the state-of-the-art 3D pose estimation models that have full access to the real 3D human pose benchmarks for training. Second, when source and target datasets differ mainly in the pose space, in which AHuP approach can be applied to further improve the performance of the state-of-the-art models when tested on the datasets different from their training dataset.
Simultaneously-Collected Multimodal Lying Pose Dataset: Towards In-Bed Human Pose Monitoring under Adverse Vision Conditions
Aug 20, 2020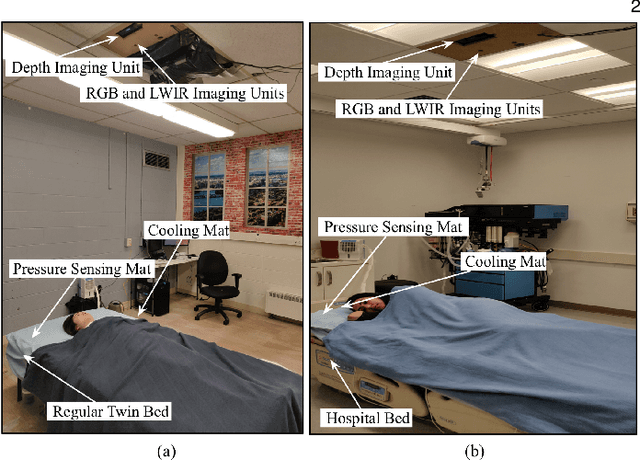
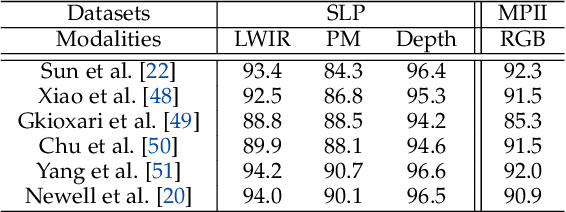
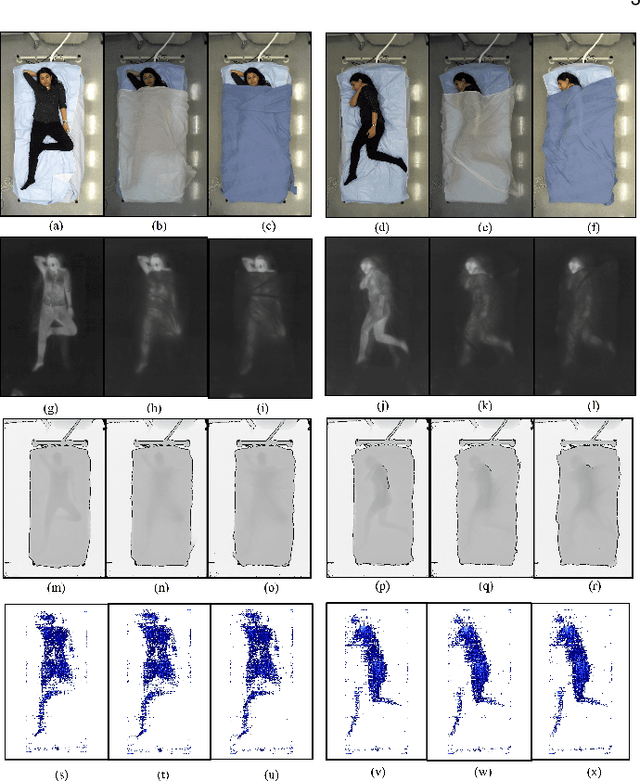
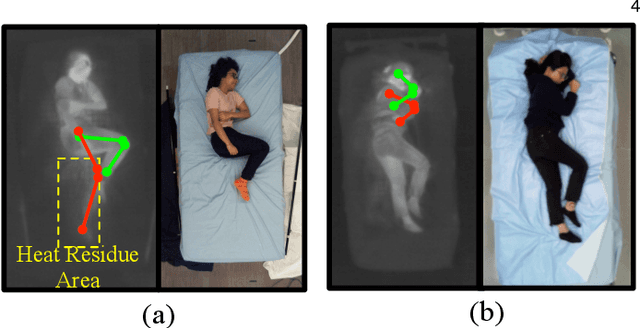
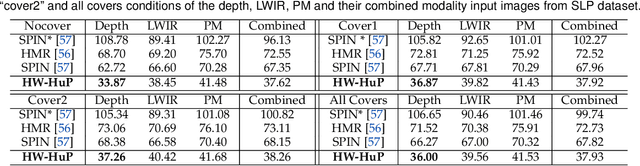
Computer vision (CV) has achieved great success in interpreting semantic meanings from images, yet CV algorithms can be brittle for tasks with adverse vision conditions and the ones suffering from data/label pair limitation. One of this tasks is in-bed human pose estimation, which has significant values in many healthcare applications. In-bed pose monitoring in natural settings could involve complete darkness or full occlusion. Furthermore, the lack of publicly available in-bed pose datasets hinders the use of many successful pose estimation algorithms for this task. In this paper, we introduce our Simultaneously-collected multimodal Lying Pose (SLP) dataset, which includes in-bed pose images from 109 participants captured using multiple imaging modalities including RGB, long wave infrared, depth, and pressure map. We also present a physical hyper parameter tuning strategy for ground truth pose label generation under extreme conditions such as lights off and being fully covered by a sheet/blanket. SLP design is compatible with the mainstream human pose datasets, therefore, the state-of-the-art 2D pose estimation models can be trained effectively with SLP data with promising performance as high as 95% at PCKh@0.5 on a single modality. The pose estimation performance can be further improved by including additional modalities through collaboration.
Development of Use-specific High Performance Cyber-Nanomaterial Optical Detectors by Effective Choice of Machine Learning Algorithms
Jan 03, 2020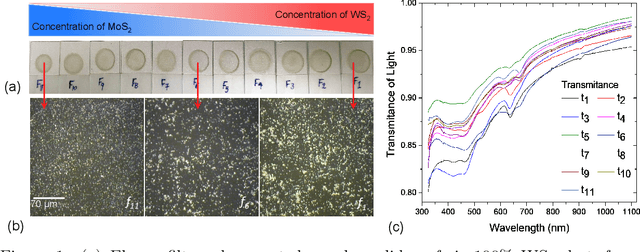
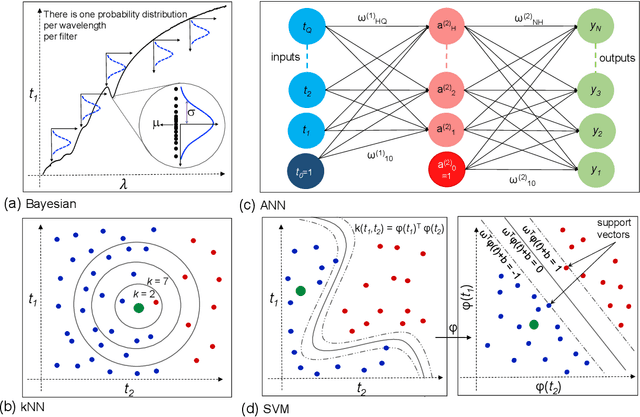
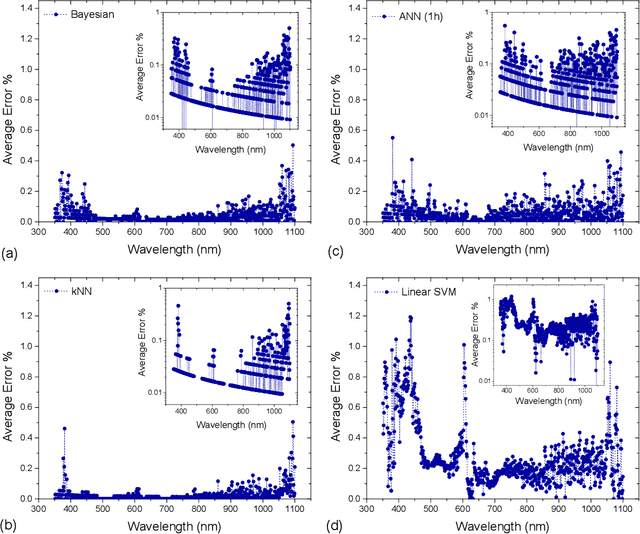
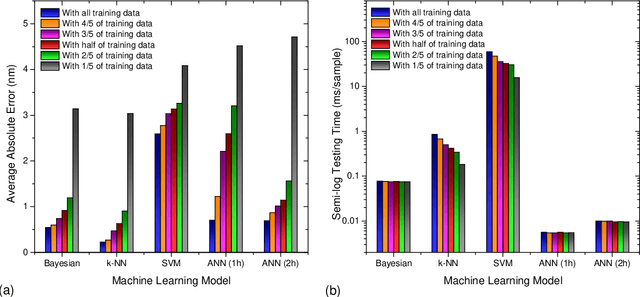
Due to their inherent variabilities,nanomaterial-based sensors are challenging to translate into real-world applications,where reliability/reproducibility is key.Recently we showed Bayesian inference can be employed on engineered variability in layered nanomaterial-based optical transmission filters to determine optical wavelengths with high accuracy/precision.In many practical applications the sensing cost/speed and long-term reliability can be equal or more important considerations.Though various machine learning tools are frequently used on sensor/detector networks to address these,nonetheless their effectiveness on nanomaterial-based sensors has not been explored.Here we show the best choice of ML algorithm in a cyber-nanomaterial detector is mainly determined by specific use considerations,e.g.,accuracy, computational cost,speed, and resilience against drifts/ageing effects.When sufficient data/computing resources are provided,highest sensing accuracy can be achieved by the kNN and Bayesian inference algorithms,but but can be computationally expensive for real-time applications.In contrast,artificial neural networks are computationally expensive to train,but provide the fastest result under testing conditions and remain reasonably accurate.When data is limited,SVMs perform well even with small training sets,while other algorithms show considerable reduction in accuracy if data is scarce,hence,setting a lower limit on the size of required training data.We show by tracking/modeling the long-term drifts of the detector performance over large (1year) period,it is possible to improve the predictive accuracy with no need for recalibration.Our research shows for the first time if the ML algorithm is chosen specific to use-case,low-cost solution-processed cyber-nanomaterial detectors can be practically implemented under diverse operational requirements,despite their inherent variabilities.
Seeing Under the Cover: A Physics Guided Learning Approach for In-Bed Pose Estimation
Jul 17, 2019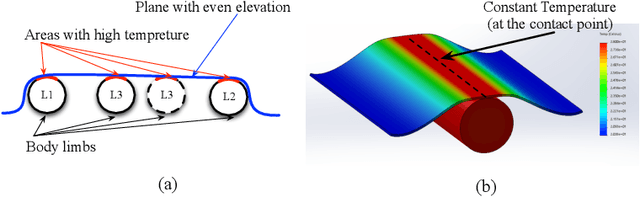
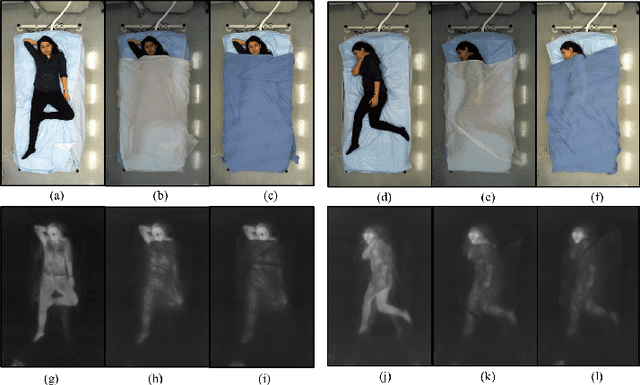
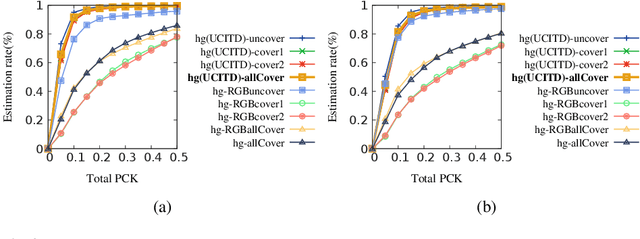
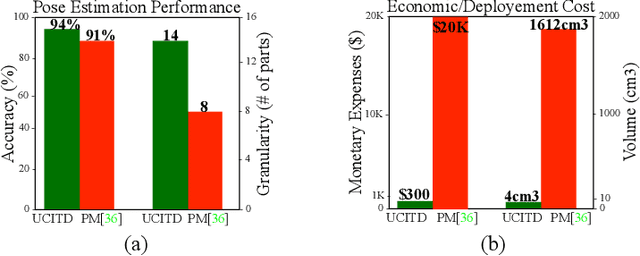
Human in-bed pose estimation has huge practical values in medical and healthcare applications yet still mainly relies on expensive pressure mapping (PM) solutions. In this paper, we introduce our novel physics inspired vision-based approach that addresses the challenging issues associated with the in-bed pose estimation problem including monitoring a fully covered person in complete darkness. We reformulated this problem using our proposed Under the Cover Imaging via Thermal Diffusion (UCITD) method to capture the high resolution pose information of the body even when it is fully covered by using a long wavelength IR technique. We proposed a physical hyperparameter concept through which we achieved high quality groundtruth pose labels in different modalities. A fully annotated in-bed pose dataset called Simultaneously-collected multimodal Lying Pose (SLP) is also formed/released with the same order of magnitude as most existing large-scale human pose datasets to support complex models' training and evaluation. A network trained from scratch on it and tested on two diverse settings, one in a living room and the other in a hospital room showed pose estimation performance of 99.5% and 95.7% in PCK0.2 standard, respectively. Moreover, in a multi-factor comparison with a state-of-the art in-bed pose monitoring solution based on PM, our solution showed significant superiority in all practical aspects by being 60 times cheaper, 300 times smaller, while having higher pose recognition granularity and accuracy.
A Semi-Supervised Data Augmentation Approach using 3D Graphical Engines
Sep 28, 2018



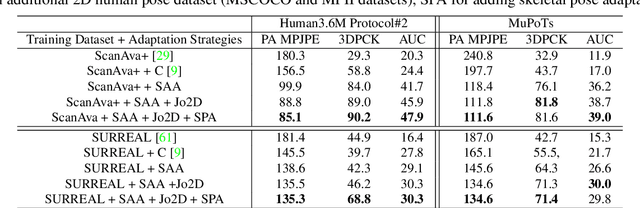
Deep learning approaches have been rapidly adopted across a wide range of fields because of their accuracy and flexibility, but require large labeled training datasets. This presents a fundamental problem for applications with limited, expensive, or private data (i.e. small data), such as human pose and behavior estimation/tracking which could be highly personalized. In this paper, we present a semi-supervised data augmentation approach that can synthesize large scale labeled training datasets using 3D graphical engines based on a physically-valid low dimensional pose descriptor. To evaluate the performance of our synthesized datasets in training deep learning-based models, we generated a large synthetic human pose dataset, called ScanAva using 3D scans of only 7 individuals based on our proposed augmentation approach. A state-of-the-art human pose estimation deep learning model then was trained from scratch using our ScanAva dataset and could achieve the pose estimation accuracy of 91.2% at PCK0.5 criteria after applying an efficient domain adaptation on the synthetic images, in which its pose estimation accuracy was comparable to the same model trained on large scale pose data from real humans such as MPII dataset and much higher than the model trained on other synthetic human dataset such as SURREAL.