 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Optimal Combination of Kernels using Genetic Programming
Apr 22, 2016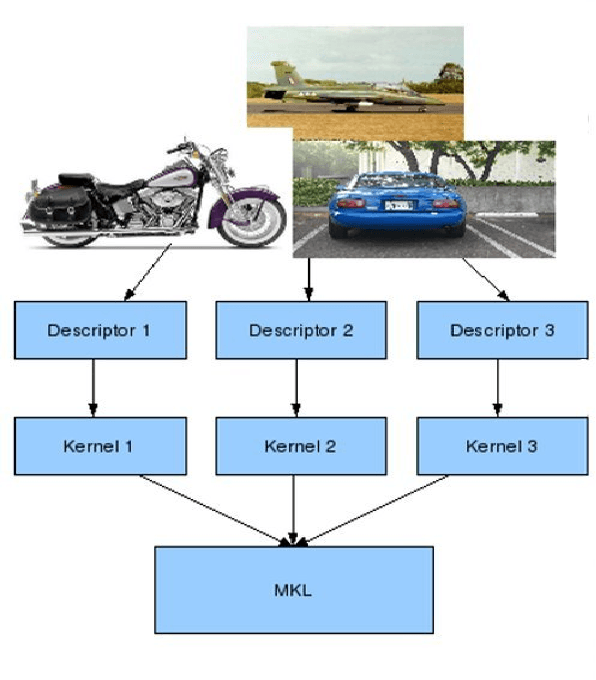

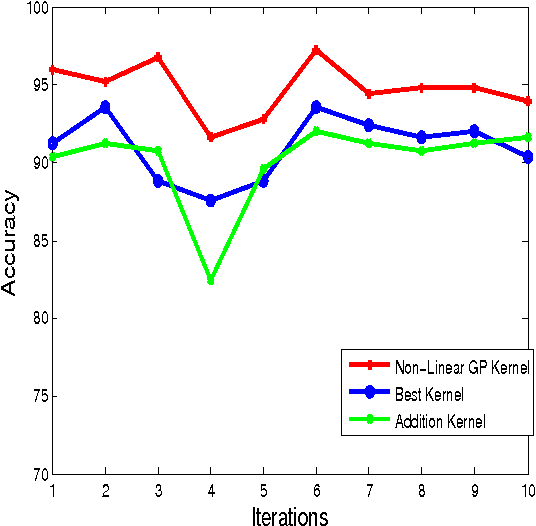
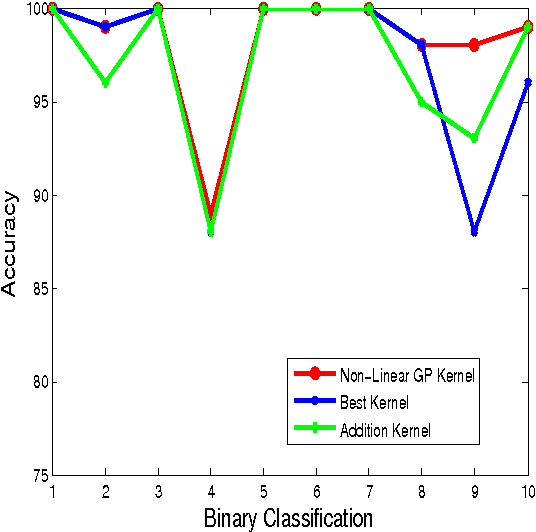
In Computer Vision, problem of identifying or classifying the objects present in an image is called Object Categorization. It is a challenging problem, especially when the images have clutter background, occlusions or different lighting conditions. Many vision features have been proposed which aid object categorization even in such adverse conditions. Past research has shown that, employing multiple features rather than any single features leads to better recognition. Multiple Kernel Learning (MKL) framework has been developed for learning an optimal combination of features for object categorization. Existing MKL methods use linear combination of base kernels which may not be optimal for object categorization. Real-world object categorization may need to consider complex combination of kernels(non-linear) and not only linear combination. Evolving non-linear functions of base kernels using Genetic Programming is proposed in this report. Experiment results show that non-kernel generated using genetic programming gives good accuracy as compared to linear combination of kernels.
Comparing Face Detection and Recognition Techniques
Apr 19, 2016This paper implements and compares different techniques for face detection and recognition. One is find where the face is located in the images that is face detection and second is face recognition that is identifying the person. We study three techniques in this paper: Face detection using self organizing map (SOM), Face recognition by projection and nearest neighbor and Face recognition using SVM.
Accessing accurate documents by mining auxiliary document information
Apr 15, 2016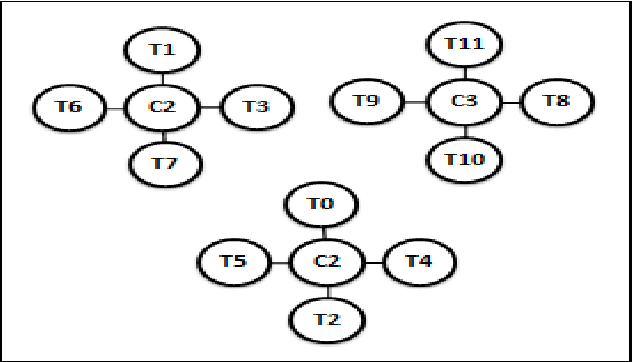
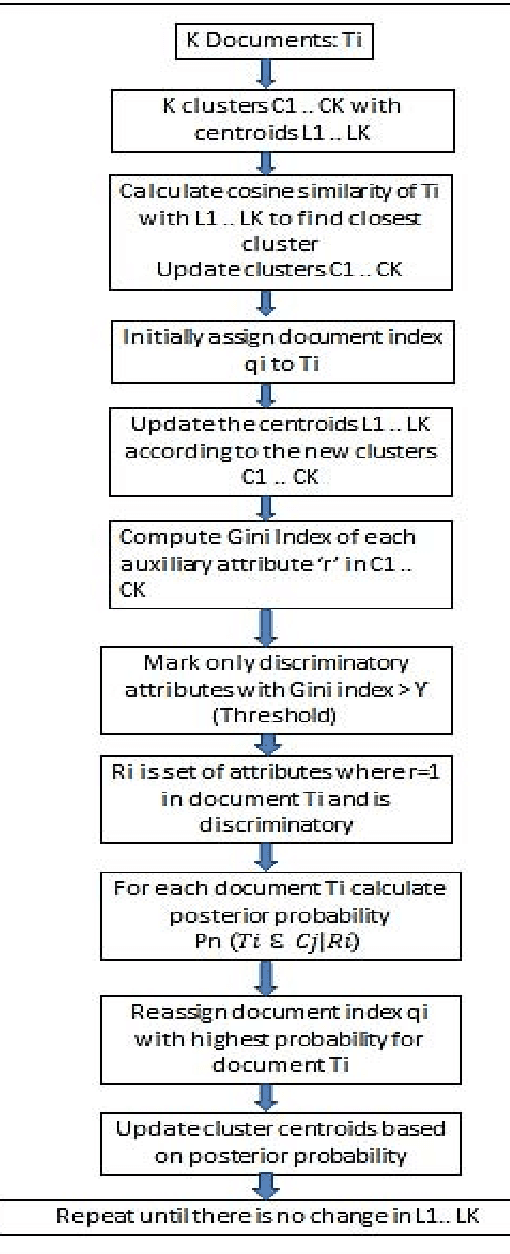
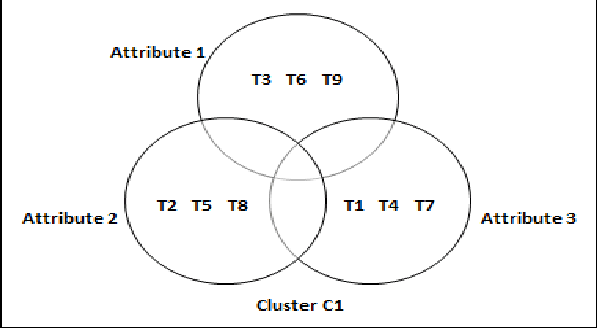
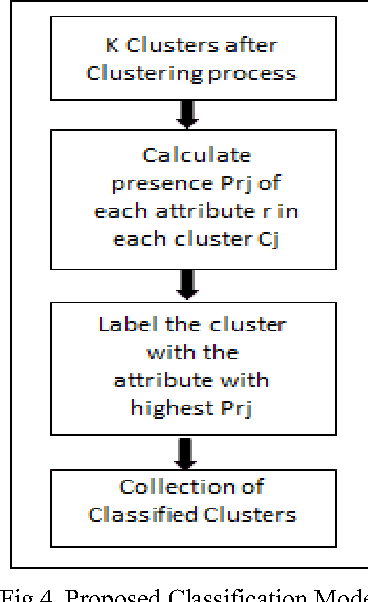
Earlier techniques of text mining included algorithms like k-means, Naive Bayes, SVM which classify and cluster the text document for mining relevant information about the documents. The need for improving the mining techniques has us searching for techniques using the available algorithms. This paper proposes one technique which uses the auxiliary information that is present inside the text documents to improve the mining. This auxiliary information can be a description to the content. This information can be either useful or completely useless for mining. The user should assess the worth of the auxiliary information before considering this technique for text mining. In this paper, a combination of classical clustering algorithms is used to mine the datasets. The algorithm runs in two stages which carry out mining at different levels of abstraction. The clustered documents would then be classified based on the necessary groups. The proposed technique is aimed at improved results of document clustering.