 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Benchmarking Modern Named Entity Recognition Techniques for Free-text Health Record De-identification
Mar 25, 2021
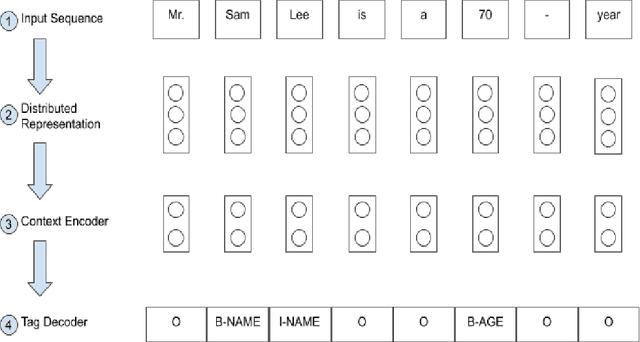
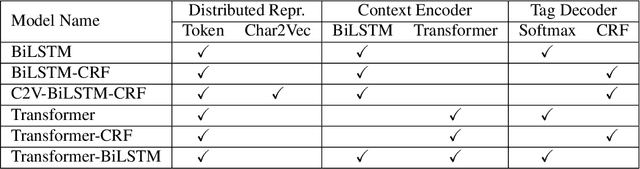
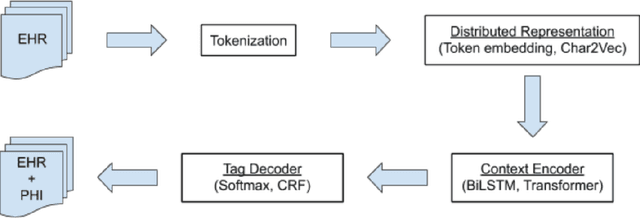
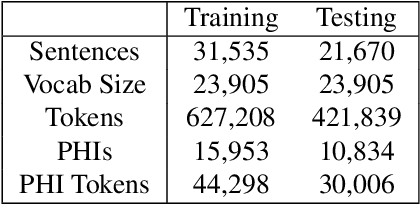
Electronic Health Records (EHRs) have become the primary form of medical data-keeping across the United States. Federal law restricts the sharing of any EHR data that contains protected health information (PHI). De-identification, the process of identifying and removing all PHI, is crucial for making EHR data publicly available for scientific research. This project explores several deep learning-based named entity recognition (NER) methods to determine which method(s) perform better on the de-identification task. We trained and tested our models on the i2b2 training dataset, and qualitatively assessed their performance using EHR data collected from a local hospital. We found that 1) BiLSTM-CRF represents the best-performing encoder/decoder combination, 2) character-embeddings and CRFs tend to improve precision at the price of recall, and 3) transformers alone under-perform as context encoders. Future work focused on structuring medical text may improve the extraction of semantic and syntactic information for the purposes of EHR de-identification.
Boost-R: Gradient Boosted Trees for Recurrence Data
Jul 03, 2021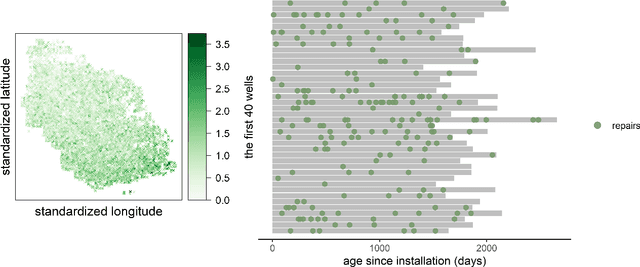
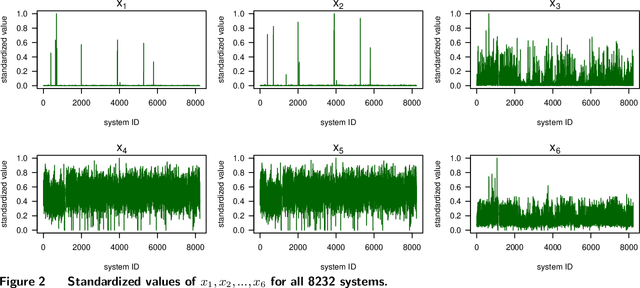
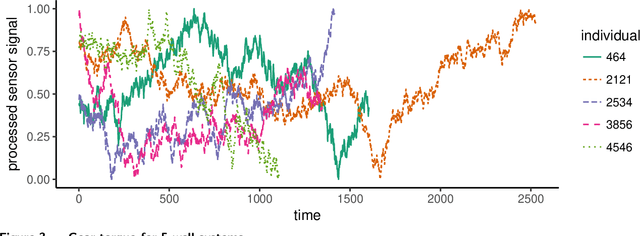
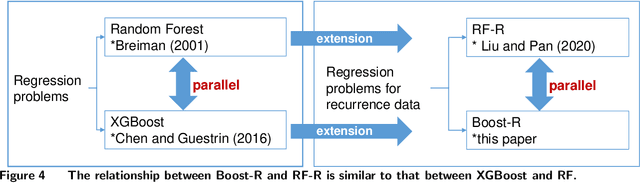
Recurrence data arise from multi-disciplinary domains spanning reliability, cyber security, healthcare, online retailing, etc. This paper investigates an additive-tree-based approach, known as Boost-R (Boosting for Recurrence Data), for recurrent event data with both static and dynamic features. Boost-R constructs an ensemble of gradient boosted additive trees to estimate the cumulative intensity function of the recurrent event process, where a new tree is added to the ensemble by minimizing the regularized L2 distance between the observed and predicted cumulative intensity. Unlike conventional regression trees, a time-dependent function is constructed by Boost-R on each tree leaf. The sum of these functions, from multiple trees, yields the ensemble estimator of the cumulative intensity. The divide-and-conquer nature of tree-based methods is appealing when hidden sub-populations exist within a heterogeneous population. The non-parametric nature of regression trees helps to avoid parametric assumptions on the complex interactions between event processes and features. Critical insights and advantages of Boost-R are investigated through comprehensive numerical examples. Datasets and computer code of Boost-R are made available on GitHub. To our best knowledge, Boost-R is the first gradient boosted additive-tree-based approach for modeling large-scale recurrent event data with both static and dynamic feature information.
Automatic Description Construction for Math Expression via Topic Relation Graph
Apr 24, 2021
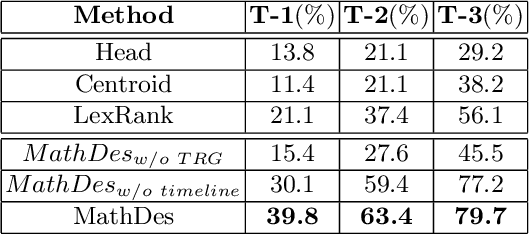
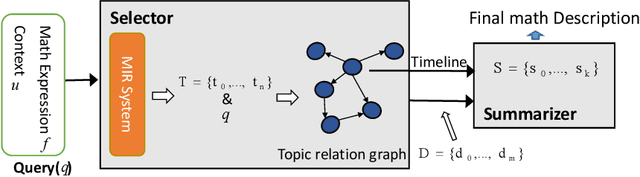
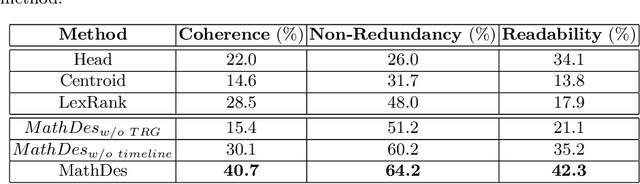
Math expressions are important parts of scientific and educational documents, but some of them may be challenging for junior scholars or students to understand. Nevertheless, constructing textual descriptions for math expressions is nontrivial. In this paper, we explore the feasibility to automatically construct descriptions for math expressions. But there are two challenges that need to be addressed: 1) finding relevant documents since a math equation understanding usually requires several topics, but these topics are often explained in different documents. 2) the sparsity of the collected relevant documents making it difficult to extract reasonable descriptions. Different documents mainly focus on different topics which makes model hard to extract salient information and organize them to form a description of math expressions. To address these issues, we propose a hybrid model (MathDes) which contains two important modules: Selector and Summarizer. In the Selector, a Topic Relation Graph (TRG) is proposed to obtain the relevant documents which contain the comprehensive information of math expressions. TRG is a graph built according to the citations between expressions. In the Summarizer, a summarization model under the Integer Linear Programming (ILP) framework is proposed. This module constructs the final description with the help of a timeline that is extracted from TRG. The experimental results demonstrate that our methods are promising for this task and outperform the baselines in all aspects.
Sequential Naive Learning
Jan 08, 2021We analyze boundedly rational updating from aggregate statistics in a model with binary actions and binary states. Agents each take an irreversible action in sequence after observing the unordered set of previous actions. Each agent first forms her prior based on the aggregate statistic, then incorporates her signal with the prior based on Bayes rule, and finally applies a decision rule that assigns a (mixed) action to each belief. If priors are formed according to a discretized DeGroot rule, then actions converge to the state (in probability), i.e., \emph{asymptotic learning}, in any informative information structure if and only if the decision rule satisfies probability matching. This result generalizes to unspecified information settings where information structures differ across agents and agents know only the information structure generating their own signal. Also, the main result extends to the case of $n$ states and $n$ actions.
Learning Invariant Representation with Consistency and Diversity for Semi-supervised Source Hypothesis Transfer
Jul 20, 2021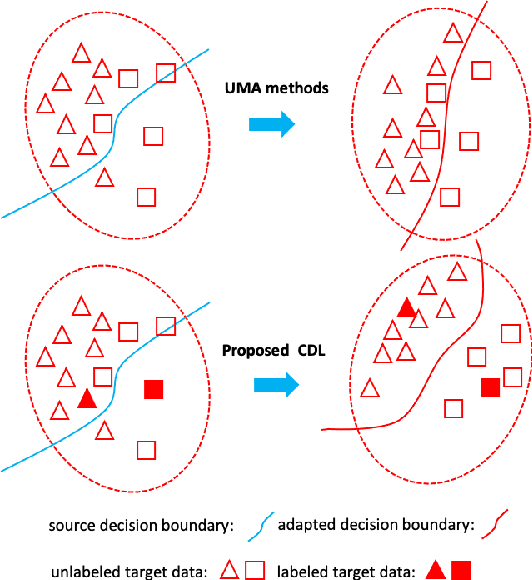

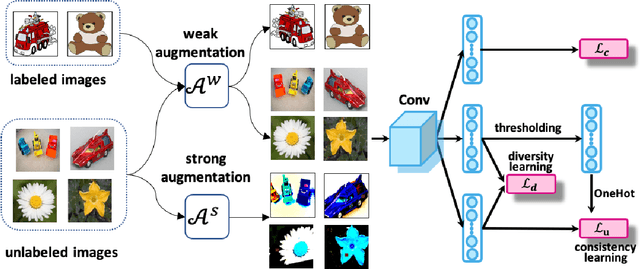
Semi-supervised domain adaptation (SSDA) aims to solve tasks in target domain by utilizing transferable information learned from the available source domain and a few labeled target data. However, source data is not always accessible in practical scenarios, which restricts the application of SSDA in real world circumstances. In this paper, we propose a novel task named Semi-supervised Source Hypothesis Transfer (SSHT), which performs domain adaptation based on source trained model, to generalize well in target domain with a few supervisions. In SSHT, we are facing two challenges: (1) The insufficient labeled target data may result in target features near the decision boundary, with the increased risk of mis-classification; (2) The data are usually imbalanced in source domain, so the model trained with these data is biased. The biased model is prone to categorize samples of minority categories into majority ones, resulting in low prediction diversity. To tackle the above issues, we propose Consistency and Diversity Learning (CDL), a simple but effective framework for SSHT by facilitating prediction consistency between two randomly augmented unlabeled data and maintaining the prediction diversity when adapting model to target domain. Encouraging consistency regularization brings difficulty to memorize the few labeled target data and thus enhances the generalization ability of the learned model. We further integrate Batch Nuclear-norm Maximization into our method to enhance the discriminability and diversity. Experimental results show that our method outperforms existing SSDA methods and unsupervised model adaptation methods on DomainNet, Office-Home and Office-31 datasets. The code is available at https://github.com/Wang-xd1899/SSHT.
COSINE: Compressive Network Embedding on Large-scale Information Networks
Dec 21, 2018
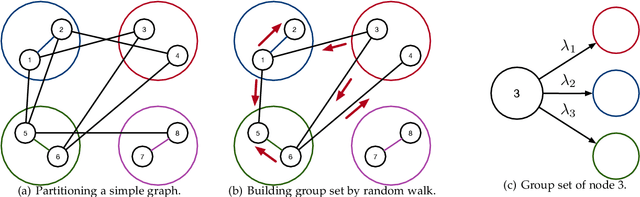
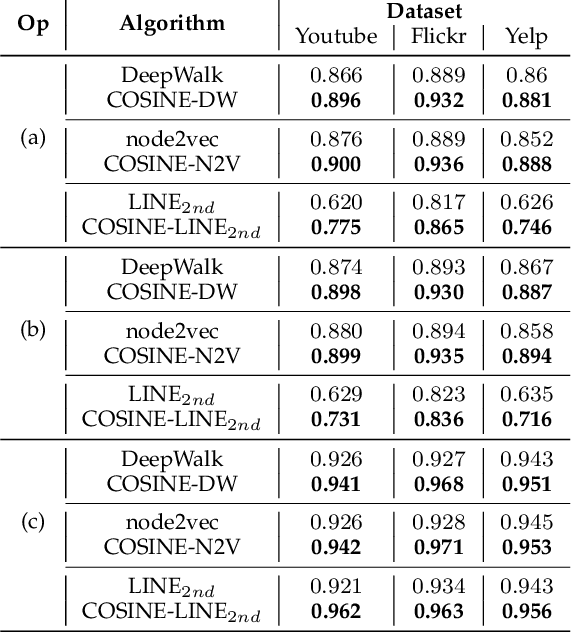
There is recently a surge in approaches that learn low-dimensional embeddings of nodes in networks. As there are many large-scale real-world networks, it's inefficient for existing approaches to store amounts of parameters in memory and update them edge after edge. With the knowledge that nodes having similar neighborhood will be close to each other in embedding space, we propose COSINE (COmpresSIve NE) algorithm which reduces the memory footprint and accelerates the training process by parameters sharing among similar nodes. COSINE applies graph partitioning algorithms to networks and builds parameter sharing dependency of nodes based on the result of partitioning. With parameters sharing among similar nodes, COSINE injects prior knowledge about higher structural information into training process which makes network embedding more efficient and effective. COSINE can be applied to any embedding lookup method and learn high-quality embeddings with limited memory and shorter training time. We conduct experiments of multi-label classification and link prediction, where baselines and our model have the same memory usage. Experimental results show that COSINE gives baselines up to 23% increase on classification and up to 25% increase on link prediction. Moreover, time of all representation learning methods using COSINE decreases from 30% to 70%.
Neural Abstractive Unsupervised Summarization of Online News Discussions
Jun 19, 2021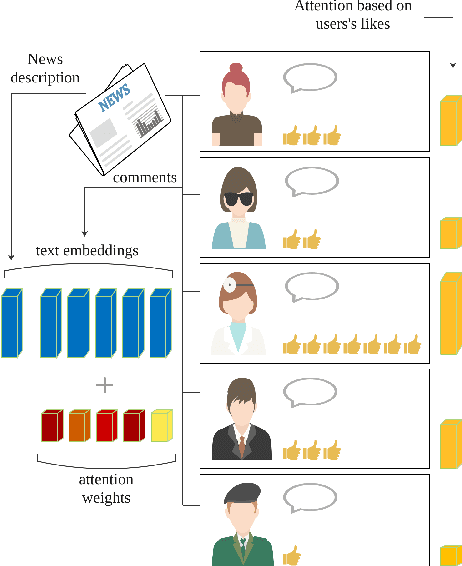
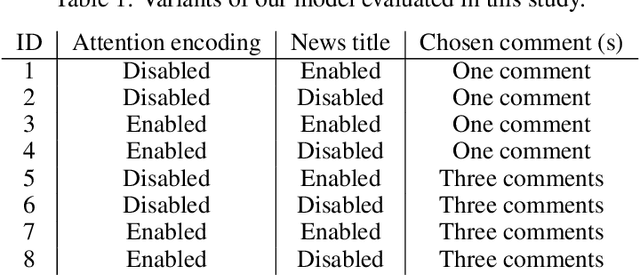
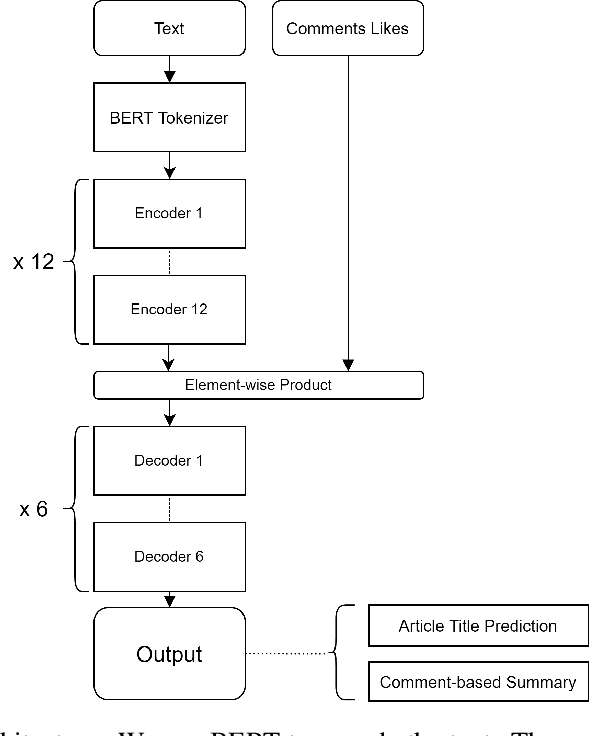
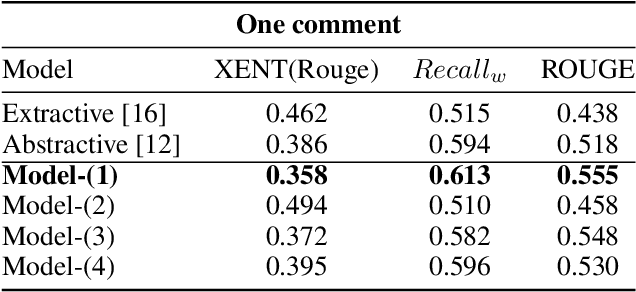
Summarization has usually relied on gold standard summaries to train extractive or abstractive models. Social media brings a hurdle to summarization techniques since it requires addressing a multi-document multi-author approach. We address this challenging task by introducing a novel method that generates abstractive summaries of online news discussions. Our method extends a BERT-based architecture, including an attention encoding that fed comments' likes during the training stage. To train our model, we define a task which consists of reconstructing high impact comments based on popularity (likes). Accordingly, our model learns to summarize online discussions based on their most relevant comments. Our novel approach provides a summary that represents the most relevant aspects of a news item that users comment on, incorporating the social context as a source of information to summarize texts in online social networks. Our model is evaluated using ROUGE scores between the generated summary and each comment on the thread. Our model, including the social attention encoding, significantly outperforms both extractive and abstractive summarization methods based on such evaluation.
Toward Subject Invariant and Class Disentangled Representation in BCI via Cross-Domain Mutual Information Estimator
Oct 18, 2019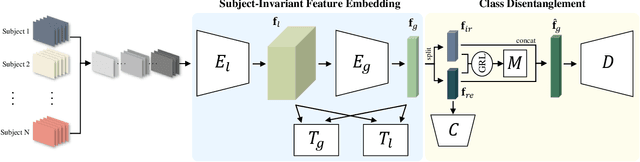
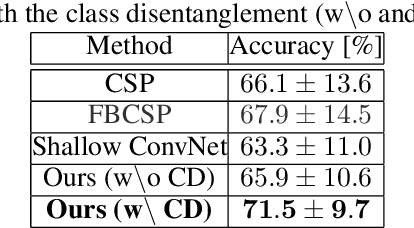
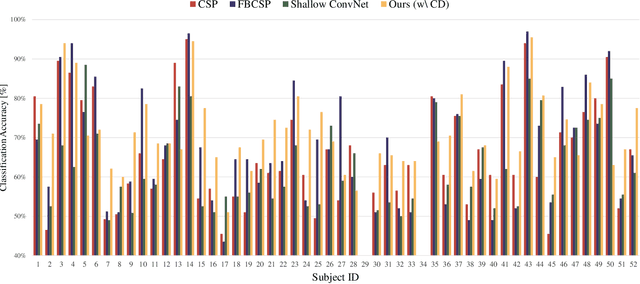

In recent, deep learning-based feature representation methods have shown a promising impact in electroencephalography (EEG)-based brain-computer interface (BCI). Nonetheless, due to high intra- and inter-subject variabilities, many studies on decoding EEG were designed in a subject-specific manner by using calibration samples, with no much concern on its less practical, time-consuming, and data-hungry process. To tackle this problem, recent studies took advantage of transfer learning, especially using domain adaptation techniques. However, there still remain two challenging limitations; i) most domain adaptation methods are designed for labeled source and unlabeled target domain whereas BCI tasks generally have multiple annotated domains. ii) most of the methods do not consider negatively transferable to disrupt generalization ability. In this paper, we propose a novel network architecture to tackle those limitations by estimating mutual information in high-level representation and low-level representation, separately. Specifically, our proposed method extracts domain-invariant and class-relevant features, thereby enhancing generalizability in classification across. It is also noteworthy that our method can be applicable to a new subject with a small amount of data via a fine-tuning, step only, reducing calibration time for practical uses. We validated our proposed method on a big motor imagery EEG dataset by showing promising results, compared to competing methods considered in our experiments.
Do All MobileNets Quantize Poorly? Gaining Insights into the Effect of Quantization on Depthwise Separable Convolutional Networks Through the Eyes of Multi-scale Distributional Dynamics
Apr 24, 2021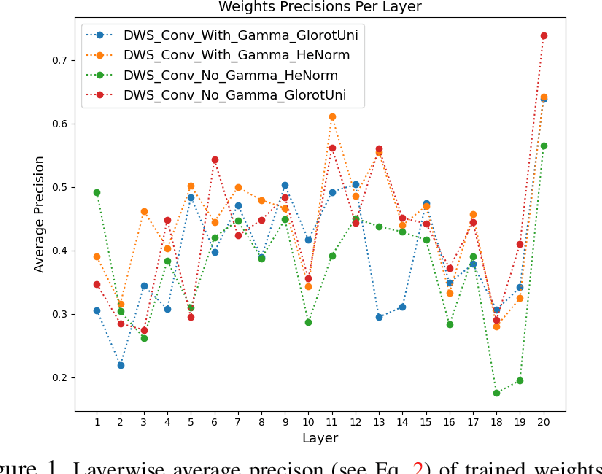
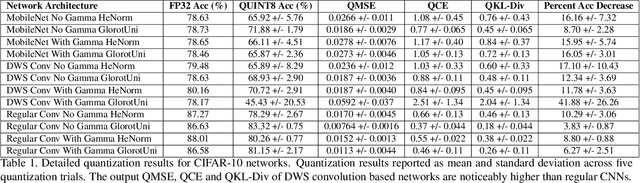
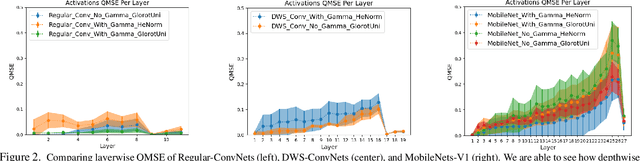

As the "Mobile AI" revolution continues to grow, so does the need to understand the behaviour of edge-deployed deep neural networks. In particular, MobileNets are the go-to family of deep convolutional neural networks (CNN) for mobile. However, they often have significant accuracy degradation under post-training quantization. While studies have introduced quantization-aware training and other methods to tackle this challenge, there is limited understanding into why MobileNets (and potentially depthwise-separable CNNs (DWSCNN) in general) quantize so poorly compared to other CNN architectures. Motivated to gain deeper insights into this phenomenon, we take a different strategy and study the multi-scale distributional dynamics of MobileNet-V1, a set of smaller DWSCNNs, and regular CNNs. Specifically, we investigate the impact of quantization on the weight and activation distributional dynamics as information propagates from layer to layer, as well as overall changes in distributional dynamics at the network level. This fine-grained analysis revealed significant dynamic range fluctuations and a "distributional mismatch" between channelwise and layerwise distributions in DWSCNNs that lead to increasing quantized degradation and distributional shift during information propagation. Furthermore, analysis of the activation quantization errors show that there is greater quantization error accumulation in DWSCNN compared to regular CNNs. The hope is that such insights can lead to innovative strategies for reducing such distributional dynamics changes and improve post-training quantization for mobile.
Scalable Teacher Forcing Network for Semi-Supervised Large Scale Data Streams
Jun 26, 2021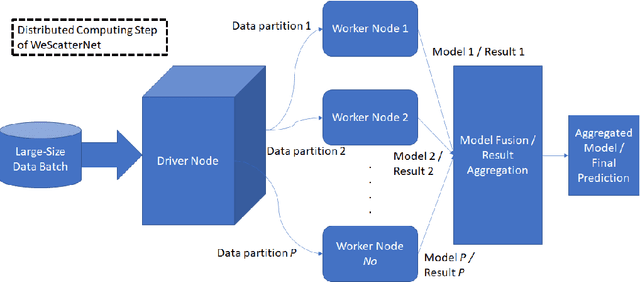
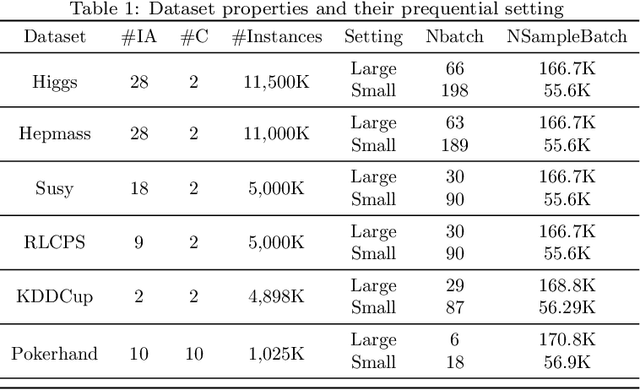
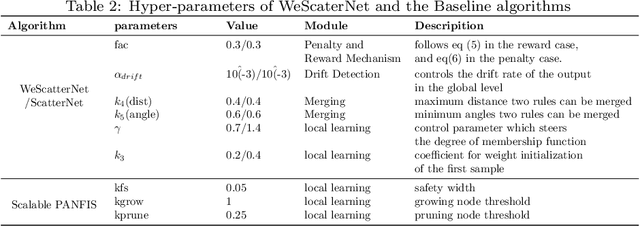
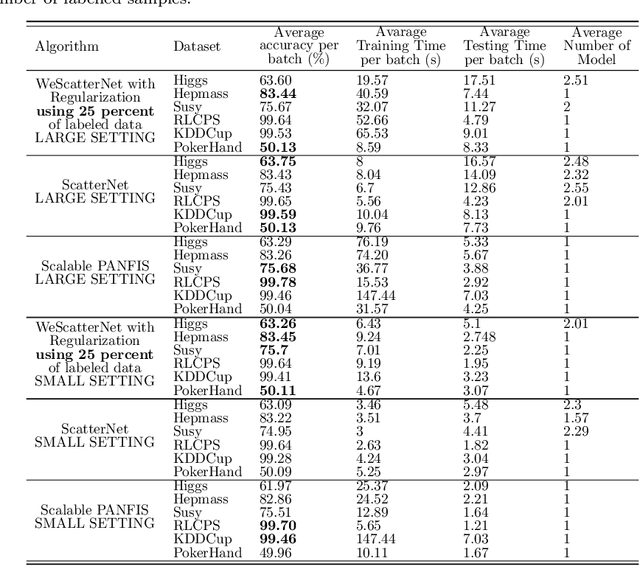
The large-scale data stream problem refers to high-speed information flow which cannot be processed in scalable manner under a traditional computing platform. This problem also imposes expensive labelling cost making the deployment of fully supervised algorithms unfeasible. On the other hand, the problem of semi-supervised large-scale data streams is little explored in the literature because most works are designed in the traditional single-node computing environments while also being fully supervised approaches. This paper offers Weakly Supervised Scalable Teacher Forcing Network (WeScatterNet) to cope with the scarcity of labelled samples and the large-scale data streams simultaneously. WeScatterNet is crafted under distributed computing platform of Apache Spark with a data-free model fusion strategy for model compression after parallel computing stage. It features an open network structure to address the global and local drift problems while integrating a data augmentation, annotation and auto-correction ($DA^3$) method for handling partially labelled data streams. The performance of WeScatterNet is numerically evaluated in the six large-scale data stream problems with only $25\%$ label proportions. It shows highly competitive performance even if compared with fully supervised learners with $100\%$ label proportions.
* This paper has been accepted for publication in Information Sciences