 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MLP-Mixer: An all-MLP Architecture for Vision
May 04, 2021
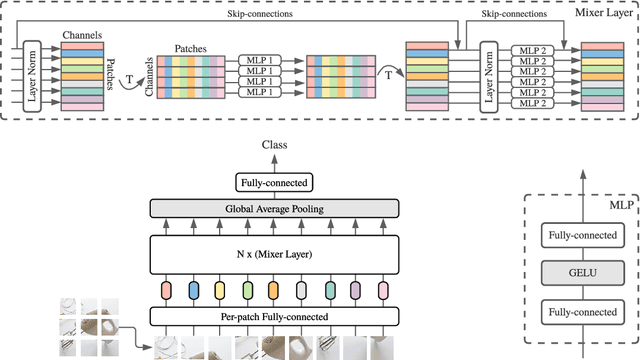
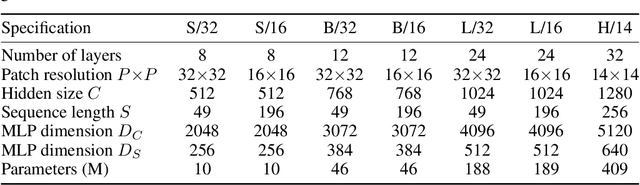
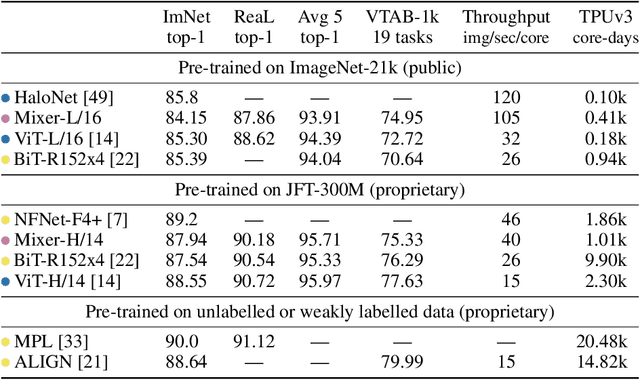
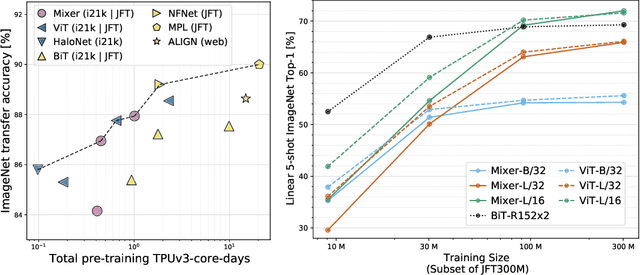
Convolutional Neural Networks (CNNs) are the go-to model for computer vision. Recently, attention-based networks, such as the Vision Transformer, have also become popular. In this paper we show that while convolutions and attention are both sufficient for good performance, neither of them are necessary. We present MLP-Mixer, an architecture based exclusively on multi-layer perceptrons (MLPs). MLP-Mixer contains two types of layers: one with MLPs applied independently to image patches (i.e. "mixing" the per-location features), and one with MLPs applied across patches (i.e. "mixing" spatial information). When trained on large datasets, or with modern regularization schemes, MLP-Mixer attains competitive scores on image classification benchmarks, with pre-training and inference cost comparable to state-of-the-art models. We hope that these results spark further research beyond the realms of well established CNNs and Transformers.
Peptipedia: a comprehensive database for peptide research supported by Assembled predictive models and Data Mining approaches
Jan 28, 2021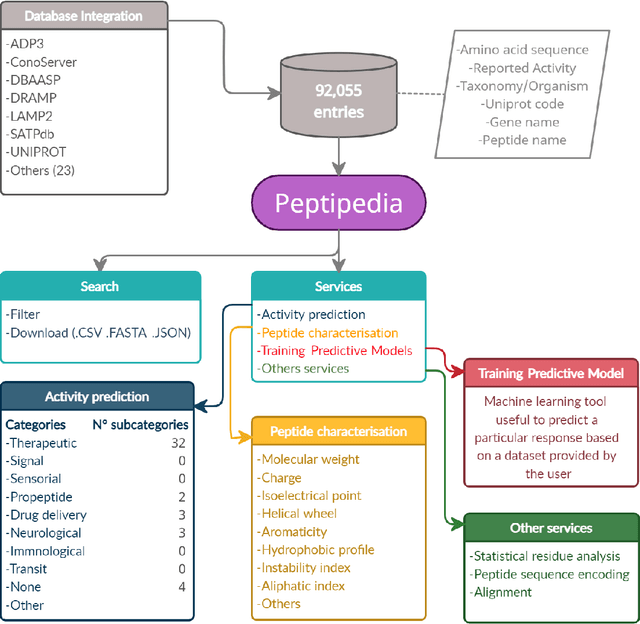
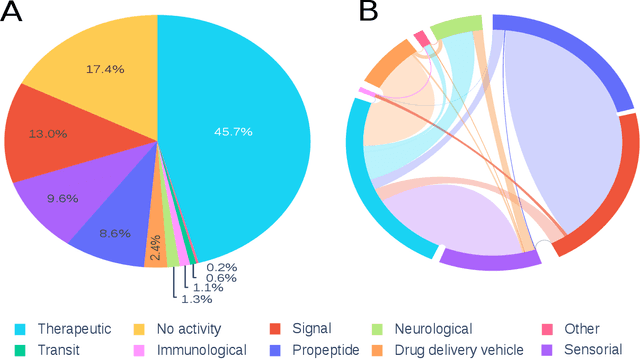
Motivation: Peptides have attracted the attention in this century due to their remarkable therapeutic properties. Computational tools are being developed to take advantage of existing information, encapsulating knowledge and making it available in a simple way for general public use. However, these are property-specific redundant data systems, and usually do not display the data in a clear way. In some cases, information download is not even possible. This data needs to be available in a simple form for drug design and other biotechnological applications. Results: We developed Peptipedia, a user-friendly database and web application to search, characterise and analyse peptide sequences. Our tool integrates the information from thirty previously reported databases, making it the largest repository of peptides with recorded activities so far. Besides, we implemented a variety of services to increase our tool's usability. The significant differences of our tools with other existing alternatives becomes a substantial contribution to develop biotechnological and bioengineering applications for peptides. Availability: Peptipedia is available for non-commercial use as an open-access software, licensed under the GNU General Public License, version GPL 3.0. The web platform is publicly available at pesb2.cl/peptipedia. Both the source code and sample datasets are available in the GitHub repository https://github.com/CristoferQ/PeptideDatabase. Contact: david.medina@cebib.cl, ana.sanchez@ing.uchile.cl
Accessing accurate documents by mining auxiliary document information
Apr 15, 2016
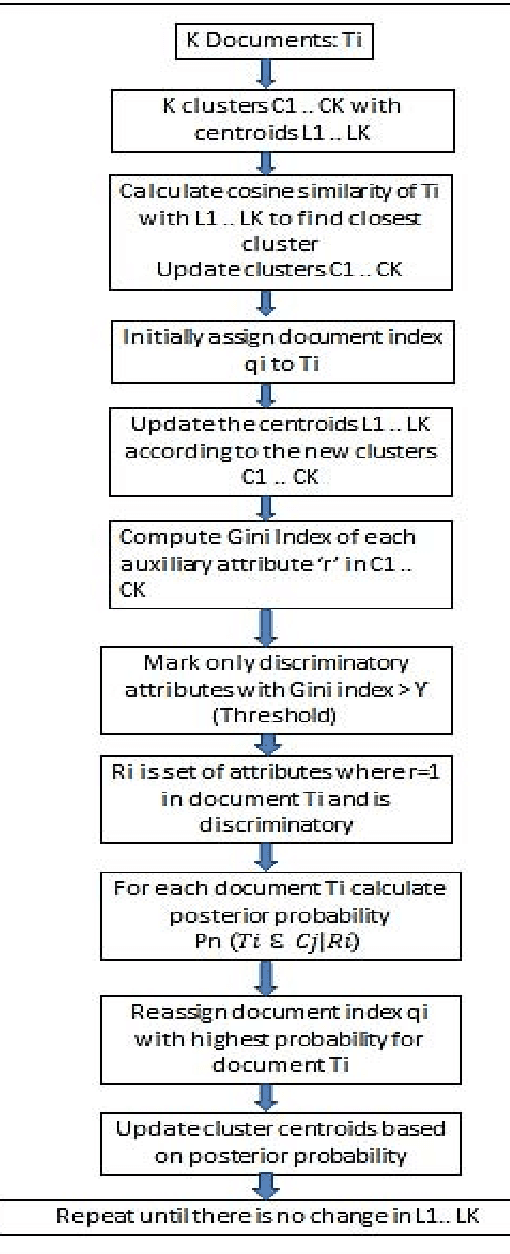
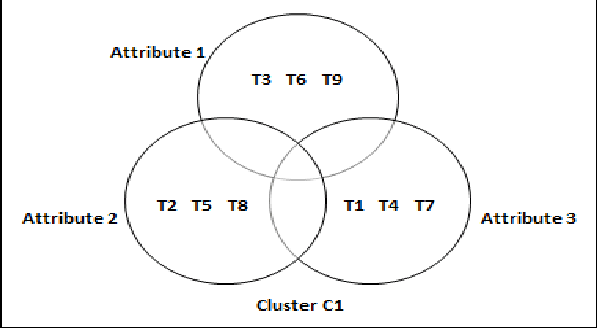
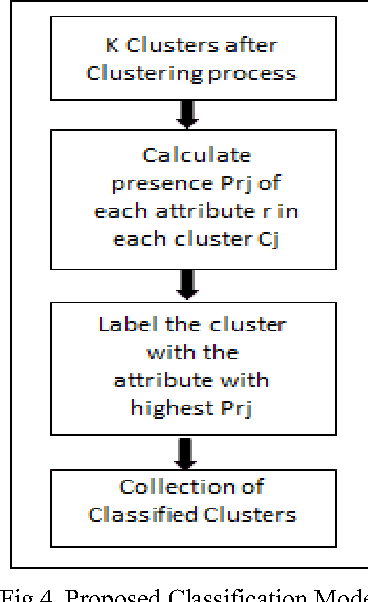
Earlier techniques of text mining included algorithms like k-means, Naive Bayes, SVM which classify and cluster the text document for mining relevant information about the documents. The need for improving the mining techniques has us searching for techniques using the available algorithms. This paper proposes one technique which uses the auxiliary information that is present inside the text documents to improve the mining. This auxiliary information can be a description to the content. This information can be either useful or completely useless for mining. The user should assess the worth of the auxiliary information before considering this technique for text mining. In this paper, a combination of classical clustering algorithms is used to mine the datasets. The algorithm runs in two stages which carry out mining at different levels of abstraction. The clustered documents would then be classified based on the necessary groups. The proposed technique is aimed at improved results of document clustering.
Entity Recognition and Relation Extraction from Scientific and Technical Texts in Russian
Dec 14, 2020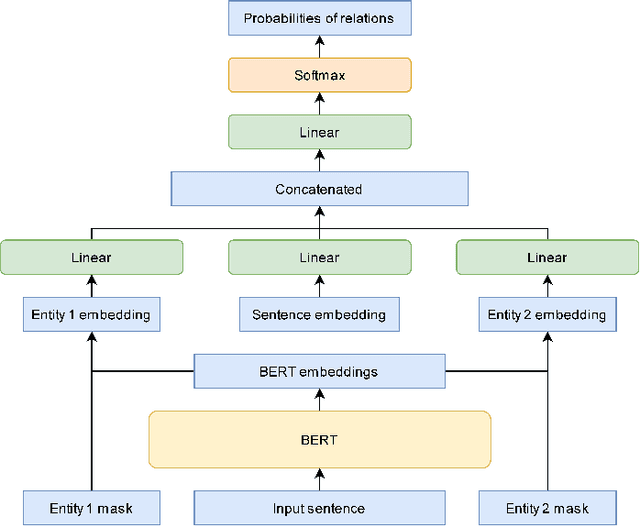
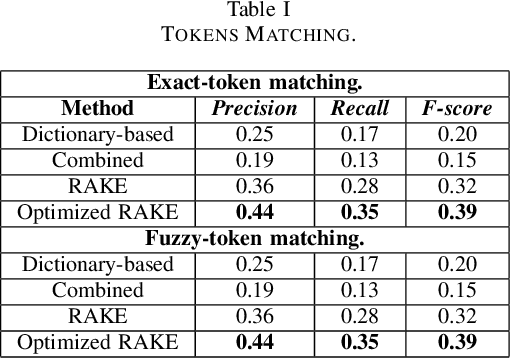
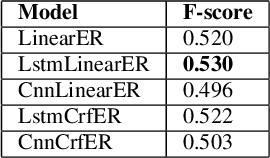
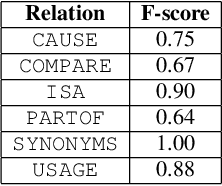
This paper is devoted to the study of methods for information extraction (entity recognition and relation classification) from scientific texts on information technology. Scientific publications provide valuable information into cutting-edge scientific advances, but efficient processing of increasing amounts of data is a time-consuming task. In this paper, several modifications of methods for the Russian language are proposed. It also includes the results of experiments comparing a keyword extraction method, vocabulary method, and some methods based on neural networks. Text collections for these tasks exist for the English language and are actively used by the scientific community, but at present, such datasets in Russian are not publicly available. In this paper, we present a corpus of scientific texts in Russian, RuSERRC. This dataset consists of 1600 unlabeled documents and 80 labeled with entities and semantic relations (6 relation types were considered). The dataset and models are available at https://github.com/iis-research-team. We hope they can be useful for research purposes and development of information extraction systems.
Stylizing 3D Scene via Implicit Representation and HyperNetwork
Jun 05, 2021
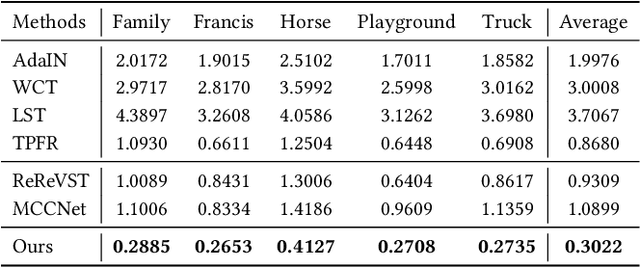
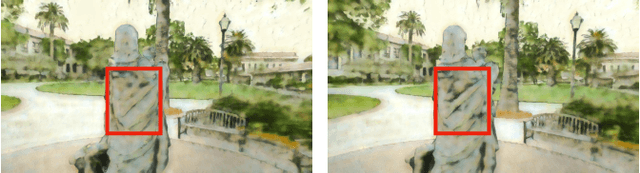
In this work, we aim to address the 3D scene stylization problem - generating stylized images of the scene at arbitrary novel view angles. A straightforward solution is to combine existing novel view synthesis and image/video style transfer approaches, which often leads to blurry results or inconsistent appearance. Inspired by the high quality results of the neural radiance fields (NeRF) method, we propose a joint framework to directly render novel views with the desired style. Our framework consists of two components: an implicit representation of the 3D scene with the neural radiance field model, and a hypernetwork to transfer the style information into the scene representation. In particular, our implicit representation model disentangles the scene into the geometry and appearance branches, and the hypernetwork learns to predict the parameters of the appearance branch from the reference style image. To alleviate the training difficulties and memory burden, we propose a two-stage training procedure and a patch sub-sampling approach to optimize the style and content losses with the neural radiance field model. After optimization, our model is able to render consistent novel views at arbitrary view angles with arbitrary style. Both quantitative evaluation and human subject study have demonstrated that the proposed method generates faithful stylization results with consistent appearance across different views.
Using natural language processing techniques to extract information on the properties and functionalities of energetic materials from large text corpora
Mar 01, 2019
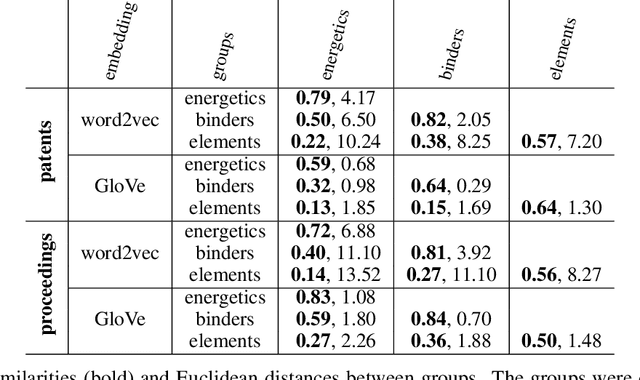


The number of scientific journal articles and reports being published about energetic materials every year is growing exponentially, and therefore extracting relevant information and actionable insights from the latest research is becoming a considerable challenge. In this work we explore how techniques from natural language processing and machine learning can be used to automatically extract chemical insights from large collections of documents. We first describe how to download and process documents from a variety of sources - journal articles, conference proceedings (including NTREM), the US Patent & Trademark Office, and the Defense Technical Information Center archive on archive.org. We present a custom NLP pipeline which uses open source NLP tools to identify the names of chemical compounds and relates them to function words ("underwater", "rocket", "pyrotechnic") and property words ("elastomer", "non-toxic"). After explaining how word embeddings work we compare the utility of two popular word embeddings - word2vec and GloVe. Chemical-chemical and chemical-application relationships are obtained by doing computations with word vectors. We show that word embeddings capture latent information about energetic materials, so that related materials appear close together in the word embedding space.
6G Downlink Transmission via Rate Splitting Space Division Multiple Access Based on Grouped Code Index Modulation
Mar 01, 2021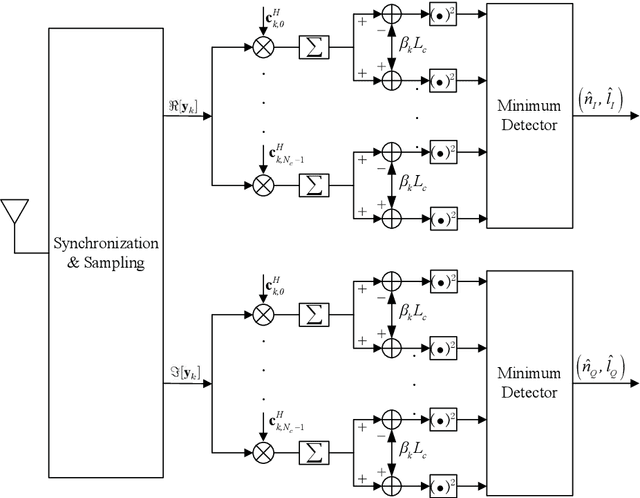
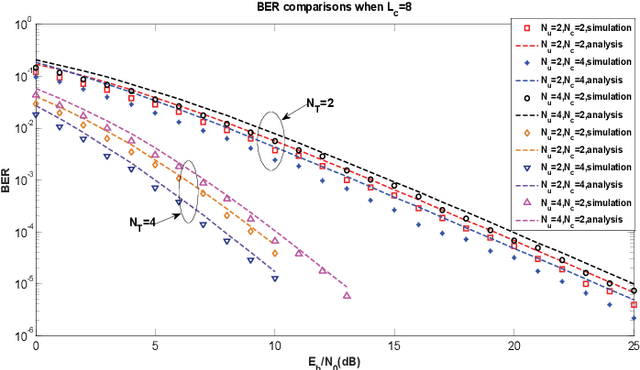
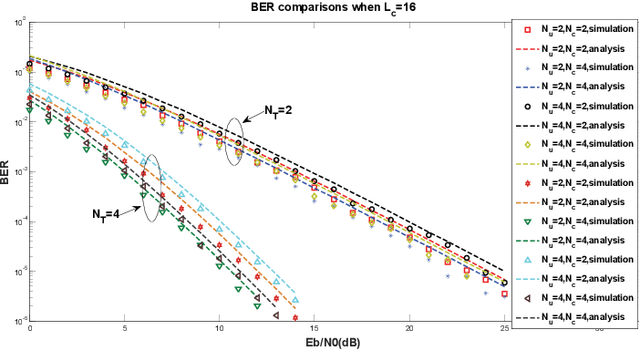
A novel rate splitting space division multiple access (SDMA) scheme based on grouped code index modulation (GrCIM) is proposed for the sixth generation (6G) downlink transmission. The proposed RSMA-GrCIM scheme transmits information to multiple user equipments (UEs) through the space division multiple access (SDMA) technique, and exploits code index modulation for rate splitting. Since the CIM scheme conveys information bits via the index of the selected Walsh code and binary phase shift keying (BPSK) signal, our RSMA scheme transmits the private messages of each user through the indices, and the common messages via the BPSK signal. Moreover, the Walsh code set is grouped into several orthogonal subsets to eliminate the interference from other users. A maximum likelihood (ML) detector is used to recovery the source bits, and a mathematical analysis is provided for the upper bound bit error ratio (BER) of each user. Comparisons are also made between our proposed scheme and the traditional SDMA scheme in spectrum utilization, number of available UEs, etc. Numerical results are given to verify the effectiveness of the proposed SDMA-GrCIM scheme.
Contrastive Separative Coding for Self-supervised Representation Learning
Mar 01, 2021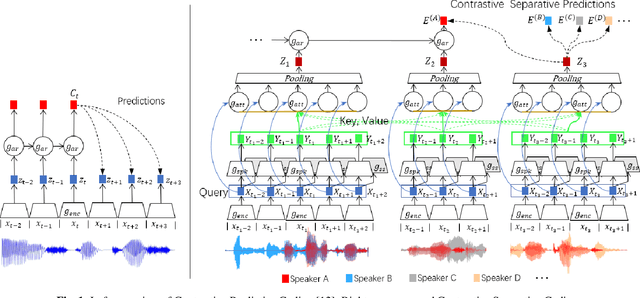
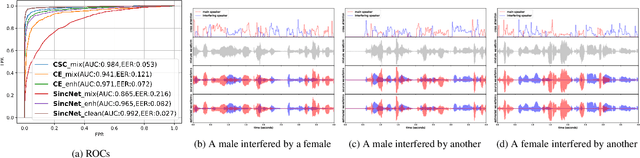
To extract robust deep representations from long sequential modeling of speech data, we propose a self-supervised learning approach, namely Contrastive Separative Coding (CSC). Our key finding is to learn such representations by separating the target signal from contrastive interfering signals. First, a multi-task separative encoder is built to extract shared separable and discriminative embedding; secondly, we propose a powerful cross-attention mechanism performed over speaker representations across various interfering conditions, allowing the model to focus on and globally aggregate the most critical information to answer the "query" (current bottom-up embedding) while paying less attention to interfering, noisy, or irrelevant parts; lastly, we form a new probabilistic contrastive loss which estimates and maximizes the mutual information between the representations and the global speaker vector. While most prior unsupervised methods have focused on predicting the future, neighboring, or missing samples, we take a different perspective of predicting the interfered samples. Moreover, our contrastive separative loss is free from negative sampling. The experiment demonstrates that our approach can learn useful representations achieving a strong speaker verification performance in adverse conditions.
Wideband Channel Estimation for IRS-Aided Systems in the Face of Beam Squint
Jun 05, 2021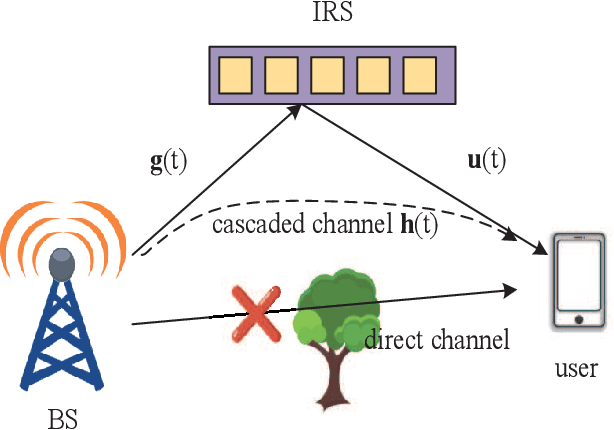
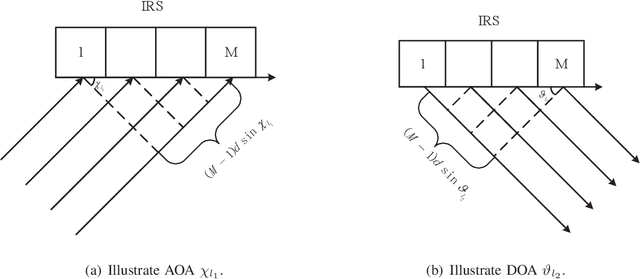
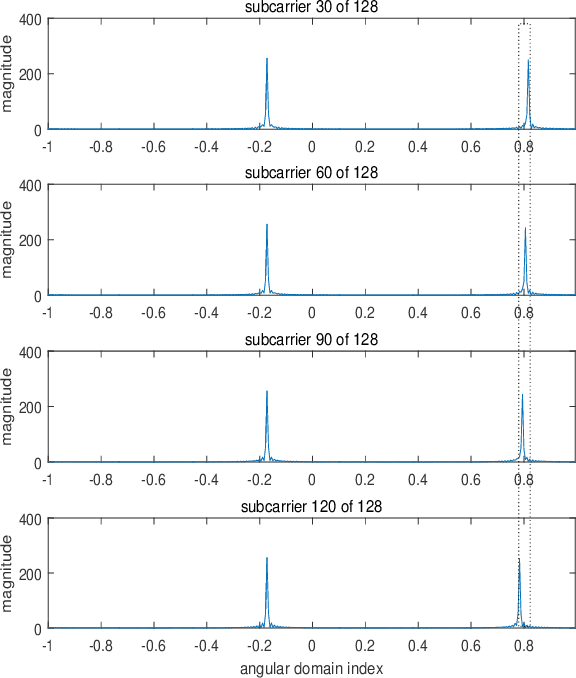
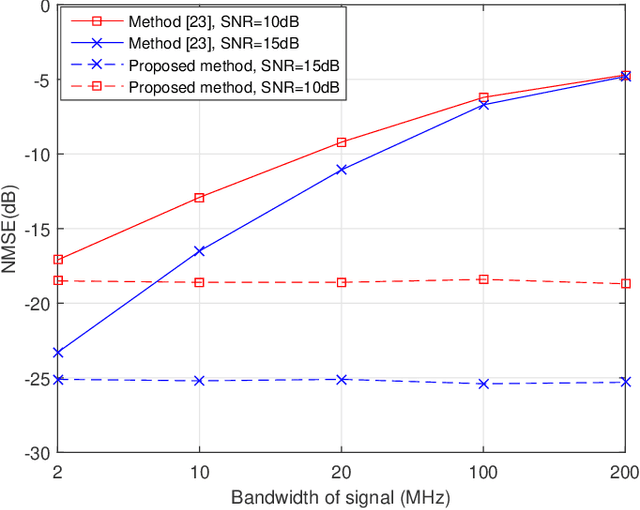
Intelligent reflecting surfaces (IRSs) improve both the bandwidth and energy efficiency of wideband communication systems by using low-cost passive elements for reflecting the impinging signals with adjustable phase shifts. To realize the full potential of IRS-aided systems, having accurate channel state information (CSI) is indispensable, but it is challenging to acquire, since these passive devices cannot carry out transmit/receive signal processing. The existing channel estimation methods conceived for wideband IRS-aided communication systems only consider the channel's frequency selectivity, but ignore the effect of beam squint, despite its severe performance degradation. Hence we fill this gap and conceive wideband channel estimation for IRS-aided communication systems by explicitly taking the effect of beam squint into consideration. We demonstrate that the mutual correlation function between the spatial steering vectors and the cascaded two-hop channel reflected by the IRS has two peaks, which leads to a pair of estimated angles for a single propagation path, due to the effect of beam squint. One of these two estimated angles is the frequency-independent `actual angle', while the other one is the frequency-dependent `false angle'. To reduce the influence of false angles on channel estimation, we propose a twin-stage orthogonal matching pursuit (TS-OMP) algorithm.
Gender Bias in Machine Translation
Apr 13, 2021
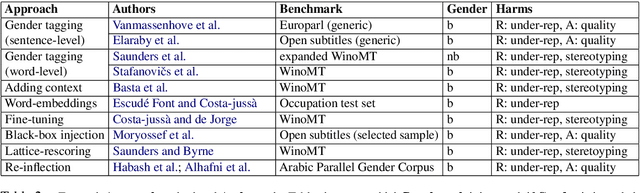
Machine translation (MT) technology has facilitated our daily tasks by providing accessible shortcuts for gathering, elaborating and communicating information. However, it can suffer from biases that harm users and society at large. As a relatively new field of inquiry, gender bias in MT still lacks internal cohesion, which advocates for a unified framework to ease future research. To this end, we: i)critically review current conceptualizations of bias in light of theoretical insights from related disciplines, ii) summarize previous analyses aimed at assessing gender bias in MT, iii)discuss the mitigating strategies proposed so far, and iv)point toward potential directions for future work.