 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Quantifying the Impact of Human Capital, Job History, and Language Factors on Job Seniority with a Large-scale Analysis of Resumes
Jun 15, 2021

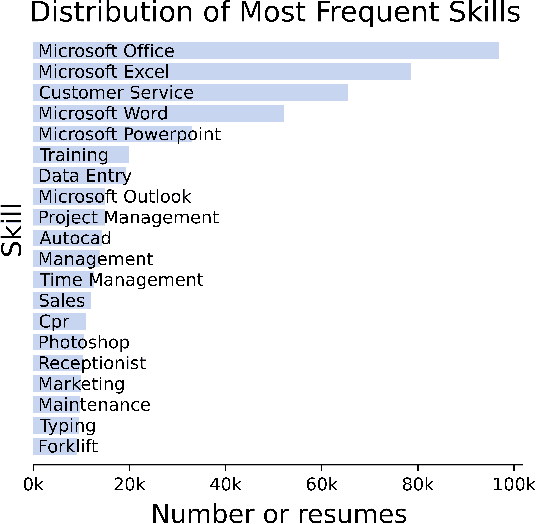
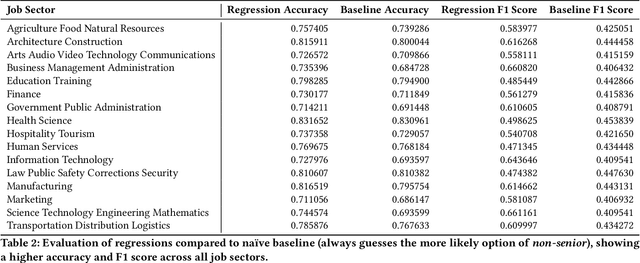
As job markets worldwide have become more competitive and applicant selection criteria have become more opaque, and different (and sometimes contradictory) information and advice is available for job seekers wishing to progress in their careers, it has never been more difficult to determine which factors in a r\'esum\'e most effectively help career progression. In this work we present a novel, large scale dataset of over half a million r\'esum\'es with preliminary analysis to begin to answer empirically which factors help or hurt people wishing to transition to more senior roles as they progress in their career. We find that previous experience forms the most important factor, outweighing other aspects of human capital, and find which language factors in a r\'esum\'e have significant effects. This lays the groundwork for future inquiry in career trajectories using large scale data analysis and natural language processing techniques.
ASK: Adversarial Soft k-Nearest Neighbor Attack and Defense
Jun 27, 2021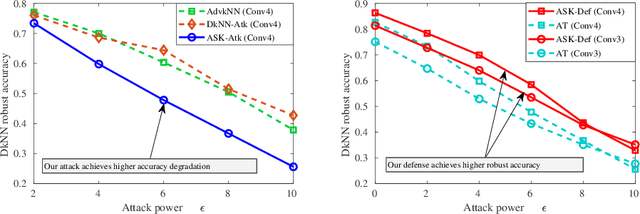
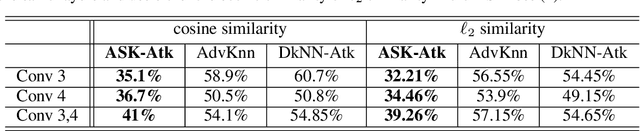

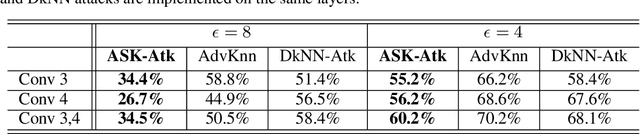
K-Nearest Neighbor (kNN)-based deep learning methods have been applied to many applications due to their simplicity and geometric interpretability. However, the robustness of kNN-based classification models has not been thoroughly explored and kNN attack strategies are underdeveloped. In this paper, we propose an Adversarial Soft kNN (ASK) loss to both design more effective kNN attack strategies and to develop better defenses against them. Our ASK loss approach has two advantages. First, ASK loss can better approximate the kNN's probability of classification error than objectives proposed in previous works. Second, the ASK loss is interpretable: it preserves the mutual information between the perturbed input and the kNN of the unperturbed input. We use the ASK loss to generate a novel attack method called the ASK-Attack (ASK-Atk), which shows superior attack efficiency and accuracy degradation relative to previous kNN attacks. Based on the ASK-Atk, we then derive an ASK-Defense (ASK-Def) method that optimizes the worst-case training loss induced by ASK-Atk.
Printed Texts Tracking and Following for a Finger-Wearable Electro-Braille System Through Opto-electrotactile Feedback
Aug 06, 2021This paper presents our recent development on a portable and refreshable text reading and sensory substitution system for the blind or visually impaired (BVI), called Finger-eye. The system mainly consists of an opto-text processing unit and a compact electro-tactile based display that can deliver text-related electrical signals to the fingertip skin through a wearable and Braille-dot patterned electrode array and thus delivers the electro-stimulation based Braille touch sensations to the fingertip. To achieve the goal of aiding BVI to read any text not written in Braille through this portable system, in this work, a Rapid Optical Character Recognition (R-OCR) method is firstly developed for real-time processing text information based on a Fisheye imaging device mounted at the finger-wearable electro-tactile display. This allows real-time translation of printed text to electro-Braille along with natural movement of user's fingertip as if reading any Braille display or book. More importantly, an electro-tactile neuro-stimulation feedback mechanism is proposed and incorporated with the R-OCR method, which facilitates a new opto-electrotactile feedback based text line tracking control approach that enables text line following by user fingertip during reading. Multiple experiments were designed and conducted to test the ability of blindfolded participants to read through and follow the text line based on the opto-electrotactile-feedback method. The experiments show that as the result of the opto-electrotactile-feedback, the users were able to maintain their fingertip within a $2mm$ distance of the text while scanning a text line. This research is a significant step to aid the BVI users with a portable means to translate and follow to read any printed text to Braille, whether in the digital realm or physically, on any surface.
Question Answering Infused Pre-training of General-Purpose Contextualized Representations
Jun 15, 2021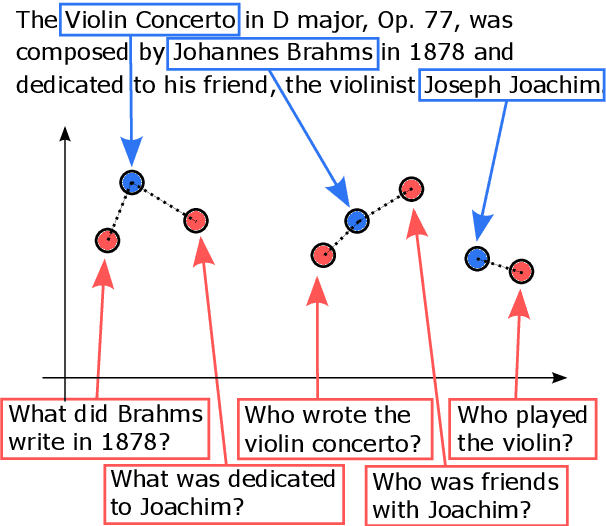
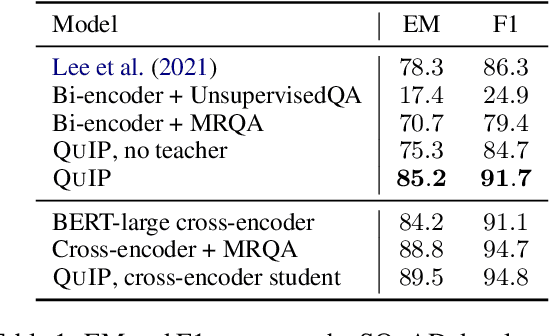
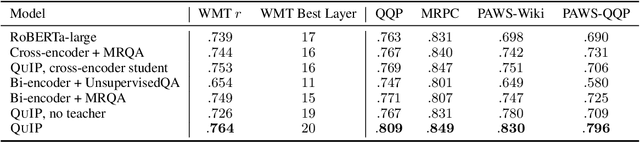
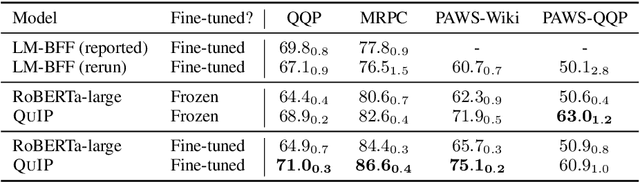
This paper proposes a pre-training objective based on question answering (QA) for learning general-purpose contextual representations, motivated by the intuition that the representation of a phrase in a passage should encode all questions that the phrase can answer in context. We accomplish this goal by training a bi-encoder QA model, which independently encodes passages and questions, to match the predictions of a more accurate cross-encoder model on 80 million synthesized QA pairs. By encoding QA-relevant information, the bi-encoder's token-level representations are useful for non-QA downstream tasks without extensive (or in some cases, any) fine-tuning. We show large improvements over both RoBERTa-large and previous state-of-the-art results on zero-shot and few-shot paraphrase detection on four datasets, few-shot named entity recognition on two datasets, and zero-shot sentiment analysis on three datasets.
Language Understanding for Field and Service Robots in a Priori Unknown Environments
May 21, 2021
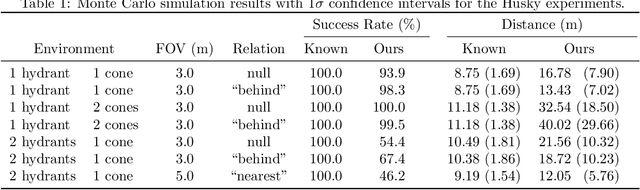

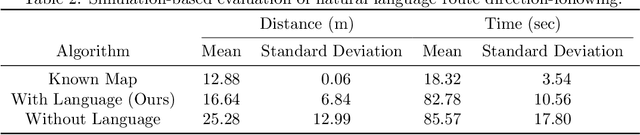
Contemporary approaches to perception, planning, estimation, and control have allowed robots to operate robustly as our remote surrogates in uncertain, unstructured environments. There is now an opportunity for robots to operate not only in isolation, but also with and alongside humans in our complex environments. Natural language provides an efficient and flexible medium through which humans can communicate with collaborative robots. Through significant progress in statistical methods for natural language understanding, robots are now able to interpret a diverse array of free-form navigation, manipulation, and mobile manipulation commands. However, most contemporary approaches require a detailed prior spatial-semantic map of the robot's environment that models the space of possible referents of the utterance. Consequently, these methods fail when robots are deployed in new, previously unknown, or partially observed environments, particularly when mental models of the environment differ between the human operator and the robot. This paper provides a comprehensive description of a novel learning framework that allows field and service robots to interpret and correctly execute natural language instructions in a priori unknown, unstructured environments. Integral to our approach is its use of language as a "sensor" -- inferring spatial, topological, and semantic information implicit in natural language utterances and then exploiting this information to learn a distribution over a latent environment model. We incorporate this distribution in a probabilistic language grounding model and infer a distribution over a symbolic representation of the robot's action space. We use imitation learning to identify a belief space policy that reasons over the environment and behavior distributions. We evaluate our framework through a variety of different navigation and mobile manipulation experiments.
Multi Point-Voxel Convolution (MPVConv) for Deep Learning on Point Clouds
Jul 28, 2021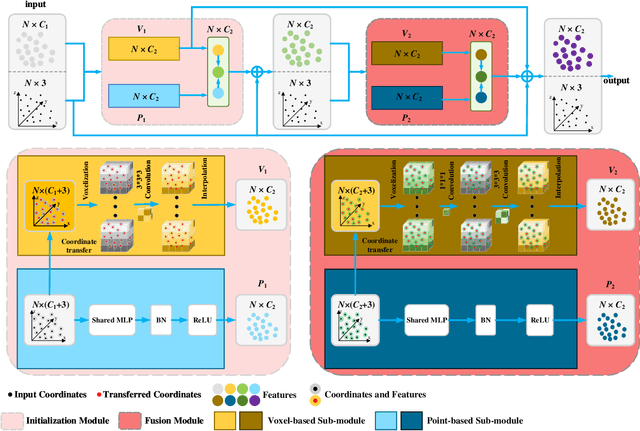



The existing 3D deep learning methods adopt either individual point-based features or local-neighboring voxel-based features, and demonstrate great potential for processing 3D data. However, the point based models are inefficient due to the unordered nature of point clouds and the voxel-based models suffer from large information loss. Motivated by the success of recent point-voxel representation, such as PVCNN, we propose a new convolutional neural network, called Multi Point-Voxel Convolution (MPVConv), for deep learning on point clouds. Integrating both the advantages of voxel and point-based methods, MPVConv can effectively increase the neighboring collection between point-based features and also promote independence among voxel-based features. Moreover, most of the existing approaches aim at solving one specific task, and only a few of them can handle a variety of tasks. Simply replacing the corresponding convolution module with MPVConv, we show that MPVConv can fit in different backbones to solve a wide range of 3D tasks. Extensive experiments on benchmark datasets such as ShapeNet Part, S3DIS and KITTI for various tasks show that MPVConv improves the accuracy of the backbone (PointNet) by up to \textbf{36\%}, and achieves higher accuracy than the voxel-based model with up to \textbf{34}$\times$ speedups. In addition, MPVConv outperforms the state-of-the-art point-based models with up to \textbf{8}$\times$ speedups. Notably, our MPVConv achieves better accuracy than the newest point-voxel-based model PVCNN (a model more efficient than PointNet) with lower latency.
Privacy Assessment of Federated Learning using Private Personalized Layers
Jun 15, 2021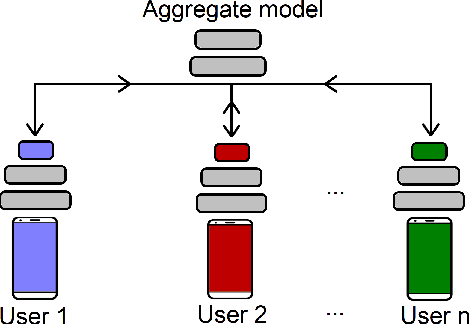
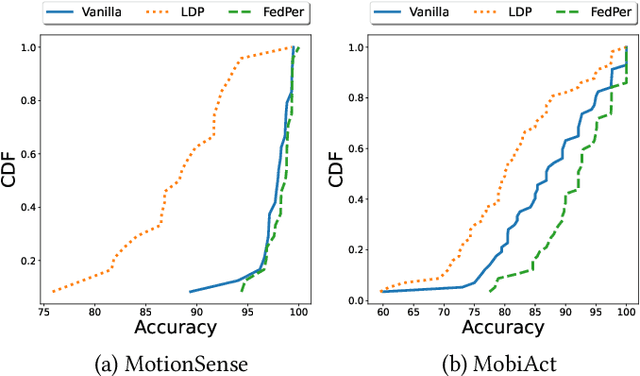
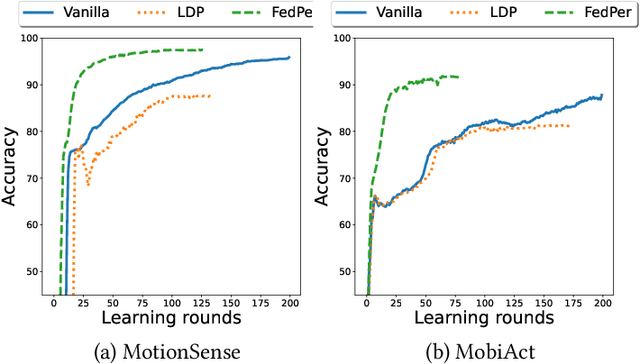
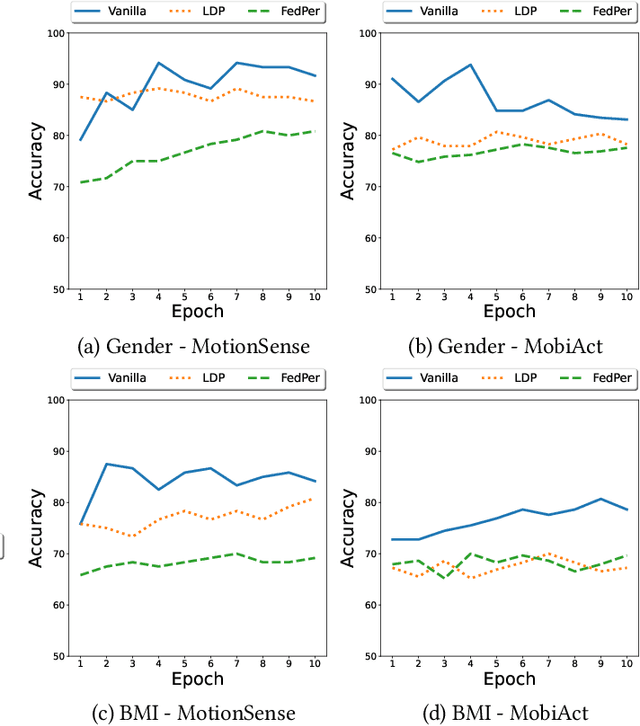
Federated Learning (FL) is a collaborative scheme to train a learning model across multiple participants without sharing data. While FL is a clear step forward towards enforcing users' privacy, different inference attacks have been developed. In this paper, we quantify the utility and privacy trade-off of a FL scheme using private personalized layers. While this scheme has been proposed as local adaptation to improve the accuracy of the model through local personalization, it has also the advantage to minimize the information about the model exchanged with the server. However, the privacy of such a scheme has never been quantified. Our evaluations using motion sensor dataset show that personalized layers speed up the convergence of the model and slightly improve the accuracy for all users compared to a standard FL scheme while better preventing both attribute and membership inferences compared to a FL scheme using local differential privacy.
UVIP: Model-Free Approach to Evaluate Reinforcement Learning Algorithms
Jun 01, 2021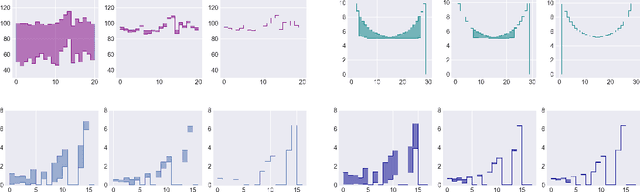
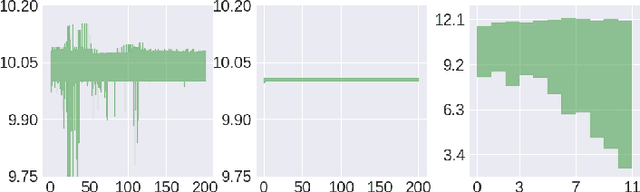
Policy evaluation is an important instrument for the comparison of different algorithms in Reinforcement Learning (RL). Yet even a precise knowledge of the value function $V^{\pi}$ corresponding to a policy $\pi$ does not provide reliable information on how far is the policy $\pi$ from the optimal one. We present a novel model-free upper value iteration procedure $({\sf UVIP})$ that allows us to estimate the suboptimality gap $V^{\star}(x) - V^{\pi}(x)$ from above and to construct confidence intervals for $V^\star$. Our approach relies on upper bounds to the solution of the Bellman optimality equation via martingale approach. We provide theoretical guarantees for ${\sf UVIP}$ under general assumptions and illustrate its performance on a number of benchmark RL problems.
EADNet: Efficient Asymmetric Dilated Network for Semantic Segmentation
Mar 16, 2021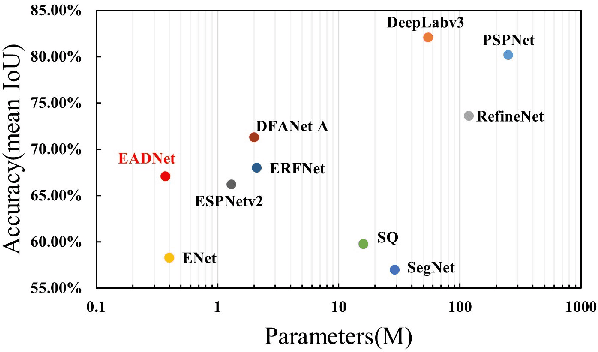
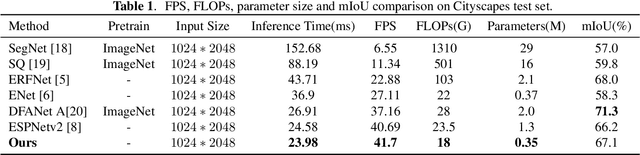
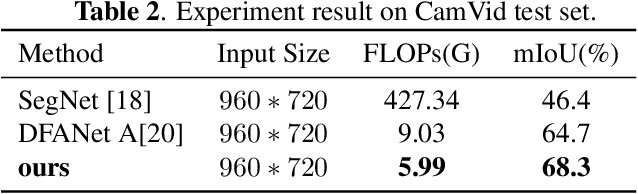
Due to real-time image semantic segmentation needs on power constrained edge devices, there has been an increasing desire to design lightweight semantic segmentation neural network, to simultaneously reduce computational cost and increase inference speed. In this paper, we propose an efficient asymmetric dilated semantic segmentation network, named EADNet, which consists of multiple developed asymmetric convolution branches with different dilation rates to capture the variable shapes and scales information of an image. Specially, a multi-scale multi-shape receptive field convolution (MMRFC) block with only a few parameters is designed to capture such information. Experimental results on the Cityscapes dataset demonstrate that our proposed EADNet achieves segmentation mIoU of 67.1 with smallest number of parameters (only 0.35M) among mainstream lightweight semantic segmentation networks.
Disambiguating Affective Stimulus Associations for Robot Perception and Dialogue
Mar 05, 2021

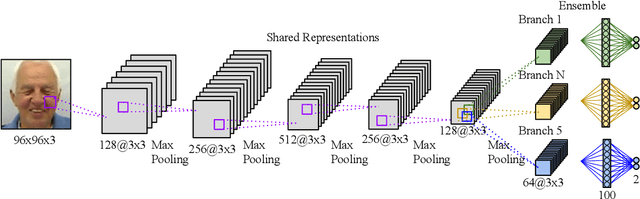
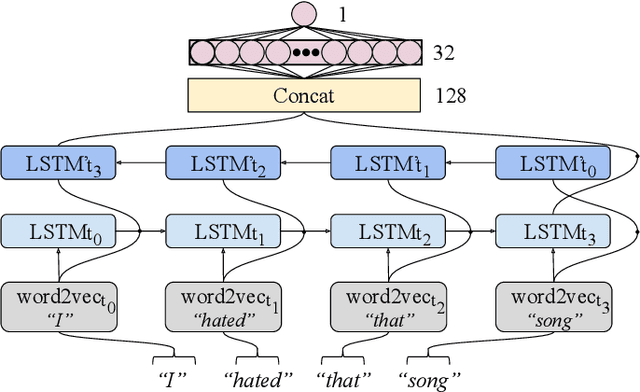
Effectively recognising and applying emotions to interactions is a highly desirable trait for social robots. Implicitly understanding how subjects experience different kinds of actions and objects in the world is crucial for natural HRI interactions, with the possibility to perform positive actions and avoid negative actions. In this paper, we utilize the NICO robot's appearance and capabilities to give the NICO the ability to model a coherent affective association between a perceived auditory stimulus and a temporally asynchronous emotion expression. This is done by combining evaluations of emotional valence from vision and language. NICO uses this information to make decisions about when to extend conversations in order to accrue more affective information if the representation of the association is not coherent. Our primary contribution is providing a NICO robot with the ability to learn the affective associations between a perceived auditory stimulus and an emotional expression. NICO is able to do this for both individual subjects and specific stimuli, with the aid of an emotion-driven dialogue system that rectifies emotional expression incoherences. The robot is then able to use this information to determine a subject's enjoyment of perceived auditory stimuli in a real HRI scenario.