 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarting Positions Matter: A Study on Better Weight Initialization for Neural Network Quantization
Jun 12, 2025



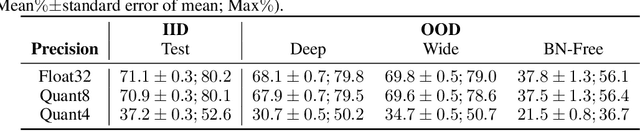
Deep neural network (DNN) quantization for fast, efficient inference has been an important tool in limiting the cost of machine learning (ML) model inference. Quantization-specific model development techniques such as regularization, quantization-aware training, and quantization-robustness penalties have served to greatly boost the accuracy and robustness of modern DNNs. However, very little exploration has been done on improving the initial conditions of DNN training for quantization. Just as random weight initialization has been shown to significantly impact test accuracy of floating point models, it would make sense that different weight initialization methods impact quantization robustness of trained models. We present an extensive study examining the effects of different weight initializations on a variety of CNN building blocks commonly used in efficient CNNs. This analysis reveals that even with varying CNN architectures, the choice of random weight initializer can significantly affect final quantization robustness. Next, we explore a new method for quantization-robust CNN initialization -- using Graph Hypernetworks (GHN) to predict parameters of quantized DNNs. Besides showing that GHN-predicted parameters are quantization-robust after regular float32 pretraining (of the GHN), we find that finetuning GHNs to predict parameters for quantized graphs (which we call GHN-QAT) can further improve quantized accuracy of CNNs. Notably, GHN-QAT shows significant accuracy improvements for even 4-bit quantization and better-than-random accuracy for 2-bits. To the best of our knowledge, this is the first in-depth study on quantization-aware DNN weight initialization. GHN-QAT offers a novel approach to quantized DNN model design. Future investigations, such as using GHN-QAT-initialized parameters for quantization-aware training, can further streamline the DNN quantization process.
GHN-QAT: Training Graph Hypernetworks to Predict Quantization-Robust Parameters of Unseen Limited Precision Neural Networks
Sep 24, 2023Graph Hypernetworks (GHN) can predict the parameters of varying unseen CNN architectures with surprisingly good accuracy at a fraction of the cost of iterative optimization. Following these successes, preliminary research has explored the use of GHNs to predict quantization-robust parameters for 8-bit and 4-bit quantized CNNs. However, this early work leveraged full-precision float32 training and only quantized for testing. We explore the impact of quantization-aware training and/or other quantization-based training strategies on quantized robustness and performance of GHN predicted parameters for low-precision CNNs. We show that quantization-aware training can significantly improve quantized accuracy for GHN predicted parameters of 4-bit quantized CNNs and even lead to greater-than-random accuracy for 2-bit quantized CNNs. These promising results open the door for future explorations such as investigating the use of GHN predicted parameters as initialization for further quantized training of individual CNNs, further exploration of "extreme bitwidth" quantization, and mixed precision quantization schemes.
GHN-Q: Parameter Prediction for Unseen Quantized Convolutional Architectures via Graph Hypernetworks
Aug 26, 2022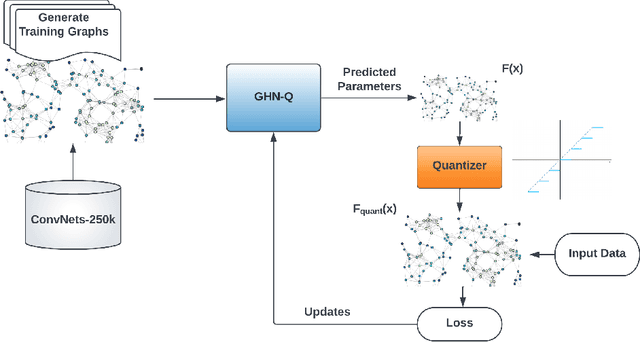
Deep convolutional neural network (CNN) training via iterative optimization has had incredible success in finding optimal parameters. However, modern CNN architectures often contain millions of parameters. Thus, any given model for a single architecture resides in a massive parameter space. Models with similar loss could have drastically different characteristics such as adversarial robustness, generalizability, and quantization robustness. For deep learning on the edge, quantization robustness is often crucial. Finding a model that is quantization-robust can sometimes require significant efforts. Recent works using Graph Hypernetworks (GHN) have shown remarkable performance predicting high-performant parameters of varying CNN architectures. Inspired by these successes, we wonder if the graph representations of GHN-2 can be leveraged to predict quantization-robust parameters as well, which we call GHN-Q. We conduct the first-ever study exploring the use of graph hypernetworks for predicting parameters of unseen quantized CNN architectures. We focus on a reduced CNN search space and find that GHN-Q can in fact predict quantization-robust parameters for various 8-bit quantized CNNs. Decent quantized accuracies are observed even with 4-bit quantization despite GHN-Q not being trained on it. Quantized finetuning of GHN-Q at lower bitwidths may bring further improvements and is currently being explored.
Reproducing BowNet: Learning Representations by Predicting Bags of Visual Words
Jan 14, 2022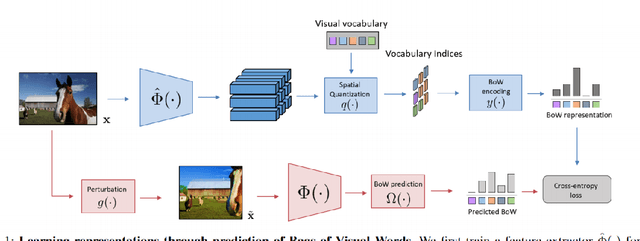
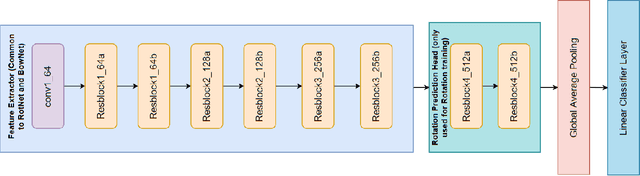
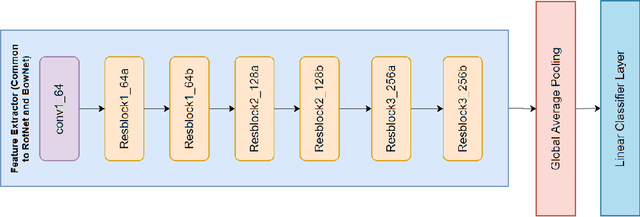
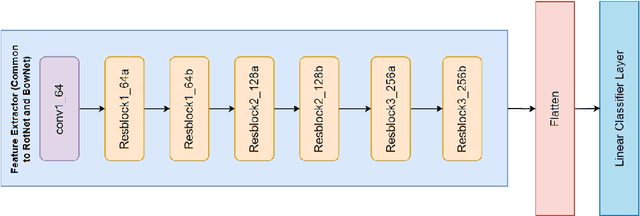
This work aims to reproduce results from the CVPR 2020 paper by Gidaris et al. Self-supervised learning (SSL) is used to learn feature representations of an image using an unlabeled dataset. This work proposes to use bag-of-words (BoW) deep feature descriptors as a self-supervised learning target to learn robust, deep representations. BowNet is trained to reconstruct the histogram of visual words (ie. the deep BoW descriptor) of a reference image when presented a perturbed version of the image as input. Thus, this method aims to learn perturbation-invariant and context-aware image features that can be useful for few-shot tasks or supervised downstream tasks. In the paper, the author describes BowNet as a network consisting of a convolutional feature extractor $\Phi(\cdot)$ and a Dense-softmax layer $\Omega(\cdot)$ trained to predict BoW features from images. After BoW training, the features of $\Phi$ are used in downstream tasks. For this challenge we were trying to build and train a network that could reproduce the CIFAR-100 accuracy improvements reported in the original paper. However, we were unsuccessful in reproducing an accuracy improvement comparable to what the authors mentioned. This could be for a variety of factors and we believe that time constraints were the primary bottleneck.
Do All MobileNets Quantize Poorly? Gaining Insights into the Effect of Quantization on Depthwise Separable Convolutional Networks Through the Eyes of Multi-scale Distributional Dynamics
Apr 24, 2021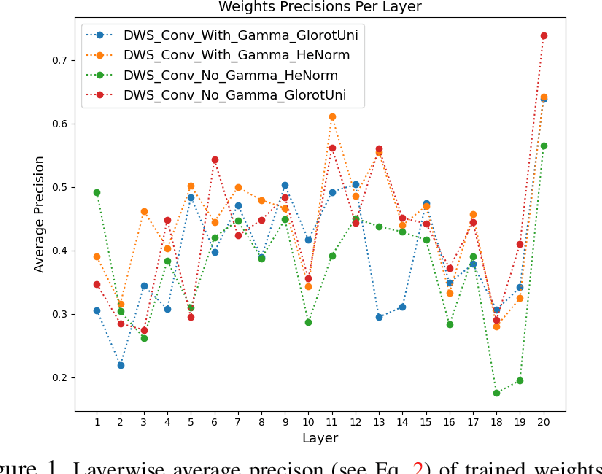
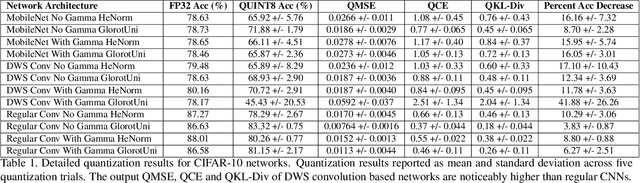
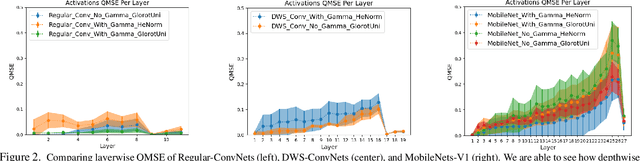

As the "Mobile AI" revolution continues to grow, so does the need to understand the behaviour of edge-deployed deep neural networks. In particular, MobileNets are the go-to family of deep convolutional neural networks (CNN) for mobile. However, they often have significant accuracy degradation under post-training quantization. While studies have introduced quantization-aware training and other methods to tackle this challenge, there is limited understanding into why MobileNets (and potentially depthwise-separable CNNs (DWSCNN) in general) quantize so poorly compared to other CNN architectures. Motivated to gain deeper insights into this phenomenon, we take a different strategy and study the multi-scale distributional dynamics of MobileNet-V1, a set of smaller DWSCNNs, and regular CNNs. Specifically, we investigate the impact of quantization on the weight and activation distributional dynamics as information propagates from layer to layer, as well as overall changes in distributional dynamics at the network level. This fine-grained analysis revealed significant dynamic range fluctuations and a "distributional mismatch" between channelwise and layerwise distributions in DWSCNNs that lead to increasing quantized degradation and distributional shift during information propagation. Furthermore, analysis of the activation quantization errors show that there is greater quantization error accumulation in DWSCNN compared to regular CNNs. The hope is that such insights can lead to innovative strategies for reducing such distributional dynamics changes and improve post-training quantization for mobile.
FactorizeNet: Progressive Depth Factorization for Efficient Network Architecture Exploration Under Quantization Constraints
Nov 30, 2020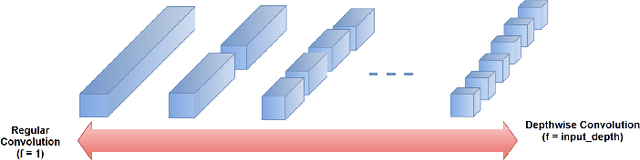
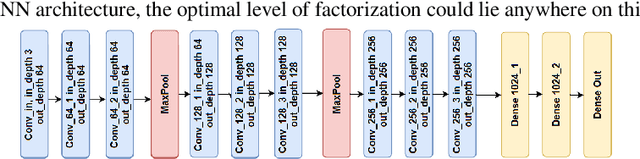
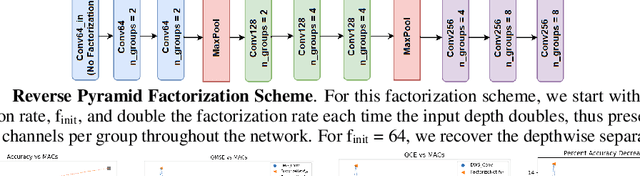
Depth factorization and quantization have emerged as two of the principal strategies for designing efficient deep convolutional neural network (CNN) architectures tailored for low-power inference on the edge. However, there is still little detailed understanding of how different depth factorization choices affect the final, trained distributions of each layer in a CNN, particularly in the situation of quantized weights and activations. In this study, we introduce a progressive depth factorization strategy for efficient CNN architecture exploration under quantization constraints. By algorithmically increasing the granularity of depth factorization in a progressive manner, the proposed strategy enables a fine-grained, low-level analysis of layer-wise distributions. Thus enabling the gain of in-depth, layer-level insights on efficiency-accuracy tradeoffs under fixed-precision quantization. Such a progressive depth factorization strategy also enables efficient identification of the optimal depth-factorized macroarchitecture design (which we will refer to here as FactorizeNet) based on the desired efficiency-accuracy requirements.
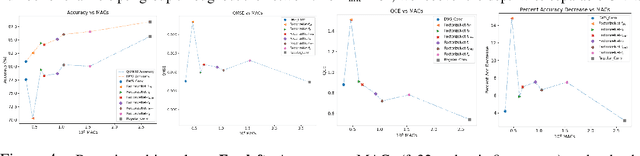
Where Should We Begin? A Low-Level Exploration of Weight Initialization Impact on Quantized Behaviour of Deep Neural Networks
Nov 30, 2020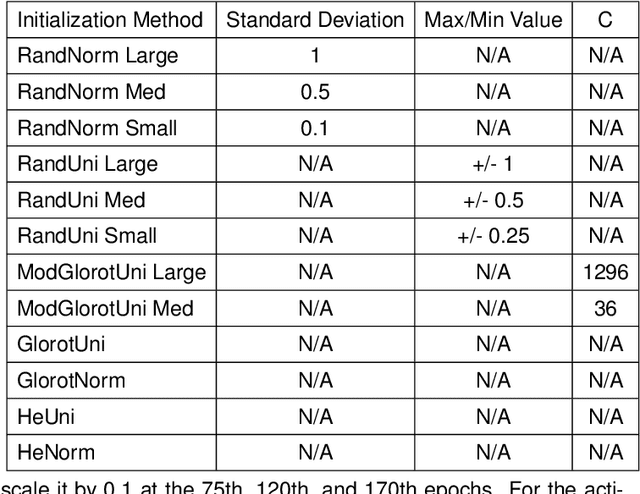
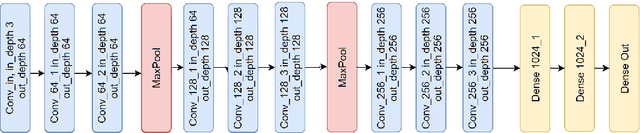
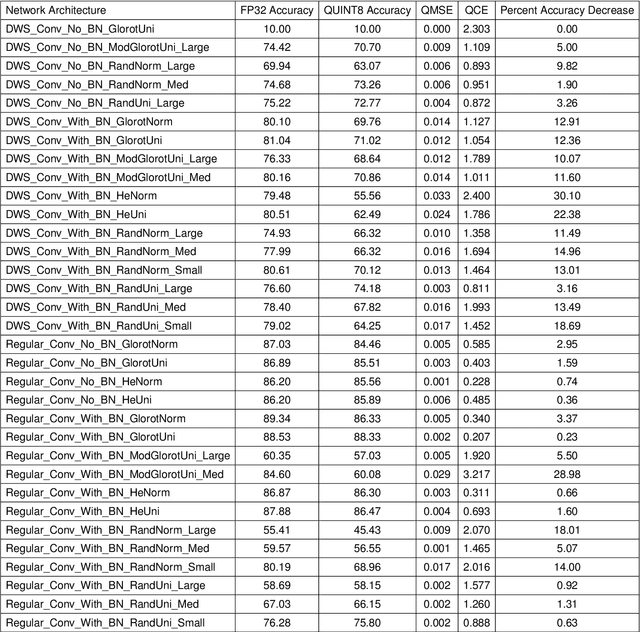
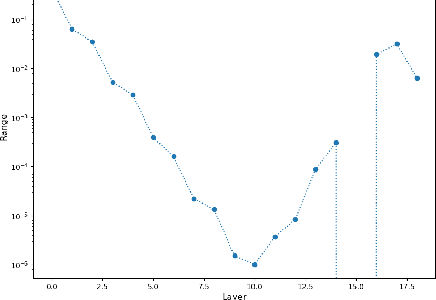
With the proliferation of deep convolutional neural network (CNN) algorithms for mobile processing, limited precision quantization has become an essential tool for CNN efficiency. Consequently, various works have sought to design fixed precision quantization algorithms and quantization-focused optimization techniques that minimize quantization induced performance degradation. However, there is little concrete understanding of how various CNN design decisions/best practices affect quantized inference behaviour. Weight initialization strategies are often associated with solving issues such as vanishing/exploding gradients but an often-overlooked aspect is their impact on the final trained distributions of each layer. We present an in-depth, fine-grained ablation study of the effect of different weights initializations on the final distributions of weights and activations of different CNN architectures. The fine-grained, layerwise analysis enables us to gain deep insights on how initial weights distributions will affect final accuracy and quantized behaviour. To our best knowledge, we are the first to perform such a low-level, in-depth quantitative analysis of weights initialization and its effect on quantized behaviour.