 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Federated Semi-supervised Medical Image Classification via Inter-client Relation Matching
Jun 16, 2021
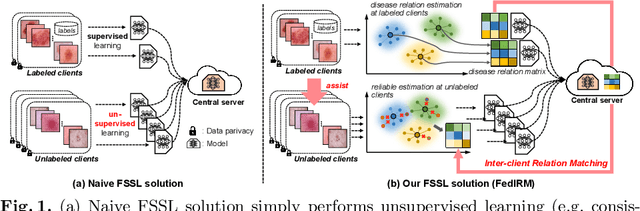
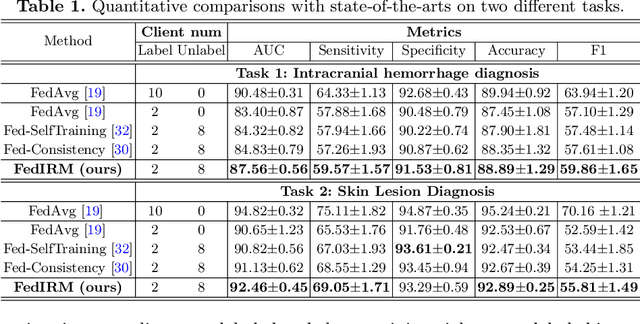
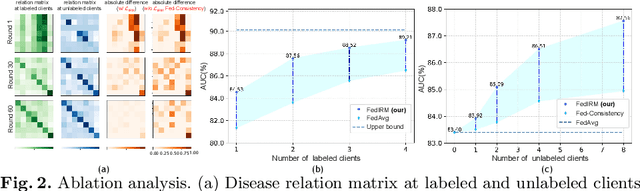
Federated learning (FL) has emerged with increasing popularity to collaborate distributed medical institutions for training deep networks. However, despite existing FL algorithms only allow the supervised training setting, most hospitals in realistic usually cannot afford the intricate data labeling due to absence of budget or expertise. This paper studies a practical yet challenging FL problem, named \textit{Federated Semi-supervised Learning} (FSSL), which aims to learn a federated model by jointly utilizing the data from both labeled and unlabeled clients (i.e., hospitals). We present a novel approach for this problem, which improves over traditional consistency regularization mechanism with a new inter-client relation matching scheme. The proposed learning scheme explicitly connects the learning across labeled and unlabeled clients by aligning their extracted disease relationships, thereby mitigating the deficiency of task knowledge at unlabeled clients and promoting discriminative information from unlabeled samples. We validate our method on two large-scale medical image classification datasets. The effectiveness of our method has been demonstrated with the clear improvements over state-of-the-arts as well as the thorough ablation analysis on both tasks\footnote{Code will be made available at \url{https://github.com/liuquande/FedIRM}}.
Attention-Guided NIR Image Colorization via Adaptive Fusion of Semantic and Texture Clues
Jul 20, 2021



Near infrared (NIR) imaging has been widely applied in low-light imaging scenarios; however, it is difficult for human and algorithms to perceive the real scene in the colorless NIR domain. While Generative Adversarial Network (GAN) has been widely employed in various image colorization tasks, it is challenging for a direct mapping mechanism, such as a conventional GAN, to transform an image from the NIR to the RGB domain with correct semantic reasoning, well-preserved textures, and vivid color combinations concurrently. In this work, we propose a novel Attention-based NIR image colorization framework via Adaptive Fusion of Semantic and Texture clues, aiming at achieving these goals within the same framework. The tasks of texture transfer and semantic reasoning are carried out in two separate network blocks. Specifically, the Texture Transfer Block (TTB) aims at extracting texture features from the NIR image's Laplacian component and transferring them for subsequent color fusion. The Semantic Reasoning Block (SRB) extracts semantic clues and maps the NIR pixel values to the RGB domain. Finally, a Fusion Attention Block (FAB) is proposed to adaptively fuse the features from the two branches and generate an optimized colorization result. In order to enhance the network's learning capacity in semantic reasoning as well as mapping precision in texture transfer, we have proposed the Residual Coordinate Attention Block (RCAB), which incorporates coordinate attention into a residual learning framework, enabling the network to capture long-range dependencies along the channel direction and meanwhile precise positional information can be preserved along spatial directions. RCAB is also incorporated into FAB to facilitate accurate texture alignment during fusion. Both quantitative and qualitative evaluations show that the proposed method outperforms state-of-the-art NIR image colorization methods.
An Efficient Cervical Whole Slide Image Analysis Framework Based on Multi-scale Semantic and Spatial Features using Deep Learning
Jun 29, 2021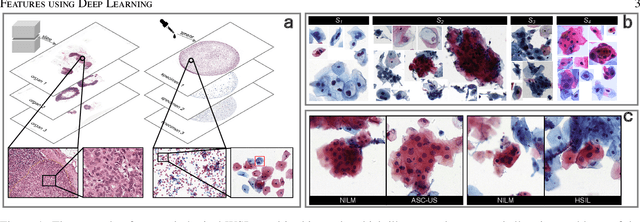
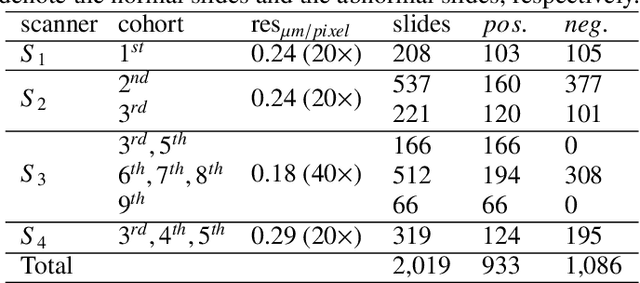
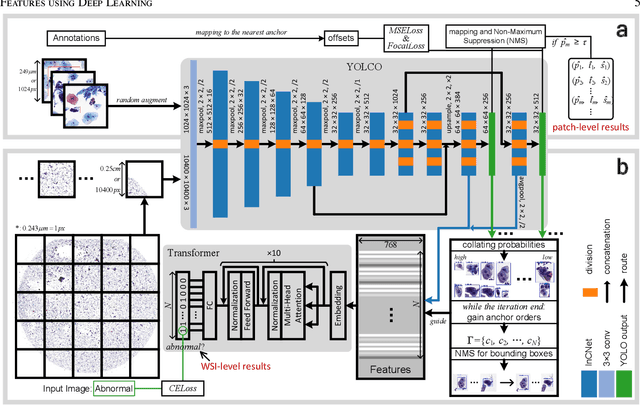
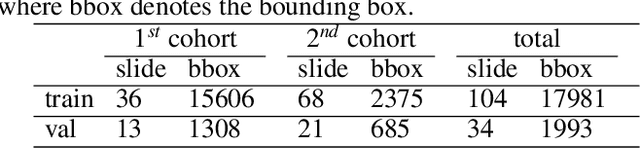
Digital gigapixel whole slide image (WSI) is widely used in clinical diagnosis, and automated WSI analysis is key for computer-aided diagnosis. Currently, analyzing the integrated descriptor of probabilities or feature maps from massive local patches encoded by ResNet classifier is the main manner for WSI-level prediction. Feature representations of the sparse and tiny lesion cells in cervical slides, however, are still challengeable for the under-promoted upstream encoders, while the unused spatial representations of cervical cells are the available features to supply the semantics analysis. As well as patches sampling with overlap and repetitive processing incur the inefficiency and the unpredictable side effect. This study designs a novel inline connection network (InCNet) by enriching the multi-scale connectivity to build the lightweight model named You Only Look Cytopathology Once (YOLCO) with the additional supervision of spatial information. The proposed model allows the input size enlarged to megapixel that can stitch the WSI without any overlap by the average repeats decreased from $10^3\sim10^4$ to $10^1\sim10^2$ for collecting features and predictions at two scales. Based on Transformer for classifying the integrated multi-scale multi-task features, the experimental results appear $0.872$ AUC score better and $2.51\times$ faster than the best conventional method in WSI classification on multicohort datasets of 2,019 slides from four scanning devices.
Learning from Perturbations: Diverse and Informative Dialogue Generation with Inverse Adversarial Training
May 31, 2021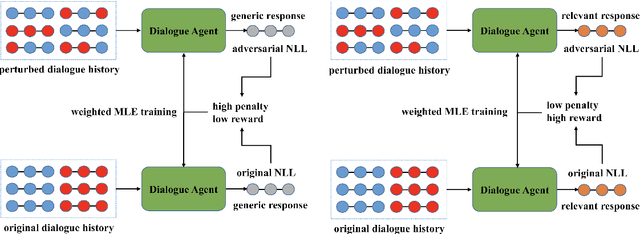
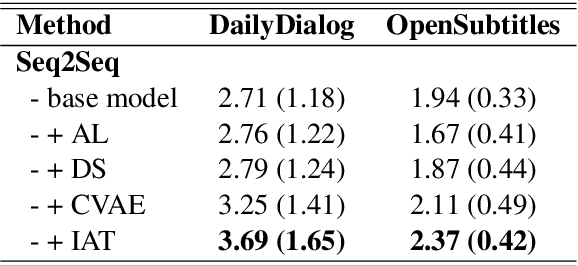
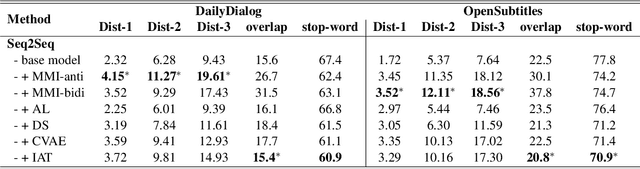
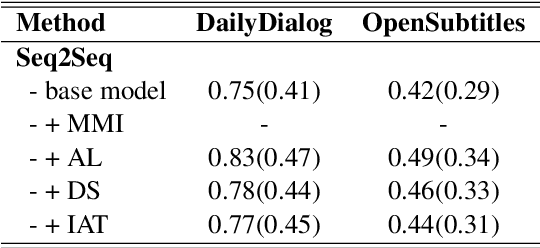
In this paper, we propose Inverse Adversarial Training (IAT) algorithm for training neural dialogue systems to avoid generic responses and model dialogue history better. In contrast to standard adversarial training algorithms, IAT encourages the model to be sensitive to the perturbation in the dialogue history and therefore learning from perturbations. By giving higher rewards for responses whose output probability reduces more significantly when dialogue history is perturbed, the model is encouraged to generate more diverse and consistent responses. By penalizing the model when generating the same response given perturbed dialogue history, the model is forced to better capture dialogue history and generate more informative responses. Experimental results on two benchmark datasets show that our approach can better model dialogue history and generate more diverse and consistent responses. In addition, we point out a problem of the widely used maximum mutual information (MMI) based methods for improving the diversity of dialogue response generation models and demonstrate it empirically.
Hierarchical Lovász Embeddings for Proposal-free Panoptic Segmentation
Jun 08, 2021
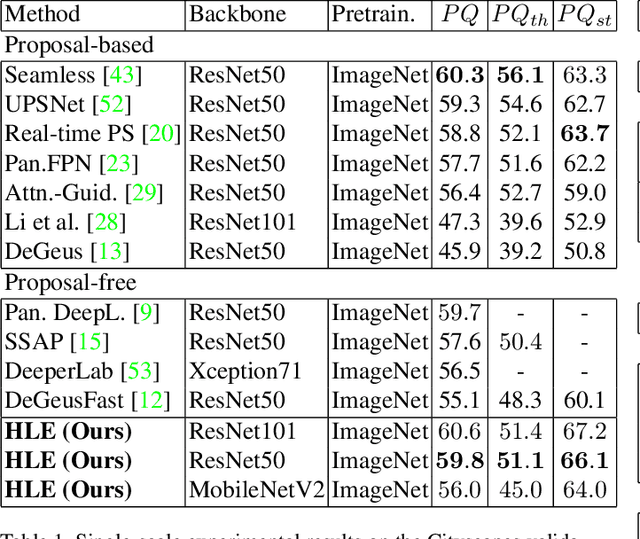
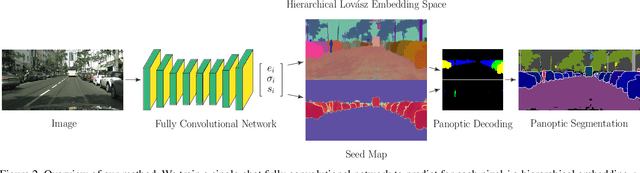

Panoptic segmentation brings together two separate tasks: instance and semantic segmentation. Although they are related, unifying them faces an apparent paradox: how to learn simultaneously instance-specific and category-specific (i.e. instance-agnostic) representations jointly. Hence, state-of-the-art panoptic segmentation methods use complex models with a distinct stream for each task. In contrast, we propose Hierarchical Lov\'asz Embeddings, per pixel feature vectors that simultaneously encode instance- and category-level discriminative information. We use a hierarchical Lov\'asz hinge loss to learn a low-dimensional embedding space structured into a unified semantic and instance hierarchy without requiring separate network branches or object proposals. Besides modeling instances precisely in a proposal-free manner, our Hierarchical Lov\'asz Embeddings generalize to categories by using a simple Nearest-Class-Mean classifier, including for non-instance "stuff" classes where instance segmentation methods are not applicable. Our simple model achieves state-of-the-art results compared to existing proposal-free panoptic segmentation methods on Cityscapes, COCO, and Mapillary Vistas. Furthermore, our model demonstrates temporal stability between video frames.
Picking Pearl From Seabed: Extracting Artefacts from Noisy Issue Triaging Collaborative Conversations for Hybrid Cloud Services
May 31, 2021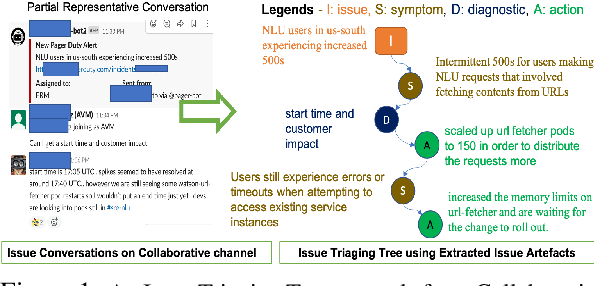
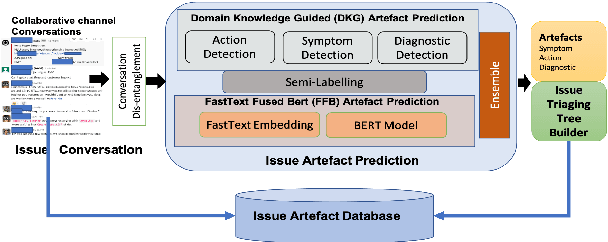
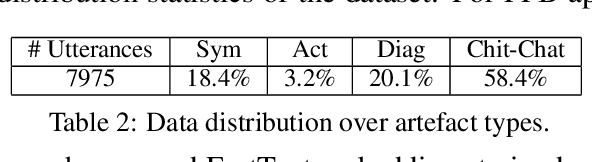
Site Reliability Engineers (SREs) play a key role in issue identification and resolution. After an issue is reported, SREs come together in a virtual room (collaboration platform) to triage the issue. While doing so, they leave behind a wealth of information which can be used later for triaging similar issues. However, usability of the conversations offer challenges due to them being i) noisy and ii) unlabelled. This paper presents a novel approach for issue artefact extraction from the noisy conversations with minimal labelled data. We propose a combination of unsupervised and supervised model with minimum human intervention that leverages domain knowledge to predict artefacts for a small amount of conversation data and use that for fine-tuning an already pretrained language model for artefact prediction on a large amount of conversation data. Experimental results on our dataset show that the proposed ensemble of unsupervised and supervised model is better than using either one of them individually.
Syft 0.5: A Platform for Universally Deployable Structured Transparency
Apr 26, 2021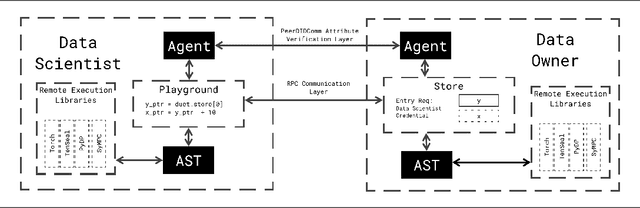
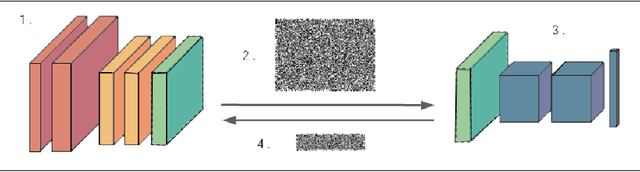
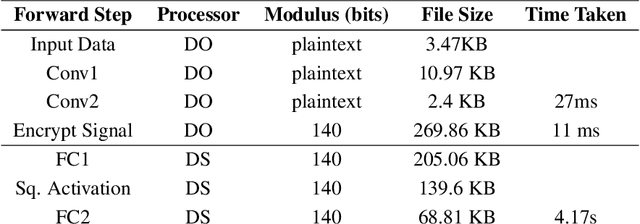
We present Syft, a general-purpose framework that combines a core group of privacy-enhancing technologies that facilitate a universal set of structured transparency systems. This framework is demonstrated through the design and implementation of a novel privacy-preserving inference information flow where we pass homomorphically encrypted activation signals through a split neural network for inference. We show that splitting the model further up the computation chain significantly reduces the computation time of inference and the payload size of activation signals at the cost of model secrecy. We evaluate our proposed flow with respect to its provision of the core structural transparency principles.
Factorising Meaning and Form for Intent-Preserving Paraphrasing
May 31, 2021
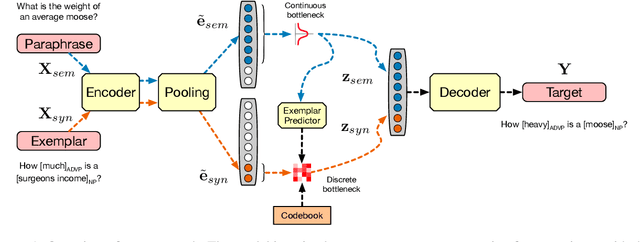

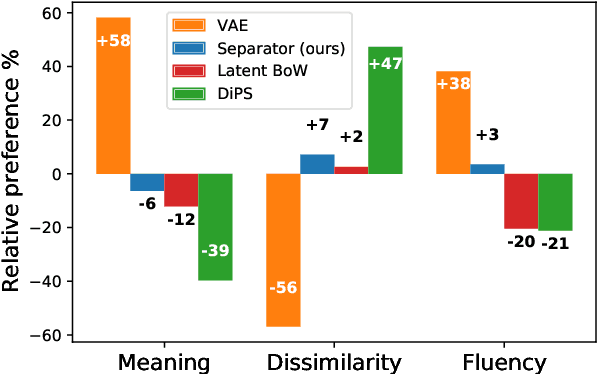
We propose a method for generating paraphrases of English questions that retain the original intent but use a different surface form. Our model combines a careful choice of training objective with a principled information bottleneck, to induce a latent encoding space that disentangles meaning and form. We train an encoder-decoder model to reconstruct a question from a paraphrase with the same meaning and an exemplar with the same surface form, leading to separated encoding spaces. We use a Vector-Quantized Variational Autoencoder to represent the surface form as a set of discrete latent variables, allowing us to use a classifier to select a different surface form at test time. Crucially, our method does not require access to an external source of target exemplars. Extensive experiments and a human evaluation show that we are able to generate paraphrases with a better tradeoff between semantic preservation and syntactic novelty compared to previous methods.
Disambiguatory Signals are Stronger in Word-initial Positions
Feb 03, 2021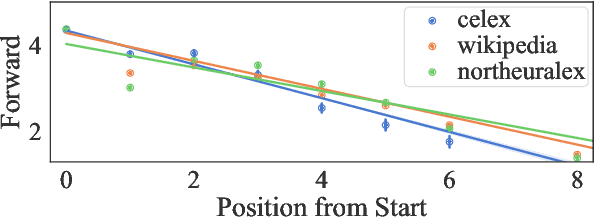
Psycholinguistic studies of human word processing and lexical access provide ample evidence of the preferred nature of word-initial versus word-final segments, e.g., in terms of attention paid by listeners (greater) or the likelihood of reduction by speakers (lower). This has led to the conjecture -- as in Wedel et al. (2019b), but common elsewhere -- that languages have evolved to provide more information earlier in words than later. Information-theoretic methods to establish such tendencies in lexicons have suffered from several methodological shortcomings that leave open the question of whether this high word-initial informativeness is actually a property of the lexicon or simply an artefact of the incremental nature of recognition. In this paper, we point out the confounds in existing methods for comparing the informativeness of segments early in the word versus later in the word, and present several new measures that avoid these confounds. When controlling for these confounds, we still find evidence across hundreds of languages that indeed there is a cross-linguistic tendency to front-load information in words.
Document-level Event Extraction via Heterogeneous Graph-based Interaction Model with a Tracker
May 31, 2021
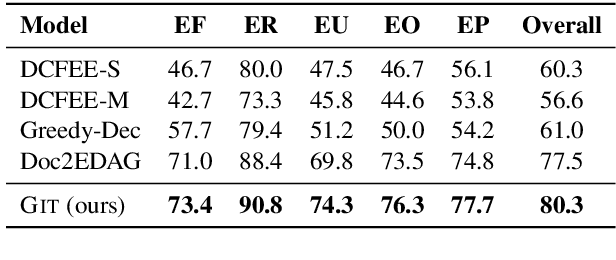
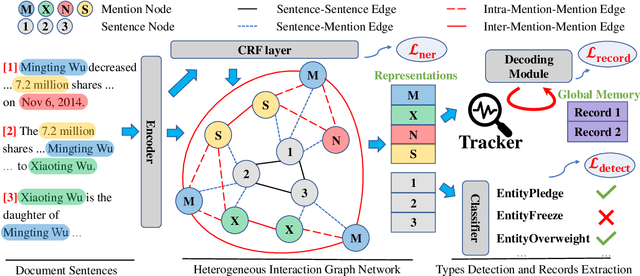

Document-level event extraction aims to recognize event information from a whole piece of article. Existing methods are not effective due to two challenges of this task: a) the target event arguments are scattered across sentences; b) the correlation among events in a document is non-trivial to model. In this paper, we propose Heterogeneous Graph-based Interaction Model with a Tracker (GIT) to solve the aforementioned two challenges. For the first challenge, GIT constructs a heterogeneous graph interaction network to capture global interactions among different sentences and entity mentions. For the second, GIT introduces a Tracker module to track the extracted events and hence capture the interdependency among the events. Experiments on a large-scale dataset (Zheng et al., 2019) show GIT outperforms the previous methods by 2.8 F1. Further analysis reveals GIT is effective in extracting multiple correlated events and event arguments that scatter across the document. Our code is available at https://github.com/RunxinXu/GIT.