 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Synthesis and Parameter-Efficient Fine-Tuning for Low-Resource NMT: A Case Study on Q'eqchi' Mayan
Jun 08, 2026Neural machine translation for digitally low-resource Indigenous languages is often hindered by extreme data scarcity, prompting reliance on extractive web-scraping. To ensure data sovereignty, this study introduces a data synthesis methodology to bootstrap NMT models without scraping target-language parallel text. Focusing on Q'eqchi' Mayan, we transformed community-sourced dictionaries into a massive synthetic corpus, utilizing Parameter-Efficient Fine-Tuning (PEFT) via LoRA adapters on an mT5-base model. In-domain evaluation demonstrates high structural acquisition (BLEU 42.02), proving that synthetic constraints effectively teach complex agglutinative morphology and VOS word order. However, evaluation against an organic glossary reveals a structural-semantic gap (BLEU 0.59), where the model maintains grammatical integrity but lacks the lexical grounding of natural language. The model exhibits overfitting to the constrained structural variance of the synthetic templates; despite high semantic entropy in the pipeline, it struggles with the syntactic fluidity of natural language, forcing organic inputs into rigid learned patterns. Furthermore, an ablation study utilizing a Multi-Task Learning architecture resulted in negative transfer, suggesting that auxiliary tasks competed for limited parameter capacity within the LoRA adapters, causing over-optimization for synthetic markers at the expense of organic flexibility. Ultimately, we establish that synthetic bootstrapping is a highly effective structural primer, but requires authentic data for semantic refinement via Curriculum Learning.
Dead Weights, Live Signals: Feedforward Graphs of Frozen Language Models
Apr 09, 2026We present a feedforward graph architecture in which heterogeneous frozen large language models serve as computational nodes, communicating through a shared continuous latent space via learned linear projections. Building on recent work demonstrating geometric compatibility between independently trained LLM latent spaces~\cite{armstrong2026thinking}, we extend this finding from static two-model steering to end-to-end trainable multi-node graphs, where projection matrices are optimized jointly via backpropagation through residual stream injection hooks. Three small frozen models (Llama-3.2-1B, Qwen2.5-1.5B, Gemma-2-2B) encode the input into a shared latent space whose aggregate signal is injected into two larger frozen models (Phi-3-mini, Mistral-7B), whose representations feed a lightweight cross-attention output node. With only 17.6M trainable parameters against approximately 12B frozen, the architecture achieves 87.3\% on ARC-Challenge, 82.8\% on OpenBookQA, and 67.2\% on MMLU, outperforming the best single constituent model by 11.4, 6.2, and 1.2 percentage points respectively, and outperforming parameter-matched learned classifiers on frozen single models by 9.1, 5.2, and 6.7 points. Gradient flow through multiple frozen model boundaries is empirically verified to be tractable, and the output node develops selective routing behavior across layer-2 nodes without explicit supervision.
Thinking in Different Spaces: Domain-Specific Latent Geometry Survives Cross-Architecture Translation
Mar 20, 2026We investigate whether independently trained language models converge to geometrically compatible latent representations, and whether this compatibility can be exploited to correct model behavior at inference time without any weight updates. We learn a linear projection matrix that maps activation vectors from a large teacher model into the coordinate system of a smaller student model, then intervene on the student's residual stream during generation by substituting its internal state with the translated teacher representation. Across a fully crossed experimental matrix of 20 heterogeneous teacher-student pairings spanning mixture-of-experts, dense, code-specialized, and synthetically trained architectures, the Ridge projection consistently achieves R^2 = 0.50 on verbal reasoning and R^2 = 0.40 on mathematical reasoning, collapsing to R^2 = -0.22 under permutation control and R^2 = 0.01 under L_1 regularization. Behavioral correction rates range from 14.0% to 50.0% on TruthfulQA (mean 25.2%) and from 8.5% to 43.3% on GSM8K arithmetic reasoning (mean 25.5%), demonstrating that the method generalizes across fundamentally different reasoning domains. We report a near-zero correlation between geometric alignment quality and behavioral correction rate (r = -0.07), revealing a dissociation between representation space fidelity and output space impact. Intervention strength is architecture-specific: student models exhibit characteristic sensitivity profiles that invert across domains, with the most steerable verbal student becoming the least steerable mathematical student. Finally, a double dissociation experiment conducted across all 20 model pairings confirms without exception that projection matrices collapse catastrophically when transferred across reasoning domains (mean R^2 = -3.83 in both transfer directions), establishing domain-specific subspace geometry as a universal property of LMs.
Say Anything but This: When Tokenizer Betrays Reasoning in LLMs
Jan 21, 2026Large language models (LLMs) reason over discrete token ID sequences, yet modern subword tokenizers routinely produce non-unique encodings: multiple token ID sequences can detokenize to identical surface strings. This representational mismatch creates an unmeasured fragility wherein reasoning processes can fail. LLMs may treat two internal representations as distinct "words" even when they are semantically identical at the text level. In this work, we show that tokenization can betray LLM reasoning through one-to-many token ID mappings. We introduce a tokenization-consistency probe that requires models to replace designated target words in context while leaving all other content unchanged. The task is intentionally simple at the surface level, enabling us to attribute failures to tokenizer-detokenizer artifacts rather than to knowledge gaps or parameter limitations. Through analysis of over 11000 replacement trials across state-of-the-art open-source LLMs, we find a non-trivial rate of outputs exhibit phantom edits: cases where models operate under the illusion of correct reasoning, a phenomenon arising from tokenizer-induced representational defects. We further analyze these cases and provide a taxonomy of eight systematic tokenizer artifacts, including whitespace-boundary shifts and intra-word resegmentation. These findings indicate that part of apparent reasoning deficiency originates in the tokenizer layer, motivating tokenizer-level remedies before incurring the cost of training ever-larger models on ever-larger corpora.
ESPERANTO: Evaluating Synthesized Phrases to Enhance Robustness in AI Detection for Text Origination
Sep 22, 2024



While large language models (LLMs) exhibit significant utility across various domains, they simultaneously are susceptible to exploitation for unethical purposes, including academic misconduct and dissemination of misinformation. Consequently, AI-generated text detection systems have emerged as a countermeasure. However, these detection mechanisms demonstrate vulnerability to evasion techniques and lack robustness against textual manipulations. This paper introduces back-translation as a novel technique for evading detection, underscoring the need to enhance the robustness of current detection systems. The proposed method involves translating AI-generated text through multiple languages before back-translating to English. We present a model that combines these back-translated texts to produce a manipulated version of the original AI-generated text. Our findings demonstrate that the manipulated text retains the original semantics while significantly reducing the true positive rate (TPR) of existing detection methods. We evaluate this technique on nine AI detectors, including six open-source and three proprietary systems, revealing their susceptibility to back-translation manipulation. In response to the identified shortcomings of existing AI text detectors, we present a countermeasure to improve the robustness against this form of manipulation. Our results indicate that the TPR of the proposed method declines by only 1.85% after back-translation manipulation. Furthermore, we build a large dataset of 720k texts using eight different LLMs. Our dataset contains both human-authored and LLM-generated texts in various domains and writing styles to assess the performance of our method and existing detectors. This dataset is publicly shared for the benefit of the research community.
Seeing Through AI's Lens: Enhancing Human Skepticism Towards LLM-Generated Fake News
Jun 20, 2024



LLMs offer valuable capabilities, yet they can be utilized by malicious users to disseminate deceptive information and generate fake news. The growing prevalence of LLMs poses difficulties in crafting detection approaches that remain effective across various text domains. Additionally, the absence of precautionary measures for AI-generated news on online social platforms is concerning. Therefore, there is an urgent need to improve people's ability to differentiate between news articles written by humans and those produced by LLMs. By providing cues in human-written and LLM-generated news, we can help individuals increase their skepticism towards fake LLM-generated news. This paper aims to elucidate simple markers that help individuals distinguish between articles penned by humans and those created by LLMs. To achieve this, we initially collected a dataset comprising 39k news articles authored by humans or generated by four distinct LLMs with varying degrees of fake. We then devise a metric named Entropy-Shift Authorship Signature (ESAS) based on the information theory and entropy principles. The proposed ESAS ranks terms or entities, like POS tagging, within news articles based on their relevance in discerning article authorship. We demonstrate the effectiveness of our metric by showing the high accuracy attained by a basic method, i.e., TF-IDF combined with logistic regression classifier, using a small set of terms with the highest ESAS score. Consequently, we introduce and scrutinize these top ESAS-ranked terms to aid individuals in strengthening their skepticism towards LLM-generated fake news.
The Looming Threat of Fake and LLM-generated LinkedIn Profiles: Challenges and Opportunities for Detection and Prevention
Jul 21, 2023



In this paper, we present a novel method for detecting fake and Large Language Model (LLM)-generated profiles in the LinkedIn Online Social Network immediately upon registration and before establishing connections. Early fake profile identification is crucial to maintaining the platform's integrity since it prevents imposters from acquiring the private and sensitive information of legitimate users and from gaining an opportunity to increase their credibility for future phishing and scamming activities. This work uses textual information provided in LinkedIn profiles and introduces the Section and Subsection Tag Embedding (SSTE) method to enhance the discriminative characteristics of these data for distinguishing between legitimate profiles and those created by imposters manually or by using an LLM. Additionally, the dearth of a large publicly available LinkedIn dataset motivated us to collect 3600 LinkedIn profiles for our research. We will release our dataset publicly for research purposes. This is, to the best of our knowledge, the first large publicly available LinkedIn dataset for fake LinkedIn account detection. Within our paradigm, we assess static and contextualized word embeddings, including GloVe, Flair, BERT, and RoBERTa. We show that the suggested method can distinguish between legitimate and fake profiles with an accuracy of about 95% across all word embeddings. In addition, we show that SSTE has a promising accuracy for identifying LLM-generated profiles, despite the fact that no LLM-generated profiles were employed during the training phase, and can achieve an accuracy of approximately 90% when only 20 LLM-generated profiles are added to the training set. It is a significant finding since the proliferation of several LLMs in the near future makes it extremely challenging to design a single system that can identify profiles created with various LLMs.
Deception Detection with Feature-Augmentation by soft Domain Transfer
May 01, 2023In this era of information explosion, deceivers use different domains or mediums of information to exploit the users, such as News, Emails, and Tweets. Although numerous research has been done to detect deception in all these domains, information shortage in a new event necessitates these domains to associate with each other to battle deception. To form this association, we propose a feature augmentation method by harnessing the intermediate layer representation of neural models. Our approaches provide an improvement over the self-domain baseline models by up to 6.60%. We find Tweets to be the most helpful information provider for Fake News and Phishing Email detection, whereas News helps most in Tweet Rumor detection. Our analysis provides a useful insight for domain knowledge transfer which can help build a stronger deception detection system than the existing literature.
Claim Verification using a Multi-GAN based Model
Mar 24, 2021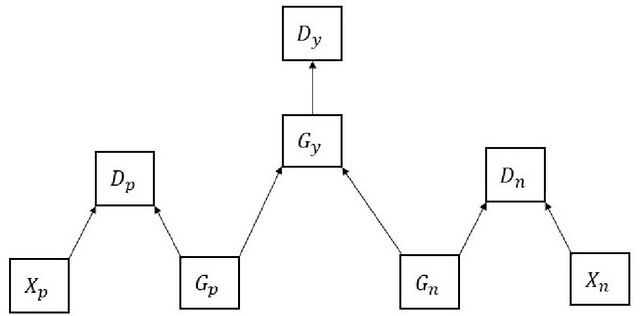
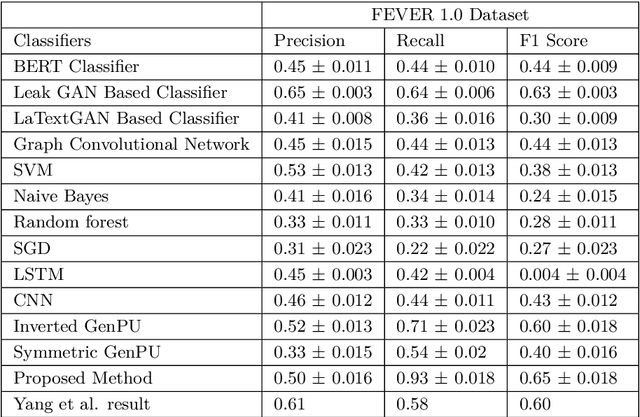
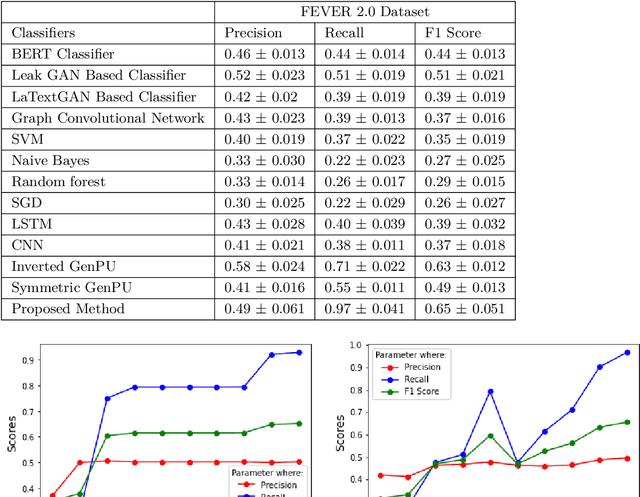
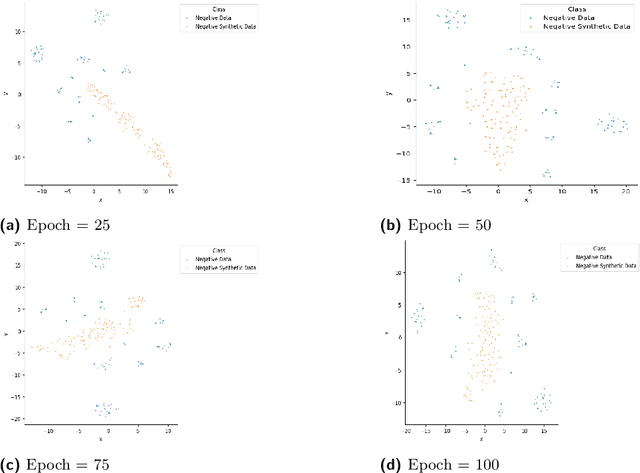
This article describes research on claim verification carried out using a multiple GAN-based model. The proposed model consists of three pairs of generators and discriminators. The generator and discriminator pairs are responsible for generating synthetic data for supported and refuted claims and claim labels. A theoretical discussion about the proposed model is provided to validate the equilibrium state of the model. The proposed model is applied to the FEVER dataset, and a pre-trained language model is used for the input text data. The synthetically generated data helps to gain information which helps the model to perform better than state of the art models and other standard classifiers.
Improving Authorship Verification using Linguistic Divergence
Mar 12, 2021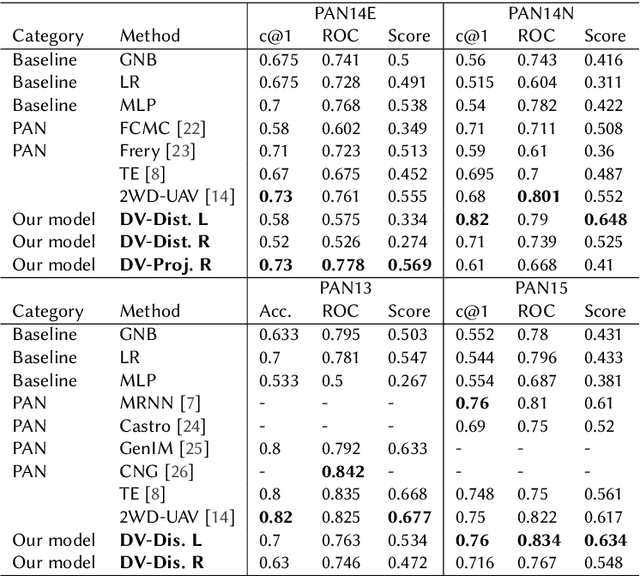
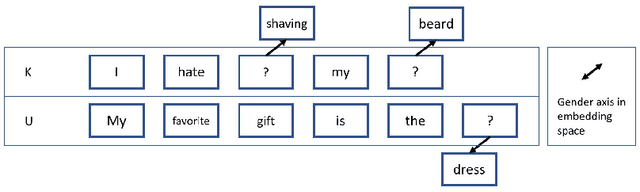
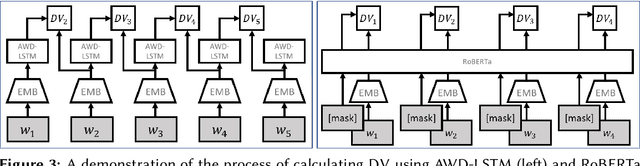
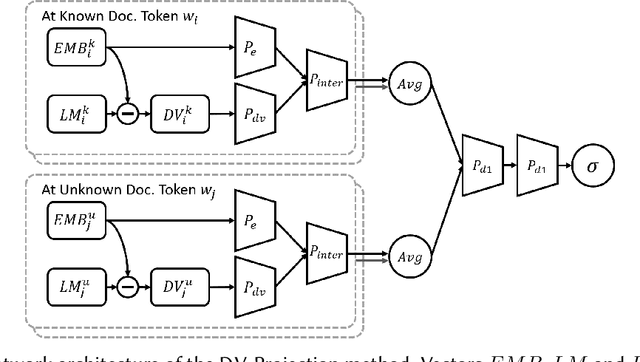
We propose an unsupervised solution to the Authorship Verification task that utilizes pre-trained deep language models to compute a new metric called DV-Distance. The proposed metric is a measure of the difference between the two authors comparing against pre-trained language models. Our design addresses the problem of non-comparability in authorship verification, frequently encountered in small or cross-domain corpora. To the best of our knowledge, this paper is the first one to introduce a method designed with non-comparability in mind from the ground up, rather than indirectly. It is also one of the first to use Deep Language Models in this setting. The approach is intuitive, and it is easy to understand and interpret through visualization. Experiments on four datasets show our methods matching or surpassing current state-of-the-art and strong baselines in most tasks.