 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Local Patterns to Global Understanding: Cross-Stock Trend Integration for Enhanced Predictive Modeling
May 22, 2025Stock price prediction is a critical area of financial forecasting, traditionally approached by training models using the historical price data of individual stocks. While these models effectively capture single-stock patterns, they fail to leverage potential correlations among stock trends, which could improve predictive performance. Current single-stock learning methods are thus limited in their ability to provide a broader understanding of price dynamics across multiple stocks. To address this, we propose a novel method that merges local patterns into a global understanding through cross-stock pattern integration. Our strategy is inspired by Federated Learning (FL), a paradigm designed for decentralized model training. FL enables collaborative learning across distributed datasets without sharing raw data, facilitating the aggregation of global insights while preserving data privacy. In our adaptation, we train models on individual stock data and iteratively merge them to create a unified global model. This global model is subsequently fine-tuned on specific stock data to retain local relevance. The proposed strategy enables parallel training of individual stock models, facilitating efficient utilization of computational resources and reducing overall training time. We conducted extensive experiments to evaluate the proposed method, demonstrating that it outperforms benchmark models and enhances the predictive capabilities of state-of-the-art approaches. Our results highlight the efficacy of Cross-Stock Trend Integration (CSTI) in advancing stock price prediction, offering a robust alternative to traditional single-stock learning methodologies.
Distributed Learning for UAV Swarms
Oct 21, 2024Unmanned Aerial Vehicle (UAV) swarms are increasingly deployed in dynamic, data-rich environments for applications such as environmental monitoring and surveillance. These scenarios demand efficient data processing while maintaining privacy and security, making Federated Learning (FL) a promising solution. FL allows UAVs to collaboratively train global models without sharing raw data, but challenges arise due to the non-Independent and Identically Distributed (non-IID) nature of the data collected by UAVs. In this study, we show an integration of the state-of-the-art FL methods to UAV Swarm application and invetigate the performance of multiple aggregation methods (namely FedAvg, FedProx, FedOpt, and MOON) with a particular focus on tackling non-IID on a variety of datasets, specifically MNIST for baseline performance, CIFAR10 for natural object classification, EuroSAT for environment monitoring, and CelebA for surveillance. These algorithms were selected to cover improved techniques on both client-side updates and global aggregation. Results show that while all algorithms perform comparably on IID data, their performance deteriorates significantly under non-IID conditions. FedProx demonstrated the most stable overall performance, emphasising the importance of regularising local updates in non-IID environments to mitigate drastic deviations in local models.
Triplane Grasping: Efficient 6-DoF Grasping with Single RGB Images
Oct 21, 2024



Reliable object grasping is one of the fundamental tasks in robotics. However, determining grasping pose based on single-image input has long been a challenge due to limited visual information and the complexity of real-world objects. In this paper, we propose Triplane Grasping, a fast grasping decision-making method that relies solely on a single RGB-only image as input. Triplane Grasping creates a hybrid Triplane-Gaussian 3D representation through a point decoder and a triplane decoder, which produce an efficient and high-quality reconstruction of the object to be grasped to meet real-time grasping requirements. We propose to use an end-to-end network to generate 6-DoF parallel-jaw grasp distributions directly from 3D points in the point cloud as potential grasp contacts and anchor the grasp pose in the observed data. Experiments demonstrate that our method achieves rapid modeling and grasping pose decision-making for daily objects, and exhibits a high grasping success rate in zero-shot scenarios.
Task-oriented Robotic Manipulation with Vision Language Models
Oct 21, 2024



Vision-Language Models (VLMs) play a crucial role in robotic manipulation by enabling robots to understand and interpret the visual properties of objects and their surroundings, allowing them to perform manipulation based on this multimodal understanding. However, understanding object attributes and spatial relationships is a non-trivial task but is critical in robotic manipulation tasks. In this work, we present a new dataset focused on spatial relationships and attribute assignment and a novel method to utilize VLMs to perform object manipulation with task-oriented, high-level input. In this dataset, the spatial relationships between objects are manually described as captions. Additionally, each object is labeled with multiple attributes, such as fragility, mass, material, and transparency, derived from a fine-tuned vision language model. The embedded object information from captions are automatically extracted and transformed into a data structure (in this case, tree, for demonstration purposes) that captures the spatial relationships among the objects within each image. The tree structures, along with the object attributes, are then fed into a language model to transform into a new tree structure that determines how these objects should be organized in order to accomplish a specific (high-level) task. We demonstrate that our method not only improves the comprehension of spatial relationships among objects in the visual environment but also enables robots to interact with these objects more effectively. As a result, this approach significantly enhances spatial reasoning in robotic manipulation tasks. To our knowledge, this is the first method of its kind in the literature, offering a novel solution that allows robots to more efficiently organize and utilize objects in their surroundings.
An Element-Wise Weights Aggregation Method for Federated Learning
Apr 24, 2024Federated learning (FL) is a powerful Machine Learning (ML) paradigm that enables distributed clients to collaboratively learn a shared global model while keeping the data on the original device, thereby preserving privacy. A central challenge in FL is the effective aggregation of local model weights from disparate and potentially unbalanced participating clients. Existing methods often treat each client indiscriminately, applying a single proportion to the entire local model. However, it is empirically advantageous for each weight to be assigned a specific proportion. This paper introduces an innovative Element-Wise Weights Aggregation Method for Federated Learning (EWWA-FL) aimed at optimizing learning performance and accelerating convergence speed. Unlike traditional FL approaches, EWWA-FL aggregates local weights to the global model at the level of individual elements, thereby allowing each participating client to make element-wise contributions to the learning process. By taking into account the unique dataset characteristics of each client, EWWA-FL enhances the robustness of the global model to different datasets while also achieving rapid convergence. The method is flexible enough to employ various weighting strategies. Through comprehensive experiments, we demonstrate the advanced capabilities of EWWA-FL, showing significant improvements in both accuracy and convergence speed across a range of backbones and benchmarks.
A Survey on Vulnerability of Federated Learning: A Learning Algorithm Perspective
Nov 27, 2023This review paper takes a comprehensive look at malicious attacks against FL, categorizing them from new perspectives on attack origins and targets, and providing insights into their methodology and impact. In this survey, we focus on threat models targeting the learning process of FL systems. Based on the source and target of the attack, we categorize existing threat models into four types, Data to Model (D2M), Model to Data (M2D), Model to Model (M2M) and composite attacks. For each attack type, we discuss the defense strategies proposed, highlighting their effectiveness, assumptions and potential areas for improvement. Defense strategies have evolved from using a singular metric to excluding malicious clients, to employing a multifaceted approach examining client models at various phases. In this survey paper, our research indicates that the to-learn data, the learning gradients, and the learned model at different stages all can be manipulated to initiate malicious attacks that range from undermining model performance, reconstructing private local data, and to inserting backdoors. We have also seen these threat are becoming more insidious. While earlier studies typically amplified malicious gradients, recent endeavors subtly alter the least significant weights in local models to bypass defense measures. This literature review provides a holistic understanding of the current FL threat landscape and highlights the importance of developing robust, efficient, and privacy-preserving defenses to ensure the safe and trusted adoption of FL in real-world applications.
Gradient Leakage Defense with Key-Lock Module for Federated Learning
May 06, 2023



Federated Learning (FL) is a widely adopted privacy-preserving machine learning approach where private data remains local, enabling secure computations and the exchange of local model gradients between local clients and third-party parameter servers. However, recent findings reveal that privacy may be compromised and sensitive information potentially recovered from shared gradients. In this study, we offer detailed analysis and a novel perspective on understanding the gradient leakage problem. These theoretical works lead to a new gradient leakage defense technique that secures arbitrary model architectures using a private key-lock module. Only the locked gradient is transmitted to the parameter server for global model aggregation. Our proposed learning method is resistant to gradient leakage attacks, and the key-lock module is designed and trained to ensure that, without the private information of the key-lock module: a) reconstructing private training data from the shared gradient is infeasible; and b) the global model's inference performance is significantly compromised. We discuss the theoretical underpinnings of why gradients can leak private information and provide theoretical proof of our method's effectiveness. We conducted extensive empirical evaluations with a total of forty-four models on several popular benchmarks, demonstrating the robustness of our proposed approach in both maintaining model performance and defending against gradient leakage attacks.
GRNN: Generative Regression Neural Network -- A Data Leakage Attack for Federated Learning
May 02, 2021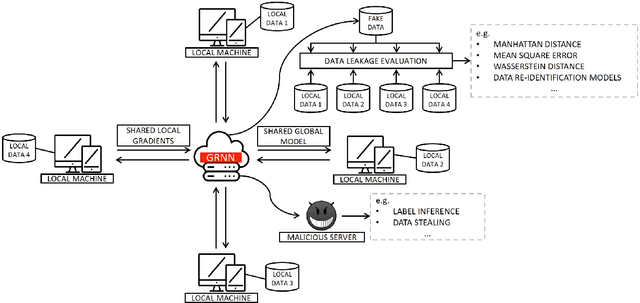
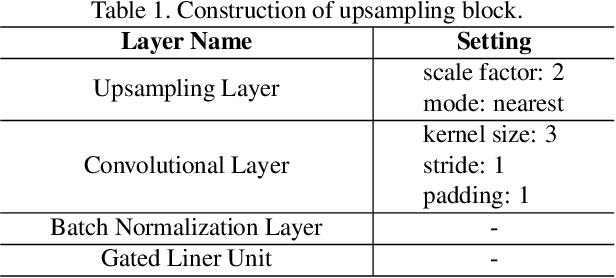
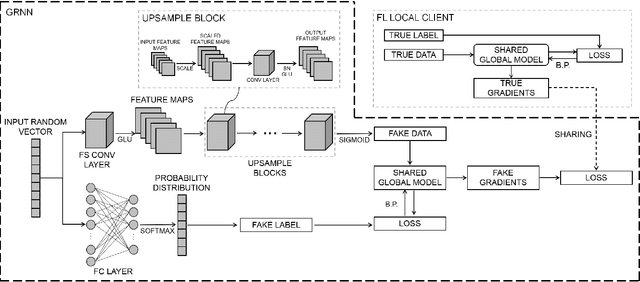

Data privacy has become an increasingly important issue in machine learning. Many approaches have been developed to tackle this issue, e.g., cryptography (Homomorphic Encryption, Differential Privacy, etc.) and collaborative training (Secure Multi-Party Computation, Distributed Learning and Federated Learning). These techniques have a particular focus on data encryption or secure local computation. They transfer the intermediate information to the third-party to compute the final result. Gradient exchanging is commonly considered to be a secure way of training a robust model collaboratively in deep learning. However, recent researches have demonstrated that sensitive information can be recovered from the shared gradient. Generative Adversarial Networks (GAN), in particular, have shown to be effective in recovering those information. However, GAN based techniques require additional information, such as class labels which are generally unavailable for privacy persevered learning. In this paper, we show that, in Federated Learning (FL) system, image-based privacy data can be easily recovered in full from the shared gradient only via our proposed Generative Regression Neural Network (GRNN). We formulate the attack to be a regression problem and optimise two branches of the generative model by minimising the distance between gradients. We evaluate our method on several image classification tasks. The results illustrate that our proposed GRNN outperforms state-of-the-art methods with better stability, stronger robustness, and higher accuracy. It also has no convergence requirement to the global FL model. Moreover, we demonstrate information leakage using face re-identification. Some defense strategies are also discussed in this work.
Privacy Preserving Text Recognition with Gradient-Boosting for Federated Learning
Jul 14, 2020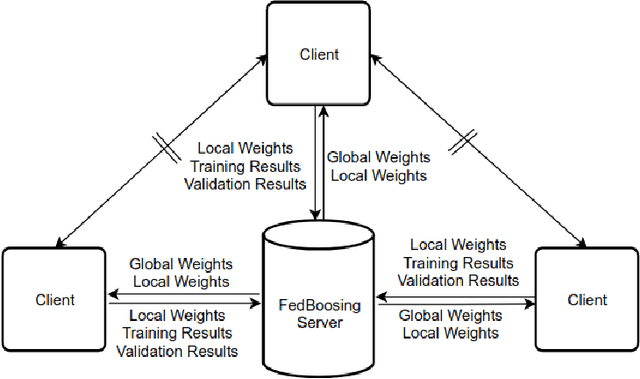
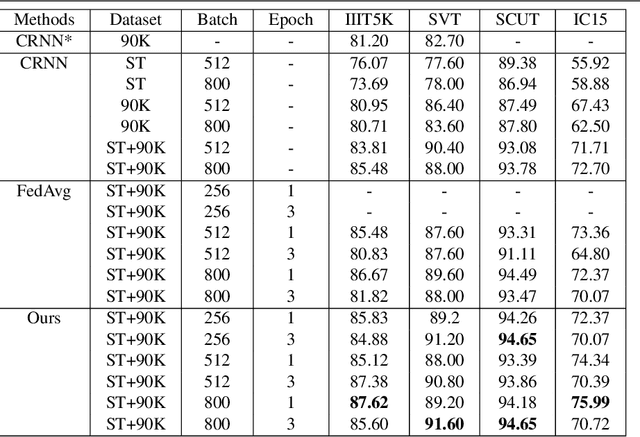
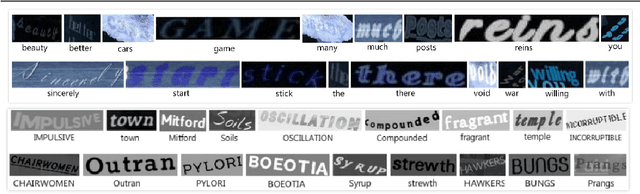

Typical machine learning approaches require centralized data for model training, which may not be possible where restrictions on data sharing are in place due to, for instance, privacy protection. The recently proposed Federated Learning (FL) frame-work allows learning a shared model collaboratively without data being centralized or data sharing among data owners. However, we show in this paper that the generalization ability of the joint model is poor on Non-Independent and Non-Identically Dis-tributed (Non-IID) data, particularly when the Federated Averaging (FedAvg) strategy is used in this collaborative learning framework thanks to the weight divergence phenomenon. We propose a novel boosting algorithm for FL to address this generalisation issue, as well as achieving much faster convergence in gradient based optimization. We demonstrate our Federated Boosting (FedBoost) method on privacy-preserved text recognition, which shows significant improvements in both performance and efficiency. The text images are based on publicly available datasets for fair comparison and we intend to make our implementation public to ensure reproducibility.