 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Link Scheduling using Graph Neural Networks
Sep 12, 2021
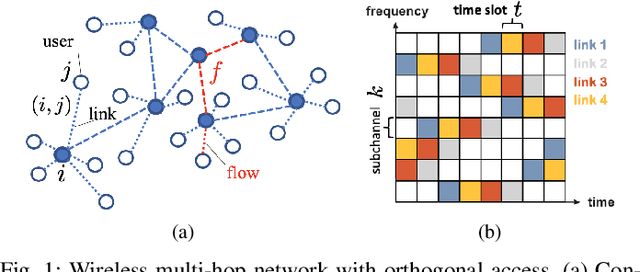
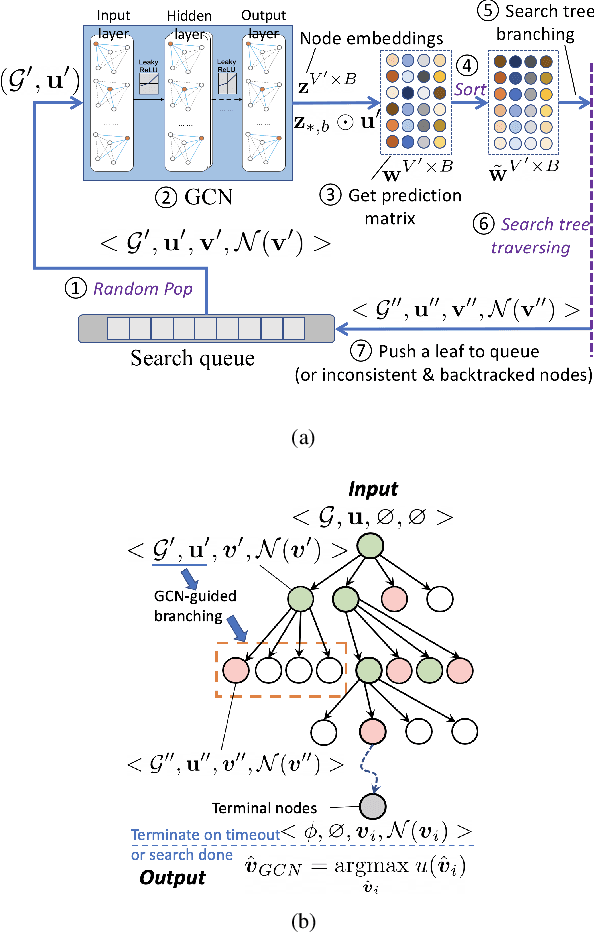
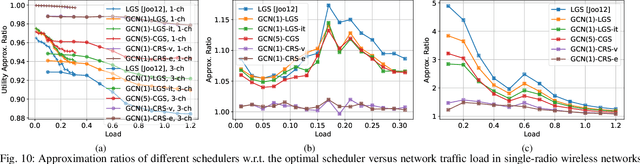
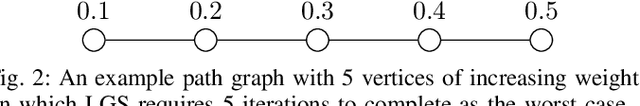
Efficient scheduling of transmissions is a key problem in wireless networks. The main challenge stems from the fact that optimal link scheduling involves solving a maximum weighted independent set (MWIS) problem, which is known to be NP-hard. For practical link scheduling schemes, centralized and distributed greedy heuristics are commonly used to approximate the solution to the MWIS problem. However, these greedy schemes mostly ignore important topological information of the wireless network. To overcome this limitation, we propose fast heuristics based on graph convolutional networks (GCNs) that can be implemented in centralized and distributed manners. Our centralized MWIS solver is based on tree search guided by a trainable GCN module and 1-step rollout. In our distributed MWIS solver, a trainable GCN module learns topology-aware node embeddings that are combined with the network weights before calling a distributed greedy solver. Test results on medium-sized wireless networks show that a GCN-based centralized MWIS solver can reach a near-optimal solution quickly. Moreover, we demonstrate that a shallow GCN-based distributed MWIS scheduler can reduce by nearly half the suboptimality gap of the distributed greedy solver with minimal increase in complexity. The proposed scheduling solutions also exhibit good generalizability across graph and weight distributions.
Weighing Features of Lung and Heart Regions for Thoracic Disease Classification
May 26, 2021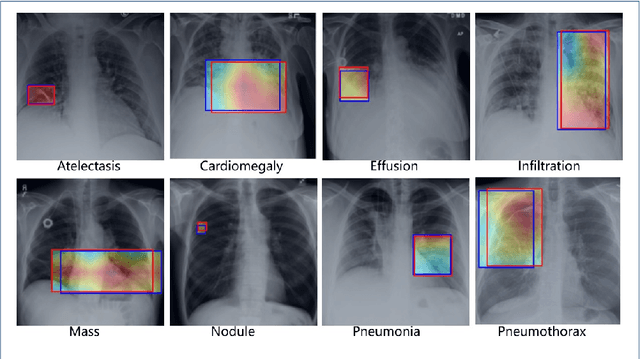
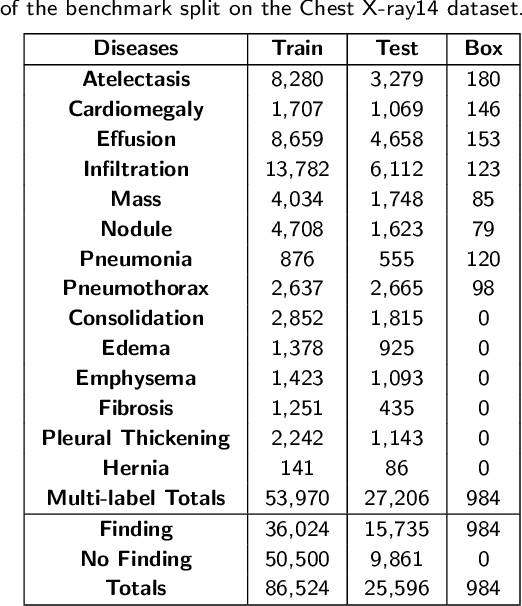
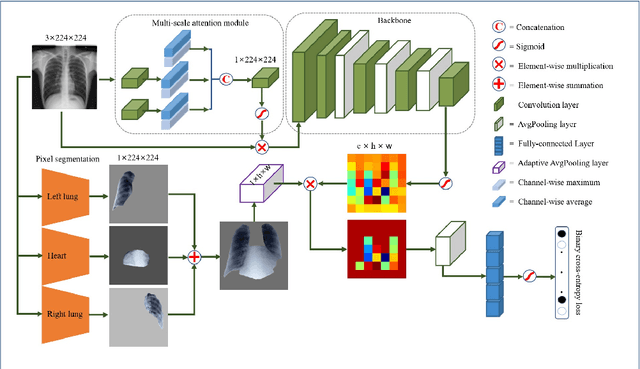
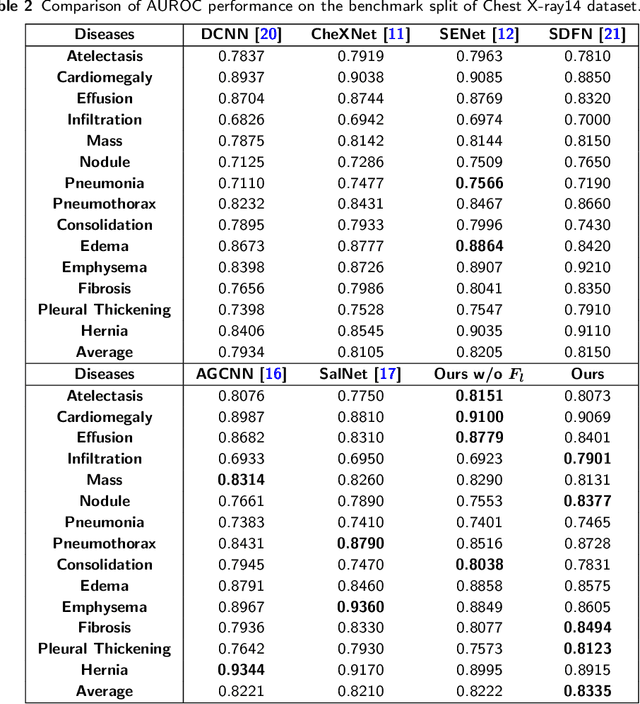
Chest X-rays are the most commonly available and affordable radiological examination for screening thoracic diseases. According to the domain knowledge of screening chest X-rays, the pathological information usually lay on the lung and heart regions. However, it is costly to acquire region-level annotation in practice, and model training mainly relies on image-level class labels in a weakly supervised manner, which is highly challenging for computer-aided chest X-ray screening. To address this issue, some methods have been proposed recently to identify local regions containing pathological information, which is vital for thoracic disease classification. Inspired by this, we propose a novel deep learning framework to explore discriminative information from lung and heart regions. We design a feature extractor equipped with a multi-scale attention module to learn global attention maps from global images. To exploit disease-specific cues effectively, we locate lung and heart regions containing pathological information by a well-trained pixel-wise segmentation model to generate binarization masks. By introducing element-wise logical AND operator on the learned global attention maps and the binarization masks, we obtain local attention maps in which pixels are $1$ for lung and heart region and $0$ for other regions. By zeroing features of non-lung and heart regions in attention maps, we can effectively exploit their disease-specific cues in lung and heart regions. Compared to existing methods fusing global and local features, we adopt feature weighting to avoid weakening visual cues unique to lung and heart regions. Evaluated by the benchmark split on the publicly available chest X-ray14 dataset, the comprehensive experiments show that our method achieves superior performance compared to the state-of-the-art methods.
Joint Multi-User Communication and Sensing Exploiting Both Signal and Environment Sparsity
Sep 06, 2021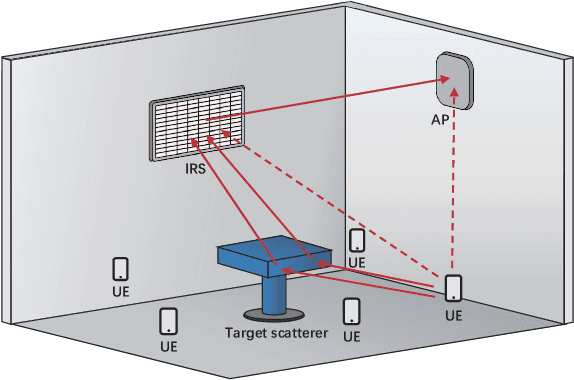
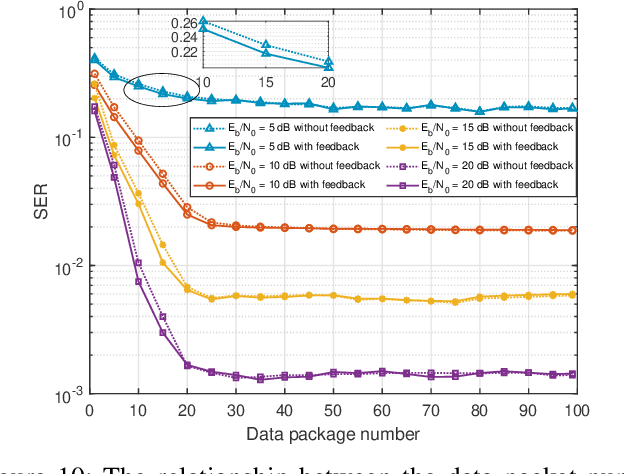
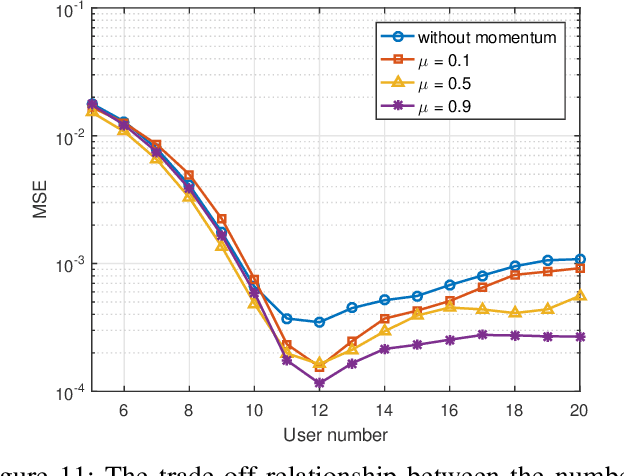
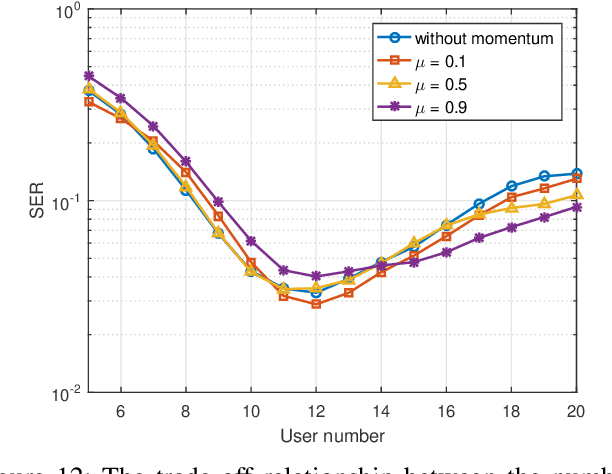
As a potential technology feature for 6G wireless networks, the idea of sensing-communication integration requires the system not only to complete reliable multi-user communication but also to achieve accurate environment sensing. In this paper, we consider such a joint communication and sensing (JCAS) scenario, in which multiple users use the sparse code multiple access (SCMA) scheme to communicate with the wireless access point (AP). Part of the user signals are scattered by the environment object and reflected by an intelligent reflective surface (IRS) before they arrive at the AP. We exploit the sparsity of both the structured user signals and the unstructured environment and propose an iterative and incremental joint multi-user communication and environment sensing scheme, in which the two processes, i.e., multi-user information detection and environment object detection, interweave with each other thanks to their intrinsic mutual dependence. The proposed algorithm is sliding-window based and also graph based, which can keep on sensing the environment as long as there are illuminating user signals. The trade-off relationship between the key system parameters is analyzed, and the simulation result validates the convergence and effectiveness of the proposed algorithm.
* Paper accepted for publication on IEEE Journal of Selected Topics in Signal Processing
Spatially-Varying Outdoor Lighting Estimation from Intrinsics
Apr 28, 2021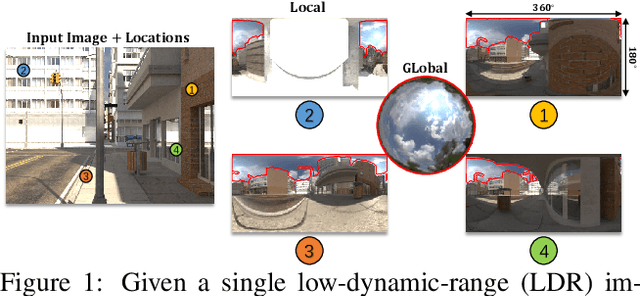
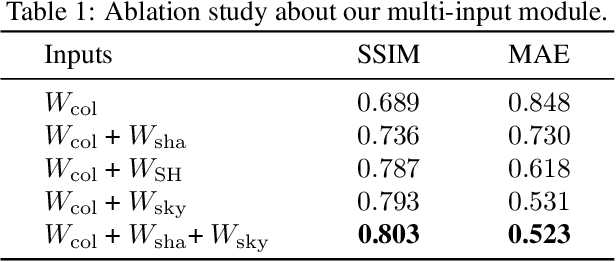
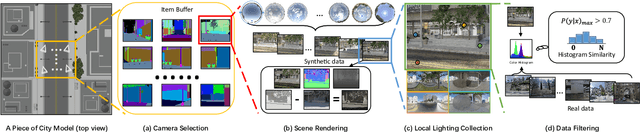
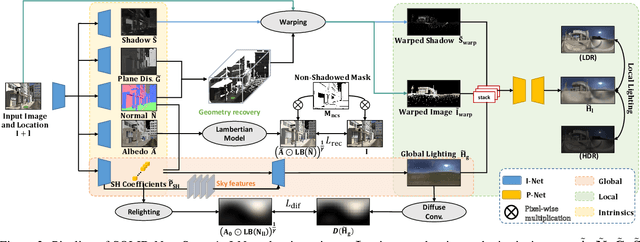
We present SOLID-Net, a neural network for spatially-varying outdoor lighting estimation from a single outdoor image for any 2D pixel location. Previous work has used a unified sky environment map to represent outdoor lighting. Instead, we generate spatially-varying local lighting environment maps by combining global sky environment map with warped image information according to geometric information estimated from intrinsics. As no outdoor dataset with image and local lighting ground truth is readily available, we introduce the SOLID-Img dataset with physically-based rendered images and their corresponding intrinsic and lighting information. We train a deep neural network to regress intrinsic cues with physically-based constraints and use them to conduct global and local lightings estimation. Experiments on both synthetic and real datasets show that SOLID-Net significantly outperforms previous methods.
Guiding Teacher Forcing with Seer Forcing for Neural Machine Translation
Jun 12, 2021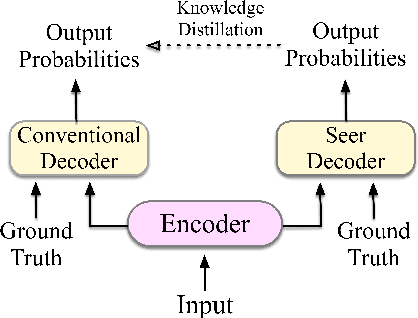
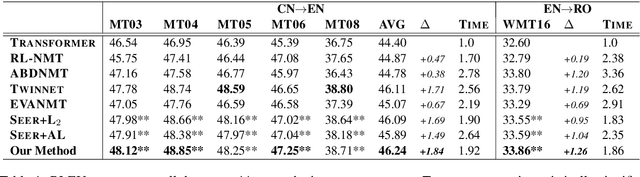
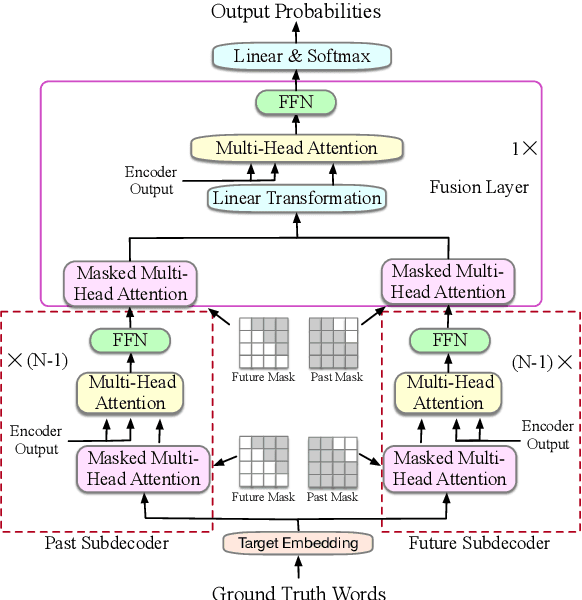
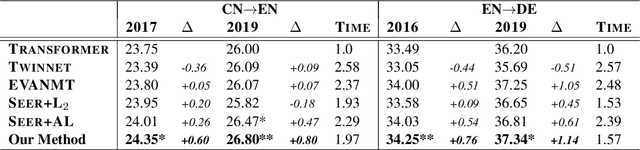
Although teacher forcing has become the main training paradigm for neural machine translation, it usually makes predictions only conditioned on past information, and hence lacks global planning for the future. To address this problem, we introduce another decoder, called seer decoder, into the encoder-decoder framework during training, which involves future information in target predictions. Meanwhile, we force the conventional decoder to simulate the behaviors of the seer decoder via knowledge distillation. In this way, at test the conventional decoder can perform like the seer decoder without the attendance of it. Experiment results on the Chinese-English, English-German and English-Romanian translation tasks show our method can outperform competitive baselines significantly and achieves greater improvements on the bigger data sets. Besides, the experiments also prove knowledge distillation the best way to transfer knowledge from the seer decoder to the conventional decoder compared to adversarial learning and L2 regularization.
Energy Minimization for IRS-aided WPCNs with Non-linear Energy Harvesting Model
Aug 31, 2021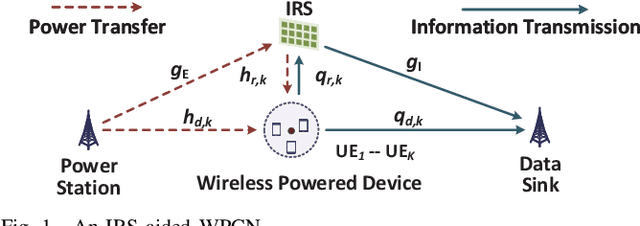
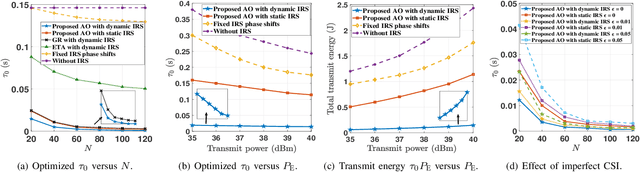
This paper considers an intelligent reflecting surface(IRS)-aided wireless powered communication network (WPCN), where devices first harvest energy from a power station (PS) in the downlink (DL) and then transmit information using non-orthogonal multiple access (NOMA) to a data sink in the uplink (UL). However, most existing works on WPCNs adopted the simplified linear energy-harvesting model and also cannot guarantee strict user quality-of-service requirements. To address these issues, we aim to minimize the total transmit energy consumption at the PS by jointly optimizing the resource allocation and IRS phase shifts over time, subject to the minimum throughput requirements of all devices. The formulated problem is decomposed into two subproblems, and solved iteratively in an alternative manner by employing difference of convex functions programming, successive convex approximation, and penalty-based algorithm. Numerical results demonstrate the significant performance gains achieved by the proposed algorithm over benchmark schemes and reveal the benefits of integrating IRS into WPCNs. In particular, employing different IRS phase shifts over UL and DL outperforms the case with static IRS beamforming.
Text mining policy: Classifying forest and landscape restoration policy agenda with neural information retrieval
Aug 07, 2019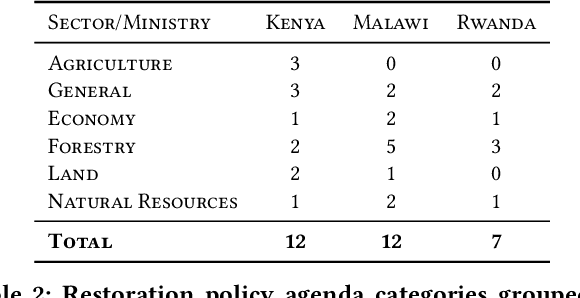
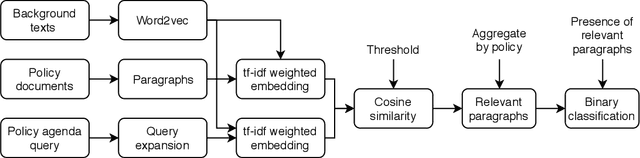


Dozens of countries have committed to restoring the ecological functionality of 350 million hectares of land by 2030. In order to achieve such wide-scale implementation of restoration, the values and priorities of multi-sectoral stakeholders must be aligned and integrated with national level commitments and other development agenda. Although misalignment across scales of policy and between stakeholders are well known barriers to implementing restoration, fast-paced policy making in multi-stakeholder environments complicates the monitoring and analysis of governance and policy. In this work, we assess the potential of machine learning to identify restoration policy agenda across diverse policy documents. An unsupervised neural information retrieval architecture is introduced that leverages transfer learning and word embeddings to create high-dimensional representations of paragraphs. Policy agenda labels are recast as information retrieval queries in order to classify policies with a cosine similarity threshold between paragraphs and query embeddings. This approach achieves a 0.83 F1-score measured across 14 policy agenda in 31 policy documents in Malawi, Kenya, and Rwanda, indicating that automated text mining can provide reliable, generalizable, and efficient analyses of restoration policy.
Information Flow in Pregroup Models of Natural Language
Nov 08, 2018

This paper is about pregroup models of natural languages, and how they relate to the explicitly categorical use of pregroups in Compositional Distributional Semantics and Natural Language Processing. These categorical interpretations make certain assumptions about the nature of natural languages that, when stated formally, may be seen to impose strong restrictions on pregroup grammars for natural languages. We formalize this as a hypothesis about the form that pregroup models of natural languages must take, and demonstrate by an artificial language example that these restrictions are not imposed by the pregroup axioms themselves. We compare and contrast the artificial language examples with natural languages (using Welsh, a language where the 'noun' type cannot be taken as primitive, as an illustrative example). The hypothesis is simply that there must exist a causal connection, or information flow, between the words of a sentence in a language whose purpose is to communicate information. This is not necessarily the case with formal languages that are simply generated by a series of 'meaning-free' rules. This imposes restrictions on the types of pregroup grammars that we expect to find in natural languages; we formalize this in algebraic, categorical, and graphical terms. We take some preliminary steps in providing conditions that ensure pregroup models satisfy these conjectured properties, and discuss the more general forms this hypothesis may take.
* In Proceedings CAPNS 2018, arXiv:1811.02701
LGA-RCNN: Loss-Guided Attention for Object Detection
May 12, 2021
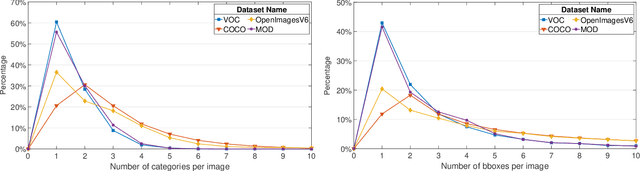
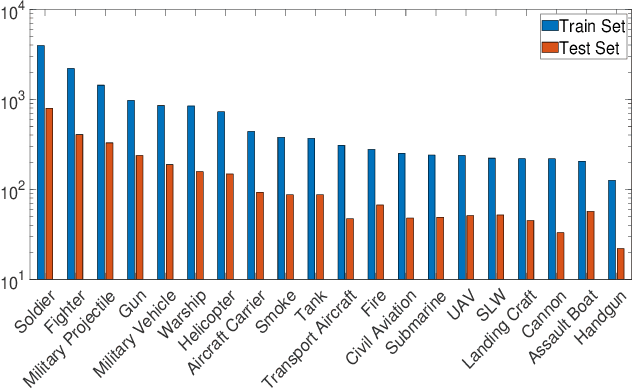
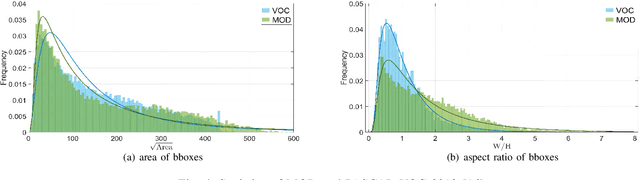
Object detection is widely studied in computer vision filed. In recent years, certain representative deep learning based detection methods along with solid benchmarks are proposed, which boosts the development of related researchs. However, existing detection methods still suffer from undesirable performance under challenges such as camouflage, blur, inter-class similarity, intra-class variance and complex environment. To address this issue, we propose LGA-RCNN which utilizes a loss-guided attention (LGA) module to highlight representative region of objects. Then, those highlighted local information are fused with global information for precise classification and localization.
Lighter Stacked Hourglass Human Pose Estimation
Jul 28, 2021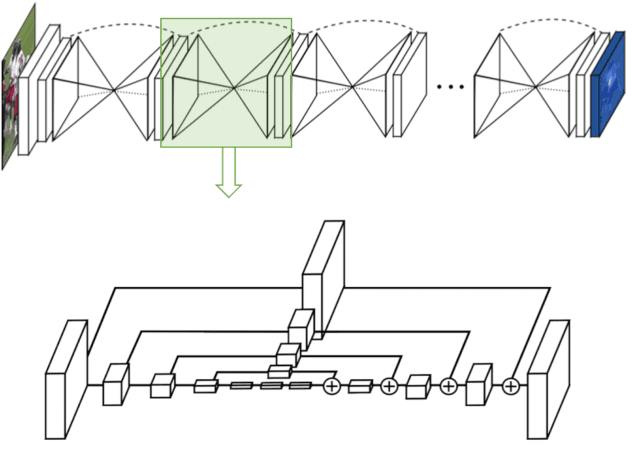
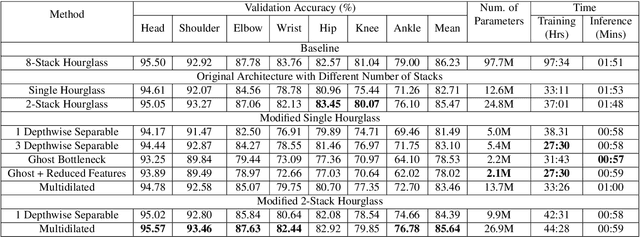
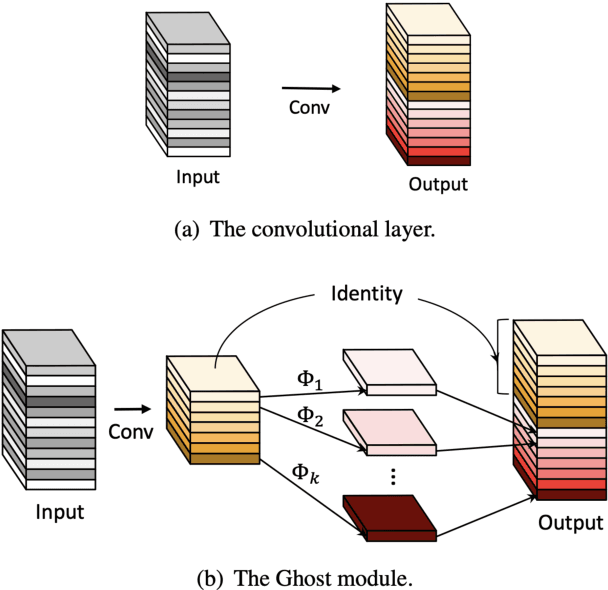
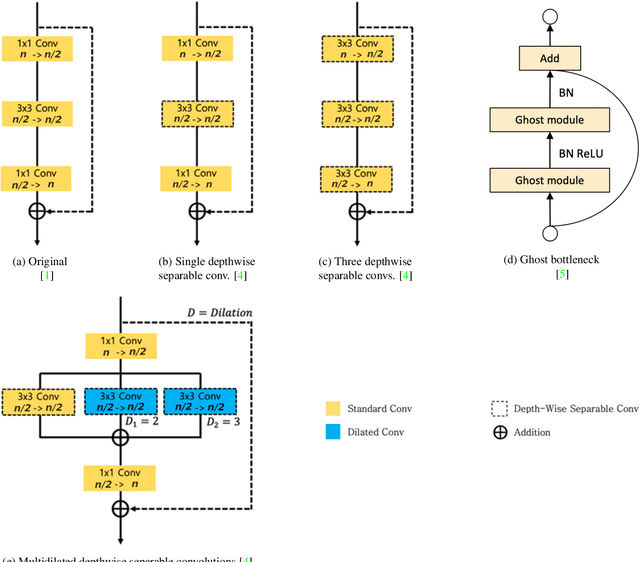
Human pose estimation (HPE) is one of the most challenging tasks in computer vision as humans are deformable by nature and thus their pose has so much variance. HPE aims to correctly identify the main joint locations of a single person or multiple people in a given image or video. Locating joints of a person in images or videos is an important task that can be applied in action recognition and object tracking. As have many computer vision tasks, HPE has advanced massively with the introduction of deep learning to the field. In this paper, we focus on one of the deep learning-based approaches of HPE proposed by Newell et al., which they named the stacked hourglass network. Their approach is widely used in many applications and is regarded as one of the best works in this area. The main focus of their approach is to capture as much information as it can at all possible scales so that a coherent understanding of the local features and full-body location is achieved. Their findings demonstrate that important cues such as orientation of a person, arrangement of limbs, and adjacent joints' relative location can be identified from multiple scales at different resolutions. To do so, they makes use of a single pipeline to process images in multiple resolutions, which comprises a skip layer to not lose spatial information at each resolution. The resolution of the images stretches as lower as 4x4 to make sure that a smaller spatial feature is included. In this study, we study the effect of architectural modifications on the computational speed and accuracy of the network.