 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ConTNet: Why not use convolution and transformer at the same time?
May 06, 2021
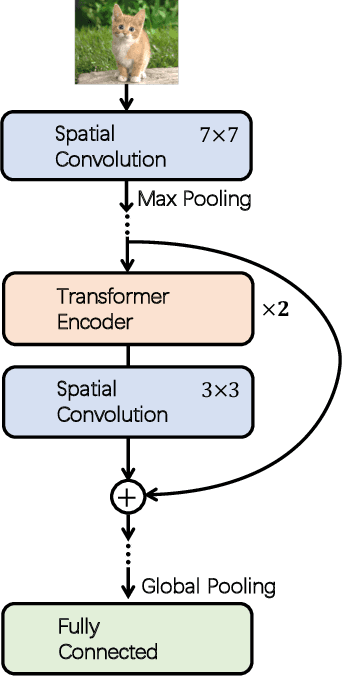
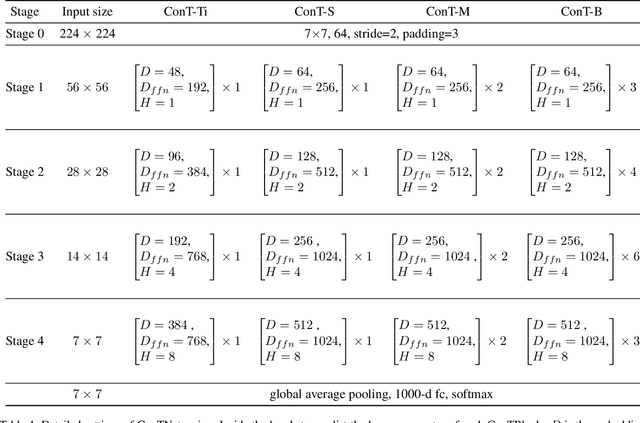

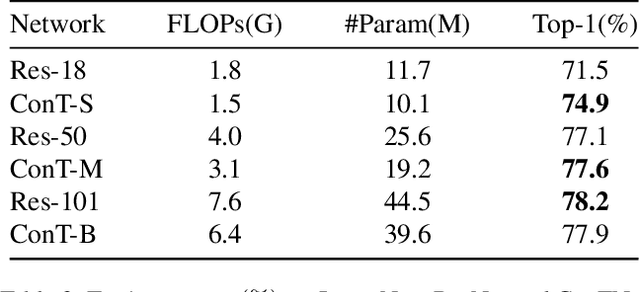
Although convolutional networks (ConvNets) have enjoyed great success in computer vision (CV), it suffers from capturing global information crucial to dense prediction tasks such as object detection and segmentation. In this work, we innovatively propose ConTNet (ConvolutionTransformer Network), combining transformer with ConvNet architectures to provide large receptive fields. Unlike the recently-proposed transformer-based models (e.g., ViT, DeiT) that are sensitive to hyper-parameters and extremely dependent on a pile of data augmentations when trained from scratch on a midsize dataset (e.g., ImageNet1k), ConTNet can be optimized like normal ConvNets (e.g., ResNet) and preserve an outstanding robustness. It is also worth pointing that, given identical strong data augmentations, the performance improvement of ConTNet is more remarkable than that of ResNet. We present its superiority and effectiveness on image classification and downstream tasks. For example, our ConTNet achieves 81.8% top-1 accuracy on ImageNet which is the same as DeiT-B with less than 40% computational complexity. ConTNet-M also outperforms ResNet50 as the backbone of both Faster-RCNN (by 2.6%) and Mask-RCNN (by 3.2%) on COCO2017 dataset. We hope that ConTNet could serve as a useful backbone for CV tasks and bring new ideas for model design
Dual Contrastive Learning for Unsupervised Image-to-Image Translation
Apr 15, 2021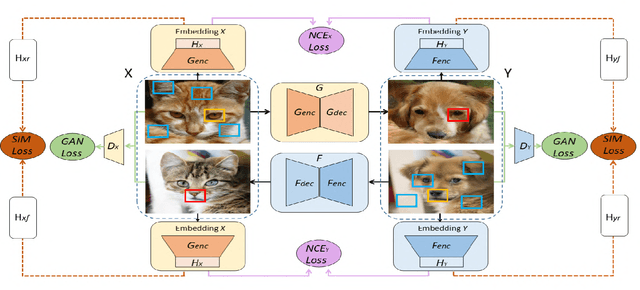
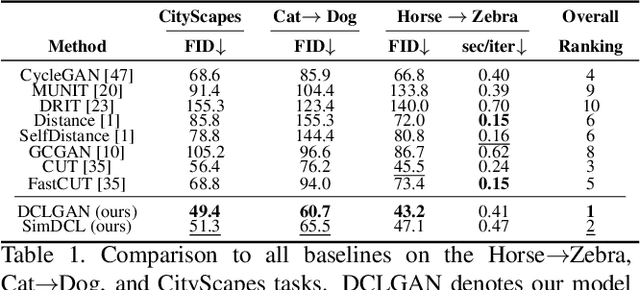


Unsupervised image-to-image translation tasks aim to find a mapping between a source domain X and a target domain Y from unpaired training data. Contrastive learning for Unpaired image-to-image Translation (CUT) yields state-of-the-art results in modeling unsupervised image-to-image translation by maximizing mutual information between input and output patches using only one encoder for both domains. In this paper, we propose a novel method based on contrastive learning and a dual learning setting (exploiting two encoders) to infer an efficient mapping between unpaired data. Additionally, while CUT suffers from mode collapse, a variant of our method efficiently addresses this issue. We further demonstrate the advantage of our approach through extensive ablation studies demonstrating superior performance comparing to recent approaches in multiple challenging image translation tasks. Lastly, we demonstrate that the gap between unsupervised methods and supervised methods can be efficiently closed.
Time-Stamped Language Model: Teaching Language Models to Understand the Flow of Events
Apr 15, 2021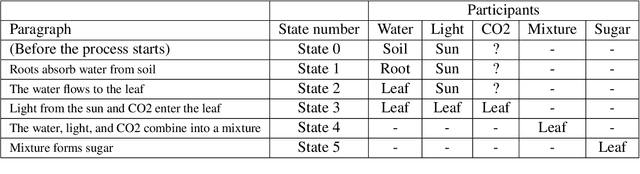
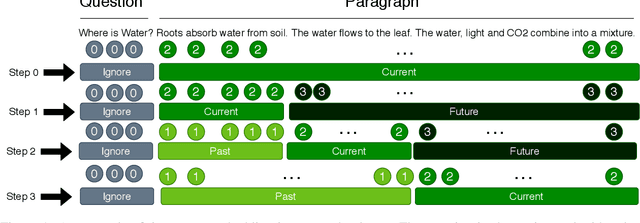
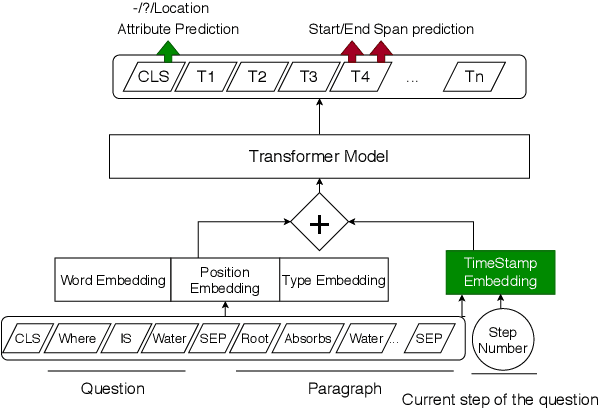
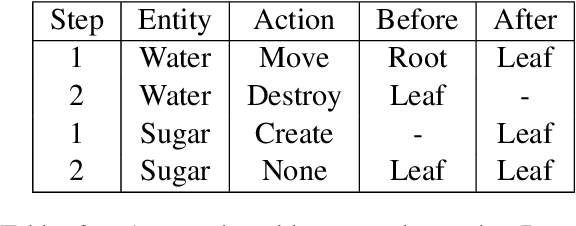
Tracking entities throughout a procedure described in a text is challenging due to the dynamic nature of the world described in the process. Firstly, we propose to formulate this task as a question answering problem. This enables us to use pre-trained transformer-based language models on other QA benchmarks by adapting those to the procedural text understanding. Secondly, since the transformer-based language models cannot encode the flow of events by themselves, we propose a Time-Stamped Language Model~(TSLM model) to encode event information in LMs architecture by introducing the timestamp encoding. Our model evaluated on the Propara dataset shows improvements on the published state-of-the-art results with a $3.1\%$ increase in F1 score. Moreover, our model yields better results on the location prediction task on the NPN-Cooking dataset. This result indicates that our approach is effective for procedural text understanding in general.
TriPose: A Weakly-Supervised 3D Human Pose Estimation via Triangulation from Video
May 14, 2021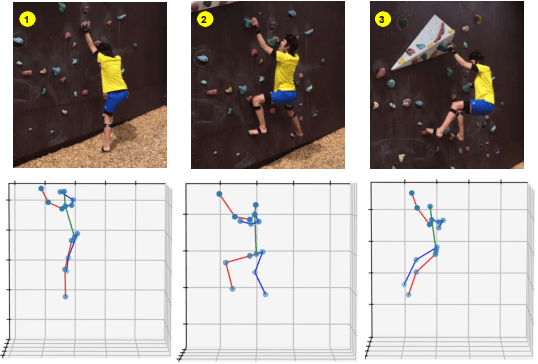
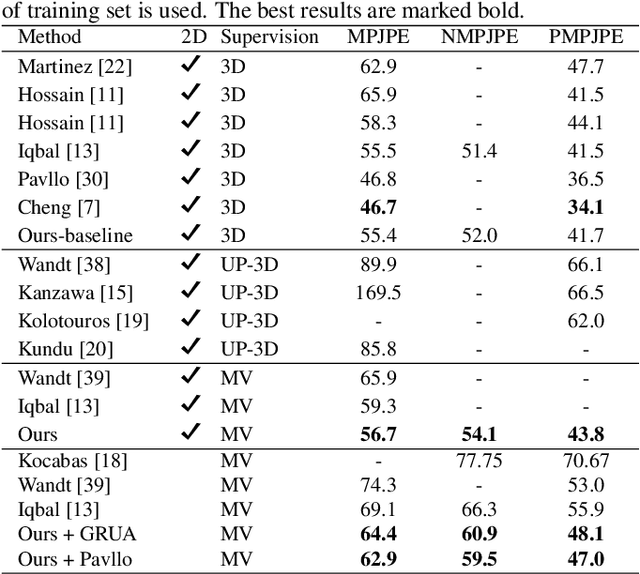
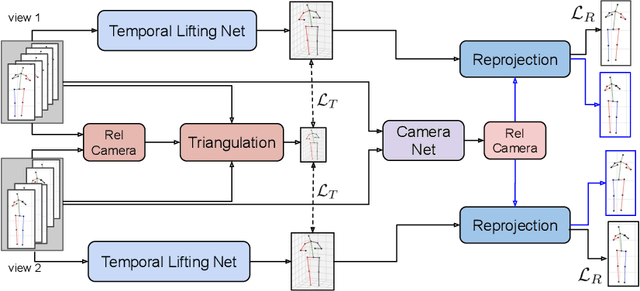
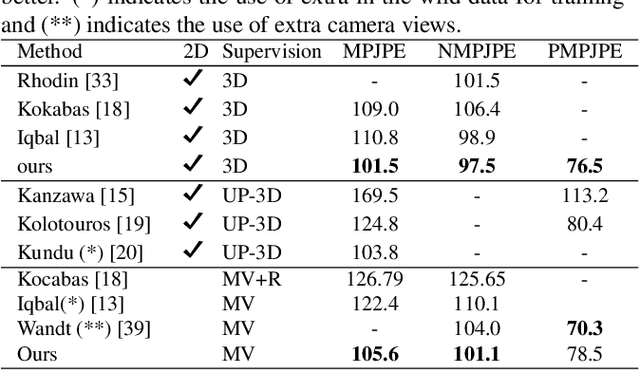
Estimating 3D human poses from video is a challenging problem. The lack of 3D human pose annotations is a major obstacle for supervised training and for generalization to unseen datasets. In this work, we address this problem by proposing a weakly-supervised training scheme that does not require 3D annotations or calibrated cameras. The proposed method relies on temporal information and triangulation. Using 2D poses from multiple views as the input, we first estimate the relative camera orientations and then generate 3D poses via triangulation. The triangulation is only applied to the views with high 2D human joint confidence. The generated 3D poses are then used to train a recurrent lifting network (RLN) that estimates 3D poses from 2D poses. We further apply a multi-view re-projection loss to the estimated 3D poses and enforce the 3D poses estimated from multi-views to be consistent. Therefore, our method relaxes the constraints in practice, only multi-view videos are required for training, and is thus convenient for in-the-wild settings. At inference, RLN merely requires single-view videos. The proposed method outperforms previous works on two challenging datasets, Human3.6M and MPI-INF-3DHP. Codes and pretrained models will be publicly available.
An Ensemble Classification Algorithm Based on Information Entropy for Data Streams
Aug 11, 2017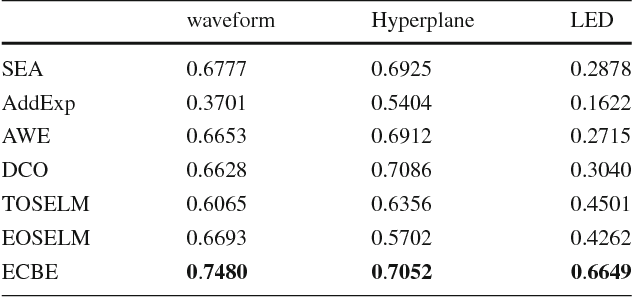
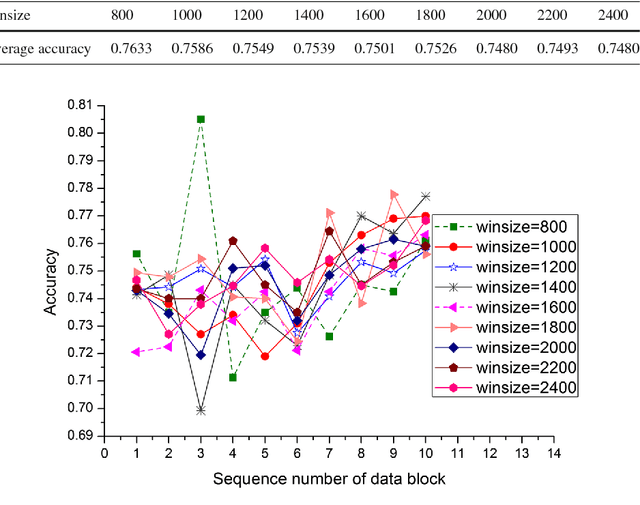
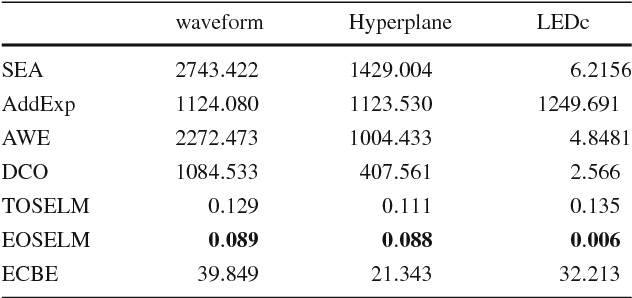
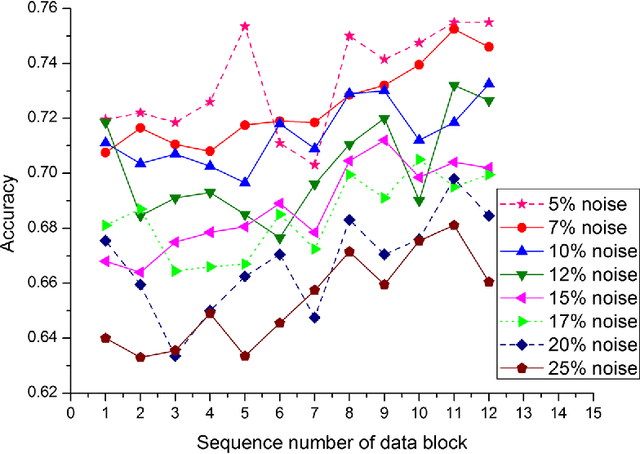
Data stream mining problem has caused widely concerns in the area of machine learning and data mining. In some recent studies, ensemble classification has been widely used in concept drift detection, however, most of them regard classification accuracy as a criterion for judging whether concept drift happening or not. Information entropy is an important and effective method for measuring uncertainty. Based on the information entropy theory, a new algorithm using information entropy to evaluate a classification result is developed. It uses ensemble classification techniques, and the weight of each classifier is decided through the entropy of the result produced by an ensemble classifiers system. When the concept in data streams changing, the classifiers' weight below a threshold value will be abandoned to adapt to a new concept in one time. In the experimental analysis section, six databases and four proposed algorithms are executed. The results show that the proposed method can not only handle concept drift effectively, but also have a better classification accuracy and time performance than the contrastive algorithms.
Age of Gossip in Networks with Community Structure
May 06, 2021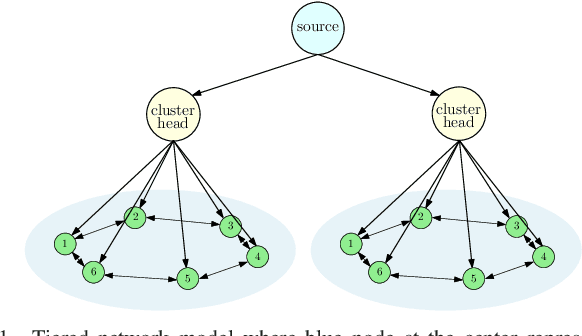
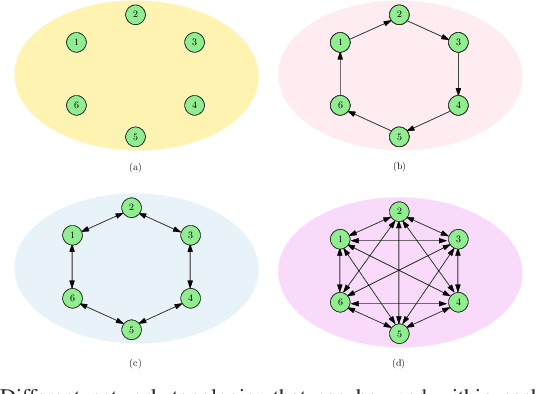
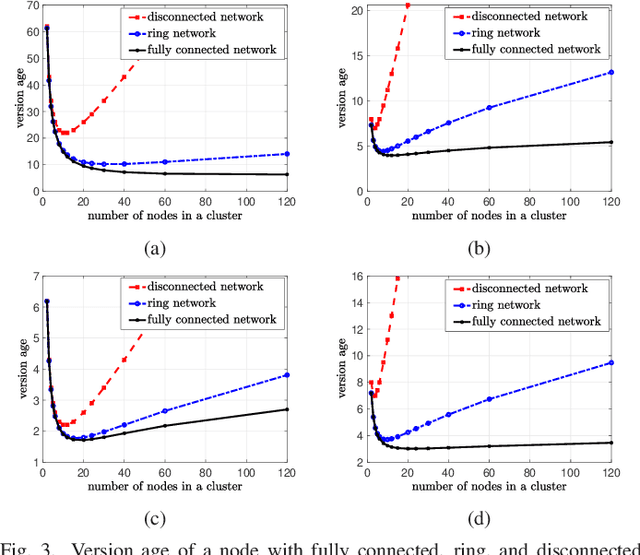
We consider a network consisting of a single source and $n$ receiver nodes that are grouped into $m$ equal size communities, i.e., clusters, where each cluster includes $k$ nodes and is served by a dedicated cluster head. The source node keeps versions of an observed process and updates each cluster through the associated cluster head. Nodes within each cluster are connected to each other according to a given network topology. Based on this topology, each node relays its current update to its neighboring nodes by $local$ $gossiping$. We use the $version$ $age$ metric to quantify information timeliness at the receiver nodes. We consider disconnected, ring, and fully connected network topologies for each cluster. For each of these network topologies, we characterize the average version age at each node and find the version age scaling as a function of the network size $n$. Our results indicate that per node version age scalings of $O(\sqrt{n})$, $O(n^{\frac{1}{3}})$, and $O(\log n)$ are achievable in disconnected, ring, and fully connected networks, respectively. Finally, through numerical evaluations, we determine the version age-optimum $(m,k)$ pairs as a function of the source, cluster head, and node update rates.
Design of Non-Coherent and Coherent Receivers for Chirp Spread Spectrum Systems
May 06, 2021
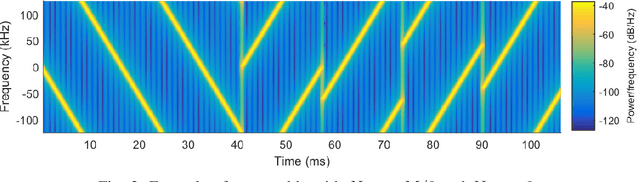
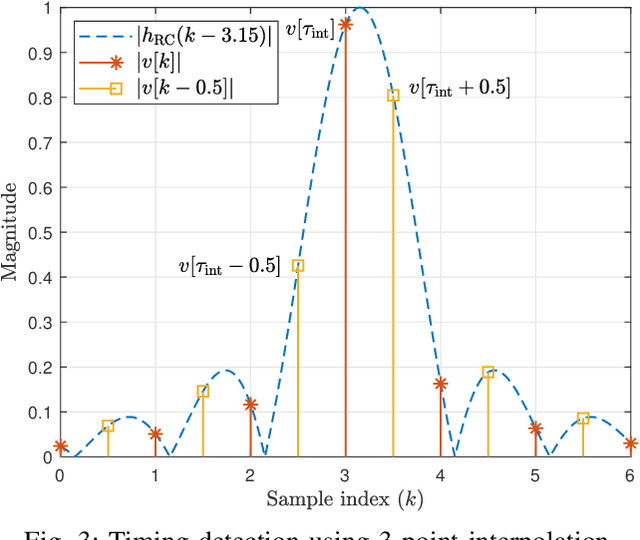
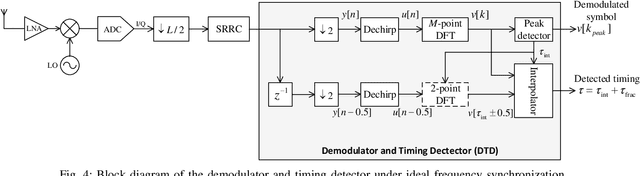
LoRaWAN is a prominent communication standard to enable reliable low-power, long-range communications for the Internet of Things (IoT). The modulation technique used in LoRaWAN, commonly known as LoRa modulation, is based on the principle of chirp spread spectrum (CSS). While extensive research has been conducted on improving various aspects of LoRa transmitter, the design of LoRa receivers that can operate under practical conditions of timing and frequency offsets is missing. To fill this gap, this paper develops and presents detailed designs of timing, frequency and phase synchronization circuits for both non-coherent and coherent detection of CSS signals. More importantly, the proposed receiver can be used to detect the recently proposed CSS-based modulation that embeds extra information bits in the starting phases of conventional CSS symbols. Such a transmission scheme, referred to as phase-shift keying CSS (PSK-CSS) helps to improve the transmission rates of the conventional CSS system. In particular, it is shown that the bit error rate performance of the PSK-CSS scheme achieved with the proposed practical coherent receiver has only 0.25 dB gaps as compared to the ideal co-coherent receiver.
Hierarchical entropy and domain interaction to understand the structure in an image
Apr 20, 2021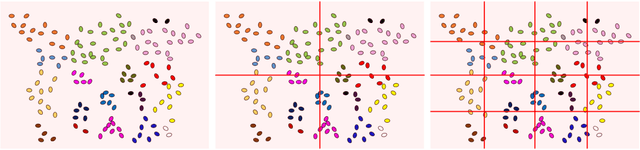
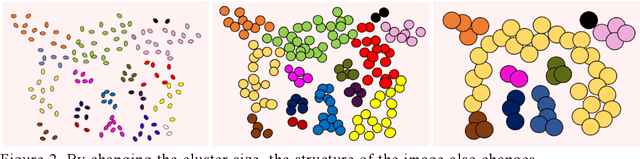
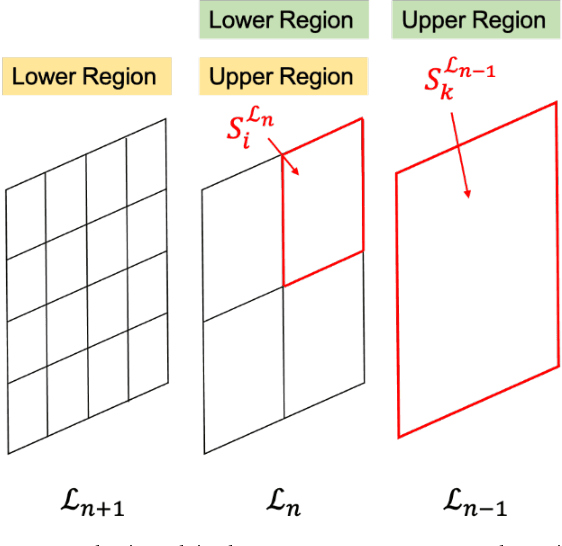
In this study, we devise a model that introduces two hierarchies into information entropy. The two hierarchies are the size of the region for which entropy is calculated and the size of the component that determines whether the structures in the image are integrated or not. And this model uses two indicators, hierarchical entropy and domain interaction. Both indicators increase or decrease due to the integration or fragmentation of the structure in the image. It aims to help people interpret and explain what the structure in an image looks like from two indicators that change with the size of the region and the component. First, we conduct experiments using images and qualitatively evaluate how the two indicators change. Next, we explain the relationship with the hidden structure of Vermeer's girl with a pearl earring using the change of hierarchical entropy. Finally, we clarify the relationship between the change of domain interaction and the appropriate segment result of the image by an experiment using a questionnaire.
Effect of Post-processing on Contextualized Word Representations
Apr 15, 2021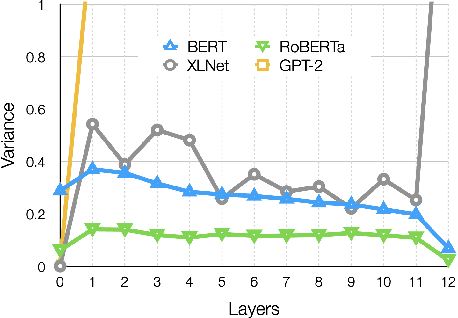
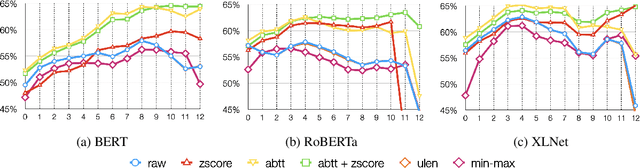
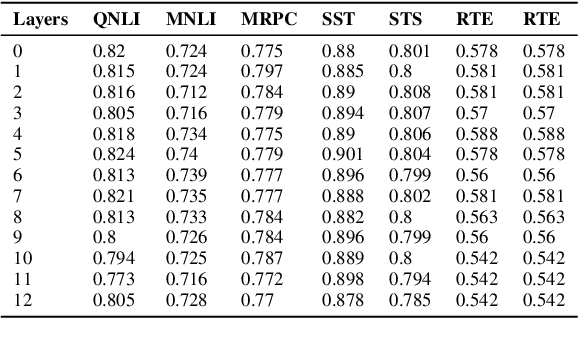
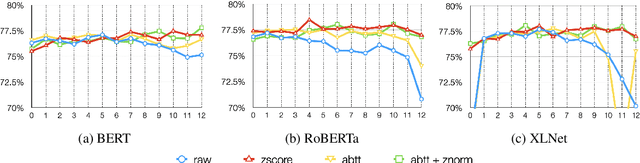
Post-processing of static embedding has beenshown to improve their performance on both lexical and sequence-level tasks. However, post-processing for contextualized embeddings is an under-studied problem. In this work, we question the usefulness of post-processing for contextualized embeddings obtained from different layers of pre-trained language models. More specifically, we standardize individual neuron activations using z-score, min-max normalization, and by removing top principle components using the all-but-the-top method. Additionally, we apply unit length normalization to word representations. On a diverse set of pre-trained models, we show that post-processing unwraps vital information present in the representations for both lexical tasks (such as word similarity and analogy)and sequence classification tasks. Our findings raise interesting points in relation to theresearch studies that use contextualized representations, and suggest z-score normalization as an essential step to consider when using them in an application.
Unified Conversational Recommendation Policy Learning via Graph-based Reinforcement Learning
May 20, 2021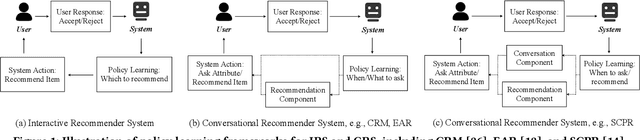
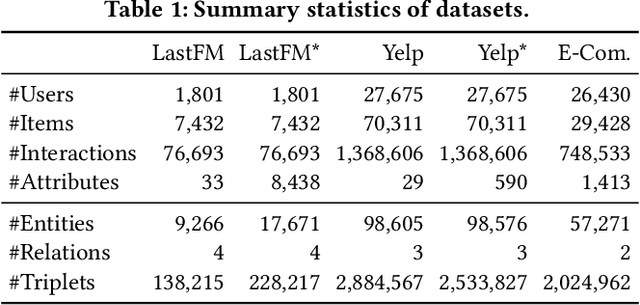
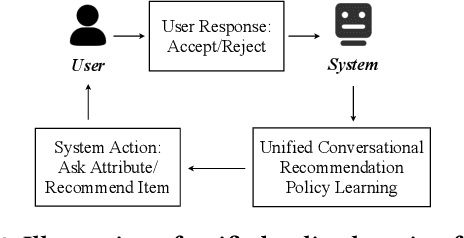
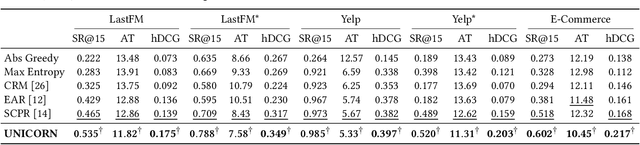
Conversational recommender systems (CRS) enable the traditional recommender systems to explicitly acquire user preferences towards items and attributes through interactive conversations. Reinforcement learning (RL) is widely adopted to learn conversational recommendation policies to decide what attributes to ask, which items to recommend, and when to ask or recommend, at each conversation turn. However, existing methods mainly target at solving one or two of these three decision-making problems in CRS with separated conversation and recommendation components, which restrict the scalability and generality of CRS and fall short of preserving a stable training procedure. In the light of these challenges, we propose to formulate these three decision-making problems in CRS as a unified policy learning task. In order to systematically integrate conversation and recommendation components, we develop a dynamic weighted graph based RL method to learn a policy to select the action at each conversation turn, either asking an attribute or recommending items. Further, to deal with the sample efficiency issue, we propose two action selection strategies for reducing the candidate action space according to the preference and entropy information. Experimental results on two benchmark CRS datasets and a real-world E-Commerce application show that the proposed method not only significantly outperforms state-of-the-art methods but also enhances the scalability and stability of CRS.