 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Teacher Forcing with Seer Forcing for Neural Machine Translation
Paper and Code
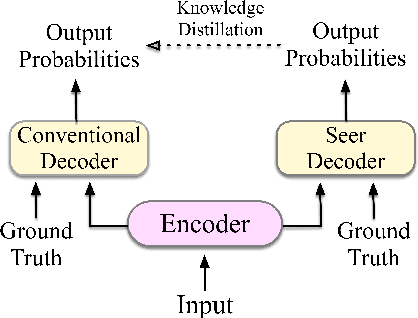
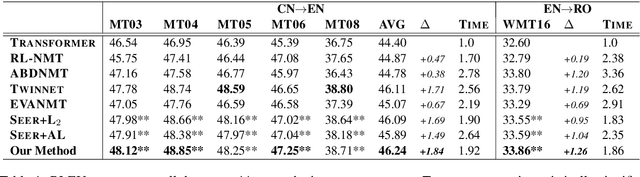
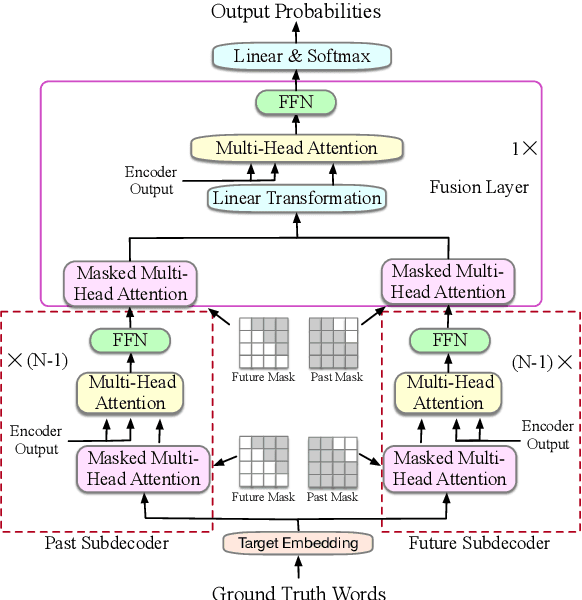
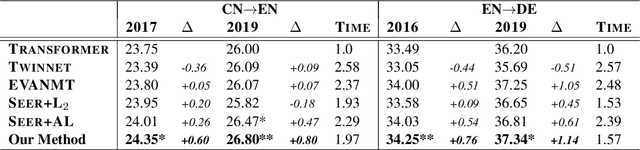
Although teacher forcing has become the main training paradigm for neural machine translation, it usually makes predictions only conditioned on past information, and hence lacks global planning for the future. To address this problem, we introduce another decoder, called seer decoder, into the encoder-decoder framework during training, which involves future information in target predictions. Meanwhile, we force the conventional decoder to simulate the behaviors of the seer decoder via knowledge distillation. In this way, at test the conventional decoder can perform like the seer decoder without the attendance of it. Experiment results on the Chinese-English, English-German and English-Romanian translation tasks show our method can outperform competitive baselines significantly and achieves greater improvements on the bigger data sets. Besides, the experiments also prove knowledge distillation the best way to transfer knowledge from the seer decoder to the conventional decoder compared to adversarial learning and L2 regularization.