 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel multimodal fusion network based on a joint coding model for lane line segmentation
Paper and Code
Mar 20, 2021
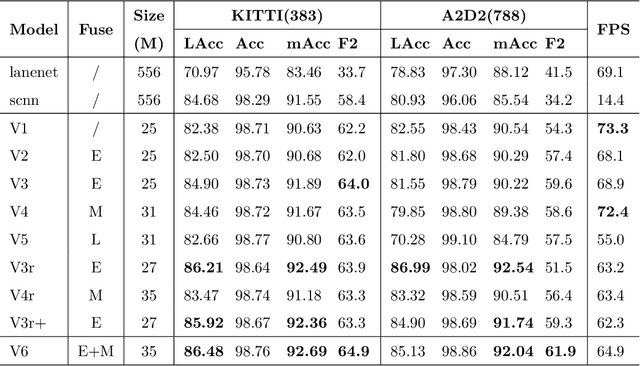
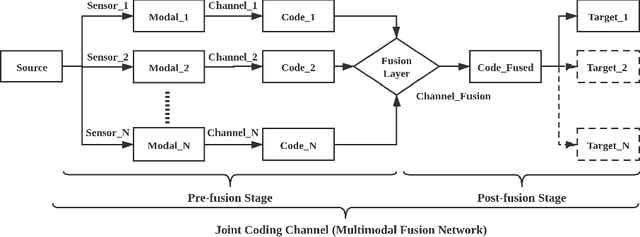
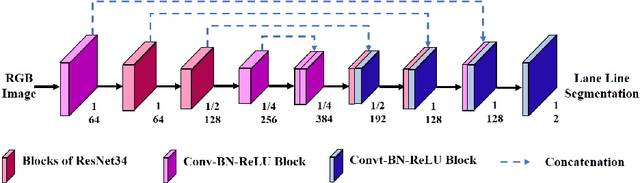
There has recently been growing interest in utilizing multimodal sensors to achieve robust lane line segmentation. In this paper, we introduce a novel multimodal fusion architecture from an information theory perspective, and demonstrate its practical utility using Light Detection and Ranging (LiDAR) camera fusion networks. In particular, we develop, for the first time, a multimodal fusion network as a joint coding model, where each single node, layer, and pipeline is represented as a channel. The forward propagation is thus equal to the information transmission in the channels. Then, we can qualitatively and quantitatively analyze the effect of different fusion approaches. We argue the optimal fusion architecture is related to the essential capacity and its allocation based on the source and channel. To test this multimodal fusion hypothesis, we progressively determine a series of multimodal models based on the proposed fusion methods and evaluate them on the KITTI and the A2D2 datasets. Our optimal fusion network achieves 85%+ lane line accuracy and 98.7%+ overall. The performance gap among the models will inform continuing future research into development of optimal fusion algorithms for the deep multimodal learning community.