 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SMASH: a Semantic-enabled Multi-agent Approach for Self-adaptation of Human-centered IoT
May 31, 2021

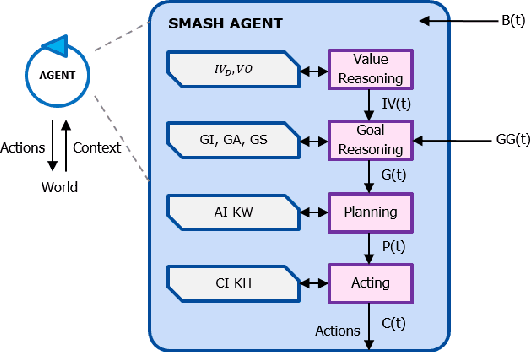
Nowadays, IoT devices have an enlarging scope of activities spanning from sensing, computing to acting and even more, learning, reasoning and planning. As the number of IoT applications increases, these objects are becoming more and more ubiquitous. Therefore, they need to adapt their functionality in response to the uncertainties of their environment to achieve their goals. In Human-centered IoT, objects and devices have direct interactions with human beings and have access to online contextual information. Self-adaptation of such applications is a crucial subject that needs to be addressed in a way that respects human goals and human values. Hence, IoT applications must be equipped with self-adaptation techniques to manage their run-time uncertainties locally or in cooperation with each other. This paper presents SMASH: a multi-agent approach for self-adaptation of IoT applications in human-centered environments. In this paper, we have considered the Smart Home as the case study of smart environments. SMASH agents are provided with a 4-layer architecture based on the BDI agent model that integrates human values with goal-reasoning, planning, and acting. It also takes advantage of a semantic-enabled platform called Home'In to address interoperability issues among non-identical agents and devices with heterogeneous protocols and data formats. This approach is compared with the literature and is validated by developing a scenario as the proof of concept. The timely responses of SMASH agents show the feasibility of the proposed approach in human-centered environments.
MUSE: Multi-Scale Temporal Features Evolution for Knowledge Tracing
Jan 30, 2021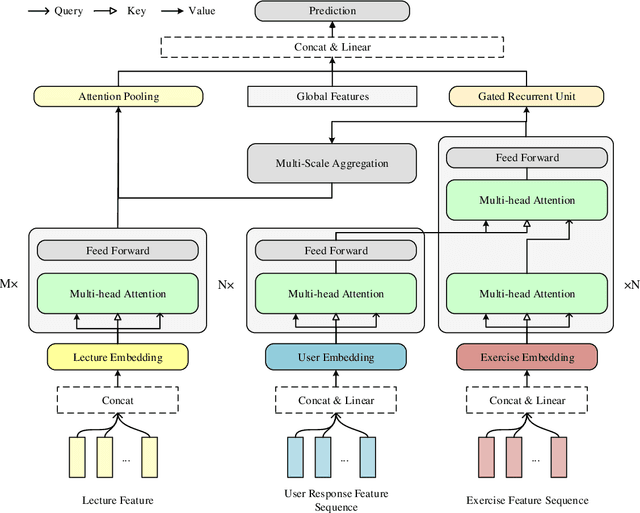
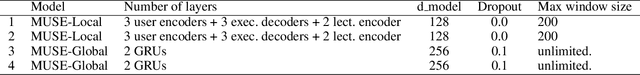
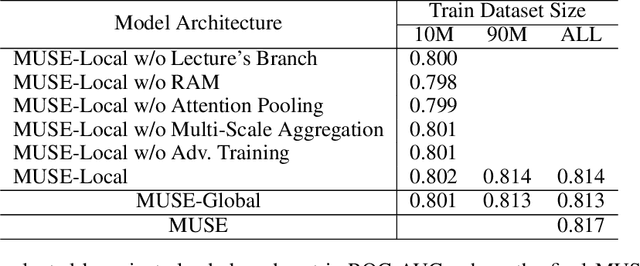
Transformer based knowledge tracing model is an extensively studied problem in the field of computer-aided education. By integrating temporal features into the encoder-decoder structure, transformers can processes the exercise information and student response information in a natural way. However, current state-of-the-art transformer-based variants still share two limitations. First, extremely long temporal features cannot well handled as the complexity of self-attention mechanism is O(n2). Second, existing approaches track the knowledge drifts under fixed a window size, without considering different temporal-ranges. To conquer these problems, we propose MUSE, which is equipped with multi-scale temporal sensor unit, that takes either local or global temporal features into consideration. The proposed model is capable to capture the dynamic changes in users knowledge states at different temporal-ranges, and provides an efficient and powerful way to combine local and global features to make predictions. Our method won the 5-th place over 3,395 teams in the Riiid AIEd Challenge 2020.
Verdi: Quality Estimation and Error Detection for Bilingual
May 31, 2021
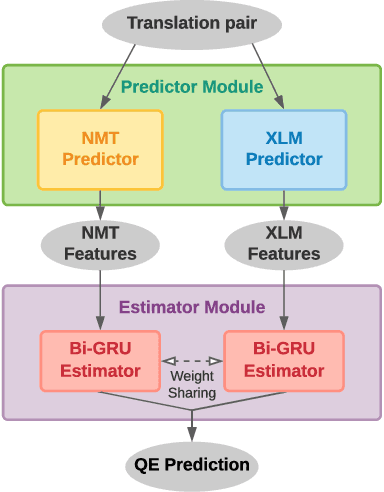
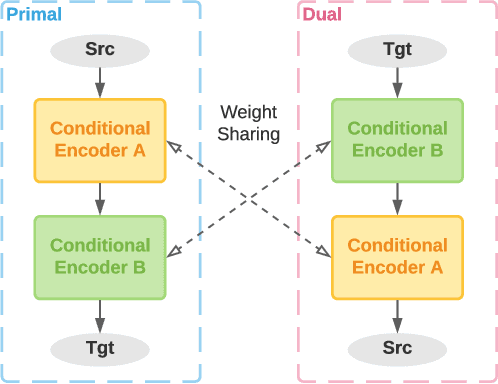

Translation Quality Estimation is critical to reducing post-editing efforts in machine translation and to cross-lingual corpus cleaning. As a research problem, quality estimation (QE) aims to directly estimate the quality of translation in a given pair of source and target sentences, and highlight the words that need corrections, without referencing to golden translations. In this paper, we propose Verdi, a novel framework for word-level and sentence-level post-editing effort estimation for bilingual corpora. Verdi adopts two word predictors to enable diverse features to be extracted from a pair of sentences for subsequent quality estimation, including a transformer-based neural machine translation (NMT) model and a pre-trained cross-lingual language model (XLM). We exploit the symmetric nature of bilingual corpora and apply model-level dual learning in the NMT predictor, which handles a primal task and a dual task simultaneously with weight sharing, leading to stronger context prediction ability than single-direction NMT models. By taking advantage of the dual learning scheme, we further design a novel feature to directly encode the translated target information without relying on the source context. Extensive experiments conducted on WMT20 QE tasks demonstrate that our method beats the winner of the competition and outperforms other baseline methods by a great margin. We further use the sentence-level scores provided by Verdi to clean a parallel corpus and observe benefits on both model performance and training efficiency.
Algorithms are not neutral: Bias in collaborative filtering
May 03, 2021Discussions of algorithmic bias tend to focus on examples where either the data or the people building the algorithms are biased. This gives the impression that clean data and good intentions could eliminate bias. The neutrality of the algorithms themselves is defended by prominent Artificial Intelligence researchers. However, algorithms are not neutral. In addition to biased data and biased algorithm makers, AI algorithms themselves can be biased. This is illustrated with the example of collaborative filtering, which is known to suffer from popularity, and homogenizing biases. Iterative information filtering algorithms in general create a selection bias in the course of learning from user responses to documents that the algorithm recommended. These are not merely biases in the statistical sense; these statistical biases can cause discriminatory outcomes. Data points on the margins of distributions of human data tend to correspond to marginalized people. Popularity and homogenizing biases have the effect of further marginalizing the already marginal. This source of bias warrants serious attention given the ubiquity of algorithmic decision-making.
Deep High-Resolution Representation Learning for Cross-Resolution Person Re-identification
May 25, 2021
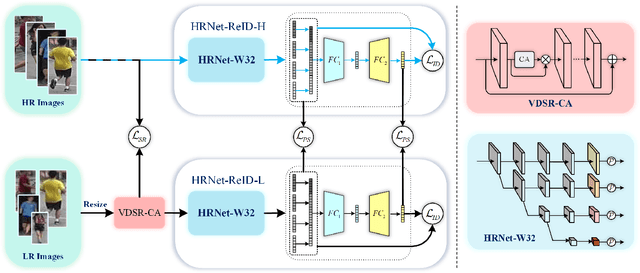
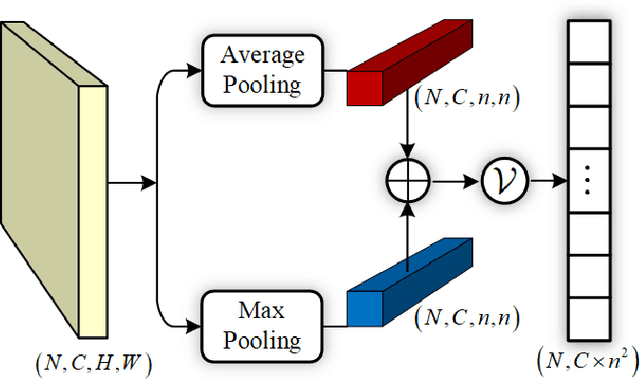
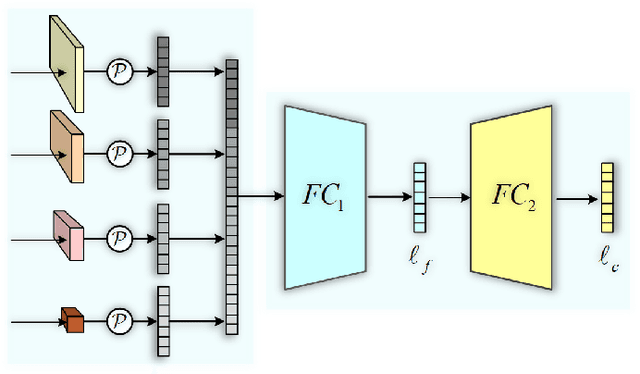
Person re-identification (re-ID) tackles the problem of matching person images with the same identity from different cameras. In practical applications, due to the differences in camera performance and distance between cameras and persons of interest, captured person images usually have various resolutions. We name this problem as Cross-Resolution Person Re-identification which brings a great challenge for matching correctly. In this paper, we propose a Deep High-Resolution Pseudo-Siamese Framework (PS-HRNet) to solve the above problem. Specifically, in order to restore the resolution of low-resolution images and make reasonable use of different channel information of feature maps, we introduce and innovate VDSR module with channel attention (CA) mechanism, named as VDSR-CA. Then we reform the HRNet by designing a novel representation head to extract discriminating features, named as HRNet-ReID. In addition, a pseudo-siamese framework is constructed to reduce the difference of feature distributions between low-resolution images and high-resolution images. The experimental results on five cross-resolution person datasets verify the effectiveness of our proposed approach. Compared with the state-of-the-art methods, our proposed PS-HRNet improves 3.4\%, 6.2\%, 2.5\%,1.1\% and 4.2\% at Rank-1 on MLR-Market-1501, MLR-CUHK03, MLR-VIPeR, MLR-DukeMTMC-reID, and CAVIAR datasets, respectively. Our code is available at \url{https://github.com/zhguoqing}.
Claim Verification using a Multi-GAN based Model
Mar 24, 2021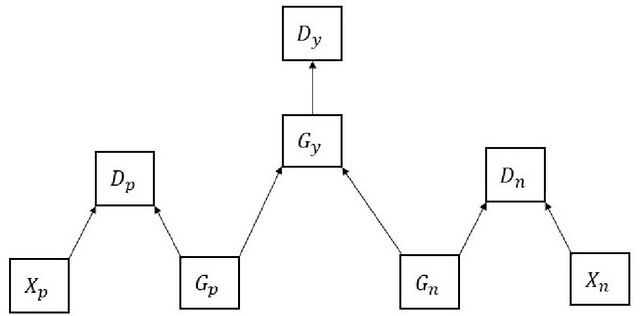
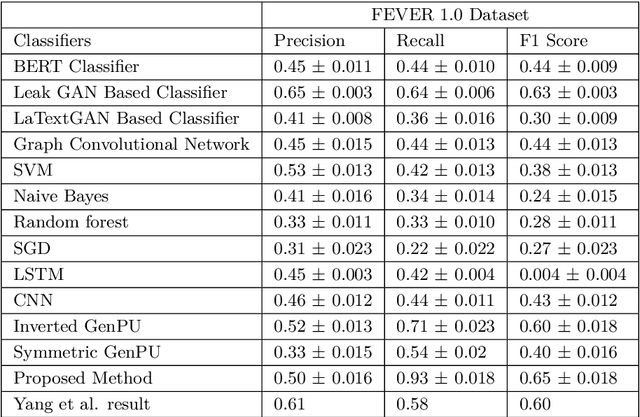
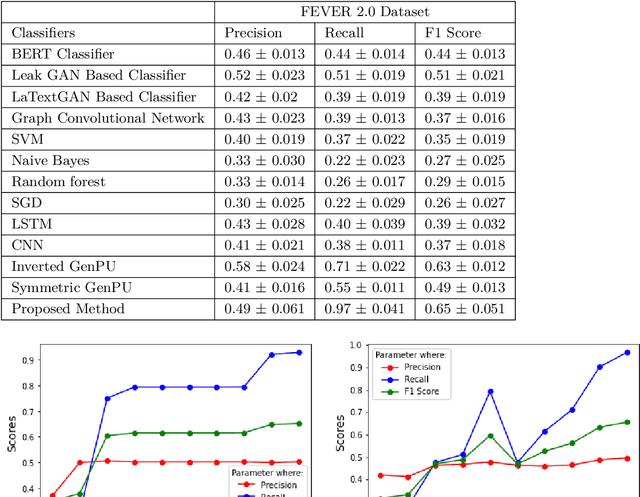
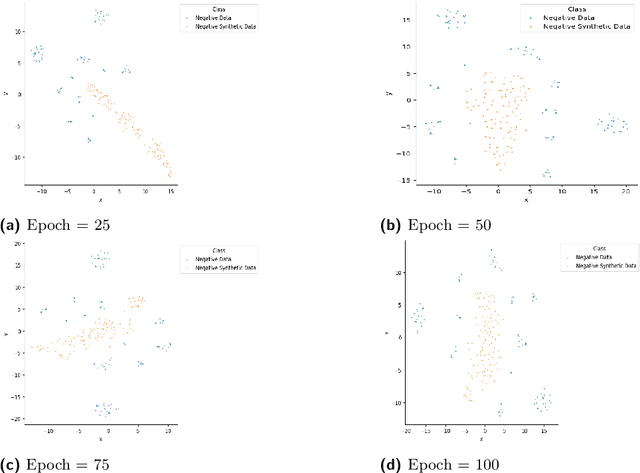
This article describes research on claim verification carried out using a multiple GAN-based model. The proposed model consists of three pairs of generators and discriminators. The generator and discriminator pairs are responsible for generating synthetic data for supported and refuted claims and claim labels. A theoretical discussion about the proposed model is provided to validate the equilibrium state of the model. The proposed model is applied to the FEVER dataset, and a pre-trained language model is used for the input text data. The synthetically generated data helps to gain information which helps the model to perform better than state of the art models and other standard classifiers.
Graph Entropy Guided Node Embedding Dimension Selection for Graph Neural Networks
May 11, 2021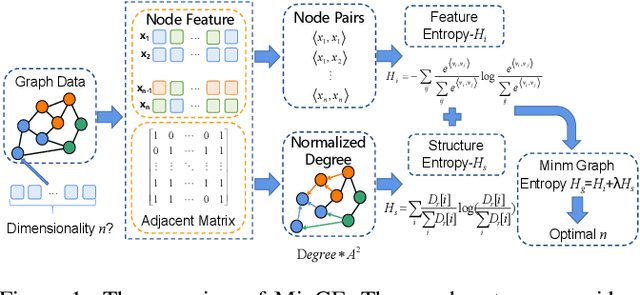
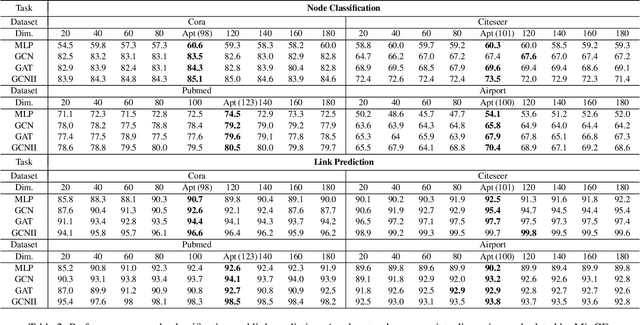
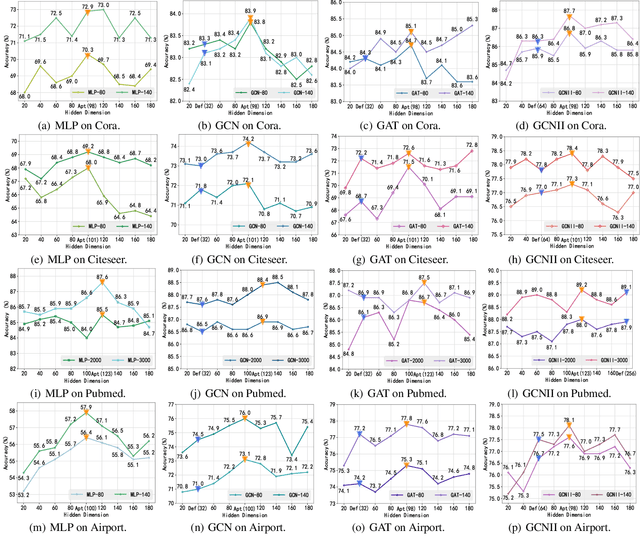
Graph representation learning has achieved great success in many areas, including e-commerce, chemistry, biology, etc. However, the fundamental problem of choosing the appropriate dimension of node embedding for a given graph still remains unsolved. The commonly used strategies for Node Embedding Dimension Selection (NEDS) based on grid search or empirical knowledge suffer from heavy computation and poor model performance. In this paper, we revisit NEDS from the perspective of minimum entropy principle. Subsequently, we propose a novel Minimum Graph Entropy (MinGE) algorithm for NEDS with graph data. To be specific, MinGE considers both feature entropy and structure entropy on graphs, which are carefully designed according to the characteristics of the rich information in them. The feature entropy, which assumes the embeddings of adjacent nodes to be more similar, connects node features and link topology on graphs. The structure entropy takes the normalized degree as basic unit to further measure the higher-order structure of graphs. Based on them, we design MinGE to directly calculate the ideal node embedding dimension for any graph. Finally, comprehensive experiments with popular Graph Neural Networks (GNNs) on benchmark datasets demonstrate the effectiveness and generalizability of our proposed MinGE.
Transfer Learning for Context-Aware Question Matching in Information-seeking Conversations in E-commerce
Jun 14, 2018
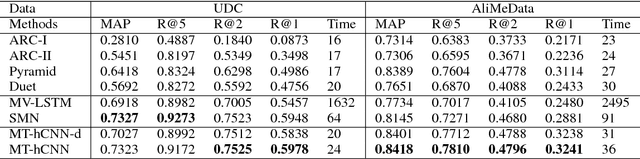


Building multi-turn information-seeking conversation systems is an important and challenging research topic. Although several advanced neural text matching models have been proposed for this task, they are generally not efficient for industrial applications. Furthermore, they rely on a large amount of labeled data, which may not be available in real-world applications. To alleviate these problems, we study transfer learning for multi-turn information seeking conversations in this paper. We first propose an efficient and effective multi-turn conversation model based on convolutional neural networks. After that, we extend our model to adapt the knowledge learned from a resource-rich domain to enhance the performance. Finally, we deployed our model in an industrial chatbot called AliMe Assist (https://consumerservice.taobao.com/online-help) and observed a significant improvement over the existing online model.
* 6
A Biomedical Information Extraction Primer for NLP Researchers
May 10, 2017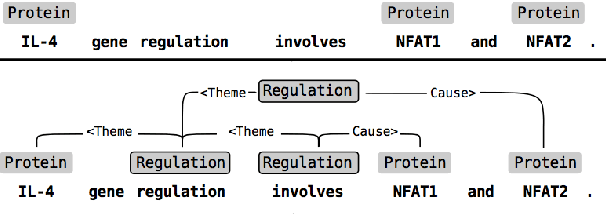
Biomedical Information Extraction is an exciting field at the crossroads of Natural Language Processing, Biology and Medicine. It encompasses a variety of different tasks that require application of state-of-the-art NLP techniques, such as NER and Relation Extraction. This paper provides an overview of the problems in the field and discusses some of the techniques used for solving them.
Transfer Learning for Node Regression Applied to Spreading Prediction
May 03, 2021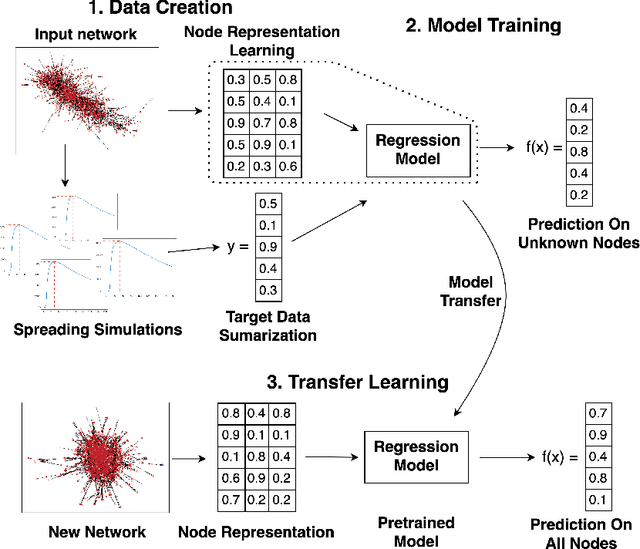

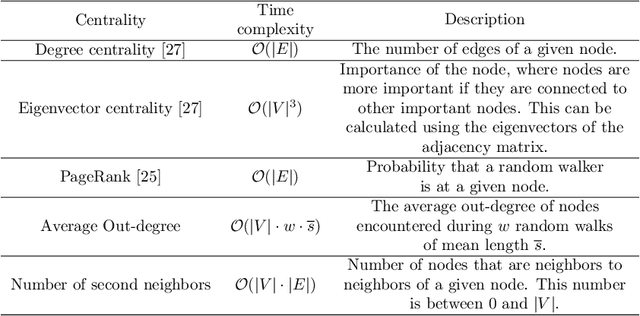
Understanding how information propagates in real-life complex networks yields a better understanding of dynamic processes such as misinformation or epidemic spreading. The recently introduced branch of machine learning methods for learning node representations offers many novel applications, one of them being the task of spreading prediction addressed in this paper. We explore the utility of the state-of-the-art node representation learners when used to assess the effects of spreading from a given node, estimated via extensive simulations. Further, as many real-life networks are topologically similar, we systematically investigate whether the learned models generalize to previously unseen networks, showing that in some cases very good model transfer can be obtained. This work is one of the first to explore transferability of the learned representations for the task of node regression; we show there exist pairs of networks with similar structure between which the trained models can be transferred (zero-shot), and demonstrate their competitive performance. To our knowledge, this is one of the first attempts to evaluate the utility of zero-shot transfer for the task of node regression.