 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Goal-Aware Neural SAT Solver
Jun 14, 2021
Modern neural networks obtain information about the problem and calculate the output solely from the input values. We argue that it is not always optimal, and the network's performance can be significantly improved by augmenting it with a query mechanism that allows the network to make several solution trials at run time and get feedback on the loss value on each trial. To demonstrate the capabilities of the query mechanism, we formulate an unsupervised (not dependant on labels) loss function for Boolean Satisfiability Problem (SAT) and theoretically show that it allows the network to extract rich information about the problem. We then propose a neural SAT solver with a query mechanism called QuerySAT and show that it outperforms the neural baseline on a wide range of SAT tasks and the classical baselines on SHA-1 preimage attack and 3-SAT task.
Mutual Clustering on Comparative Texts via Heterogeneous Information Networks
Mar 09, 2019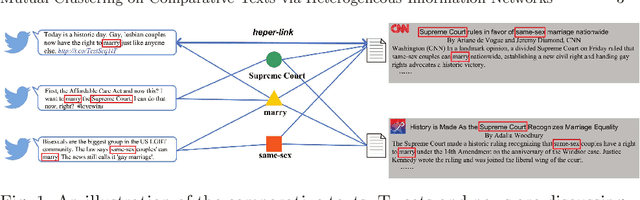
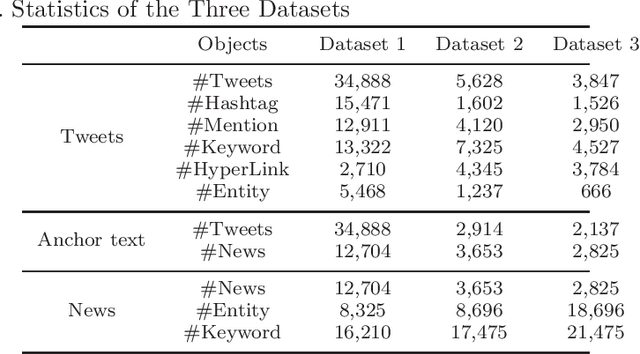
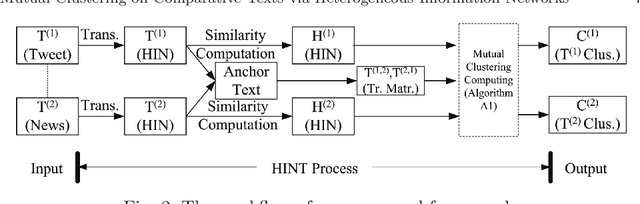
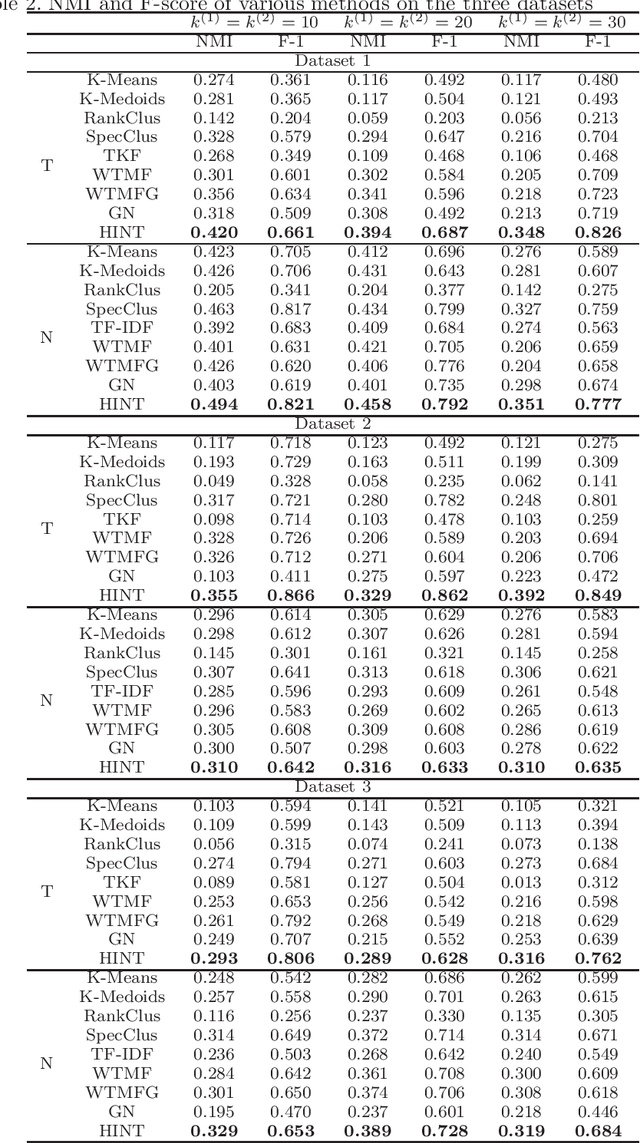
Currently, many intelligence systems contain the texts from multi-sources, e.g., bulletin board system (BBS) posts, tweets and news. These texts can be ``comparative'' since they may be semantically correlated and thus provide us with different perspectives toward the same topics or events. To better organize the multi-sourced texts and obtain more comprehensive knowledge, we propose to study the novel problem of Mutual Clustering on Comparative Texts (MCCT), which aims to cluster the comparative texts simultaneously and collaboratively. The MCCT problem is difficult to address because 1) comparative texts usually present different data formats and structures and thus they are hard to organize, and 2) there lacks an effective method to connect the semantically correlated comparative texts to facilitate clustering them in an unified way. To this aim, in this paper we propose a Heterogeneous Information Network-based Text clustering framework HINT. HINT first models multi-sourced texts (e.g. news and tweets) as heterogeneous information networks by introducing the shared ``anchor texts'' to connect the comparative texts. Next, two similarity matrices based on HINT as well as a transition matrix for cross-text-source knowledge transfer are constructed. Comparative texts clustering are then conducted by utilizing the constructed matrices. Finally, a mutual clustering algorithm is also proposed to further unify the separate clustering results of the comparative texts by introducing a clustering consistency constraint. We conduct extensive experimental on three tweets-news datasets, and the results demonstrate the effectiveness and robustness of the proposed method in addressing the MCCT problem.
Spike-inspired Rank Coding for Fast and Accurate Recurrent Neural Networks
Oct 06, 2021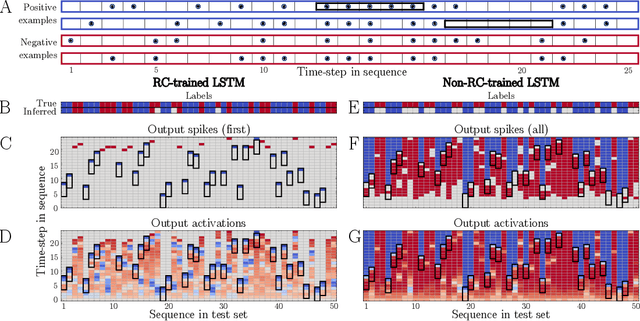
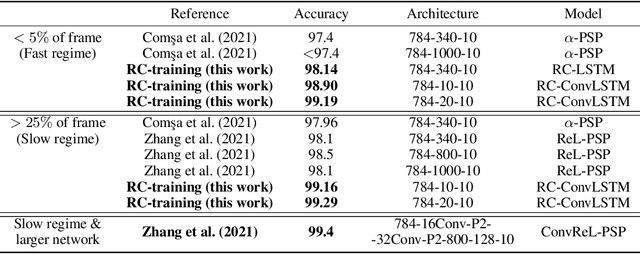

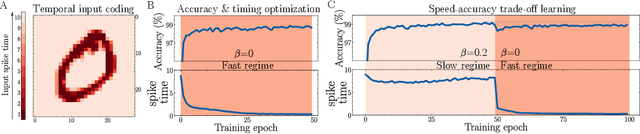
Biological spiking neural networks (SNNs) can temporally encode information in their outputs, e.g. in the rank order in which neurons fire, whereas artificial neural networks (ANNs) conventionally do not. As a result, models of SNNs for neuromorphic computing are regarded as potentially more rapid and efficient than ANNs when dealing with temporal input. On the other hand, ANNs are simpler to train, and usually achieve superior performance. Here we show that temporal coding such as rank coding (RC) inspired by SNNs can also be applied to conventional ANNs such as LSTMs, and leads to computational savings and speedups. In our RC for ANNs, we apply backpropagation through time using the standard real-valued activations, but only from a strategically early time step of each sequential input example, decided by a threshold-crossing event. Learning then incorporates naturally also _when_ to produce an output, without other changes to the model or the algorithm. Both the forward and the backward training pass can be significantly shortened by skipping the remaining input sequence after that first event. RC-training also significantly reduces time-to-insight during inference, with a minimal decrease in accuracy. The desired speed-accuracy trade-off is tunable by varying the threshold or a regularization parameter that rewards output entropy. We demonstrate these in two toy problems of sequence classification, and in a temporally-encoded MNIST dataset where our RC model achieves 99.19% accuracy after the first input time-step, outperforming the state of the art in temporal coding with SNNs, as well as in spoken-word classification of Google Speech Commands, outperforming non-RC-trained early inference with LSTMs.
Deep Bayesian inference for seismic imaging with tasks
Oct 10, 2021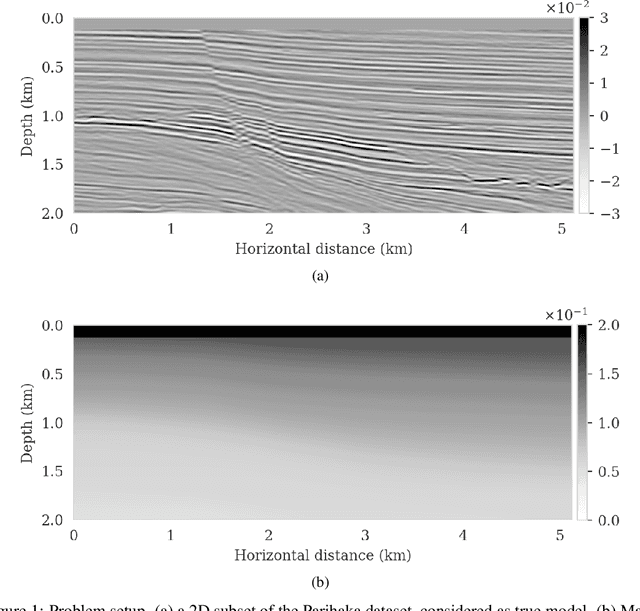
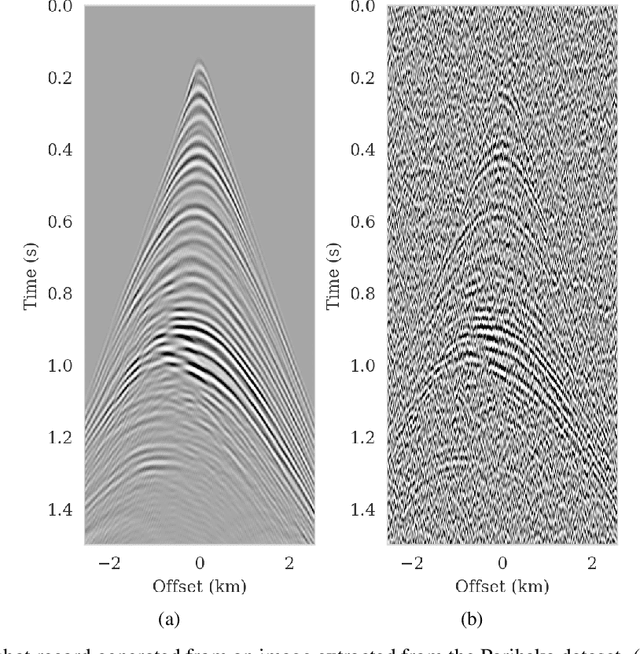
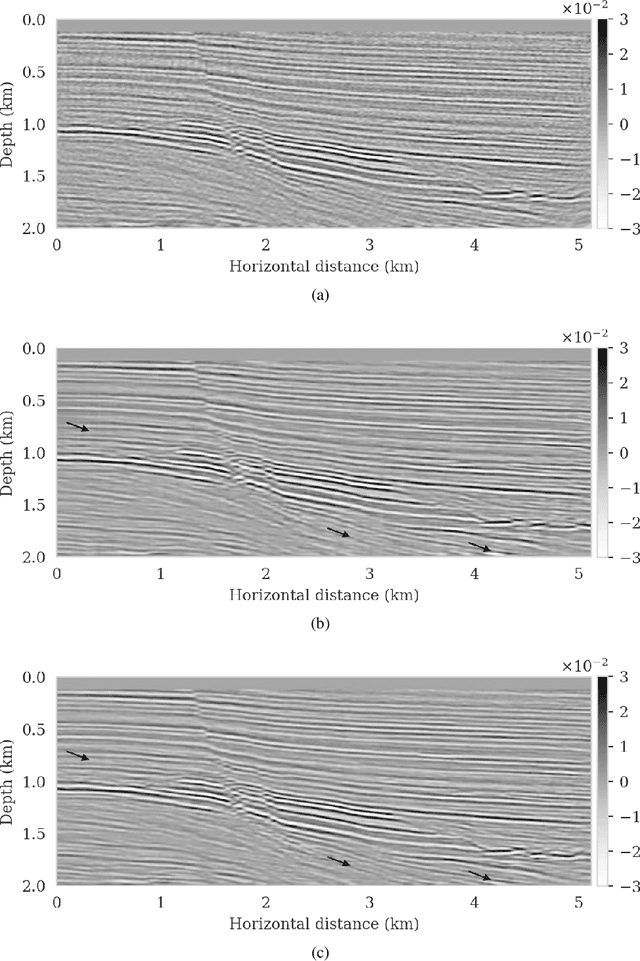
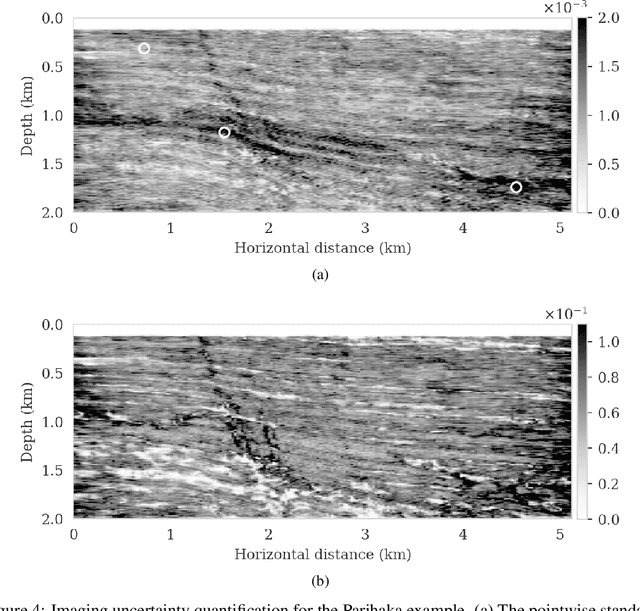
We propose to use techniques from Bayesian inference and deep neural networks to translate uncertainty in seismic imaging to uncertainty in tasks performed on the image, such as horizon tracking. Seismic imaging is an ill-posed inverse problem because of unavoidable bandwidth and aperture limitations, which that is hampered by the presence of noise and linearization errors. Many regularization methods, such as transform-domain sparsity promotion, have been designed to deal with the adverse effects of these errors, however, these methods run the risk of biasing the solution and do not provide information on uncertainty in the image space and how this uncertainty impacts certain tasks on the image. A systematic approach is proposed to translate uncertainty due to noise in the data to confidence intervals of automatically tracked horizons in the image. The uncertainty is characterized by a convolutional neural network (CNN) and to assess these uncertainties, samples are drawn from the posterior distribution of the CNN weights, used to parameterize the image. Compared to traditional priors, in the literature it is argued that these CNNs introduce a flexible inductive bias that is a surprisingly good fit for many diverse domains in imaging. The method of stochastic gradient Langevin dynamics is employed to sample from the posterior distribution. This method is designed to handle large scale Bayesian inference problems with computationally expensive forward operators as in seismic imaging. Aside from offering a robust alternative to maximum a posteriori estimate that is prone to overfitting, access to these samples allow us to translate uncertainty in the image, due to noise in the data, to uncertainty on the tracked horizons. For instance, it admits estimates for the pointwise standard deviation on the image and for confidence intervals on its automatically tracked horizons.
GRNN: Generative Regression Neural Network -- A Data Leakage Attack for Federated Learning
May 02, 2021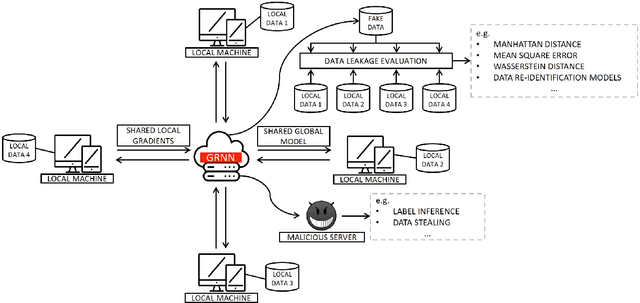
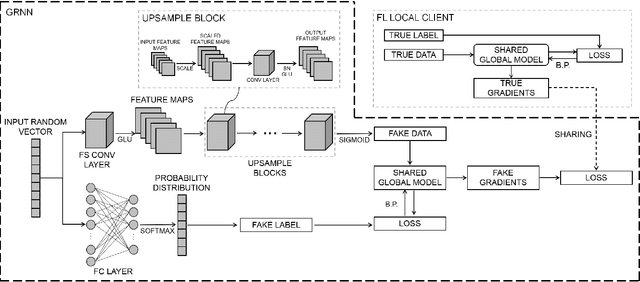

Data privacy has become an increasingly important issue in machine learning. Many approaches have been developed to tackle this issue, e.g., cryptography (Homomorphic Encryption, Differential Privacy, etc.) and collaborative training (Secure Multi-Party Computation, Distributed Learning and Federated Learning). These techniques have a particular focus on data encryption or secure local computation. They transfer the intermediate information to the third-party to compute the final result. Gradient exchanging is commonly considered to be a secure way of training a robust model collaboratively in deep learning. However, recent researches have demonstrated that sensitive information can be recovered from the shared gradient. Generative Adversarial Networks (GAN), in particular, have shown to be effective in recovering those information. However, GAN based techniques require additional information, such as class labels which are generally unavailable for privacy persevered learning. In this paper, we show that, in Federated Learning (FL) system, image-based privacy data can be easily recovered in full from the shared gradient only via our proposed Generative Regression Neural Network (GRNN). We formulate the attack to be a regression problem and optimise two branches of the generative model by minimising the distance between gradients. We evaluate our method on several image classification tasks. The results illustrate that our proposed GRNN outperforms state-of-the-art methods with better stability, stronger robustness, and higher accuracy. It also has no convergence requirement to the global FL model. Moreover, we demonstrate information leakage using face re-identification. Some defense strategies are also discussed in this work.
OadTR: Online Action Detection with Transformers
Jun 21, 2021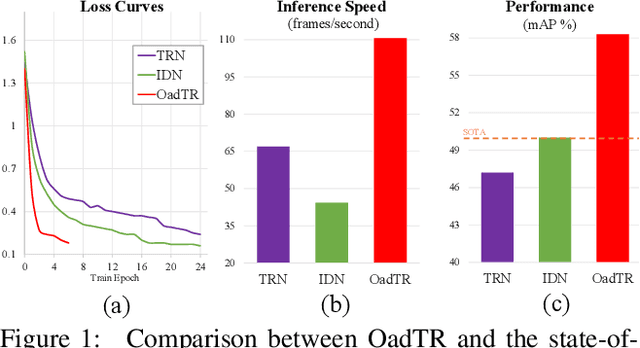

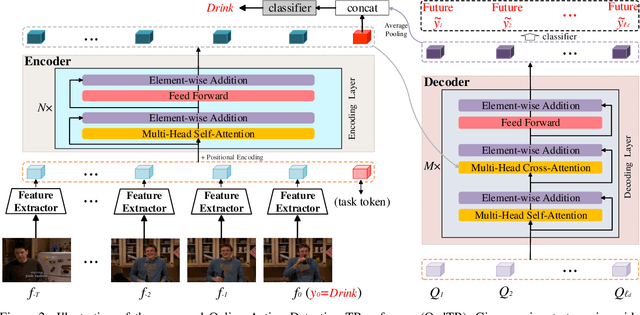
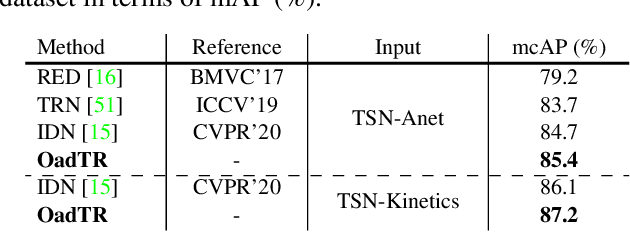
Most recent approaches for online action detection tend to apply Recurrent Neural Network (RNN) to capture long-range temporal structure. However, RNN suffers from non-parallelism and gradient vanishing, hence it is hard to be optimized. In this paper, we propose a new encoder-decoder framework based on Transformers, named OadTR, to tackle these problems. The encoder attached with a task token aims to capture the relationships and global interactions between historical observations. The decoder extracts auxiliary information by aggregating anticipated future clip representations. Therefore, OadTR can recognize current actions by encoding historical information and predicting future context simultaneously. We extensively evaluate the proposed OadTR on three challenging datasets: HDD, TVSeries, and THUMOS14. The experimental results show that OadTR achieves higher training and inference speeds than current RNN based approaches, and significantly outperforms the state-of-the-art methods in terms of both mAP and mcAP. Code is available at https://github.com/wangxiang1230/OadTR.
3D Face Recognition: A Survey
Aug 25, 2021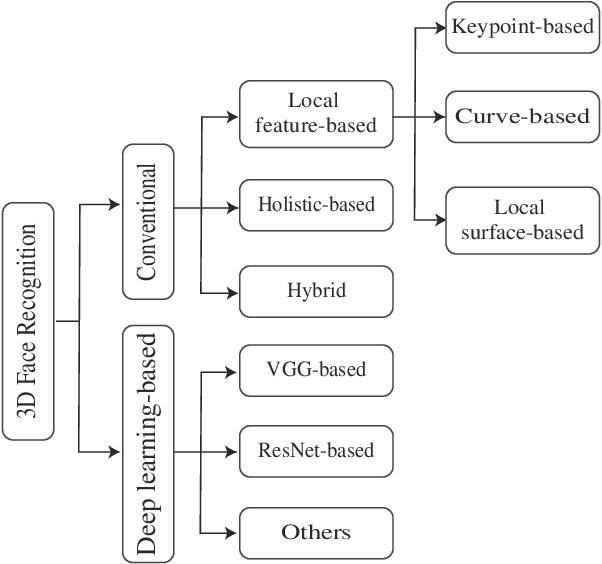
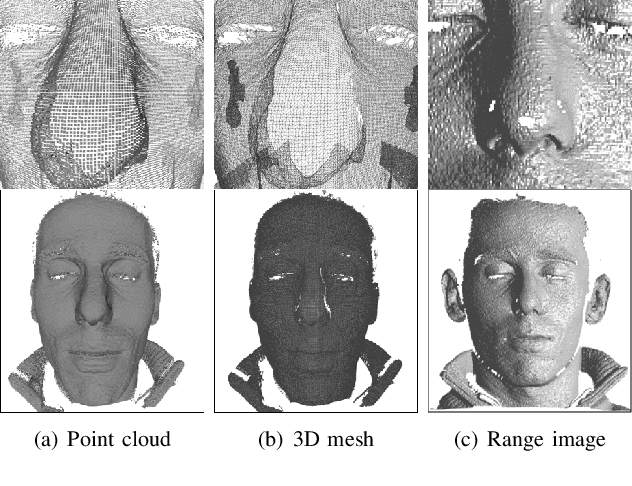
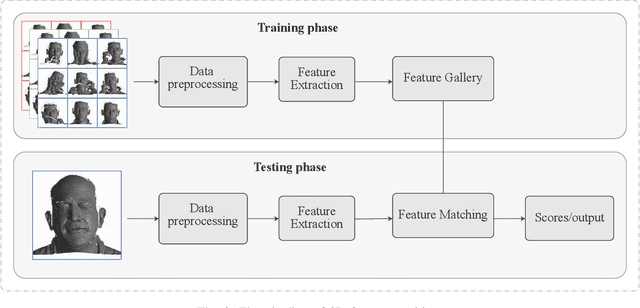
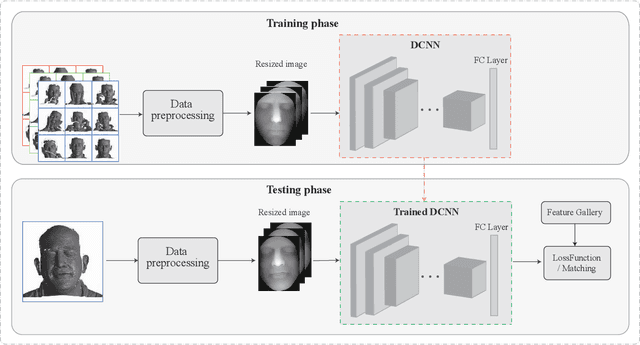
Face recognition is one of the most studied research topics in the community. In recent years, the research on face recognition has shifted to using 3D facial surfaces, as more discriminating features can be represented by the 3D geometric information. This survey focuses on reviewing the 3D face recognition techniques developed in the past ten years which are generally categorized into conventional methods and deep learning methods. The categorized techniques are evaluated using detailed descriptions of the representative works. The advantages and disadvantages of the techniques are summarized in terms of accuracy, complexity and robustness to face variation (expression, pose and occlusions, etc). The main contribution of this survey is that it comprehensively covers both conventional methods and deep learning methods on 3D face recognition. In addition, a review of available 3D face databases is provided, along with the discussion of future research challenges and directions.
Early Lane Change Prediction for Automated Driving Systems Using Multi-Task Attention-based Convolutional Neural Networks
Sep 22, 2021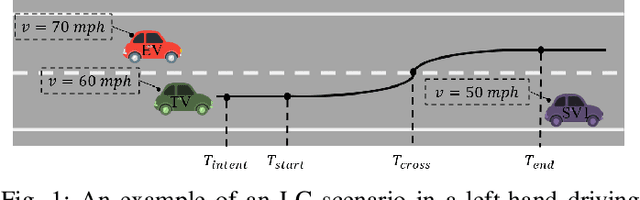
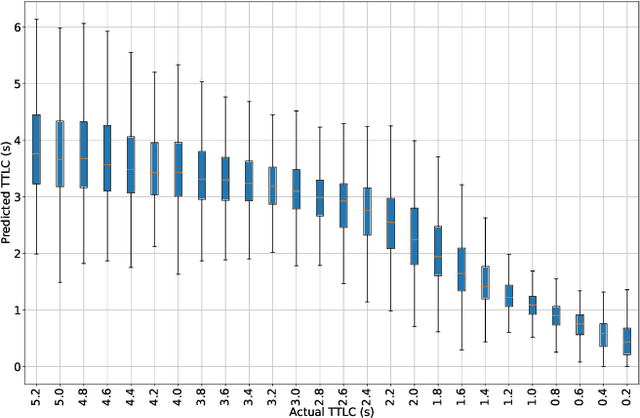
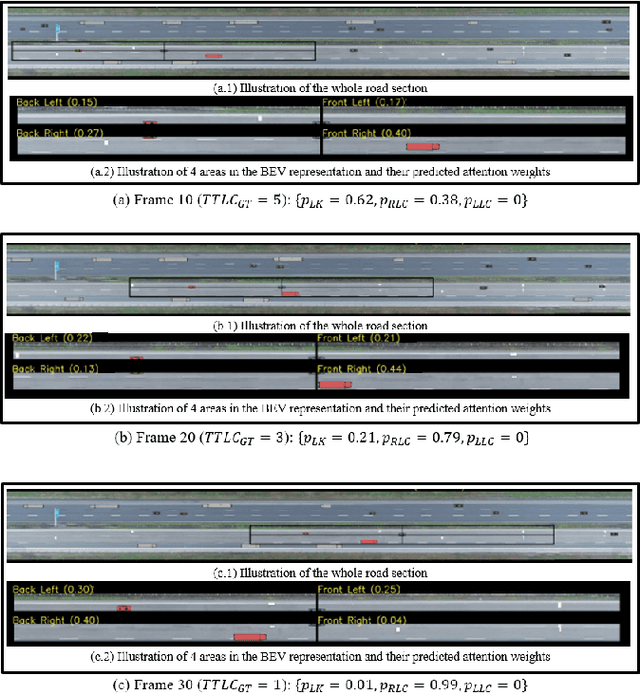

Lane change (LC) is one of the safety-critical manoeuvres in highway driving according to various road accident records. Thus, reliably predicting such manoeuvre in advance is critical for the safe and comfortable operation of automated driving systems. The majority of previous studies rely on detecting a manoeuvre that has been already started, rather than predicting the manoeuvre in advance. Furthermore, most of the previous works do not estimate the key timings of the manoeuvre (e.g., crossing time), which can actually yield more useful information for the decision making in the ego vehicle. To address these shortcomings, this paper proposes a novel multi-task model to simultaneously estimate the likelihood of LC manoeuvres and the time-to-lane-change (TTLC). In both tasks, an attention-based convolutional neural network (CNN) is used as a shared feature extractor from a bird's eye view representation of the driving environment. The spatial attention used in the CNN model improves the feature extraction process by focusing on the most relevant areas of the surrounding environment. In addition, two novel curriculum learning schemes are employed to train the proposed approach. The extensive evaluation and comparative analysis of the proposed method in existing benchmark datasets show that the proposed method outperforms state-of-the-art LC prediction models, particularly considering long-term prediction performance.
Confidence-guided Adaptive Gate and Dual Differential Enhancement for Video Salient Object Detection
May 14, 2021
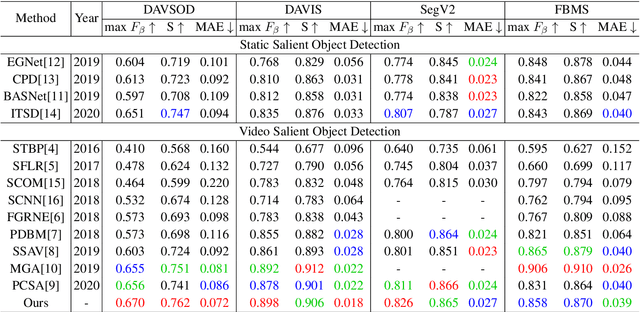
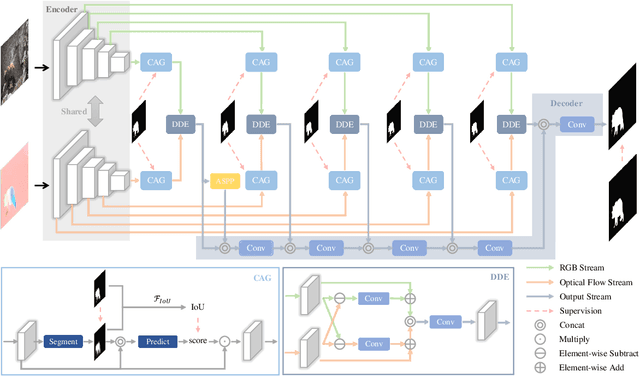
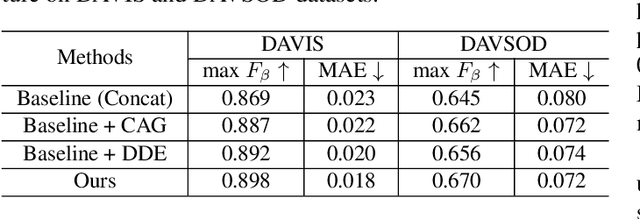
Video salient object detection (VSOD) aims to locate and segment the most attractive object by exploiting both spatial cues and temporal cues hidden in video sequences. However, spatial and temporal cues are often unreliable in real-world scenarios, such as low-contrast foreground, fast motion, and multiple moving objects. To address these problems, we propose a new framework to adaptively capture available information from spatial and temporal cues, which contains Confidence-guided Adaptive Gate (CAG) modules and Dual Differential Enhancement (DDE) modules. For both RGB features and optical flow features, CAG estimates confidence scores supervised by the IoU between predictions and the ground truths to re-calibrate the information with a gate mechanism. DDE captures the differential feature representation to enrich the spatial and temporal information and generate the fused features. Experimental results on four widely used datasets demonstrate the effectiveness of the proposed method against thirteen state-of-the-art methods.
Self-Supervised Detection of Contextual Synonyms in a Multi-Class Setting: Phenotype Annotation Use Case
Sep 04, 2021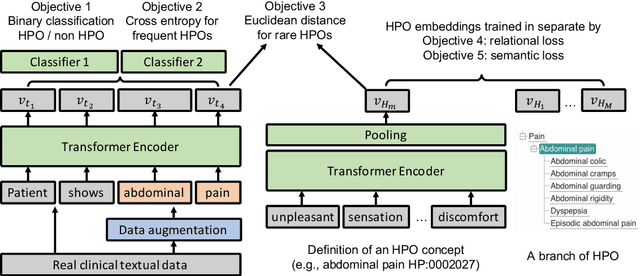
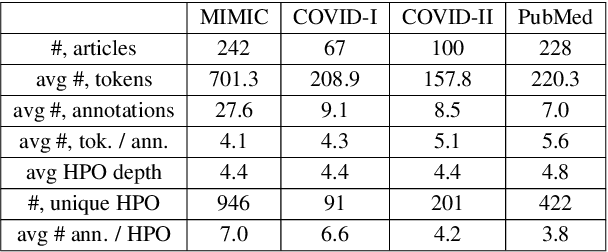
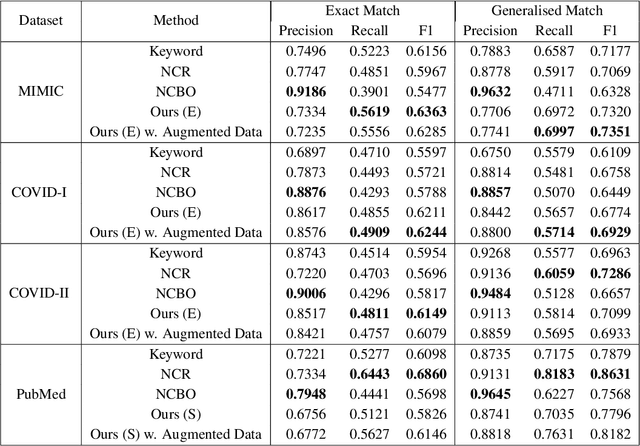
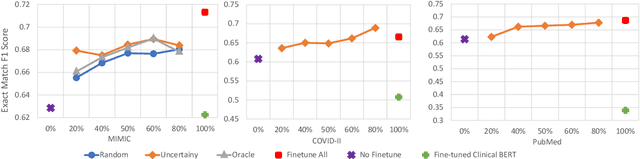
Contextualised word embeddings is a powerful tool to detect contextual synonyms. However, most of the current state-of-the-art (SOTA) deep learning concept extraction methods remain supervised and underexploit the potential of the context. In this paper, we propose a self-supervised pre-training approach which is able to detect contextual synonyms of concepts being training on the data created by shallow matching. We apply our methodology in the sparse multi-class setting (over 15,000 concepts) to extract phenotype information from electronic health records. We further investigate data augmentation techniques to address the problem of the class sparsity. Our approach achieves a new SOTA for the unsupervised phenotype concept annotation on clinical text on F1 and Recall outperforming the previous SOTA with a gain of up to 4.5 and 4.0 absolute points, respectively. After fine-tuning with as little as 20\% of the labelled data, we also outperform BioBERT and ClinicalBERT. The extrinsic evaluation on three ICU benchmarks also shows the benefit of using the phenotypes annotated by our model as features.