 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Qualitative Evaluation of User Preference for Link-based vs. Text-based Recommendations of Wikipedia Articles
Sep 16, 2021
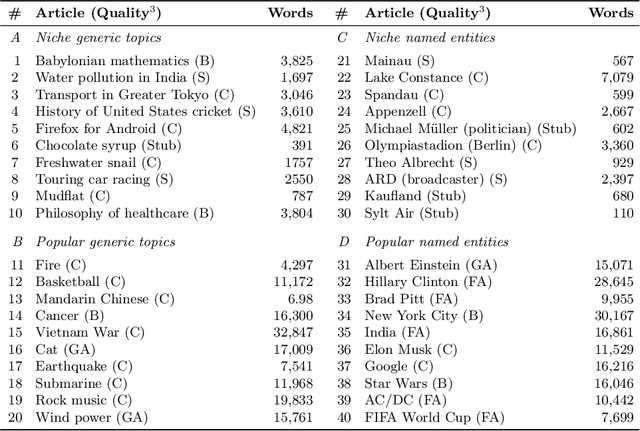
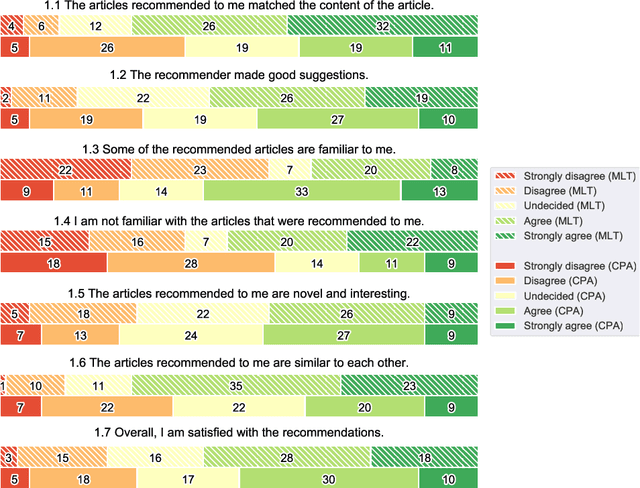
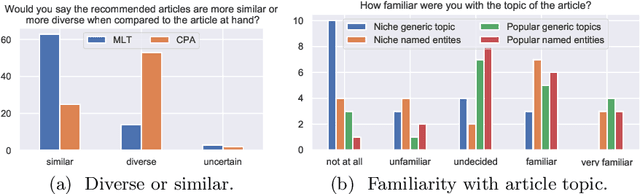
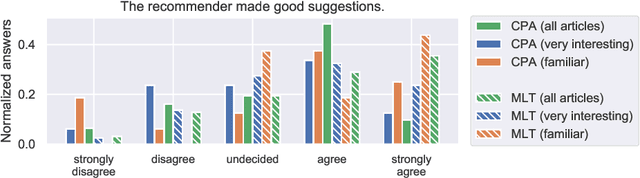
Literature recommendation systems (LRS) assist readers in the discovery of relevant content from the overwhelming amount of literature available. Despite the widespread adoption of LRS, there is a lack of research on the user-perceived recommendation characteristics for fundamentally different approaches to content-based literature recommendation. To complement existing quantitative studies on literature recommendation, we present qualitative study results that report on users' perceptions for two contrasting recommendation classes: (1) link-based recommendation represented by the Co-Citation Proximity (CPA) approach, and (2) text-based recommendation represented by Lucene's MoreLikeThis (MLT) algorithm. The empirical data analyzed in our study with twenty users and a diverse set of 40 Wikipedia articles indicate a noticeable difference between text- and link-based recommendation generation approaches along several key dimensions. The text-based MLT method receives higher satisfaction ratings in terms of user-perceived similarity of recommended articles. In contrast, the CPA approach receives higher satisfaction scores in terms of diversity and serendipity of recommendations. We conclude that users of literature recommendation systems can benefit most from hybrid approaches that combine both link- and text-based approaches, where the user's information needs and preferences should control the weighting for the approaches used. The optimal weighting of multiple approaches used in a hybrid recommendation system is highly dependent on a user's shifting needs.
Improving Distantly Supervised Relation Extraction with Self-Ensemble Noise Filtering
Aug 22, 2021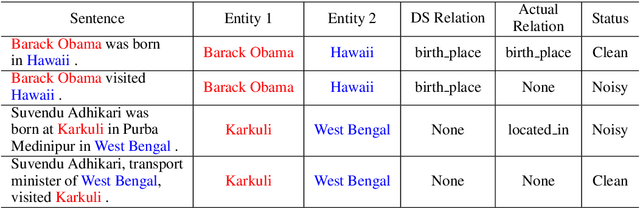
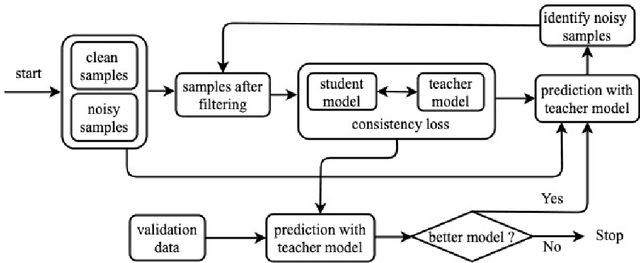
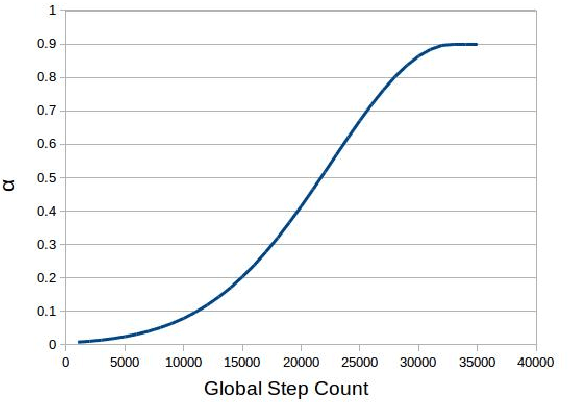

Distantly supervised models are very popular for relation extraction since we can obtain a large amount of training data using the distant supervision method without human annotation. In distant supervision, a sentence is considered as a source of a tuple if the sentence contains both entities of the tuple. However, this condition is too permissive and does not guarantee the presence of relevant relation-specific information in the sentence. As such, distantly supervised training data contains much noise which adversely affects the performance of the models. In this paper, we propose a self-ensemble filtering mechanism to filter out the noisy samples during the training process. We evaluate our proposed framework on the New York Times dataset which is obtained via distant supervision. Our experiments with multiple state-of-the-art neural relation extraction models show that our proposed filtering mechanism improves the robustness of the models and increases their F1 scores.
Topos and Stacks of Deep Neural Networks
Jun 28, 2021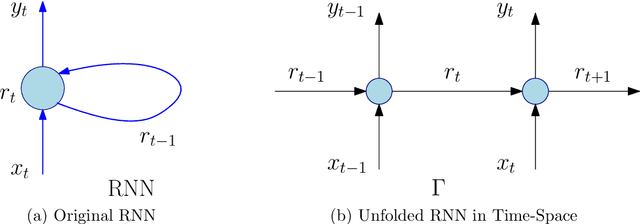
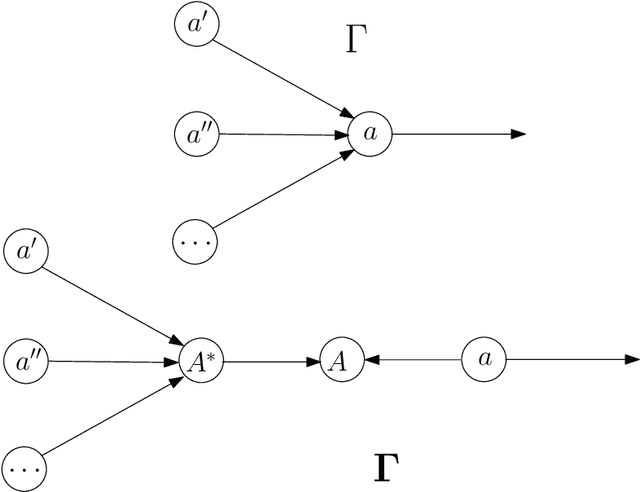
Every known artificial deep neural network (DNN) corresponds to an object in a canonical Grothendieck's topos; its learning dynamic corresponds to a flow of morphisms in this topos. Invariance structures in the layers (like CNNs or LSTMs) correspond to Giraud's stacks. This invariance is supposed to be responsible of the generalization property, that is extrapolation from learning data under constraints. The fibers represent pre-semantic categories (Culioli, Thom), over which artificial languages are defined, with internal logics, intuitionist, classical or linear (Girard). Semantic functioning of a network is its ability to express theories in such a language for answering questions in output about input data. Quantities and spaces of semantic information are defined by analogy with the homological interpretation of Shannon's entropy (P.Baudot and D.B. 2015). They generalize the measures found by Carnap and Bar-Hillel (1952). Amazingly, the above semantical structures are classified by geometric fibrant objects in a closed model category of Quillen, then they give rise to homotopical invariants of DNNs and of their semantic functioning. Intentional type theories (Martin-Loef) organize these objects and fibrations between them. Information contents and exchanges are analyzed by Grothendieck's derivators.
An Information-Theoretic Framework for Non-linear Canonical Correlation Analysis
Oct 31, 2018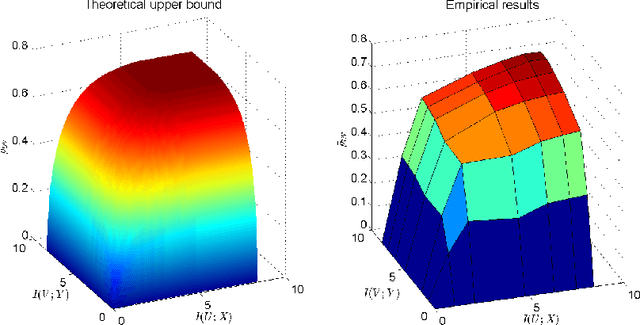
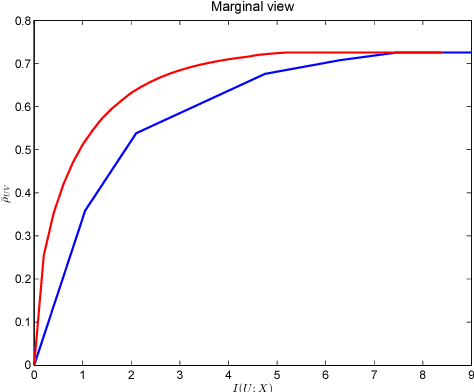
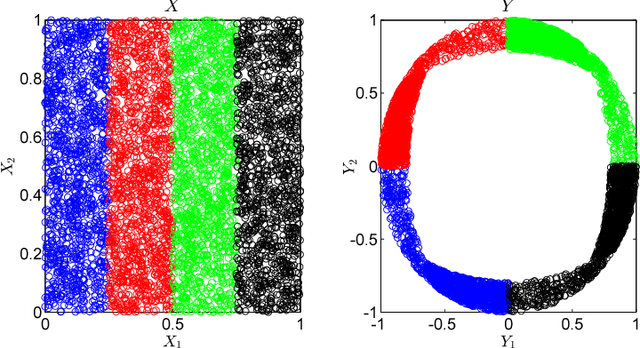
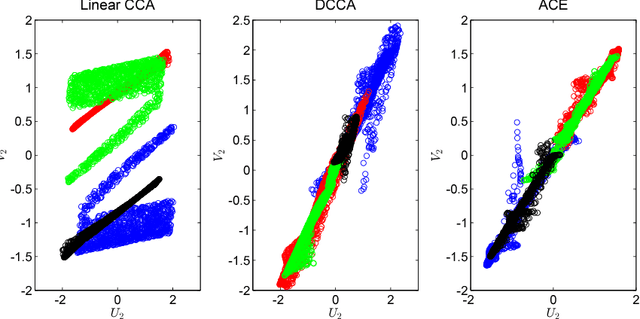
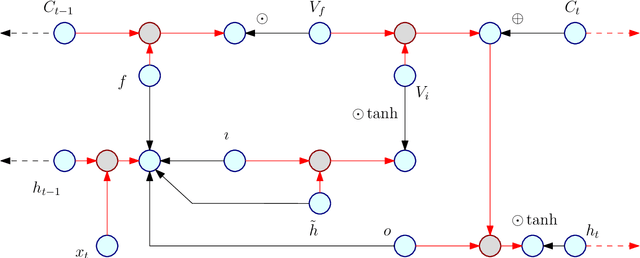
Canonical Correlation Analysis (CCA) is a linear representation learning method that seeks maximally correlated variables in multi-view data. Non-linear CCA extends this notion to a broader family of transformations, which are more powerful for many real-world applications. Given the joint probability, the Alternating Conditional Expectation (ACE) provides an optimal solution to the non-linear CCA problem. However, it suffers from limited performance and an increasing computational burden when only a finite number of observations is available. In this work we introduce an information-theoretic framework for the non-linear CCA problem (ITCCA), which extends the classical ACE approach. Our suggested framework seeks compressed representations of the data that allow a maximal level of correlation. This way we control the trade-off between the flexibility and the complexity of the representation. Our approach demonstrates favorable performance at a reduced computational burden, compared to non-linear alternatives, in a finite sample size regime. Further, ITCCA provides theoretical bounds and optimality conditions, as we establish fundamental connections to rate-distortion theory, the information bottleneck and remote source coding. In addition, it implies a "soft" dimensionality reduction, as the compression level is measured (and governed) by the mutual information between the original noisy data and the signals that we extract.
Enhancing Self-Disclosure In Neural Dialog Models By Candidate Re-ranking
Sep 10, 2021
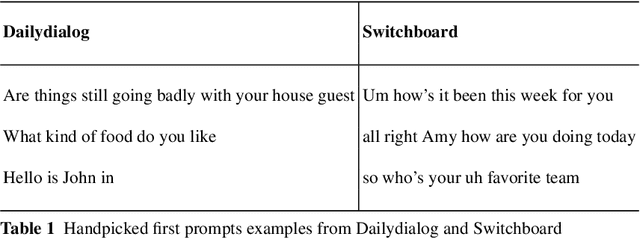
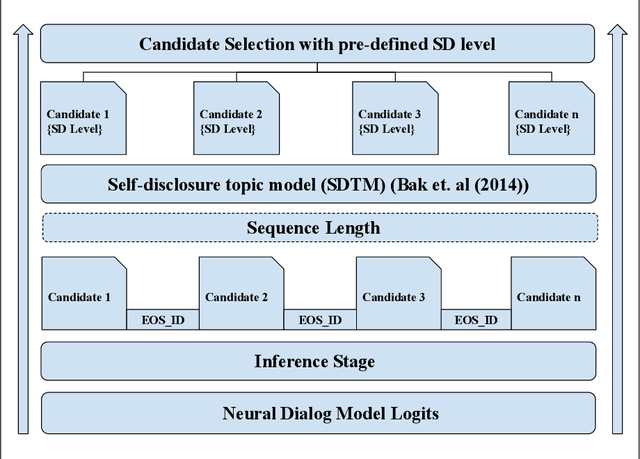
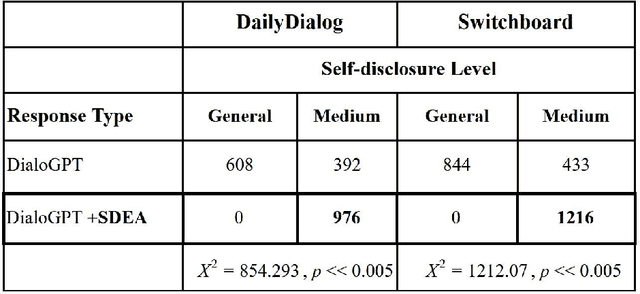
Neural language modelling has progressed the state-of-the-art in different downstream Natural Language Processing (NLP) tasks. One such area is of open-domain dialog modelling, neural dialog models based on GPT-2 such as DialoGPT have shown promising performance in single-turn conversation. However, such (neural) dialog models have been criticized for generating responses which although may have relevance to the previous human response, tend to quickly dissipate human interest and descend into trivial conversation. One reason for such performance is the lack of explicit conversation strategy being employed in human-machine conversation. Humans employ a range of conversation strategies while engaging in a conversation, one such key social strategies is Self-disclosure(SD). A phenomenon of revealing information about one-self to others. Social penetration theory (SPT) proposes that communication between two people moves from shallow to deeper levels as the relationship progresses primarily through self-disclosure. Disclosure helps in creating rapport among the participants engaged in a conversation. In this paper, Self-disclosure enhancement architecture (SDEA) is introduced utilizing Self-disclosure Topic Model (SDTM) during inference stage of a neural dialog model to re-rank response candidates to enhance self-disclosure in single-turn responses from from the model.
Event-based Timestamp Image Encoding Network for Human Action Recognition and Anticipation
Apr 12, 2021

Event camera is an asynchronous, high frequencyvision sensor with low power consumption, which is suitable forhuman action understanding task. It is vital to encode the spatial-temporal information of event data properly and use standardcomputer vision tool to learn from the data. In this work, wepropose a timestamp image encoding 2D network, which takes theencoded spatial-temporal images with polarity information of theevent data as input and output the action label. In addition, wepropose a future timestamp image generator to generate futureaction information to aid the model to anticipate the humanaction when the action is not completed. Experiment results showthat our method can achieve the same level of performance asthose RGB-based benchmarks on real world action recognition,and also achieve the state of the art (SOTA) result on gesturerecognition. Our future timestamp image generating model caneffectively improve the prediction accuracy when the action is notcompleted. We also provide insight discussion on the importanceof motion and appearance information in action recognition andanticipation.
Unsupervised Moving Object Detection via Contextual Information Separation
Jan 10, 2019

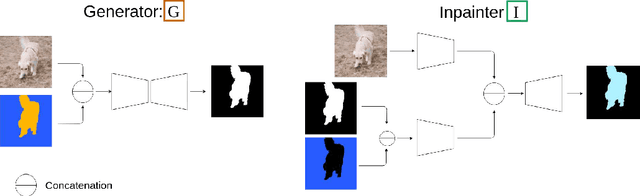

We propose an adversarial contextual model for detecting moving objects in images. A deep neural network is trained to predict the optical flow in a region using information from everywhere else but that region (context), while another network attempts to make such context as uninformative as possible. The result is a model where hypotheses naturally compete with no need for explicit regularization or hyper-parameter tuning. Although our method requires no supervision whatsoever, it outperforms several methods that are pre-trained on large annotated datasets. Our model can be thought of as a generalization of classical variational generative region-based segmentation, but in a way that avoids explicit regularization or solution of partial differential equations at run-time.
Spatially Invariant Unsupervised 3D Object Segmentation with Graph Neural Networks
Jun 10, 2021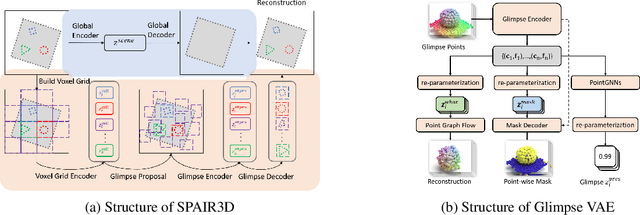
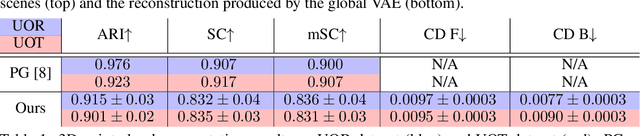
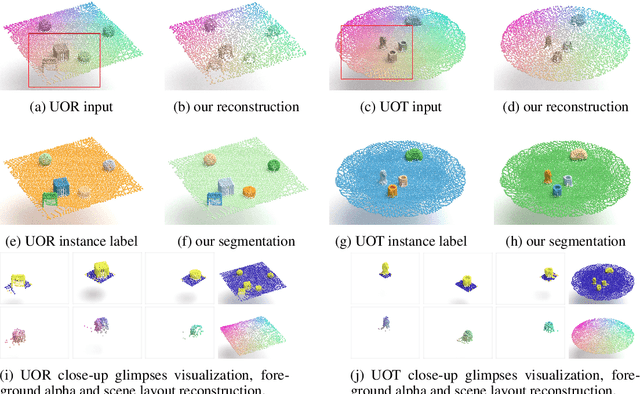
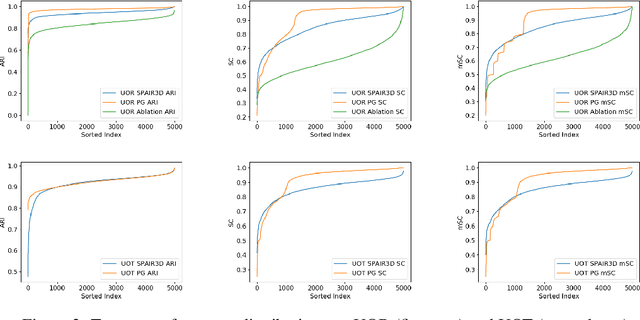
In this paper, we tackle the problem of unsupervised 3D object segmentation from a point cloud without RGB information. In particular, we propose a framework,~{\bf SPAIR3D}, to model a point cloud as a spatial mixture model and jointly learn the multiple-object representation and segmentation in 3D via Variational Autoencoders (VAE). Inspired by SPAIR, we adopt an object-specification scheme that describes each object's location relative to its local voxel grid cell rather than the point cloud as a whole. To model the spatial mixture model on point clouds, we derive the~\emph{Chamfer Likelihood}, which fits naturally into the variational training pipeline. We further design a new spatially invariant graph neural network to generate a varying number of 3D points as a decoder within our VAE.~Experimental results demonstrate that~{\bf SPAIR3D} is capable of detecting and segmenting variable number of objects without appearance information across diverse scenes.
Federated Meta Learning Enhanced Acoustic Radio Cooperative Framework for Ocean of Things Underwater Acoustic Communications
May 24, 2021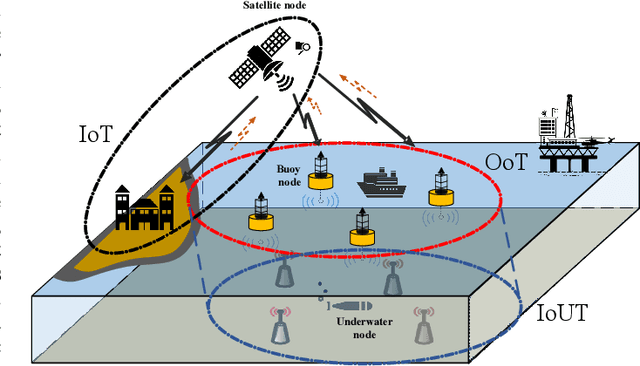
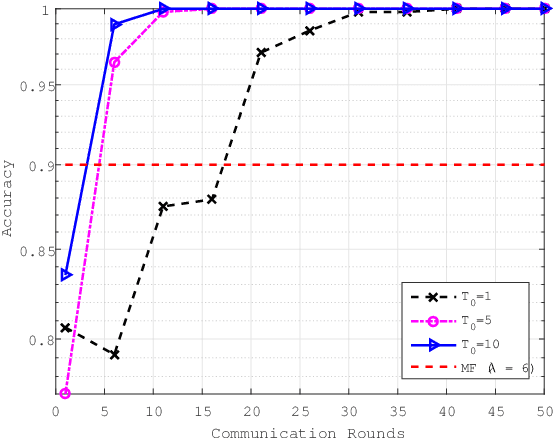

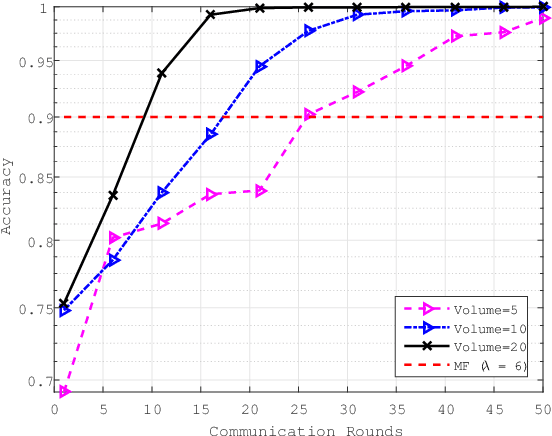
Sixth-generation wireless communication (6G) will be an integrated architecture of "space, air, ground and sea". One of the most difficult part of this architecture is the underwater information acquisition which need to transmitt information cross the interface between water and air.In this senario, ocean of things (OoT) will play an important role, because it can serve as a hub connecting Internet of things (IoT) and Internet of underwater things (IoUT). OoT device not only can collect data through underwater methods, but also can utilize radio frequence over the air. For underwater communications, underwater acoustic communications (UWA COMMs) is the most effective way for OoT devices to exchange information, but it is always tormented by doppler shift and synchronization errors. In this paper, in order to overcome UWA tough conditions, a deep neural networks based receiver for underwater acoustic chirp communication, called C-DNN, is proposed. Moreover, to improve the performance of DL-model and solve the problem of model generalization, we also proposed a novel federated meta learning (FML) enhanced acoustic radio cooperative (ARC) framework, dubbed ARC/FML, to do transfer. Particularly, tractable expressions are derived for the convergence rate of FML in a wireless setting, accounting for effects from both scheduling ratio, local epoch and the data amount on a single node.From our analysis and simulation results, it is shown that, the proposed C-DNN can provide a better BER performance and lower complexity than classical matched filter (MF) in underwater acoustic communications scenario. The ARC/FML framework has good convergence under a variety of channels than federated learning (FL). In summary, the proposed ARC/FML for OoT is a promising scheme for information exchange across water and air.
A More Compact Object Detector Head Network with Feature Enhancement and Relational Reasoning
Jun 28, 2021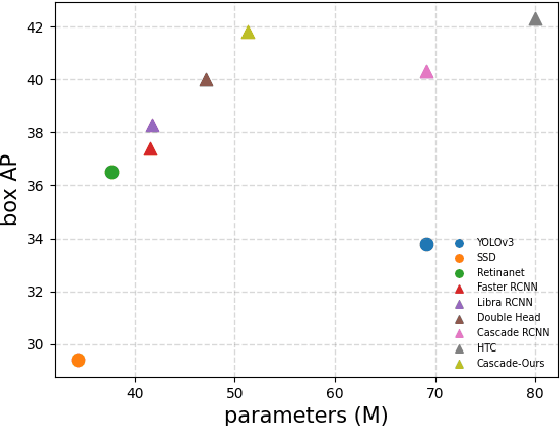
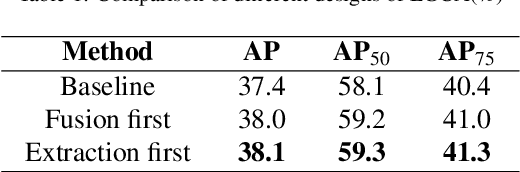
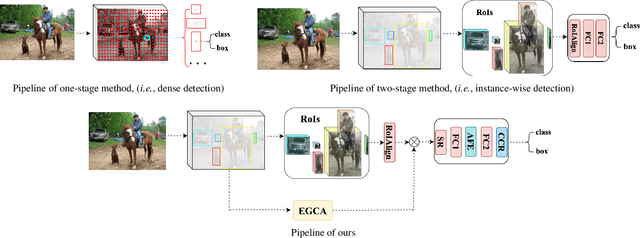
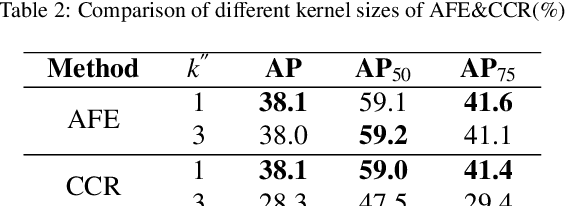
Modeling implicit feature interaction patterns is of significant importance to object detection tasks. However, in the two-stage detectors, due to the excessive use of hand-crafted components, it is very difficult to reason about the implicit relationship of the instance features. To tackle this problem, we analyze three different levels of feature interaction relationships, namely, the dependency relationship between the cropped local features and global features, the feature autocorrelation within the instance, and the cross-correlation relationship between the instances. To this end, we propose a more compact object detector head network (CODH), which can not only preserve global context information and condense the information density, but also allows instance-wise feature enhancement and relational reasoning in a larger matrix space. Without bells and whistles, our method can effectively improve the detection performance while significantly reducing the parameters of the model, e.g., with our method, the parameters of the head network is 0.6 times smaller than the state-of-the-art Cascade R-CNN, yet the performance boost is 1.3% on COCO test-dev. Without losing generality, we can also build a more lighter head network for other multi-stage detectors by assembling our method.