 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On Deep Learning with Label Differential Privacy
Feb 11, 2021
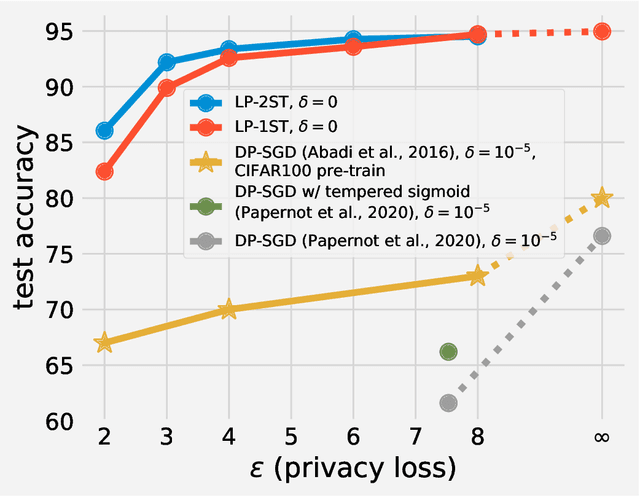
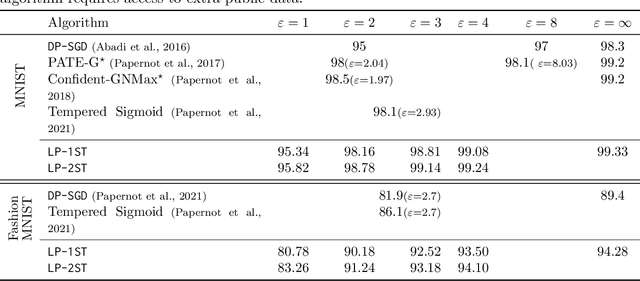

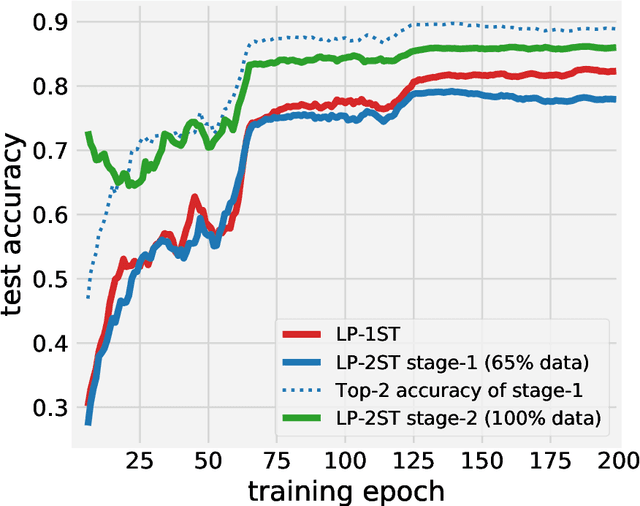
In many machine learning applications, the training data can contain highly sensitive personal information. Training large-scale deep models that are guaranteed not to leak sensitive information while not compromising their accuracy has been a significant challenge. In this work, we study the multi-class classification setting where the labels are considered sensitive and ought to be protected. We propose a new algorithm for training deep neural networks with label differential privacy, and run evaluations on several datasets. For Fashion MNIST and CIFAR-10, we demonstrate that our algorithm achieves significantly higher accuracy than the state-of-the-art, and in some regimes comes close to the non-private baselines. We also provide non-trivial training results for the the challenging CIFAR-100 dataset. We complement our algorithm with theoretical findings showing that in the setting of convex empirical risk minimization, the sample complexity of training with label differential privacy is dimension-independent, which is in contrast to vanilla differential privacy.
Marginal Utility Diminishes: Exploring the Minimum Knowledge for BERT Knowledge Distillation
Jun 10, 2021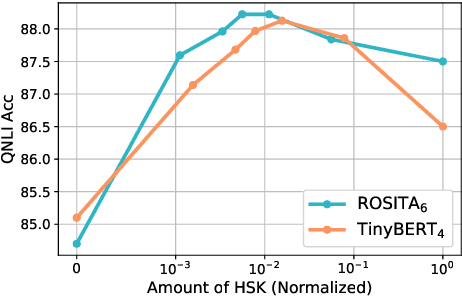

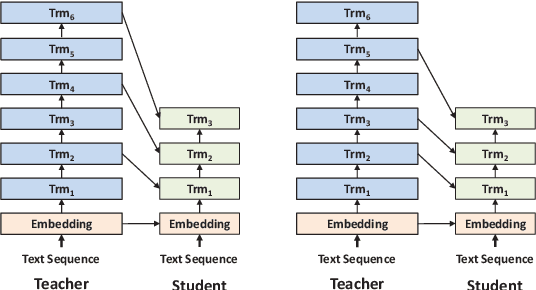
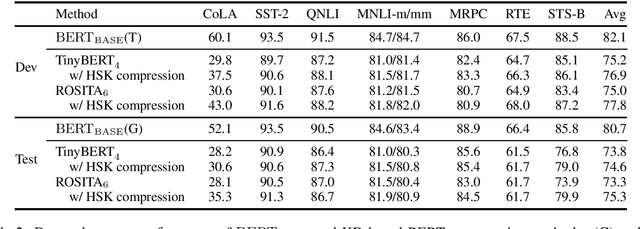
Recently, knowledge distillation (KD) has shown great success in BERT compression. Instead of only learning from the teacher's soft label as in conventional KD, researchers find that the rich information contained in the hidden layers of BERT is conducive to the student's performance. To better exploit the hidden knowledge, a common practice is to force the student to deeply mimic the teacher's hidden states of all the tokens in a layer-wise manner. In this paper, however, we observe that although distilling the teacher's hidden state knowledge (HSK) is helpful, the performance gain (marginal utility) diminishes quickly as more HSK is distilled. To understand this effect, we conduct a series of analysis. Specifically, we divide the HSK of BERT into three dimensions, namely depth, length and width. We first investigate a variety of strategies to extract crucial knowledge for each single dimension and then jointly compress the three dimensions. In this way, we show that 1) the student's performance can be improved by extracting and distilling the crucial HSK, and 2) using a tiny fraction of HSK can achieve the same performance as extensive HSK distillation. Based on the second finding, we further propose an efficient KD paradigm to compress BERT, which does not require loading the teacher during the training of student. For two kinds of student models and computing devices, the proposed KD paradigm gives rise to training speedup of 2.7x ~ 3.4x.
Byzantine-Robust and Privacy-Preserving Framework for FedML
May 05, 2021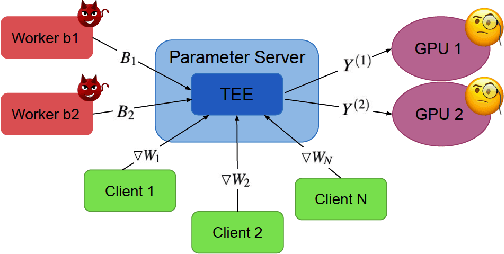
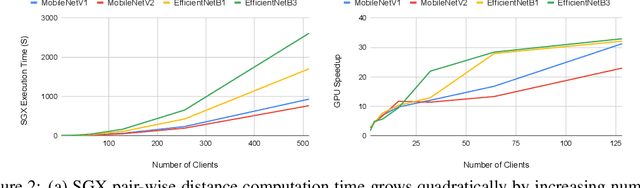
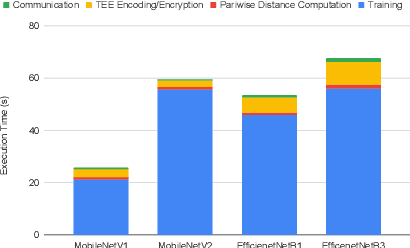
Federated learning has emerged as a popular paradigm for collaboratively training a model from data distributed among a set of clients. This learning setting presents, among others, two unique challenges: how to protect privacy of the clients' data during training, and how to ensure integrity of the trained model. We propose a two-pronged solution that aims to address both challenges under a single framework. First, we propose to create secure enclaves using a trusted execution environment (TEE) within the server. Each client can then encrypt their gradients and send them to verifiable enclaves. The gradients are decrypted within the enclave without the fear of privacy breaches. However, robustness check computations in a TEE are computationally prohibitive. Hence, in the second step, we perform a novel gradient encoding that enables TEEs to encode the gradients and then offloading Byzantine check computations to accelerators such as GPUs. Our proposed approach provides theoretical bounds on information leakage and offers a significant speed-up over the baseline in empirical evaluation.
Deep neural network loses attention to adversarial images
Jun 10, 2021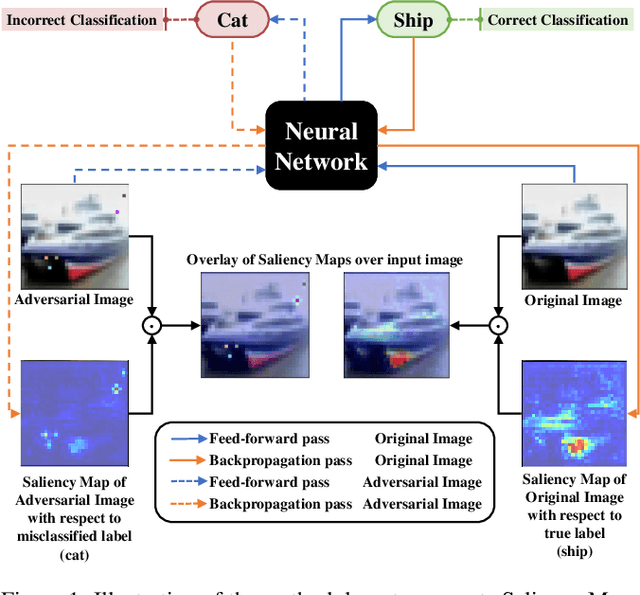



Adversarial algorithms have shown to be effective against neural networks for a variety of tasks. Some adversarial algorithms perturb all the pixels in the image minimally for the image classification task in image classification. In contrast, some algorithms perturb few pixels strongly. However, very little information is available regarding why these adversarial samples so diverse from each other exist. Recently, Vargas et al. showed that the existence of these adversarial samples might be due to conflicting saliency within the neural network. We test this hypothesis of conflicting saliency by analysing the Saliency Maps (SM) and Gradient-weighted Class Activation Maps (Grad-CAM) of original and few different types of adversarial samples. We also analyse how different adversarial samples distort the attention of the neural network compared to original samples. We show that in the case of Pixel Attack, perturbed pixels either calls the network attention to themselves or divert the attention from them. Simultaneously, the Projected Gradient Descent Attack perturbs pixels so that intermediate layers inside the neural network lose attention for the correct class. We also show that both attacks affect the saliency map and activation maps differently. Thus, shedding light on why some defences successful against some attacks remain vulnerable against other attacks. We hope that this analysis will improve understanding of the existence and the effect of adversarial samples and enable the community to develop more robust neural networks.
Polarization-driven Semantic Segmentation via Efficient Attention-bridged Fusion
Nov 26, 2020
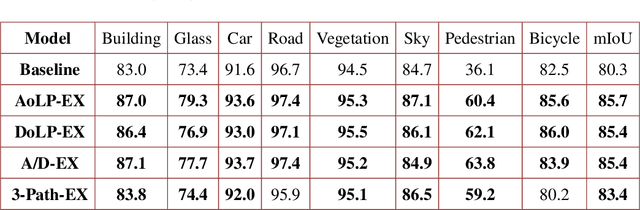

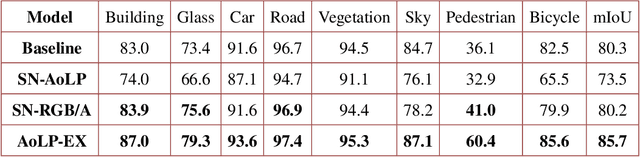
Semantic Segmentation (SS) is promising for outdoor scene perception in safety-critical applications like autonomous vehicles, assisted navigation and so on. However, traditional SS is primarily based on RGB images, which limits the reliability of SS in complex outdoor scenes, where RGB images lack necessary information dimensions to fully perceive unconstrained environments. As preliminary investigation, we examine SS in an unexpected obstacle detection scenario, which demonstrates the necessity of multimodal fusion. Thereby, in this work, we present EAFNet, an Efficient Attention-bridged Fusion Network to exploit complementary information coming from different optical sensors. Specifically, we incorporate polarization sensing to obtain supplementary information, considering its optical characteristics for robust representation of diverse materials. By using a single-shot polarization sensor, we build the first RGB-P dataset which consists of 394 annotated pixel-aligned RGB-Polarization images. A comprehensive variety of experiments shows the effectiveness of EAFNet to fuse polarization and RGB information, as well as the flexibility to be adapted to other sensor combination scenarios.
Interpretation of multi-label classification models using shapley values
Apr 21, 2021
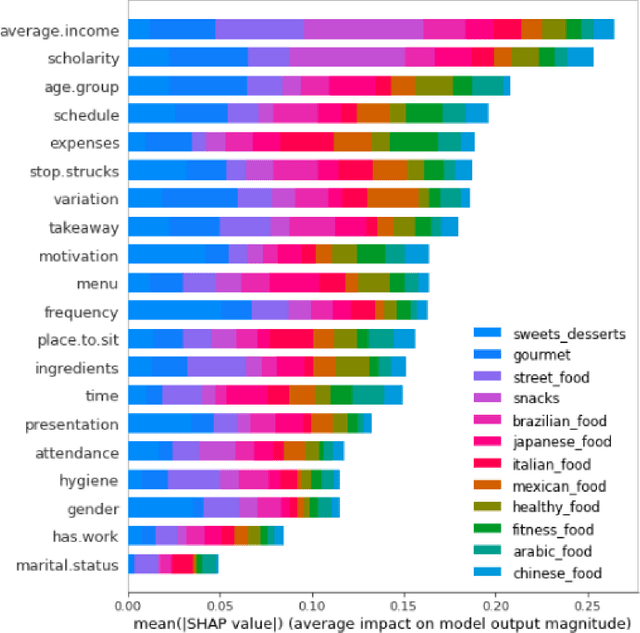
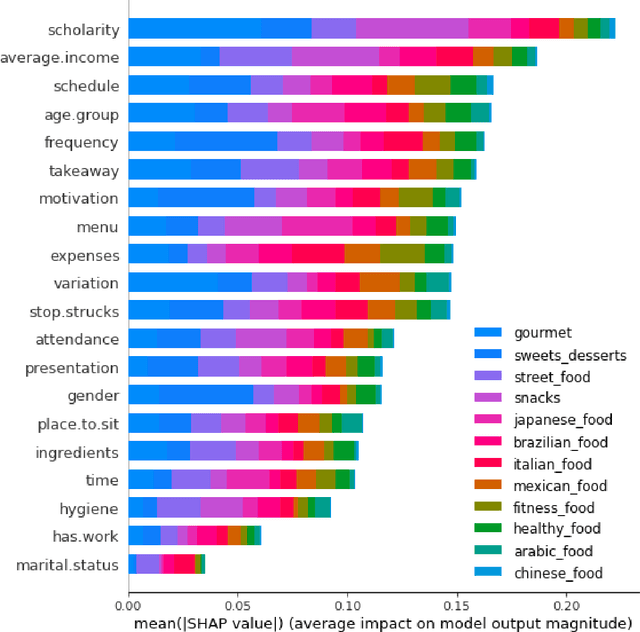
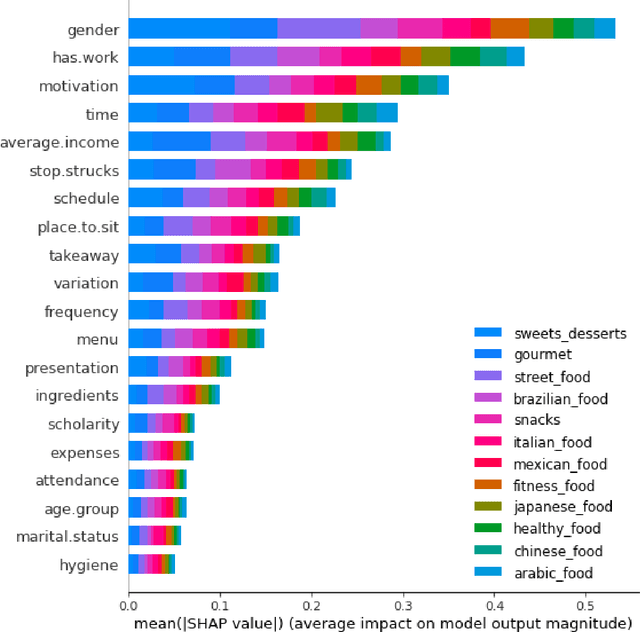
Multi-label classification is a type of classification task, it is used when there are two or more classes, and the data point we want to predict may belong to none of the classes or all of them at the same time. In the real world, many applications are actually multi-label involved, including information retrieval, multimedia content annotation, web mining, and so on. A game theory-based framework known as SHapley Additive exPlanations (SHAP) has been applied to explain various supervised learning models without being aware of the exact model. Herein, this work further extends the explanation of multi-label classification task by using the SHAP methodology. The experiment demonstrates a comprehensive comparision of different algorithms on well known multi-label datasets and shows the usefulness of the interpretation.
Prioritized Architecture Sampling with Monto-Carlo Tree Search
Mar 22, 2021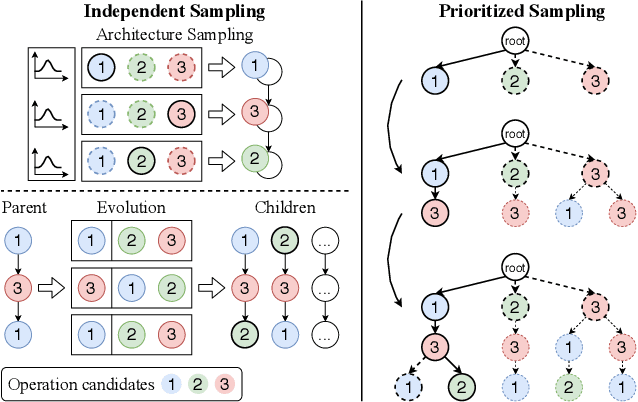
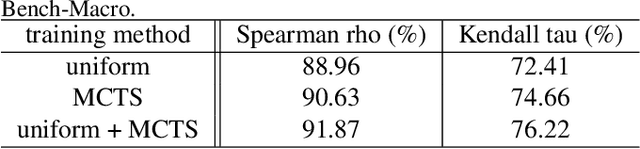
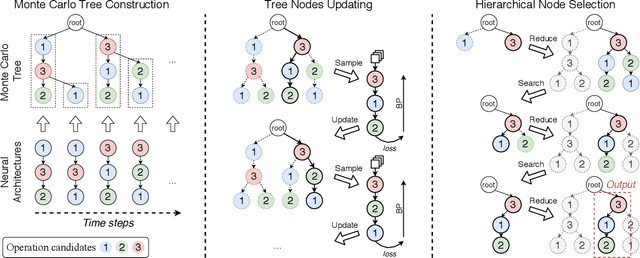
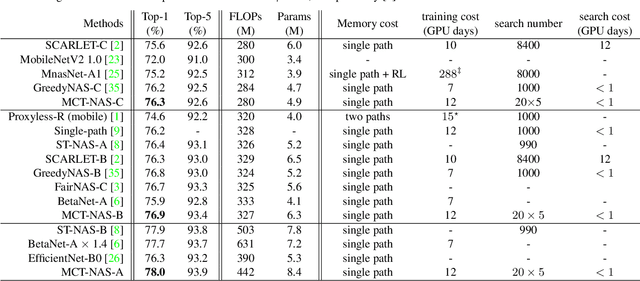
One-shot neural architecture search (NAS) methods significantly reduce the search cost by considering the whole search space as one network, which only needs to be trained once. However, current methods select each operation independently without considering previous layers. Besides, the historical information obtained with huge computation cost is usually used only once and then discarded. In this paper, we introduce a sampling strategy based on Monte Carlo tree search (MCTS) with the search space modeled as a Monte Carlo tree (MCT), which captures the dependency among layers. Furthermore, intermediate results are stored in the MCT for the future decision and a better exploration-exploitation balance. Concretely, MCT is updated using the training loss as a reward to the architecture performance; for accurately evaluating the numerous nodes, we propose node communication and hierarchical node selection methods in the training and search stages, respectively, which make better uses of the operation rewards and hierarchical information. Moreover, for a fair comparison of different NAS methods, we construct an open-source NAS benchmark of a macro search space evaluated on CIFAR-10, namely NAS-Bench-Macro. Extensive experiments on NAS-Bench-Macro and ImageNet demonstrate that our method significantly improves search efficiency and performance. For example, by only searching $20$ architectures, our obtained architecture achieves $78.0\%$ top-1 accuracy with 442M FLOPs on ImageNet. Code (Benchmark) is available at: \url{https://github.com/xiusu/NAS-Bench-Macro}.
Unsupervised Activity Segmentation by Joint Representation Learning and Online Clustering
May 28, 2021
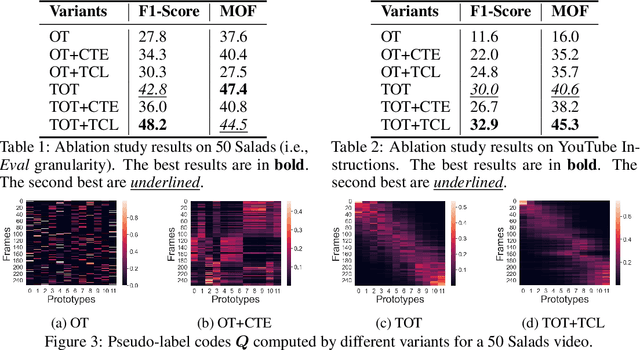
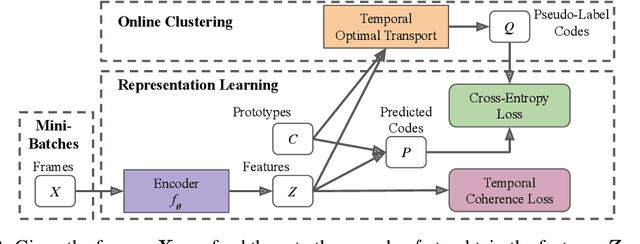
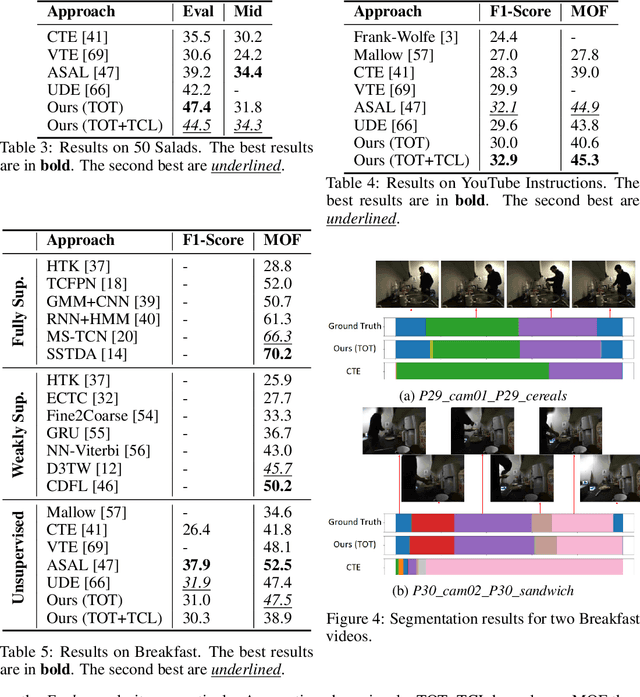
We present a novel approach for unsupervised activity segmentation, which uses video frame clustering as a pretext task and simultaneously performs representation learning and online clustering. This is in contrast with prior works where representation learning and clustering are often performed sequentially. We leverage temporal information in videos by employing temporal optimal transport and temporal coherence loss. In particular, we incorporate a temporal regularization term into the standard optimal transport module, which preserves the temporal order of the activity, yielding the temporal optimal transport module for computing pseudo-label cluster assignments. Next, the temporal coherence loss encourages neighboring video frames to be mapped to nearby points while distant video frames are mapped to farther away points in the embedding space. The combination of these two components results in effective representations for unsupervised activity segmentation. Furthermore, previous methods require storing learned features for the entire dataset before clustering them in an offline manner, whereas our approach processes one mini-batch at a time in an online manner. Extensive evaluations on three public datasets, i.e. 50-Salads, YouTube Instructions, and Breakfast, and our dataset, i.e., Desktop Assembly, show that our approach performs on par or better than previous methods for unsupervised activity segmentation, despite having significantly less memory constraints.
Automatic Pulmonary Artery and Vein Separation Algorithm Based on Multitask Classification Network and Topology Reconstruction in Chest CT Images
Mar 22, 2021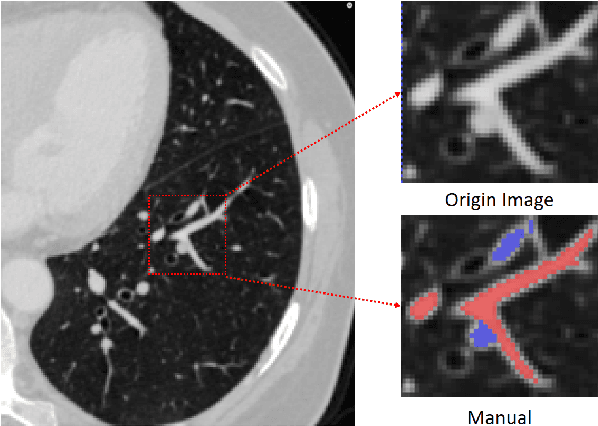
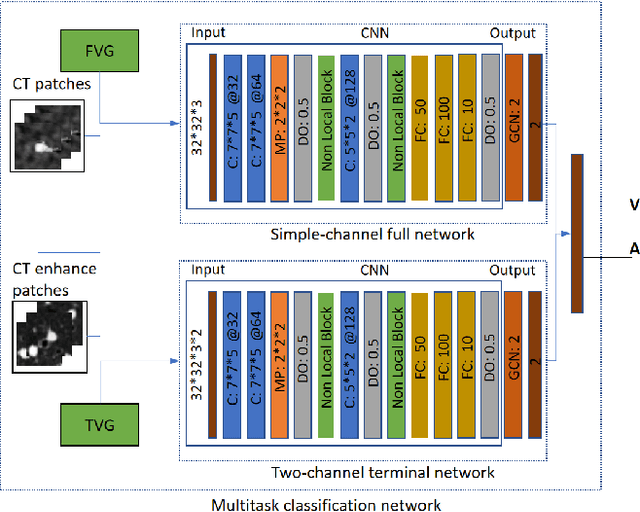
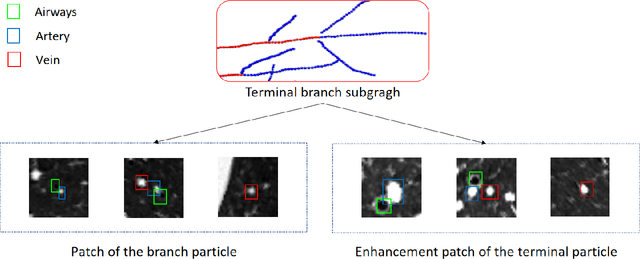
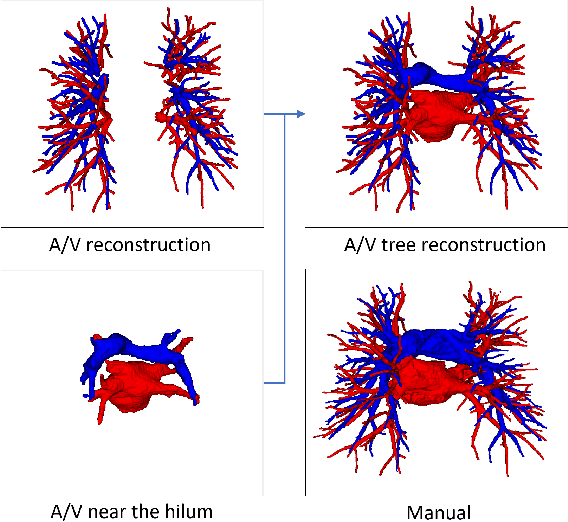
With the development of medical computer-aided diagnostic systems, pulmonary artery-vein(A/V) reconstruction plays a crucial role in assisting doctors in preoperative planning for lung cancer surgery. However, distinguishing arterial from venous irrigation in chest CT images remains a challenge due to the similarity and complex structure of the arteries and veins. We propose a novel method for automatic separation of pulmonary arteries and veins from chest CT images. The method consists of three parts. First, global connection information and local feature information are used to construct a complete topological tree and ensure the continuity of vessel reconstruction. Second, the multitask classification network proposed can automatically learn the differences between arteries and veins at different scales to reduce classification errors caused by changes in terminal vessel characteristics. Finally, the topology optimizer considers interbranch and intrabranch topological relationships to maintain spatial consistency to avoid the misclassification of A/V irrigations. We validate the performance of the method on chest CT images. Compared with manual classification, the proposed method achieves an average accuracy of 96.2% on noncontrast chest CT. In addition, the method has been proven to have good generalization, that is, the accuracies of 93.8% and 94.8% are obtained for CT scans from other devices and other modes, respectively. The result of pulmonary artery-vein reconstruction obtained by the proposed method can provide better assistance for preoperative planning of lung cancer surgery.
Word-level Text Highlighting of Medical Texts forTelehealth Services
May 21, 2021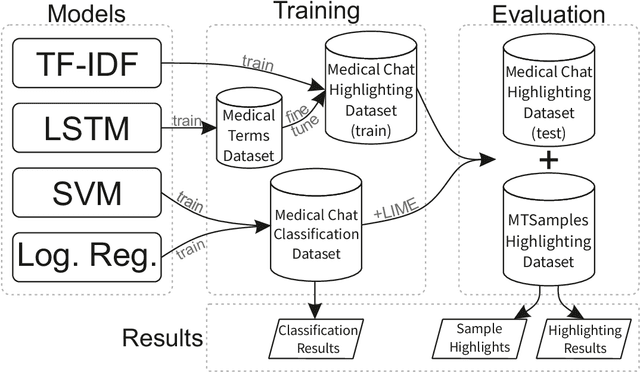
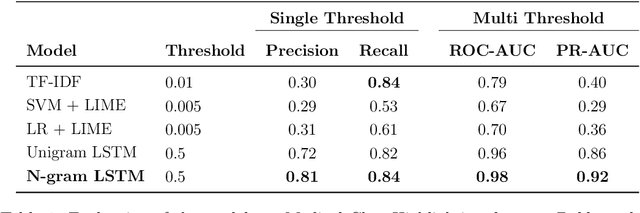

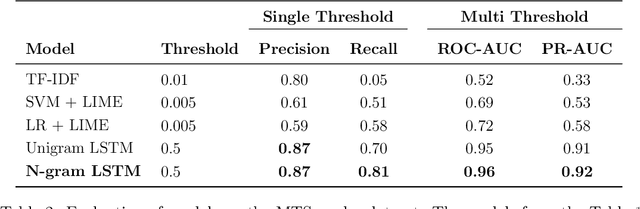
The medical domain is often subject to information overload. The digitization of healthcare, constant updates to online medical repositories, and increasing availability of biomedical datasets make it challenging to effectively analyze the data. This creates additional work for medical professionals who are heavily dependent on medical data to complete their research and consult their patients. This paper aims to show how different text highlighting techniques can capture relevant medical context. This would reduce the doctors' cognitive load and response time to patients by facilitating them in making faster decisions, thus improving the overall quality of online medical services. Three different word-level text highlighting methodologies are implemented and evaluated. The first method uses TF-IDF scores directly to highlight important parts of the text. The second method is a combination of TF-IDF scores and the application of Local Interpretable Model-Agnostic Explanations to classification models. The third method uses neural networks directly to make predictions on whether or not a word should be highlighted. The results of our experiments show that the neural network approach is successful in highlighting medically-relevant terms and its performance is improved as the size of the input segment increases.