 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Conversational Diagnostic AI with Multimodal Reasoning
May 06, 2025



Large Language Models (LLMs) have demonstrated great potential for conducting diagnostic conversations but evaluation has been largely limited to language-only interactions, deviating from the real-world requirements of remote care delivery. Instant messaging platforms permit clinicians and patients to upload and discuss multimodal medical artifacts seamlessly in medical consultation, but the ability of LLMs to reason over such data while preserving other attributes of competent diagnostic conversation remains unknown. Here we advance the conversational diagnosis and management performance of the Articulate Medical Intelligence Explorer (AMIE) through a new capability to gather and interpret multimodal data, and reason about this precisely during consultations. Leveraging Gemini 2.0 Flash, our system implements a state-aware dialogue framework, where conversation flow is dynamically controlled by intermediate model outputs reflecting patient states and evolving diagnoses. Follow-up questions are strategically directed by uncertainty in such patient states, leading to a more structured multimodal history-taking process that emulates experienced clinicians. We compared AMIE to primary care physicians (PCPs) in a randomized, blinded, OSCE-style study of chat-based consultations with patient actors. We constructed 105 evaluation scenarios using artifacts like smartphone skin photos, ECGs, and PDFs of clinical documents across diverse conditions and demographics. Our rubric assessed multimodal capabilities and other clinically meaningful axes like history-taking, diagnostic accuracy, management reasoning, communication, and empathy. Specialist evaluation showed AMIE to be superior to PCPs on 7/9 multimodal and 29/32 non-multimodal axes (including diagnostic accuracy). The results show clear progress in multimodal conversational diagnostic AI, but real-world translation needs further research.
Benchmarking Modern Named Entity Recognition Techniques for Free-text Health Record De-identification
Mar 25, 2021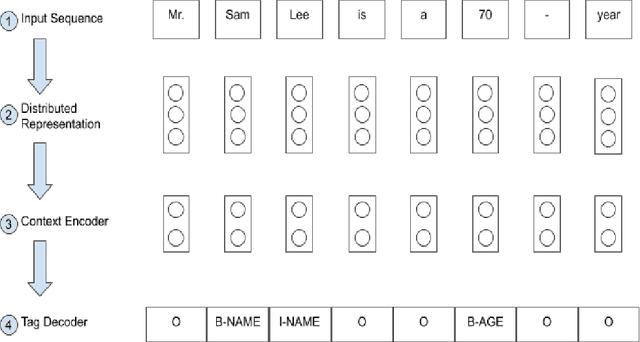
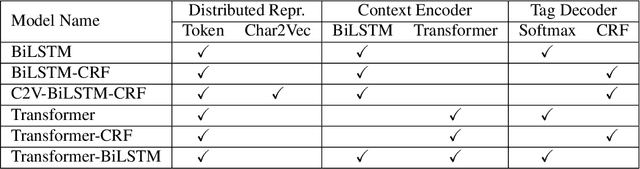
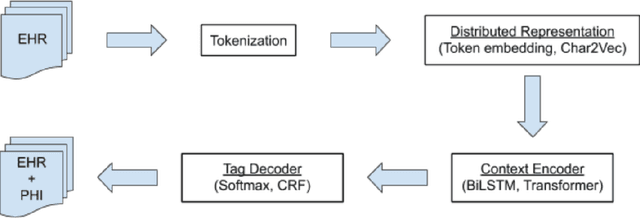
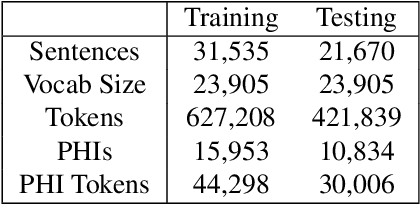
Electronic Health Records (EHRs) have become the primary form of medical data-keeping across the United States. Federal law restricts the sharing of any EHR data that contains protected health information (PHI). De-identification, the process of identifying and removing all PHI, is crucial for making EHR data publicly available for scientific research. This project explores several deep learning-based named entity recognition (NER) methods to determine which method(s) perform better on the de-identification task. We trained and tested our models on the i2b2 training dataset, and qualitatively assessed their performance using EHR data collected from a local hospital. We found that 1) BiLSTM-CRF represents the best-performing encoder/decoder combination, 2) character-embeddings and CRFs tend to improve precision at the price of recall, and 3) transformers alone under-perform as context encoders. Future work focused on structuring medical text may improve the extraction of semantic and syntactic information for the purposes of EHR de-identification.