 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reinforced Generative Adversarial Network for Abstractive Text Summarization
May 31, 2021
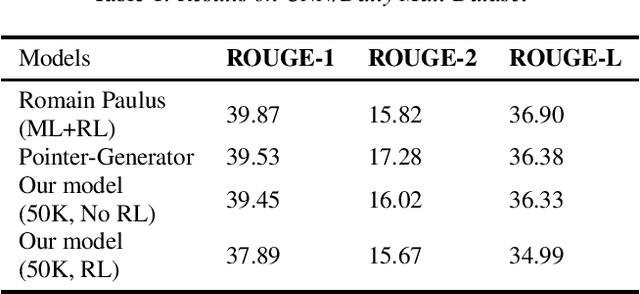
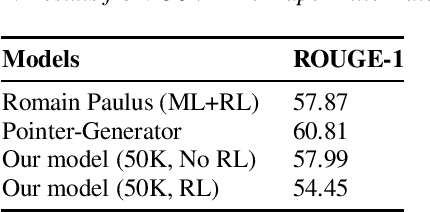
Sequence-to-sequence models provide a viable new approach to generative summarization, allowing models that are no longer limited to simply selecting and recombining sentences from the original text. However, these models have three drawbacks: their grasp of the details of the original text is often inaccurate, and the text generated by such models often has repetitions, while it is difficult to handle words that are beyond the word list. In this paper, we propose a new architecture that combines reinforcement learning and adversarial generative networks to enhance the sequence-to-sequence attention model. First, we use a hybrid pointer-generator network that copies words directly from the source text, contributing to accurate reproduction of information without sacrificing the ability of generators to generate new words. Second, we use both intra-temporal and intra-decoder attention to penalize summarized content and thus discourage repetition. We apply our model to our own proposed COVID-19 paper title summarization task and achieve close approximations to the current model on ROUEG, while bringing better readability.
Energy-Efficient Precoding in Electromagnetic Exposure-Constrained Uplink Multiuser MIMO
May 31, 2021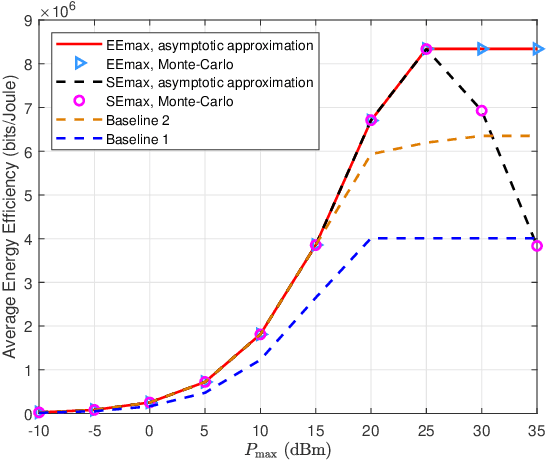
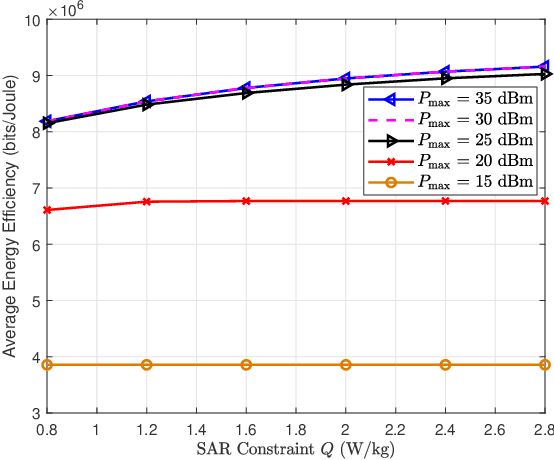
User electromagnetic (EM) exposure is continuously being exacerbated by the evolution of multi-antenna portable devices. To mitigate the effects of EM radiation, portable devices must satisfy tight regulations on user exposure level, generally measured by specific absorption rate (SAR). To this end, we investigate the SAR-aware uplink precoder design for the energy efficiency (EE) maximization in multiuser multiple-input multiple-output transmission exploiting statistical channel state information (CSI). As the objective function of the design problem is computationally demanding in the absence of closed form, we present an asymptotic approximation of the objective to facilitate the precoder design. An iterative algorithm based on Dinkelbach's method and sequential optimization is proposed to obtain an optimal solution of the asymptotic EE optimization problem. Based on the transformed problem, an iterative SAR-aware water-filing scheme is further conceived for the EE optimization precoding design with statistical CSI. Numerical results illustrate substantial performance improvements provided by our proposed SAR-aware energy-efficient transmission scheme over the traditional baseline schemes.
Leveraging Conditional Generative Models in a General Explanation Framework of Classifier Decisions
Jun 21, 2021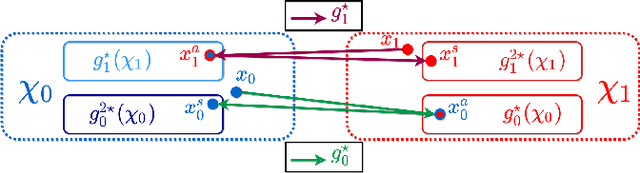
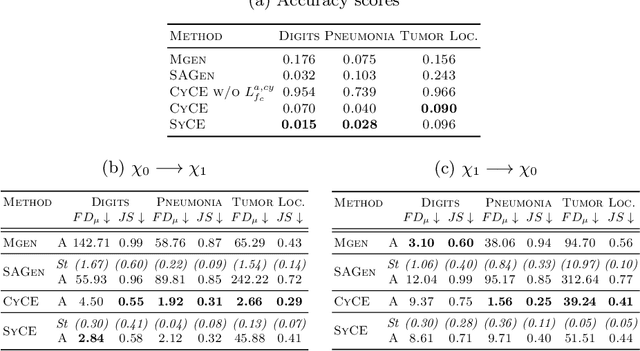
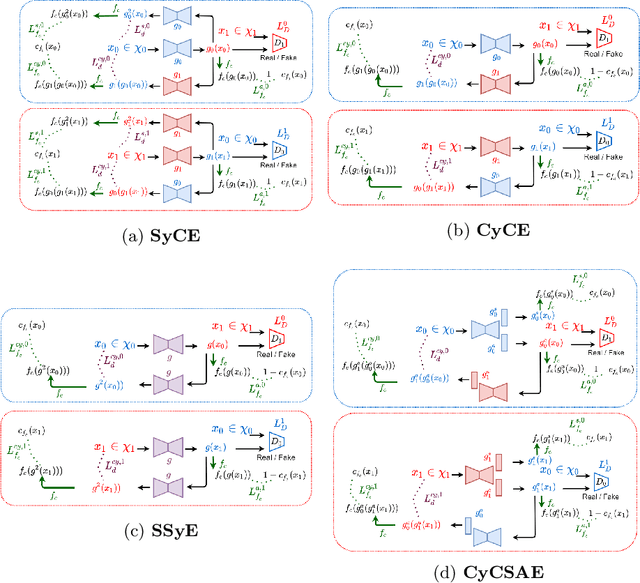
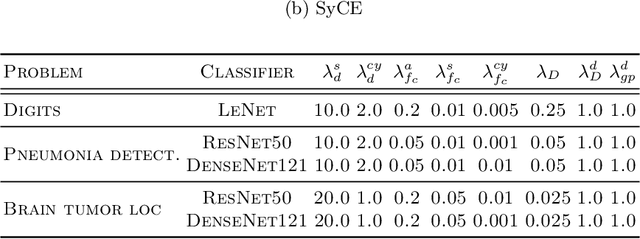
Providing a human-understandable explanation of classifiers' decisions has become imperative to generate trust in their use for day-to-day tasks. Although many works have addressed this problem by generating visual explanation maps, they often provide noisy and inaccurate results forcing the use of heuristic regularization unrelated to the classifier in question. In this paper, we propose a new general perspective of the visual explanation problem overcoming these limitations. We show that visual explanation can be produced as the difference between two generated images obtained via two specific conditional generative models. Both generative models are trained using the classifier to explain and a database to enforce the following properties: (i) All images generated by the first generator are classified similarly to the input image, whereas the second generator's outputs are classified oppositely. (ii) Generated images belong to the distribution of real images. (iii) The distances between the input image and the corresponding generated images are minimal so that the difference between the generated elements only reveals relevant information for the studied classifier. Using symmetrical and cyclic constraints, we present two different approximations and implementations of the general formulation. Experimentally, we demonstrate significant improvements w.r.t the state-of-the-art on three different public data sets. In particular, the localization of regions influencing the classifier is consistent with human annotations.
A novel multimodal fusion network based on a joint coding model for lane line segmentation
Mar 20, 2021
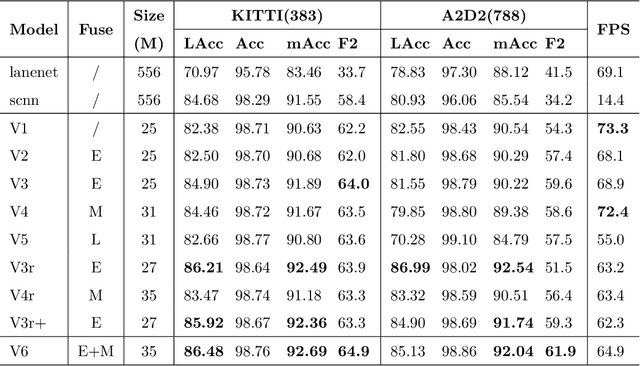
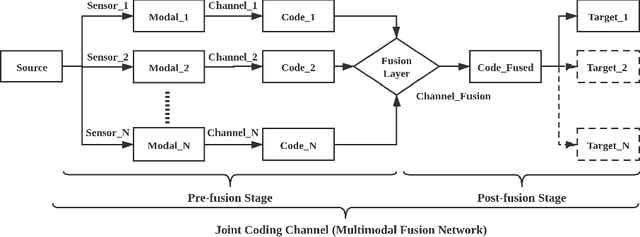
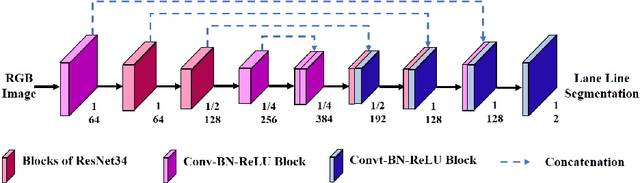
There has recently been growing interest in utilizing multimodal sensors to achieve robust lane line segmentation. In this paper, we introduce a novel multimodal fusion architecture from an information theory perspective, and demonstrate its practical utility using Light Detection and Ranging (LiDAR) camera fusion networks. In particular, we develop, for the first time, a multimodal fusion network as a joint coding model, where each single node, layer, and pipeline is represented as a channel. The forward propagation is thus equal to the information transmission in the channels. Then, we can qualitatively and quantitatively analyze the effect of different fusion approaches. We argue the optimal fusion architecture is related to the essential capacity and its allocation based on the source and channel. To test this multimodal fusion hypothesis, we progressively determine a series of multimodal models based on the proposed fusion methods and evaluate them on the KITTI and the A2D2 datasets. Our optimal fusion network achieves 85%+ lane line accuracy and 98.7%+ overall. The performance gap among the models will inform continuing future research into development of optimal fusion algorithms for the deep multimodal learning community.
Pho(SC)Net: An Approach Towards Zero-shot Word Image Recognition in Historical Documents
May 31, 2021
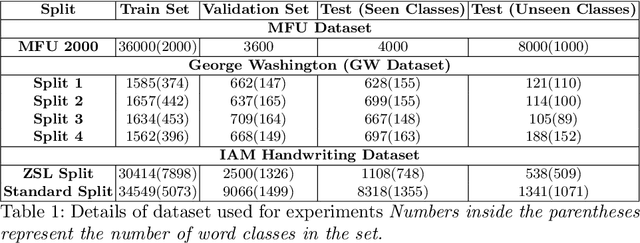

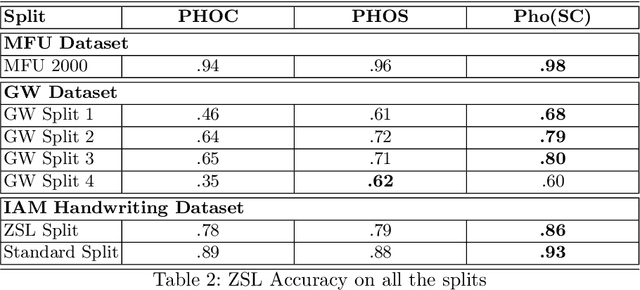
Annotating words in a historical document image archive for word image recognition purpose demands time and skilled human resource (like historians, paleographers). In a real-life scenario, obtaining sample images for all possible words is also not feasible. However, Zero-shot learning methods could aptly be used to recognize unseen/out-of-lexicon words in such historical document images. Based on previous state-of-the-art methods for word spotting and recognition, we propose a hybrid representation that considers the character's shape appearance to differentiate between two different words and has shown to be more effective in recognizing unseen words. This representation has been termed as Pyramidal Histogram of Shapes (PHOS), derived from PHOC, which embeds information about the occurrence and position of characters in the word. Later, the two representations are combined and experiments were conducted to examine the effectiveness of an embedding that has properties of both PHOS and PHOC. Encouraging results were obtained on two publicly available historical document datasets and one synthetic handwritten dataset, which justifies the efficacy of "Phos" and the combined "Pho(SC)" representation.
Arthroscopic Multi-Spectral Scene Segmentation Using Deep Learning
Mar 03, 2021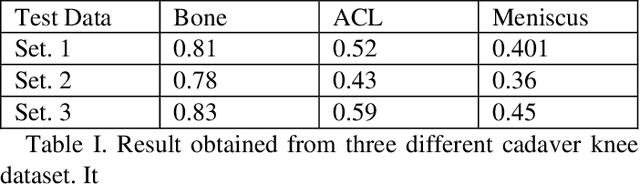
Knee arthroscopy is a minimally invasive surgical (MIS) procedure which is performed to treat knee-joint ailment. Lack of visual information of the surgical site obtained from miniaturized cameras make this surgical procedure more complex. Knee cavity is a very confined space; therefore, surgical scenes are captured at close proximity. Insignificant context of knee atlas often makes them unrecognizable as a consequence unintentional tissue damage often occurred and shows a long learning curve to train new surgeons. Automatic context awareness through labeling of the surgical site can be an alternative to mitigate these drawbacks. However, from the previous studies, it is confirmed that the surgical site exhibits several limitations, among others, lack of discriminative contextual information such as texture and features which drastically limits this vision task. Additionally, poor imaging conditions and lack of accurate ground-truth labels are also limiting the accuracy. To mitigate these limitations of knee arthroscopy, in this work we proposed a scene segmentation method that successfully segments multi structures.
A Little Pretraining Goes a Long Way: A Case Study on Dependency Parsing Task for Low-resource Morphologically Rich Languages
Feb 12, 2021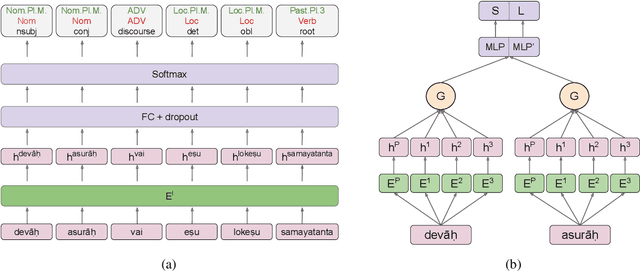
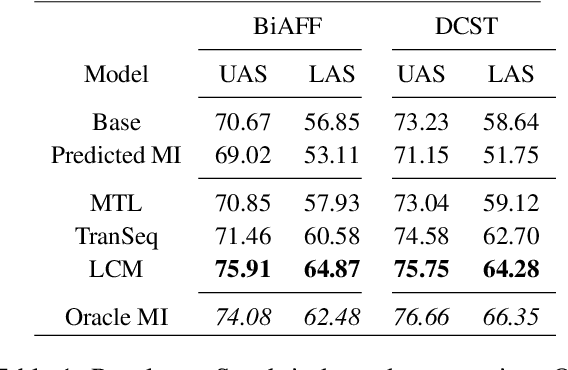
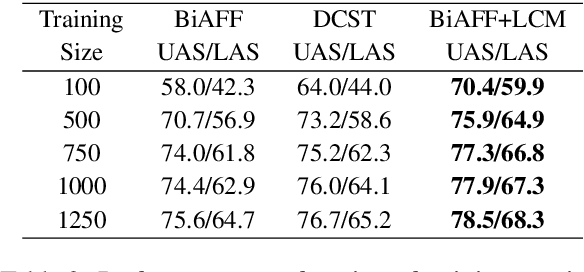
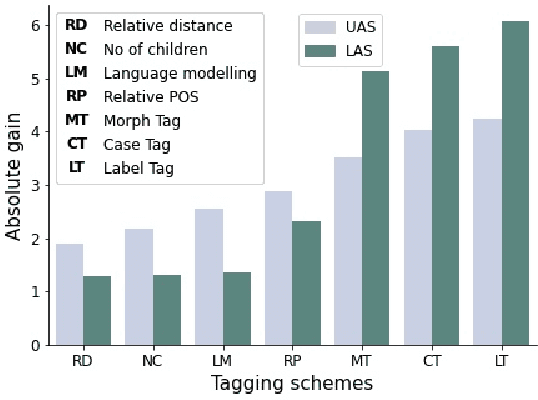
Neural dependency parsing has achieved remarkable performance for many domains and languages. The bottleneck of massive labeled data limits the effectiveness of these approaches for low resource languages. In this work, we focus on dependency parsing for morphological rich languages (MRLs) in a low-resource setting. Although morphological information is essential for the dependency parsing task, the morphological disambiguation and lack of powerful analyzers pose challenges to get this information for MRLs. To address these challenges, we propose simple auxiliary tasks for pretraining. We perform experiments on 10 MRLs in low-resource settings to measure the efficacy of our proposed pretraining method and observe an average absolute gain of 2 points (UAS) and 3.6 points (LAS). Code and data available at: https://github.com/jivnesh/LCM
Efficiently Explaining CSPs with Unsatisfiable Subset Optimization
May 31, 2021
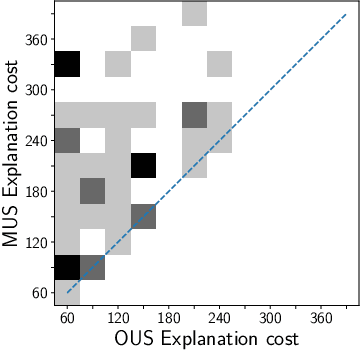
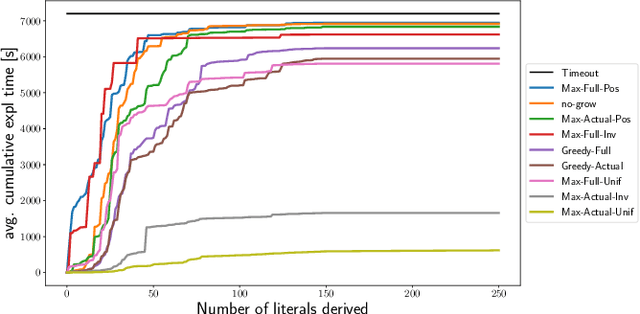
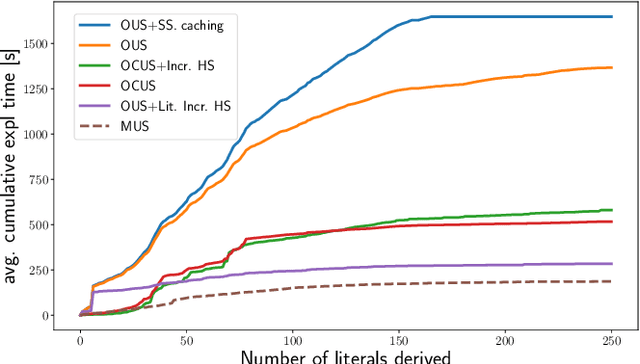
We build on a recently proposed method for explaining solutions of constraint satisfaction problems. An explanation here is a sequence of simple inference steps, where the simplicity of an inference step is measured by the number and types of constraints and facts used, and where the sequence explains all logical consequences of the problem. We build on these formal foundations and tackle two emerging questions, namely how to generate explanations that are provably optimal (with respect to the given cost metric) and how to generate them efficiently. To answer these questions, we develop 1) an implicit hitting set algorithm for finding optimal unsatisfiable subsets; 2) a method to reduce multiple calls for (optimal) unsatisfiable subsets to a single call that takes constraints on the subset into account, and 3) a method for re-using relevant information over multiple calls to these algorithms. The method is also applicable to other problems that require finding cost-optimal unsatiable subsets. We specifically show that this approach can be used to effectively find sequences of optimal explanation steps for constraint satisfaction problems like logic grid puzzles.
GeoQA: A Geometric Question Answering Benchmark Towards Multimodal Numerical Reasoning
Jun 08, 2021
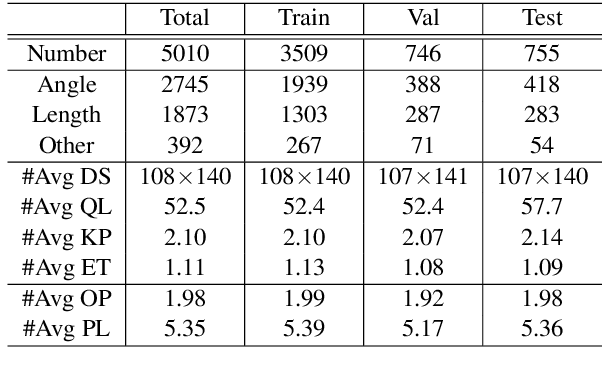

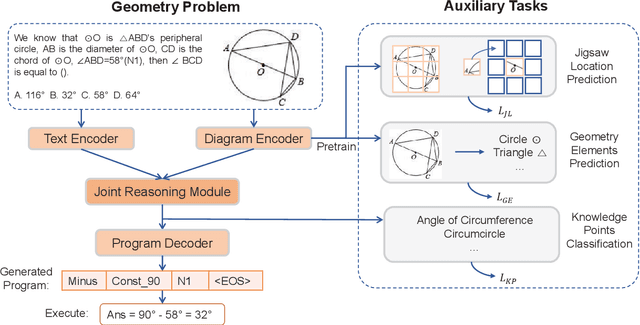
Automatic math problem solving has recently attracted increasing attention as a long-standing AI benchmark. In this paper, we focus on solving geometric problems, which requires a comprehensive understanding of textual descriptions, visual diagrams, and theorem knowledge. However, the existing methods were highly dependent on handcraft rules and were merely evaluated on small-scale datasets. Therefore, we propose a Geometric Question Answering dataset GeoQA, containing 5,010 geometric problems with corresponding annotated programs, which illustrate the solving process of the given problems. Compared with another publicly available dataset GeoS, GeoQA is 25 times larger, in which the program annotations can provide a practical testbed for future research on explicit and explainable numerical reasoning. Moreover, we introduce a Neural Geometric Solver (NGS) to address geometric problems by comprehensively parsing multimodal information and generating interpretable programs. We further add multiple self-supervised auxiliary tasks on NGS to enhance cross-modal semantic representation. Extensive experiments on GeoQA validate the effectiveness of our proposed NGS and auxiliary tasks. However, the results are still significantly lower than human performance, which leaves large room for future research. Our benchmark and code are released at https://github.com/chen-judge/GeoQA .
Understanding who uses Reddit: Profiling individuals with a self-reported bipolar disorder diagnosis
Apr 23, 2021
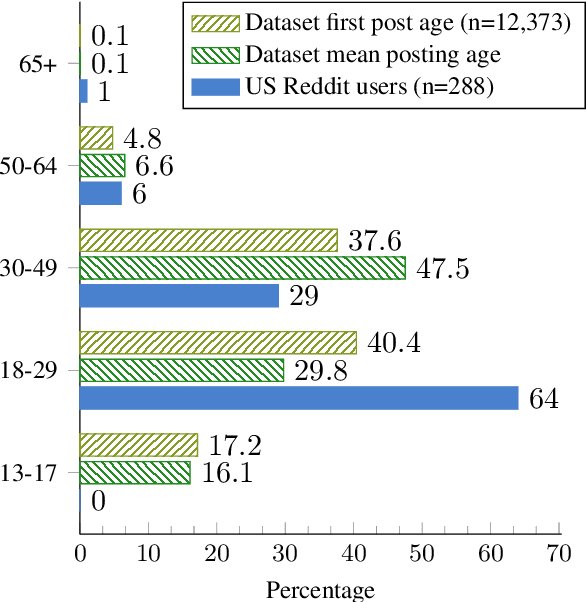
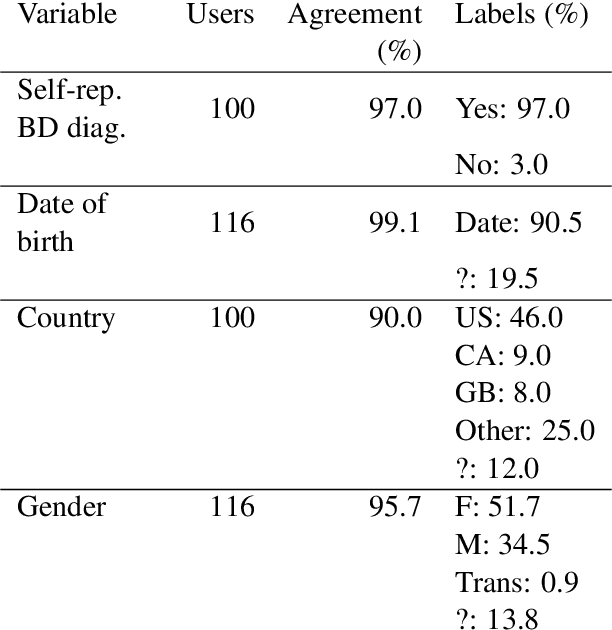
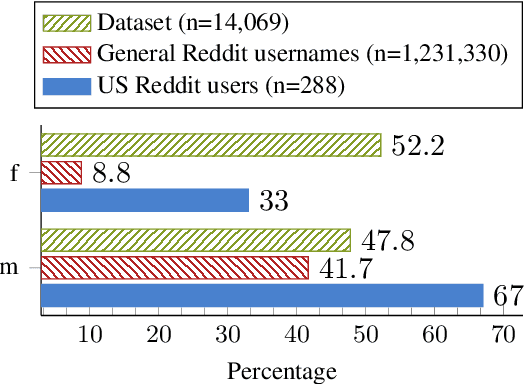
Recently, research on mental health conditions using public online data, including Reddit, has surged in NLP and health research but has not reported user characteristics, which are important to judge generalisability of findings. This paper shows how existing NLP methods can yield information on clinical, demographic, and identity characteristics of almost 20K Reddit users who self-report a bipolar disorder diagnosis. This population consists of slightly more feminine- than masculine-gendered mainly young or middle-aged US-based adults who often report additional mental health diagnoses, which is compared with general Reddit statistics and epidemiological studies. Additionally, this paper carefully evaluates all methods and discusses ethical issues.