 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Clustering on Comparative Texts via Heterogeneous Information Networks
Paper and Code
Mar 09, 2019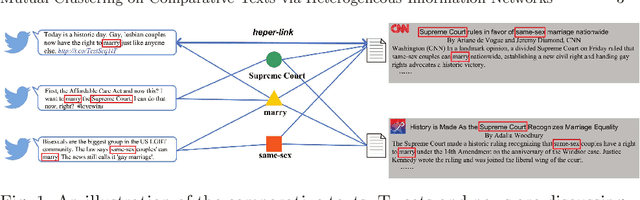
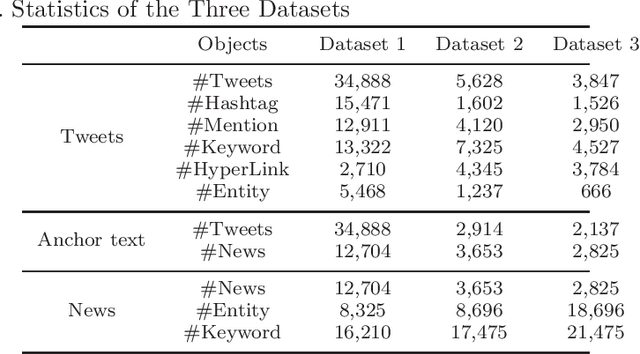
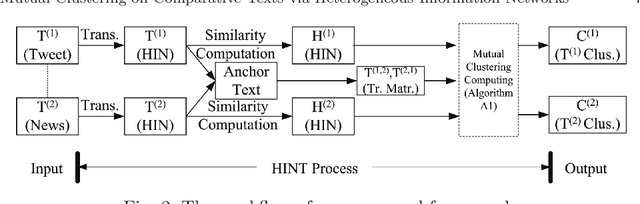
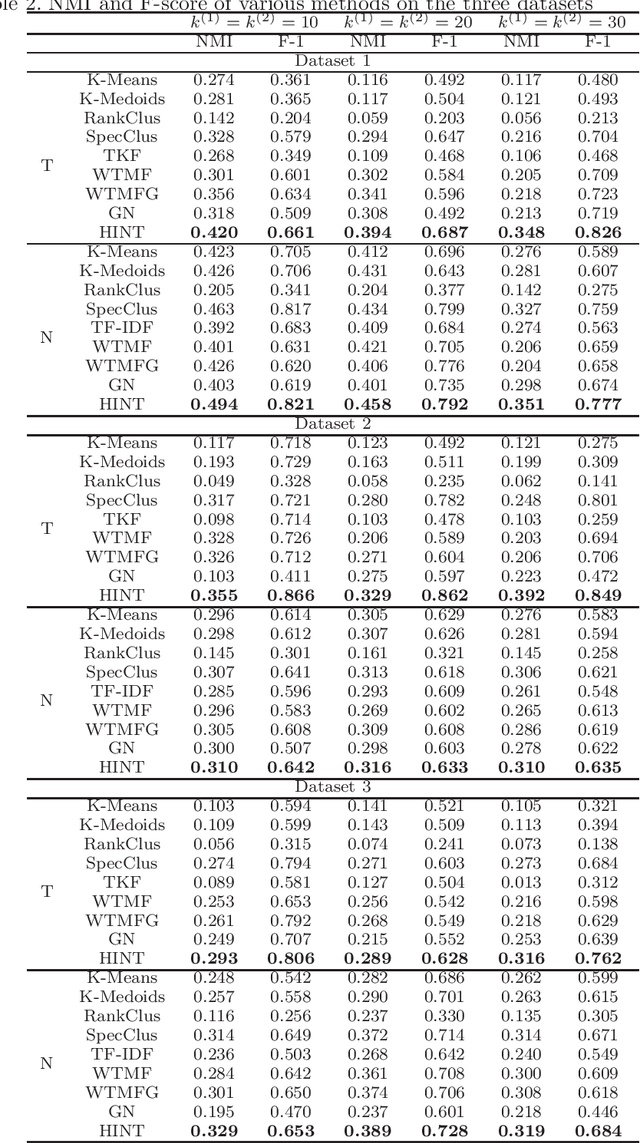
Currently, many intelligence systems contain the texts from multi-sources, e.g., bulletin board system (BBS) posts, tweets and news. These texts can be ``comparative'' since they may be semantically correlated and thus provide us with different perspectives toward the same topics or events. To better organize the multi-sourced texts and obtain more comprehensive knowledge, we propose to study the novel problem of Mutual Clustering on Comparative Texts (MCCT), which aims to cluster the comparative texts simultaneously and collaboratively. The MCCT problem is difficult to address because 1) comparative texts usually present different data formats and structures and thus they are hard to organize, and 2) there lacks an effective method to connect the semantically correlated comparative texts to facilitate clustering them in an unified way. To this aim, in this paper we propose a Heterogeneous Information Network-based Text clustering framework HINT. HINT first models multi-sourced texts (e.g. news and tweets) as heterogeneous information networks by introducing the shared ``anchor texts'' to connect the comparative texts. Next, two similarity matrices based on HINT as well as a transition matrix for cross-text-source knowledge transfer are constructed. Comparative texts clustering are then conducted by utilizing the constructed matrices. Finally, a mutual clustering algorithm is also proposed to further unify the separate clustering results of the comparative texts by introducing a clustering consistency constraint. We conduct extensive experimental on three tweets-news datasets, and the results demonstrate the effectiveness and robustness of the proposed method in addressing the MCCT problem.