 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLittle Brains, Big Feats: Exploring Compact Language Models
Jun 29, 2026While large language models have been dominating the research landscape recently, small language models remain highly relevant across various domains; yet, they receive far less attention. In this study, we investigate how smaller language models perform during the generation stage within a Retrieval-Augmented Generation (RAG) system. To benchmark these models effectively, we utilised both open-source and proprietary datasets covering diverse subject areas and question types. Our findings demonstrate that a RAG system with small language models can be executed directly on-device without requiring any GPU hardware within a reasonable time. The experimental code and links to the supplementary materials can be accessed through the GitHub repository: https://github.com/SibNN/SLM-RAG-EVAL.
Data filtering methods for training language models
May 28, 2026Data quality is a critical factor in the effectiveness of machine learning models. Label errors, present even in widely used benchmarks, introduce noise into training data and reduce model generalization. In this work, we conduct a comparative analysis of two automatic label error detection methods - Confident Learning and Dataset Cartography - on three Russian text classification corpora of varying size, number of classes, and domain: ru_emotion_e-culture (49,123 examples, emotion classification), RuCoLA (8,524 examples, linguistic acceptability), and TERRa (2,337 examples, textual entailment recognition). We use the pre-trained rubert-base-cased model fine-tuned on each corpus. To verify the meaningfulness of filtering, we conduct control experiments with random removal of an equivalent number of examples. Results show that the effectiveness of both methods depends strongly on dataset characteristics: on large corpora with low noise levels, filtering does not improve performance, while on small datasets with high noise, Confident Learning achieves a significant F1-macro improvement. Dataset Cartography demonstrates more conservative behavior, removing fewer examples. Across all corpora, targeted removal by both methods outperforms random removal, confirming the meaningfulness of the approaches.
TAM-Eval: Evaluating LLMs for Automated Unit Test Maintenance
Jan 26, 2026While Large Language Models (LLMs) have shown promise in software engineering, their application to unit testing remains largely confined to isolated test generation or oracle prediction, neglecting the broader challenge of test suite maintenance. We introduce TAM-Eval (Test Automated Maintenance Evaluation), a framework and benchmark designed to evaluate model performance across three core test maintenance scenarios: creation, repair, and updating of test suites. Unlike prior work limited to function-level tasks, TAM-Eval operates at the test file level, while maintaining access to full repository context during isolated evaluation, better reflecting real-world maintenance workflows. Our benchmark comprises 1,539 automatically extracted and validated scenarios from Python, Java, and Go projects. TAM-Eval supports system-agnostic evaluation of both raw LLMs and agentic workflows, using a reference-free protocol based on test suite pass rate, code coverage, and mutation testing. Empirical results indicate that state-of-the-art LLMs have limited capabilities in realistic test maintenance processes and yield only marginal improvements in test effectiveness. We release TAM-Eval as an open-source framework to support future research in automated software testing. Our data and code are publicly available at https://github.com/trndcenter/TAM-Eval.
RM -RF: Reward Model for Run-Free Unit Test Evaluation
Jan 19, 2026We present RM-RF, a lightweight reward model for run-free evaluation of automatically generated unit tests. Instead of repeatedly compiling and executing candidate tests, RM-RF predicts - from source and test code alone - three execution-derived signals: (1) whether the augmented test suite compiles and runs successfully, (2) whether the generated test cases increase code coverage, and (3) whether the generated test cases improve the mutation kill rate. To train and evaluate RM-RF we assemble a multilingual dataset (Java, Python, Go) of focal files, test files, and candidate test additions labeled by an execution-based pipeline, and we release an associated dataset and methodology for comparative evaluation. We tested multiple model families and tuning regimes (zero-shot, full fine-tuning, and PEFT via LoRA), achieving an average F1 of 0.69 across the three targets. Compared to conventional compile-and-run instruments, RM-RF provides substantially lower latency and infrastructure cost while delivering competitive predictive fidelity, enabling fast, scalable feedback for large-scale test generation and RL-based code optimization.
MERA Code: A Unified Framework for Evaluating Code Generation Across Tasks
Jul 16, 2025Advancements in LLMs have enhanced task automation in software engineering; however, current evaluations primarily focus on natural language tasks, overlooking code quality. Most benchmarks prioritize high-level reasoning over executable code and real-world performance, leaving gaps in understanding true capabilities and risks associated with these models in production. To address this issue, we propose MERA Code, a new addition to the MERA benchmark family, specifically focused on evaluating code for the latest code generation LLMs in Russian. This benchmark includes 11 evaluation tasks that span 8 programming languages. Our proposed evaluation methodology features a taxonomy that outlines the practical coding skills necessary for models to complete these tasks. The benchmark comprises an open-source codebase for users to conduct MERA assessments, a scoring system compatible with various programming environments, and a platform featuring a leaderboard and submission system. We evaluate open LLMs and frontier API models, analyzing their limitations in terms of practical coding tasks in non-English languages. We are publicly releasing MERA to guide future research, anticipate groundbreaking features in model development, and standardize evaluation procedures.
Russian-Language Multimodal Dataset for Automatic Summarization of Scientific Papers
May 13, 2024



The paper discusses the creation of a multimodal dataset of Russian-language scientific papers and testing of existing language models for the task of automatic text summarization. A feature of the dataset is its multimodal data, which includes texts, tables and figures. The paper presents the results of experiments with two language models: Gigachat from SBER and YandexGPT from Yandex. The dataset consists of 420 papers and is publicly available on https://github.com/iis-research-team/summarization-dataset.
Automatic Aspect Extraction from Scientific Texts
Oct 06, 2023



Being able to extract from scientific papers their main points, key insights, and other important information, referred to here as aspects, might facilitate the process of conducting a scientific literature review. Therefore, the aim of our research is to create a tool for automatic aspect extraction from Russian-language scientific texts of any domain. In this paper, we present a cross-domain dataset of scientific texts in Russian, annotated with such aspects as Task, Contribution, Method, and Conclusion, as well as a baseline algorithm for aspect extraction, based on the multilingual BERT model fine-tuned on our data. We show that there are some differences in aspect representation in different domains, but even though our model was trained on a limited number of scientific domains, it is still able to generalize to new domains, as was proved by cross-domain experiments. The code and the dataset are available at \url{https://github.com/anna-marshalova/automatic-aspect-extraction-from-scientific-texts}.
TERMinator: A system for scientific texts processing
Sep 29, 2022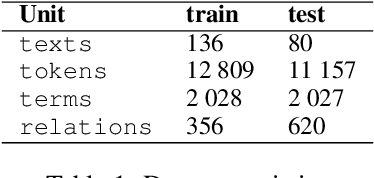

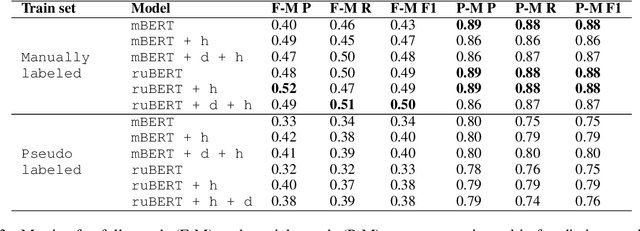
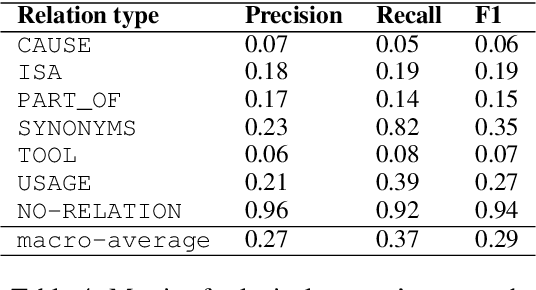
This paper is devoted to the extraction of entities and semantic relations between them from scientific texts, where we consider scientific terms as entities. In this paper, we present a dataset that includes annotations for two tasks and develop a system called TERMinator for the study of the influence of language models on term recognition and comparison of different approaches for relation extraction. Experiments show that language models pre-trained on the target language are not always show the best performance. Also adding some heuristic approaches may improve the overall quality of the particular task. The developed tool and the annotated corpus are publicly available at https://github.com/iis-research-team/terminator and may be useful for other researchers.
A system for information extraction from scientific texts in Russian
Sep 14, 2021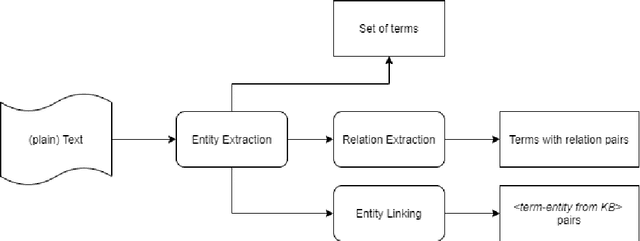
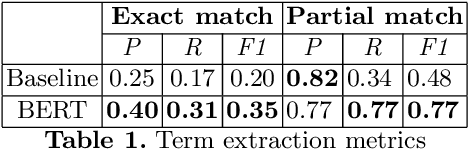
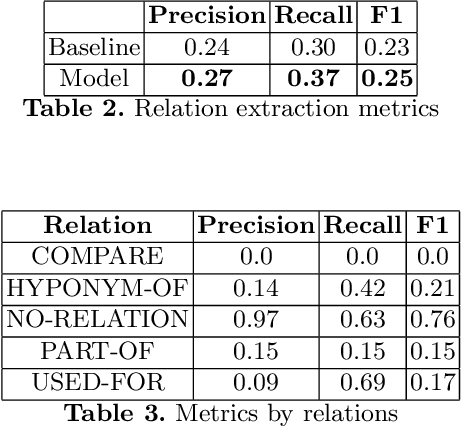
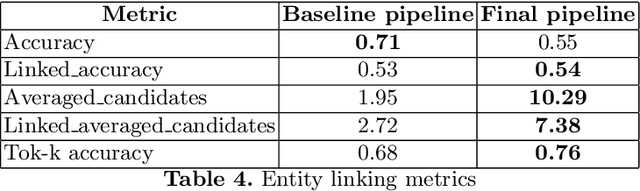
In this paper, we present a system for information extraction from scientific texts in the Russian language. The system performs several tasks in an end-to-end manner: term recognition, extraction of relations between terms, and term linking with entities from the knowledge base. These tasks are extremely important for information retrieval, recommendation systems, and classification. The advantage of the implemented methods is that the system does not require a large amount of labeled data, which saves time and effort for data labeling and therefore can be applied in low- and mid-resource settings. The source code is publicly available and can be used for different research purposes.
Entity Recognition and Relation Extraction from Scientific and Technical Texts in Russian
Dec 14, 2020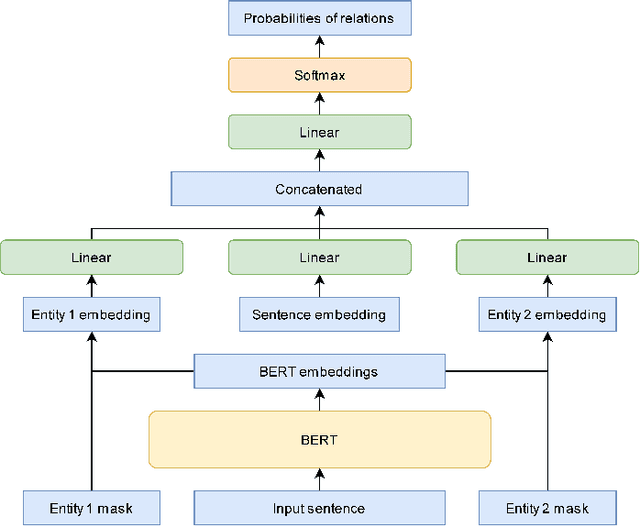
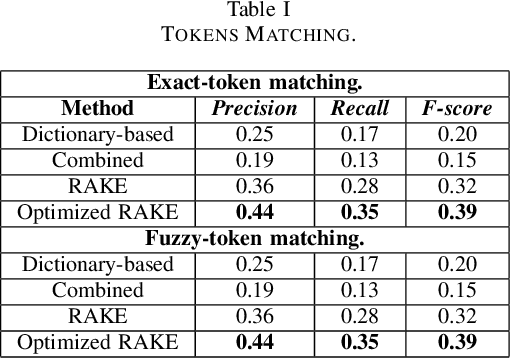
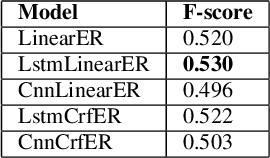
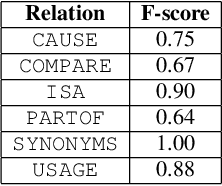
This paper is devoted to the study of methods for information extraction (entity recognition and relation classification) from scientific texts on information technology. Scientific publications provide valuable information into cutting-edge scientific advances, but efficient processing of increasing amounts of data is a time-consuming task. In this paper, several modifications of methods for the Russian language are proposed. It also includes the results of experiments comparing a keyword extraction method, vocabulary method, and some methods based on neural networks. Text collections for these tasks exist for the English language and are actively used by the scientific community, but at present, such datasets in Russian are not publicly available. In this paper, we present a corpus of scientific texts in Russian, RuSERRC. This dataset consists of 1600 unlabeled documents and 80 labeled with entities and semantic relations (6 relation types were considered). The dataset and models are available at https://github.com/iis-research-team. We hope they can be useful for research purposes and development of information extraction systems.