 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EnD: Entangling and Disentangling deep representations for bias correction
Mar 02, 2021
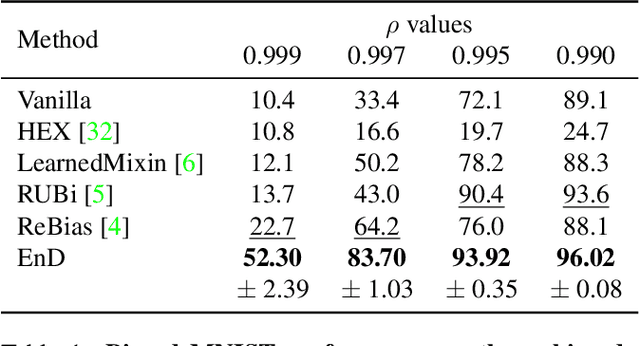
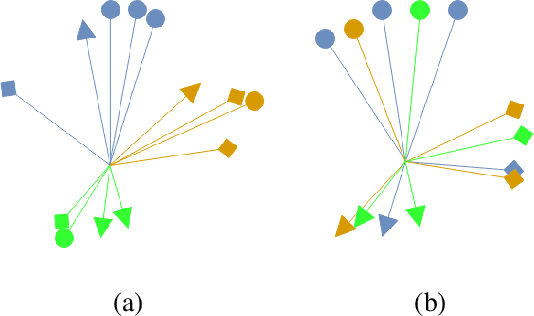

Artificial neural networks perform state-of-the-art in an ever-growing number of tasks, and nowadays they are used to solve an incredibly large variety of tasks. There are problems, like the presence of biases in the training data, which question the generalization capability of these models. In this work we propose EnD, a regularization strategy whose aim is to prevent deep models from learning unwanted biases. In particular, we insert an "information bottleneck" at a certain point of the deep neural network, where we disentangle the information about the bias, still letting the useful information for the training task forward-propagating in the rest of the model. One big advantage of EnD is that we do not require additional training complexity (like decoders or extra layers in the model), since it is a regularizer directly applied on the trained model. Our experiments show that EnD effectively improves the generalization on unbiased test sets, and it can be effectively applied on real-case scenarios, like removing hidden biases in the COVID-19 detection from radiographic images.
End-to-end Temporal Action Detection with Transformer
Jul 14, 2021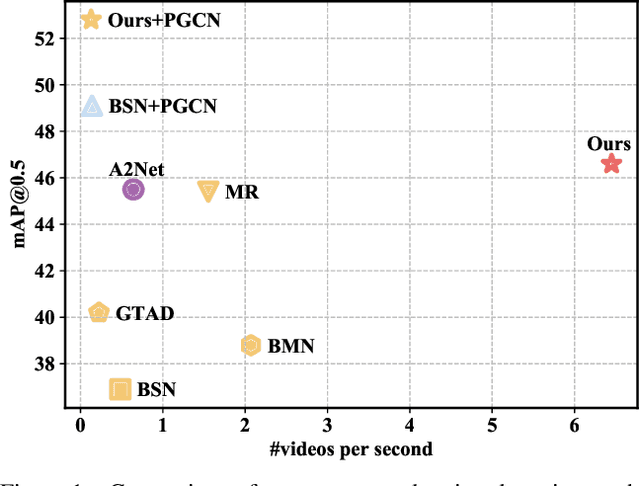
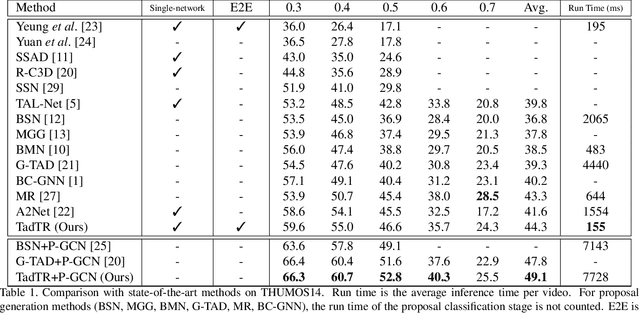
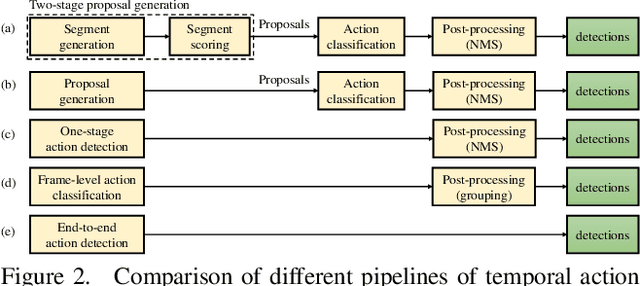
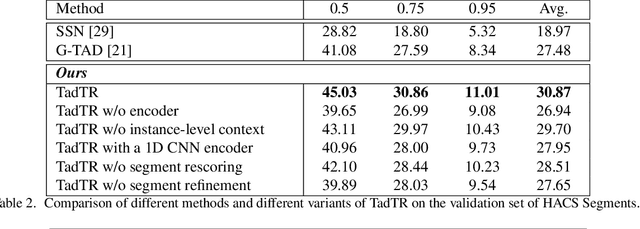
Temporal action detection (TAD) aims to determine the semantic label and the boundaries of every action instance in an untrimmed video. It is a fundamental and challenging task in video understanding and significant progress has been made. Previous methods involve multiple stages or networks and hand-designed rules or operations, which fall short in efficiency and flexibility. In this paper, we propose an end-to-end framework for TAD upon Transformer, termed \textit{TadTR}, which maps a set of learnable embeddings to action instances in parallel. TadTR is able to adaptively extract temporal context information required for making action predictions, by selectively attending to a sparse set of snippets in a video. As a result, it simplifies the pipeline of TAD and requires lower computation cost than previous detectors, while preserving remarkable detection performance. TadTR achieves state-of-the-art performance on HACS Segments (+3.35% average mAP). As a single-network detector, TadTR runs 10$\times$ faster than its comparable competitor. It outperforms existing single-network detectors by a large margin on THUMOS14 (+5.0% average mAP) and ActivityNet (+7.53% average mAP). When combined with other detectors, it reports 54.1% mAP at IoU=0.5 on THUMOS14, and 34.55% average mAP on ActivityNet-1.3. Our code will be released at \url{https://github.com/xlliu7/TadTR}.
CloudAAE: Learning 6D Object Pose Regression with On-line Data Synthesis on Point Clouds
Mar 02, 2021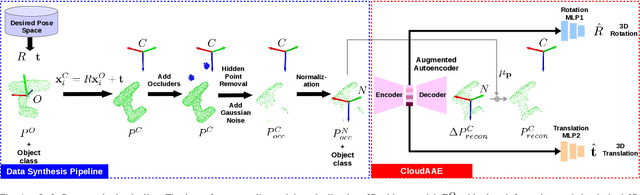
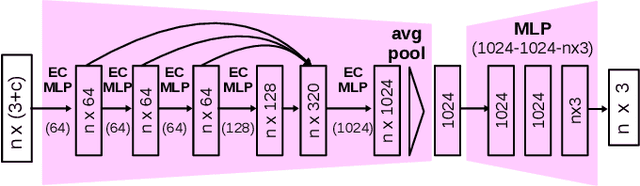
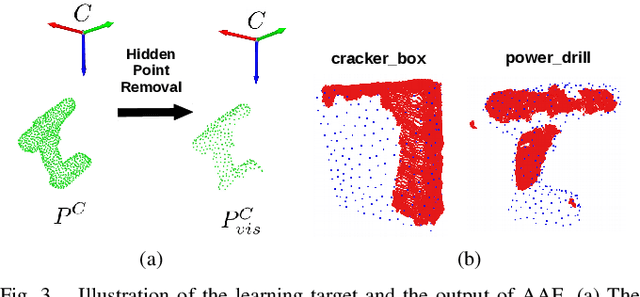
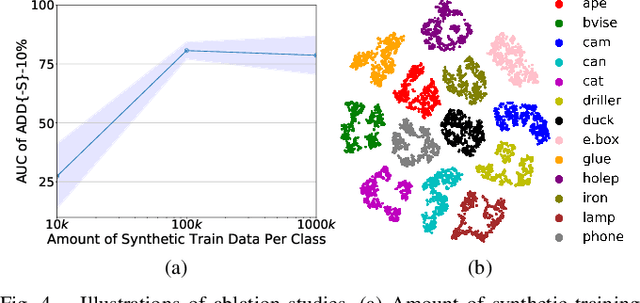
It is often desired to train 6D pose estimation systems on synthetic data because manual annotation is expensive. However, due to the large domain gap between the synthetic and real images, synthesizing color images is expensive. In contrast, this domain gap is considerably smaller and easier to fill for depth information. In this work, we present a system that regresses 6D object pose from depth information represented by point clouds, and a lightweight data synthesis pipeline that creates synthetic point cloud segments for training. We use an augmented autoencoder (AAE) for learning a latent code that encodes 6D object pose information for pose regression. The data synthesis pipeline only requires texture-less 3D object models and desired viewpoints, and it is cheap in terms of both time and hardware storage. Our data synthesis process is up to three orders of magnitude faster than commonly applied approaches that render RGB image data. We show the effectiveness of our system on the LineMOD, LineMOD Occlusion, and YCB Video datasets. The implementation of our system is available at: https://github.com/GeeeG/CloudAAE.
Massive-MIMO Iterative Channel Estimation and Decoding (MICED) in the Uplink
Apr 30, 2021
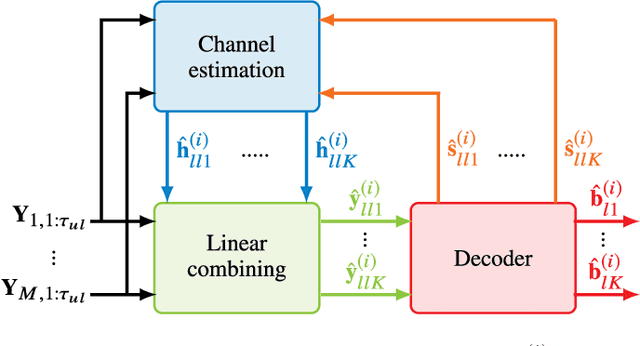
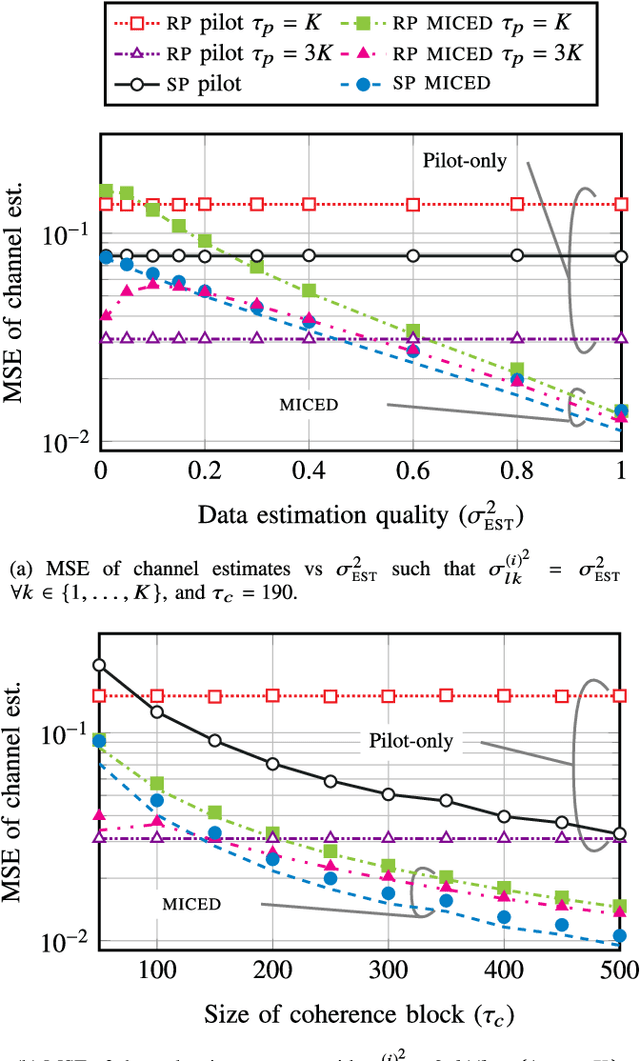
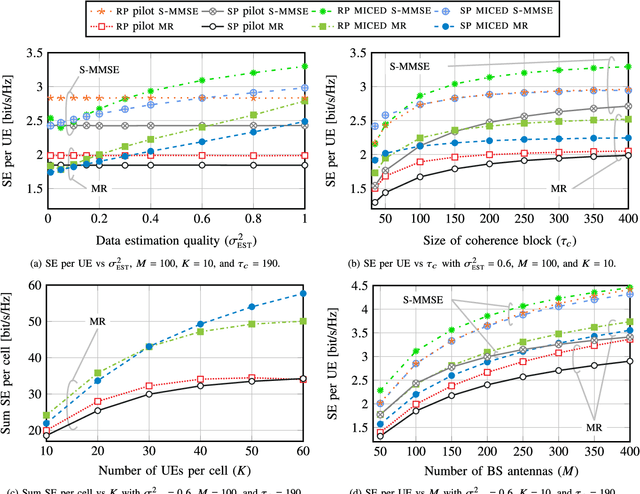
Massive MIMO uses a large number of antennas to increase the spectral efficiency (SE) through spatial multiplexing of users, which requires accurate channel state information. It is often assumed that regular pilots (RP), where a fraction of the time-frequency resources is reserved for pilots, suffices to provide high SE. However, the SE is limited by the pilot overhead and pilot contamination. An alternative is superimposed pilots (SP) where all resources are used for pilots and data. This removes the pilot overhead and reduces pilot contamination by using longer pilots. However, SP suffers from data interference that reduces the SE gains. This paper proposes the Massive-MIMO Iterative Channel Estimation and Decoding (MICED) algorithm where partially decoded data is used as side-information to improve the channel estimation and increase SE. We show that users with precise data estimates can help users with poor data estimates to decode. Numerical results with QPSK modulation and LDPC codes show that the MICED algorithm increases the SE and reduces the block-error-rate with RP and SP compared to conventional methods. The MICED algorithm with SP delivers the highest SE and it is especially effective in scenarios with short coherence blocks like high mobility or high frequencies.
* Published in IEEE Transactions on Communications, 16 pages, 7 figures
GasHis-Transformer: A Multi-scale Visual Transformer Approach for Gastric Histopathology Image Classification
May 25, 2021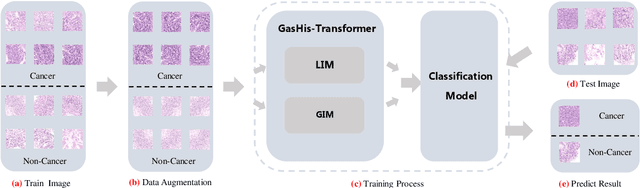

Existing deep learning methods for diagnosis of gastric cancer commonly use convolutional neural networks (CNN). Recently, the Visual Transformer (VT) has attracted a major attention because of its performance and efficiency, but its applications are mostly in the field of computer vision. In this paper, a multi-scale visual transformer model, referred to as GasHis-Transformer, is proposed for gastric histopathology image classification (GHIC), which enables the automatic classification of microscopic gastric images into abnormal and normal cases. The GasHis-Transformer model consists of two key modules: a global information module (GIM) and a local information module (LIM) to extract pathological features effectively. In our experiments, a public hematoxylin and eosin (H&E) stained gastric histopathology dataset with 280 abnormal or normal images using the GasHis-Transformer model is applied to estimate precision, recall, F1-score, and accuracy on the testing set as 98.0%, 100.0%, 96.0% and 98.0% respectively. Furthermore, a critical study is conducted to evaluate the robustness of GasHis-Transformer according to add ten different noises including adversarial attack and traditional image noise. In addition, a clinically meaningful study is executed to test the gastric cancer identification of GasHis-Transformerwith 420 abnormal images and achieves 96.2% accuracy. Finally, a comparative study is performed to test the generalizability with both H&E and Immunohistochemical (IHC) stained images on a lymphoma image dataset, a breast cancer dataset and a cervical cancer dataset, producing comparable F1-scores (85.6%, 82.8% and 65.7%, respectively) and accuracy (83.9%, 89.4% and 65.7%, respectively) respectively. In conclusion, GasHis-Transformerdemonstrates a high classification performance and shows its significant potential in histopathology image analysis.
A User-Guided Bayesian Framework for Ensemble Feature Selection in Life Science Applications (UBayFS)
Apr 30, 2021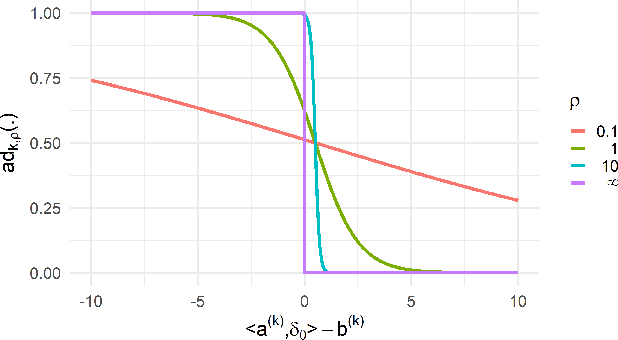
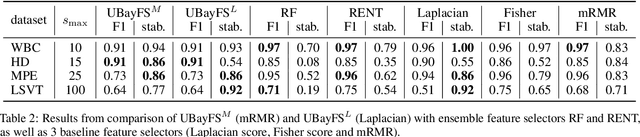
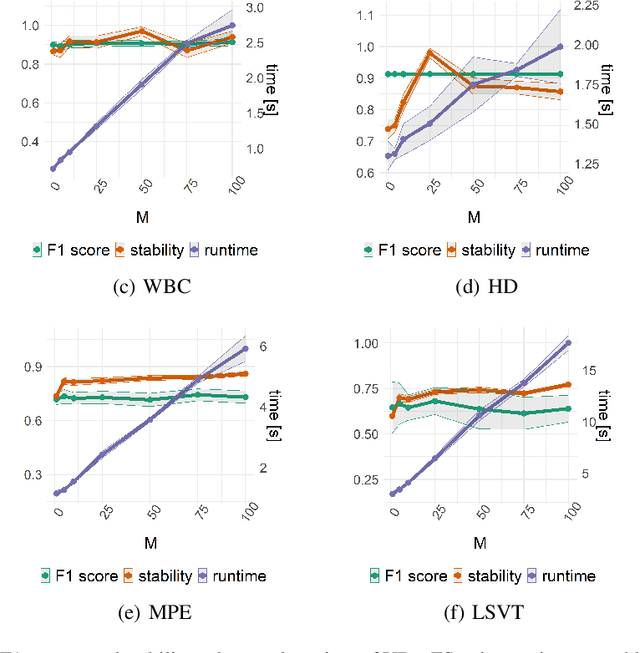
Training predictive models on high-dimensional datasets is a challenging task in artificial intelligence. Users must take measures to prevent overfitting and keep model complexity low. Thus, the feature selection plays a key role in data preprocessing and delivers insights into the systematic variation in the data. The latter aspect is crucial in domains that rely on model interpretability, such as life sciences. We propose UBayFS, an ensemble feature selection technique, embedded in a Bayesian statistical framework. Our approach enhances the feature selection process by considering two sources of information: data and domain knowledge. Therefore, we build an ensemble of elementary feature selectors that extract information from empirical data, leading to a meta-model, which compensates for inconsistencies between elementary feature selectors. The user guides UBayFS by weighting features and penalizing specific feature combinations. The framework builds on a multinomial likelihood and a novel version of constrained Dirichlet-type prior distribution, involving initial feature weights and side constraints. In a quantitative evaluation, we demonstrate that the presented framework allows for a balanced trade-off between user knowledge and data observations. A comparison with standard feature selectors underlines that UBayFS achieves competitive performance, while providing additional flexibility to incorporate domain knowledge.
Using Self-Supervised Feature Extractors with Attention for Automatic COVID-19 Detection from Speech
Jun 30, 2021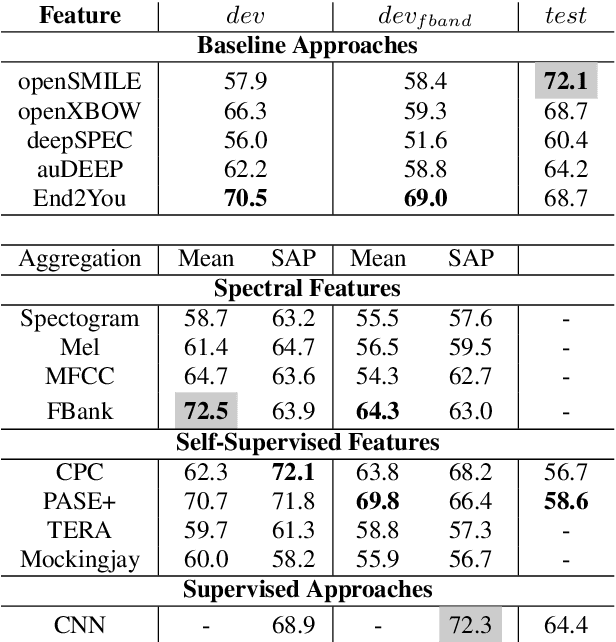
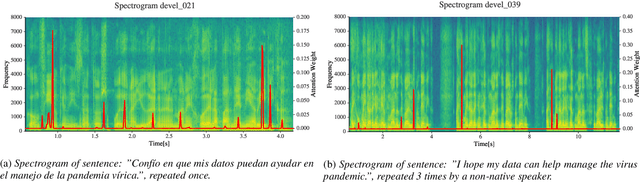
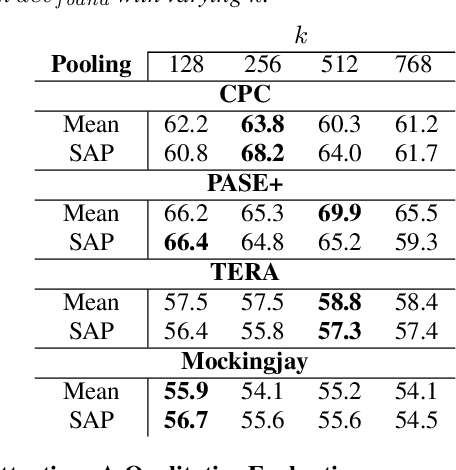
The ComParE 2021 COVID-19 Speech Sub-challenge provides a test-bed for the evaluation of automatic detectors of COVID-19 from speech. Such models can be of value by providing test triaging capabilities to health authorities, working alongside traditional testing methods. Herein, we leverage the usage of pre-trained, problem agnostic, speech representations and evaluate their use for this task. We compare the obtained results against a CNN architecture trained from scratch and traditional frequency-domain representations. We also evaluate the usage of Self-Attention Pooling as an utterance-level information aggregation method. Experimental results demonstrate that models trained on features extracted from self-supervised models perform similarly or outperform fully-supervised models and models based on handcrafted features. Our best model improves the Unweighted Average Recall (UAR) from 69.0\% to 72.3\% on a development set comprised of only full-band examples and achieves 64.4\% on the test set. Furthermore, we study where the network is attending, attempting to draw some conclusions regarding its explainability. In this relatively small dataset, we find the network attends especially to vowels and aspirates.
Safer Reinforcement Learning through Transferable Instinct Networks
Jul 14, 2021



Random exploration is one of the main mechanisms through which reinforcement learning (RL) finds well-performing policies. However, it can lead to undesirable or catastrophic outcomes when learning online in safety-critical environments. In fact, safe learning is one of the major obstacles towards real-world agents that can learn during deployment. One way of ensuring that agents respect hard limitations is to explicitly configure boundaries in which they can operate. While this might work in some cases, we do not always have clear a-priori information which states and actions can lead dangerously close to hazardous states. Here, we present an approach where an additional policy can override the main policy and offer a safer alternative action. In our instinct-regulated RL (IR^2L) approach, an "instinctual" network is trained to recognize undesirable situations, while guarding the learning policy against entering them. The instinct network is pre-trained on a single task where it is safe to make mistakes, and transferred to environments in which learning a new task safely is critical. We demonstrate IR^2L in the OpenAI Safety gym domain, in which it receives a significantly lower number of safety violations during training than a baseline RL approach while reaching similar task performance.
WildGait: Learning Gait Representations from Raw Surveillance Streams
May 13, 2021
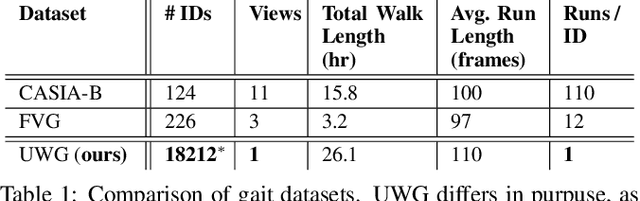
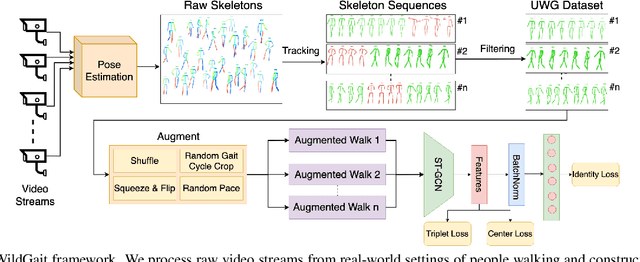

The use of gait for person identification has important advantages such as being non-invasive, unobtrusive, not requiring cooperation and being less likely to be obscured compared to other biometrics. Existing methods for gait recognition require cooperative gait scenarios, in which a single person is walking multiple times in a straight line in front of a camera. We aim to address the hard challenges of real-world scenarios in which camera feeds capture multiple people, who in most cases pass in front of the camera only once. We address privacy concerns by using only motion information of walking individuals, with no identifiable appearance-based information. As such, we propose a novel weakly supervised learning framework, WildGait, which consists of training a Spatio-Temporal Graph Convolutional Network on a large number of automatically annotated skeleton sequences obtained from raw, real-world, surveillance streams to learn useful gait signatures. Our results show that, with fine-tuning, we surpass in terms of recognition accuracy the current state-of-the-art pose-based gait recognition solutions. Our proposed method is reliable in training gait recognition methods in unconstrained environments, especially in settings with scarce amounts of annotated data. We obtain an accuracy of 84.43% on CASIA-B and 71.3% on FVG, while using only 10% of the available training data. This consists of 29% and 38% accuracy improvement on the respective datasets when using the same network without pretraining.
Predicting crop yields with little ground truth: A simple statistical model for in-season forecasting
Jun 18, 2021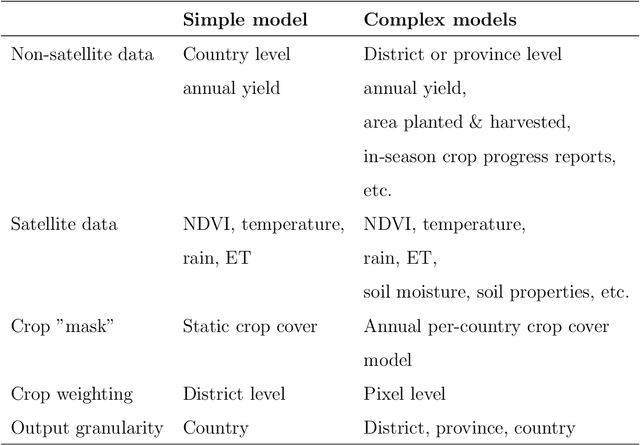
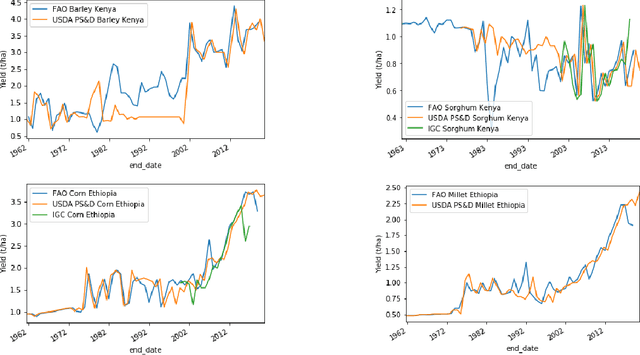
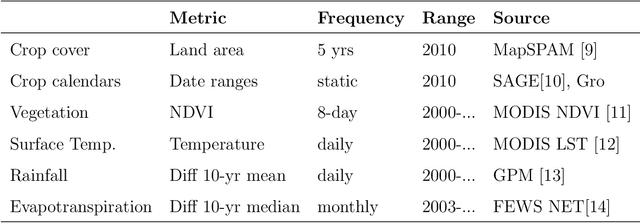
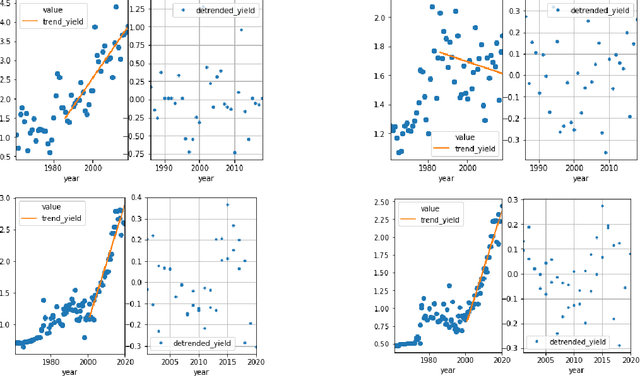
We present a fully automated model for in-season crop yield prediction, designed to work where there is a dearth of sub-national "ground truth" information. Our approach relies primarily on satellite data and is characterized by careful feature engineering combined with a simple regression model. As such, it can work almost anywhere in the world. Applying it to 10 different crop-country pairs (5 cereals -- corn, wheat, sorghum, barley and millet, in 2 countries -- Ethiopia and Kenya), we achieve RMSEs of 5%-10% for predictions 9 months into the year, and 7%-14% for predictions 3 months into the year. The model outputs daily forecasts for the final yield of the current year. It is trained using approximately 4 million data points for each crop-country pair. These consist of: historical country-level annual yields, crop calendars, crop cover, NDVI, temperature, rainfall, and evapotransporation.