 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Iris Presentation Attack Detection by Attention-based and Deep Pixel-wise Binary Supervision Network
Jun 28, 2021
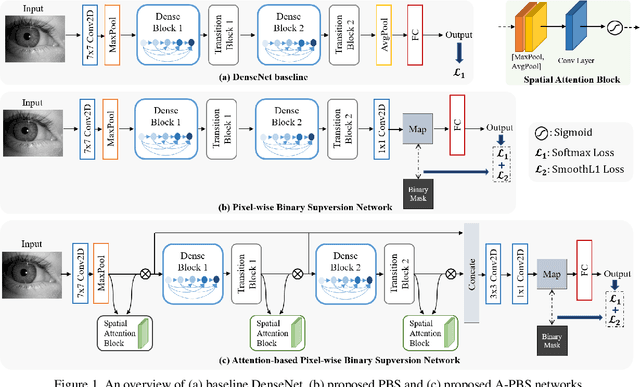
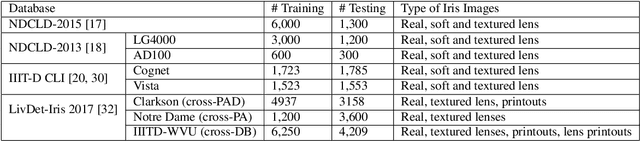
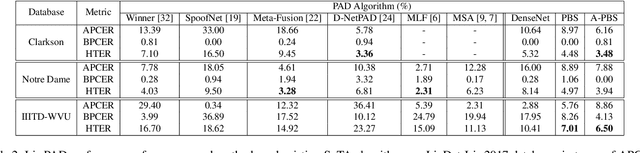
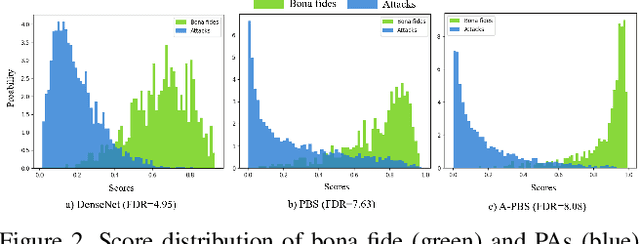
Iris presentation attack detection (PAD) plays a vital role in iris recognition systems. Most existing CNN-based iris PAD solutions 1) perform only binary label supervision during the training of CNNs, serving global information learning but weakening the capture of local discriminative features, 2) prefer the stacked deeper convolutions or expert-designed networks, raising the risk of overfitting, 3) fuse multiple PAD systems or various types of features, increasing difficulty for deployment on mobile devices. Hence, we propose a novel attention-based deep pixel-wise binary supervision (A-PBS) method. Pixel-wise supervision is first able to capture the fine-grained pixel/patch-level cues. Then, the attention mechanism guides the network to automatically find regions that most contribute to an accurate PAD decision. Extensive experiments are performed on LivDet-Iris 2017 and three other publicly available databases to show the effectiveness and robustness of proposed A-PBS methods. For instance, the A-PBS model achieves an HTER of 6.50% on the IIITD-WVU database outperforming state-of-the-art methods.
Fast Crack Detection Using Convolutional Neural Network
May 23, 2021



To improve the efficiency and reduce the labour cost of the renovation process, this study presents a lightweight Convolutional Neural Network (CNN)-based architecture to extract crack-like features, such as cracks and joints. Moreover, Transfer Learning (TF) method was used to save training time while offering comparable prediction results. For three different objectives: 1) Detection of the concrete cracks; 2) Detection of natural stone cracks; 3) Differentiation between joints and cracks in natural stone; We built a natural stone dataset with joints and cracks information as complementary for the concrete benchmark dataset. As the results show, our model is demonstrated as an effective tool for industry use.
Shape or Texture: Understanding Discriminative Features in CNNs
Jan 27, 2021
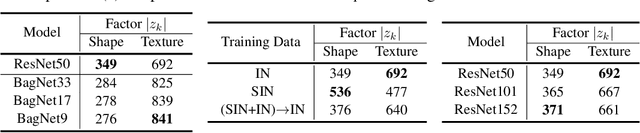
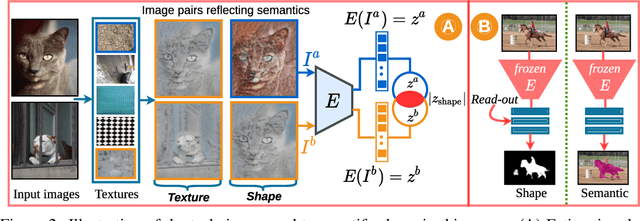
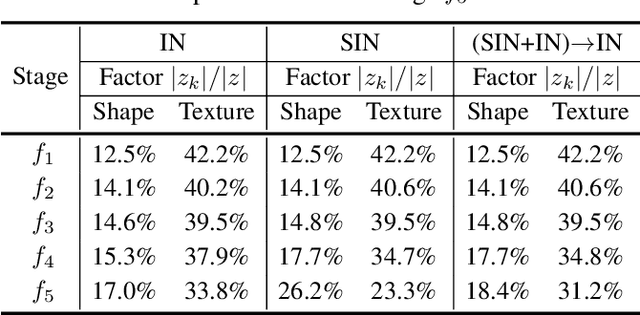
Contrasting the previous evidence that neurons in the later layers of a Convolutional Neural Network (CNN) respond to complex object shapes, recent studies have shown that CNNs actually exhibit a `texture bias': given an image with both texture and shape cues (e.g., a stylized image), a CNN is biased towards predicting the category corresponding to the texture. However, these previous studies conduct experiments on the final classification output of the network, and fail to robustly evaluate the bias contained (i) in the latent representations, and (ii) on a per-pixel level. In this paper, we design a series of experiments that overcome these issues. We do this with the goal of better understanding what type of shape information contained in the network is discriminative, where shape information is encoded, as well as when the network learns about object shape during training. We show that a network learns the majority of overall shape information at the first few epochs of training and that this information is largely encoded in the last few layers of a CNN. Finally, we show that the encoding of shape does not imply the encoding of localized per-pixel semantic information. The experimental results and findings provide a more accurate understanding of the behaviour of current CNNs, thus helping to inform future design choices.
ProtoTransformer: A Meta-Learning Approach to Providing Student Feedback
Jul 23, 2021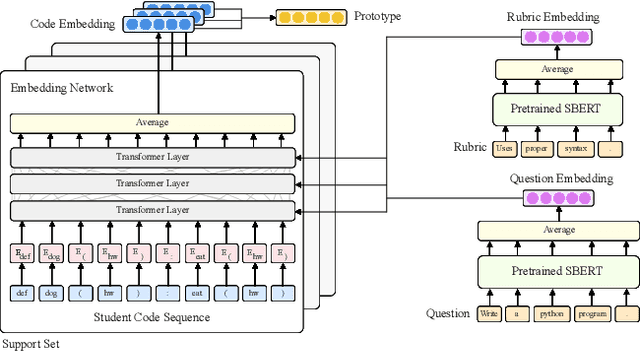



High-quality computer science education is limited by the difficulty of providing instructor feedback to students at scale. While this feedback could in principle be automated, supervised approaches to predicting the correct feedback are bottlenecked by the intractability of annotating large quantities of student code. In this paper, we instead frame the problem of providing feedback as few-shot classification, where a meta-learner adapts to give feedback to student code on a new programming question from just a few examples annotated by instructors. Because data for meta-training is limited, we propose a number of amendments to the typical few-shot learning framework, including task augmentation to create synthetic tasks, and additional side information to build stronger priors about each task. These additions are combined with a transformer architecture to embed discrete sequences (e.g. code) to a prototypical representation of a feedback class label. On a suite of few-shot natural language processing tasks, we match or outperform state-of-the-art performance. Then, on a collection of student solutions to exam questions from an introductory university course, we show that our approach reaches an average precision of 88% on unseen questions, surpassing the 82% precision of teaching assistants. Our approach was successfully deployed to deliver feedback to 16,000 student exam-solutions in a programming course offered by a tier 1 university. This is, to the best of our knowledge, the first successful deployment of a machine learning based feedback to open-ended student code.
High-dimensional distributed semantic spaces for utterances
Apr 01, 2021High-dimensional distributed semantic spaces have proven useful and effective for aggregating and processing visual, auditory, and lexical information for many tasks related to human-generated data. Human language makes use of a large and varying number of features, lexical and constructional items as well as contextual and discourse-specific data of various types, which all interact to represent various aspects of communicative information. Some of these features are mostly local and useful for the organisation of e.g. argument structure of a predication; others are persistent over the course of a discourse and necessary for achieving a reasonable level of understanding of the content. This paper describes a model for high-dimensional representation for utterance and text level data including features such as constructions or contextual data, based on a mathematically principled and behaviourally plausible approach to representing linguistic information. The implementation of the representation is a straightforward extension of Random Indexing models previously used for lexical linguistic items. The paper shows how the implemented model is able to represent a broad range of linguistic features in a common integral framework of fixed dimensionality, which is computationally habitable, and which is suitable as a bridge between symbolic representations such as dependency analysis and continuous representations used e.g. in classifiers or further machine-learning approaches. This is achieved with operations on vectors that constitute a powerful computational algebra, accompanied with an associative memory for the vectors. The paper provides a technical overview of the framework and a worked through implemented example of how it can be applied to various types of linguistic features.
On the instability of embeddings for recommender systems: the case of Matrix Factorization
Apr 12, 2021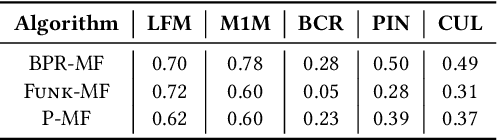
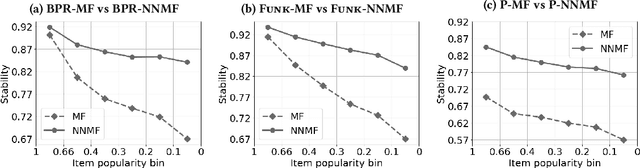
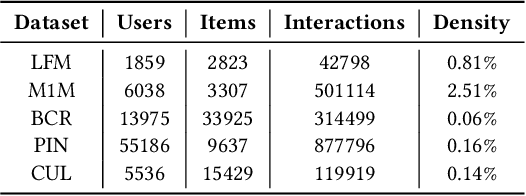
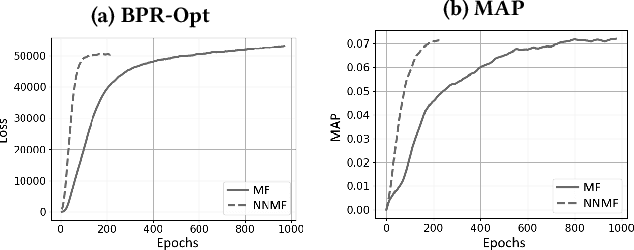
Most state-of-the-art top-N collaborative recommender systems work by learning embeddings to jointly represent users and items. Learned embeddings are considered to be effective to solve a variety of tasks. Among others, providing and explaining recommendations. In this paper we question the reliability of the embeddings learned by Matrix Factorization (MF). We empirically demonstrate that, by simply changing the initial values assigned to the latent factors, the same MF method generates very different embeddings of items and users, and we highlight that this effect is stronger for less popular items. To overcome these drawbacks, we present a generalization of MF, called Nearest Neighbors Matrix Factorization (NNMF). The new method propagates the information about items and users to their neighbors, speeding up the training procedure and extending the amount of information that supports recommendations and representations. We describe the NNMF variants of three common MF approaches, and with extensive experiments on five different datasets we show that they strongly mitigate the instability issues of the original MF versions and they improve the accuracy of recommendations on the long-tail.
Surrogate Scoring Rules and a Dominant Truth Serum for Information Elicitation
May 04, 2018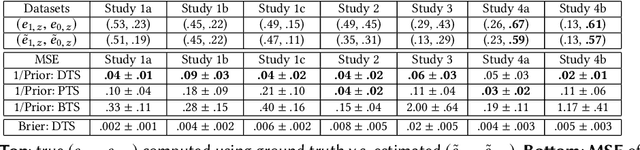
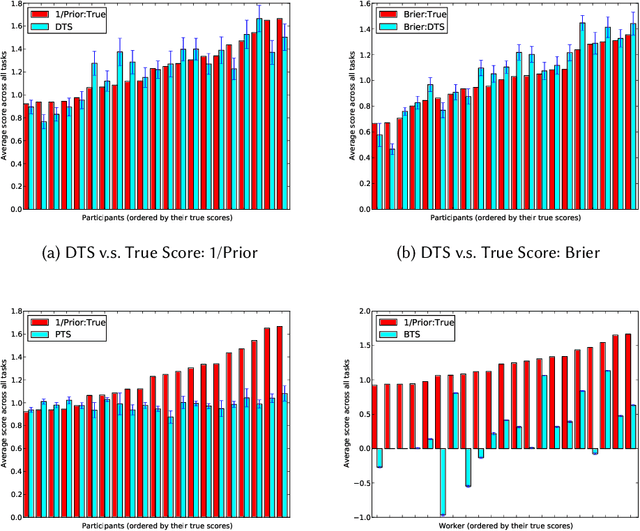
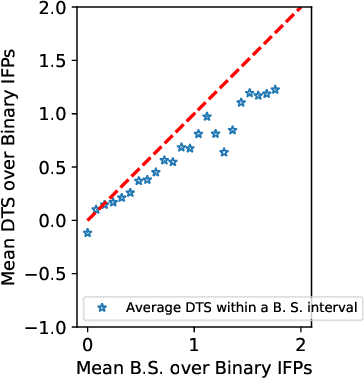

We study information elicitation without verification (IEWV) and ask the following question: Can we achieve truthfulness in dominant strategy in IEWV? This paper considers two elicitation settings. The first setting is when the mechanism designer has access to a random variable that is a noisy or proxy version of the ground truth, with known biases. The second setting is the standard peer prediction setting where agents' reports are the only source of information that the mechanism designer has. We introduce surrogate scoring rules (SSR) for the first setting, which use the noisy ground truth to evaluate quality of elicited information, and show that SSR achieve truthful elicitation in dominant strategy. Built upon SSR, we develop a multi-task mechanism, dominant truth serum (DTS), to achieve truthful elicitation in dominant strategy when the mechanism designer only has access to agents' reports (the second setting). The method relies on an estimation procedure to accurately estimate the average bias in the reports of other agents. With the accurate estimation, a random peer agent's report serves as a noisy ground truth and SSR can then be applied to achieve truthfulness in dominant strategy. A salient feature of SSR and DTS is that they both quantify the quality or value of information despite lack of ground truth, just as proper scoring rules do for the with verification setting. Our work complements both the strictly proper scoring rule literature by solving the case where the mechanism designer only has access to a noisy or proxy version of the ground truth, and the peer prediction literature by achieving truthful elicitation in dominant strategy.
Towards Optimally Weighted Physics-Informed Neural Networks in Ocean Modelling
Jun 16, 2021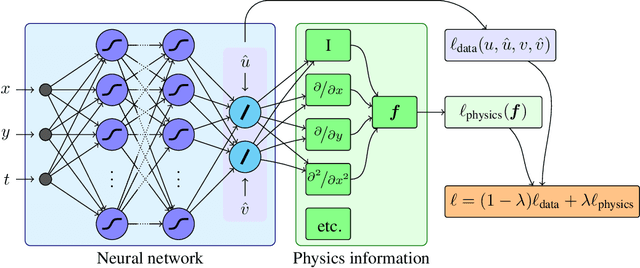

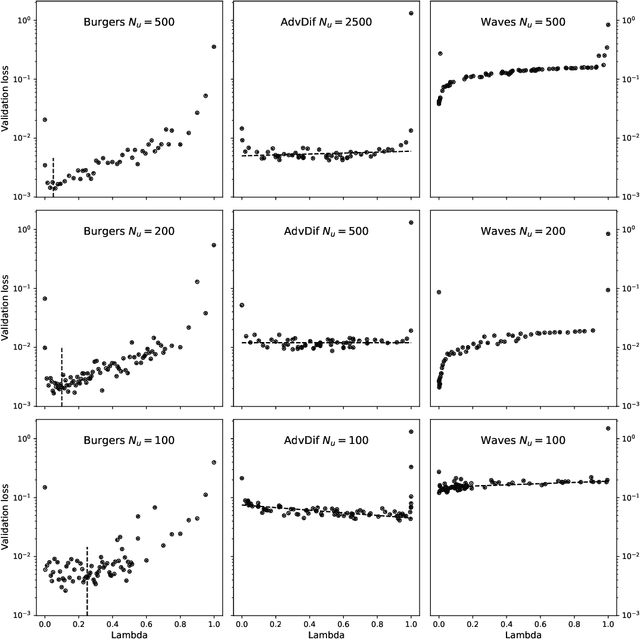
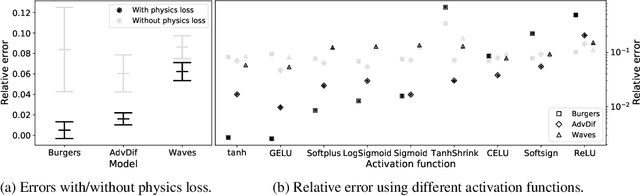
The carbon pump of the world's ocean plays a vital role in the biosphere and climate of the earth, urging improved understanding of the functions and influences of the ocean for climate change analyses. State-of-the-art techniques are required to develop models that can capture the complexity of ocean currents and temperature flows. This work explores the benefits of using physics-informed neural networks (PINNs) for solving partial differential equations related to ocean modeling; such as the Burgers, wave, and advection-diffusion equations. We explore the trade-offs of using data vs. physical models in PINNs for solving partial differential equations. PINNs account for the deviation from physical laws in order to improve learning and generalization. We observed how the relative weight between the data and physical model in the loss function influence training results, where small data sets benefit more from the added physics information.
Differential Privacy for Text Analytics via Natural Text Sanitization
Jun 02, 2021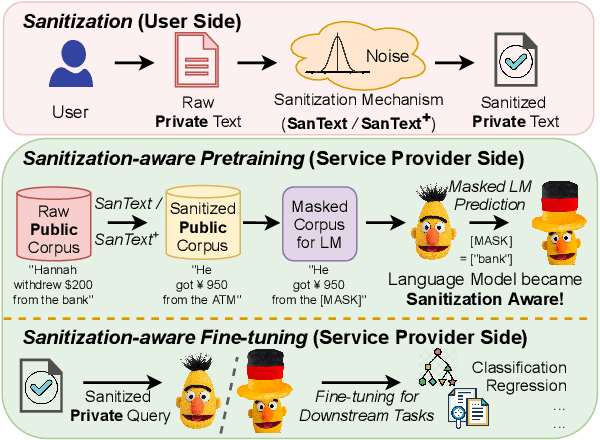
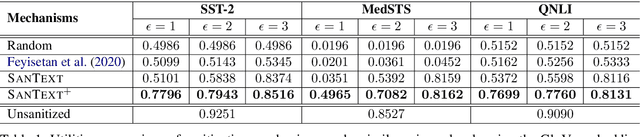
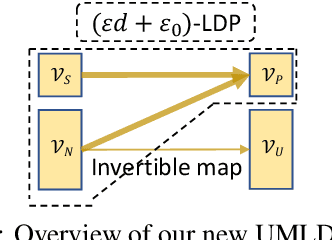
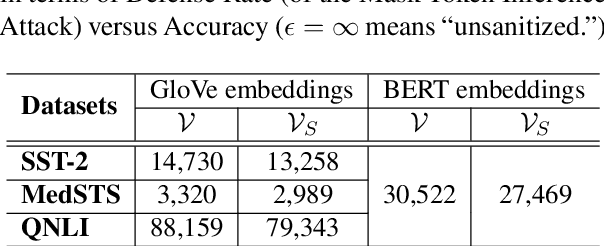
Texts convey sophisticated knowledge. However, texts also convey sensitive information. Despite the success of general-purpose language models and domain-specific mechanisms with differential privacy (DP), existing text sanitization mechanisms still provide low utility, as cursed by the high-dimensional text representation. The companion issue of utilizing sanitized texts for downstream analytics is also under-explored. This paper takes a direct approach to text sanitization. Our insight is to consider both sensitivity and similarity via our new local DP notion. The sanitized texts also contribute to our sanitization-aware pretraining and fine-tuning, enabling privacy-preserving natural language processing over the BERT language model with promising utility. Surprisingly, the high utility does not boost up the success rate of inference attacks.
Legal Judgment Prediction with Multi-Stage CaseRepresentation Learning in the Real Court Setting
Jul 12, 2021

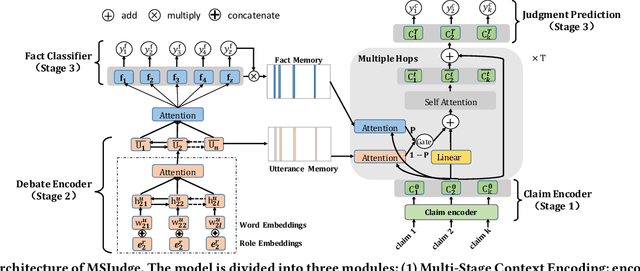
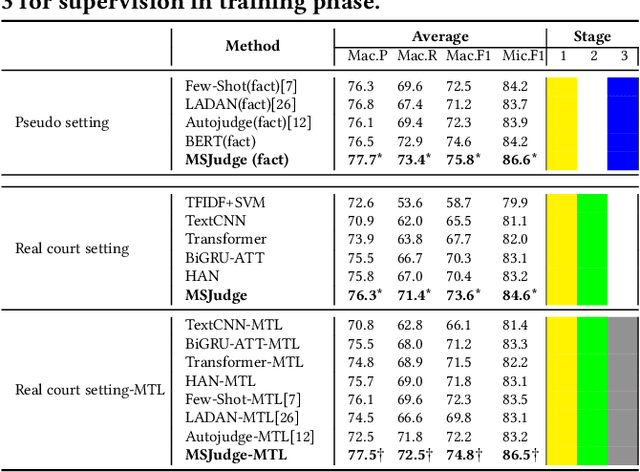
Legal judgment prediction(LJP) is an essential task for legal AI. While prior methods studied on this topic in a pseudo setting by employing the judge-summarized case narrative as the input to predict the judgment, neglecting critical case life-cycle information in real court setting could threaten the case logic representation quality and prediction correctness. In this paper, we introduce a novel challenging dataset from real courtrooms to predict the legal judgment in a reasonably encyclopedic manner by leveraging the genuine input of the case -- plaintiff's claims and court debate data, from which the case's facts are automatically recognized by comprehensively understanding the multi-role dialogues of the court debate, and then learnt to discriminate the claims so as to reach the final judgment through multi-task learning. An extensive set of experiments with a large civil trial data set shows that the proposed model can more accurately characterize the interactions among claims, fact and debate for legal judgment prediction, achieving significant improvements over strong state-of-the-art baselines. Moreover, the user study conducted with real judges and law school students shows the neural predictions can also be interpretable and easily observed, and thus enhancing the trial efficiency and judgment quality.