 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Masking by Moving: Learning Distraction-Free Radar Odometry from Pose Information
Sep 12, 2019
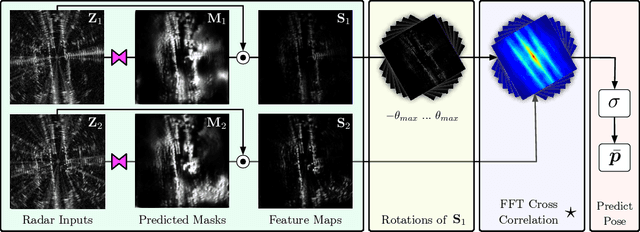
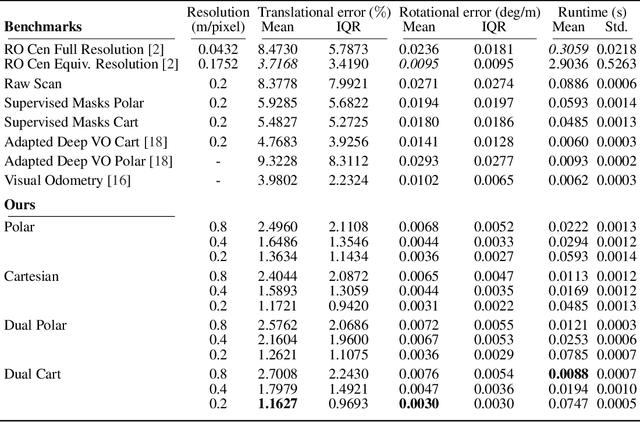
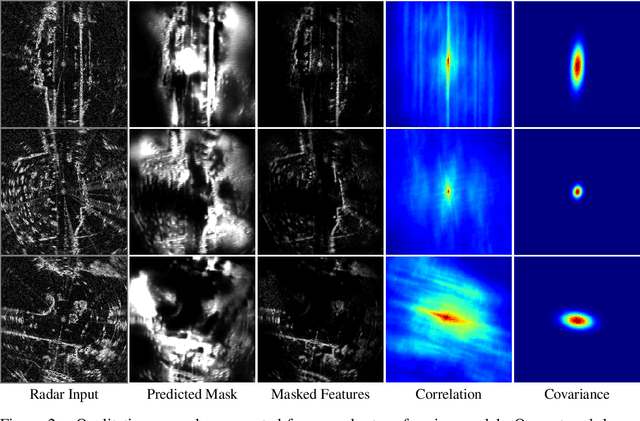
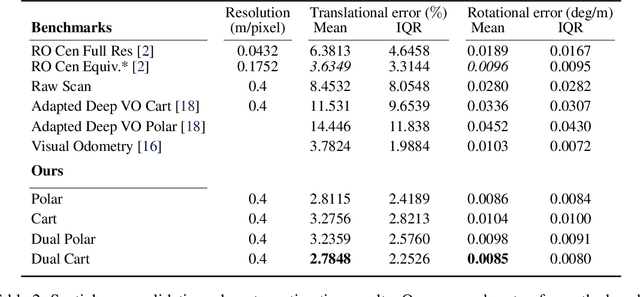
This paper presents an end-to-end radar odometry system which delivers robust, real-time pose estimates based on a learned embedding space free of sensing artefacts and distractor objects. The system deploys a fully differentiable, correlation-based radar matching approach. This provides the same level of interpretability as established scan-matching methods and allows for a principled derivation of uncertainty estimates. The system is trained in a (self-)supervised way using only previously obtained pose information as a training signal. Using 280km of urban driving data, we demonstrate that our approach outperforms the previous state-of-the-art in radar odometry by reducing errors by up 68% whilst running an order of magnitude faster.
Global Context Enhanced Social Recommendation with Hierarchical Graph Neural Networks
Oct 08, 2021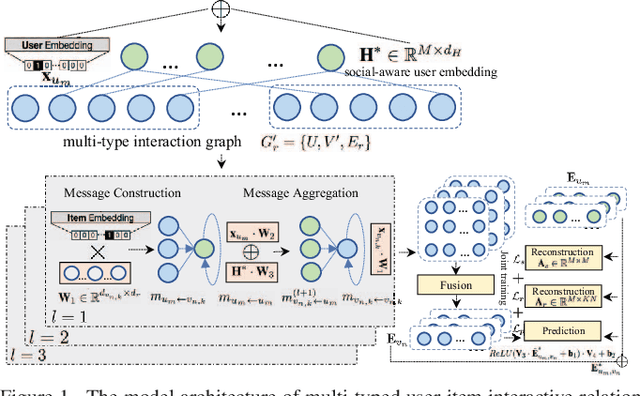
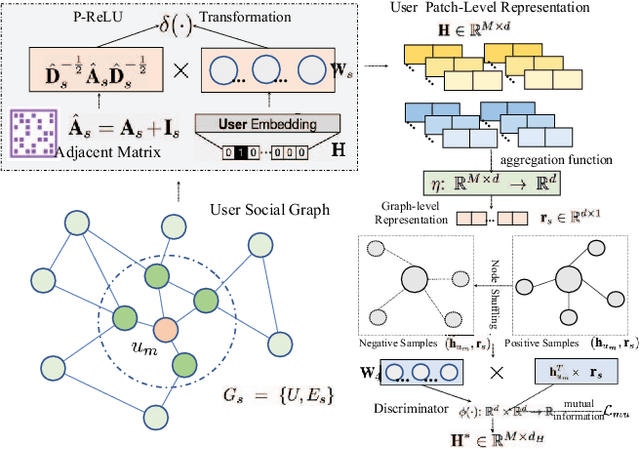
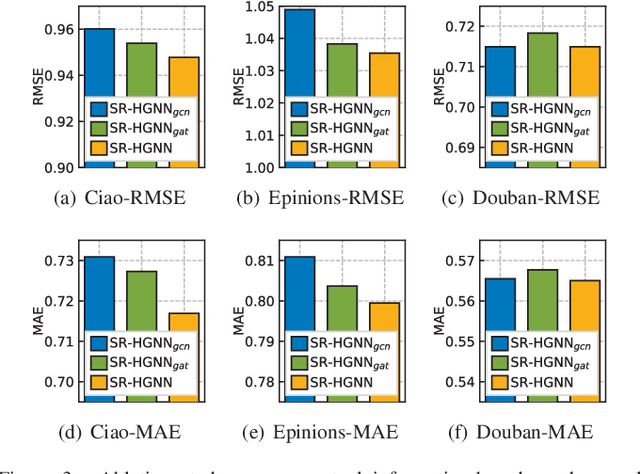
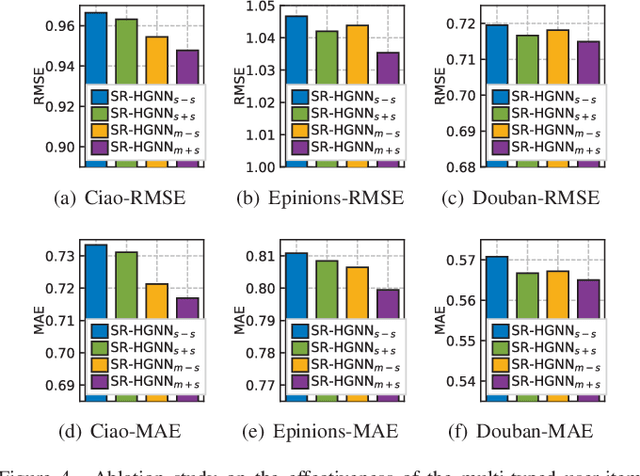
Social recommendation which aims to leverage social connections among users to enhance the recommendation performance. With the revival of deep learning techniques, many efforts have been devoted to developing various neural network-based social recommender systems, such as attention mechanisms and graph-based message passing frameworks. However, two important challenges have not been well addressed yet: (i) Most of existing social recommendation models fail to fully explore the multi-type user-item interactive behavior as well as the underlying cross-relational inter-dependencies. (ii) While the learned social state vector is able to model pair-wise user dependencies, it still has limited representation capacity in capturing the global social context across users. To tackle these limitations, we propose a new Social Recommendation framework with Hierarchical Graph Neural Networks (SR-HGNN). In particular, we first design a relation-aware reconstructed graph neural network to inject the cross-type collaborative semantics into the recommendation framework. In addition, we further augment SR-HGNN with a social relation encoder based on the mutual information learning paradigm between low-level user embeddings and high-level global representation, which endows SR-HGNN with the capability of capturing the global social contextual signals. Empirical results on three public benchmarks demonstrate that SR-HGNN significantly outperforms state-of-the-art recommendation methods. Source codes are available at: https://github.com/xhcdream/SR-HGNN.
Attention Gate in Traffic Forecasting
Sep 27, 2021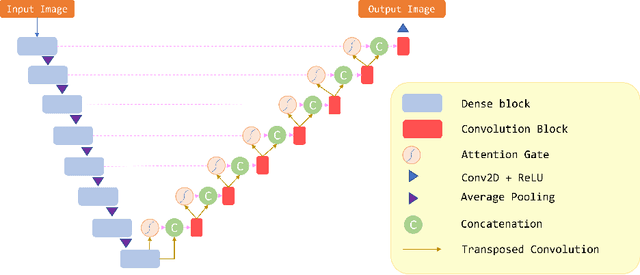
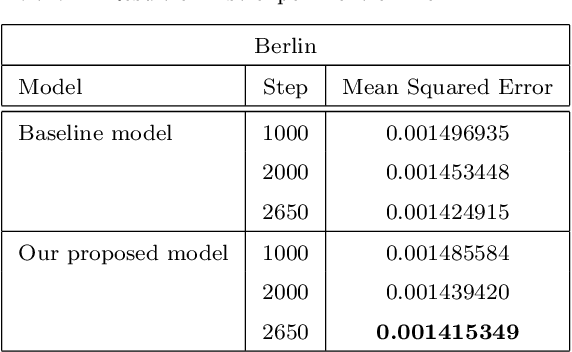
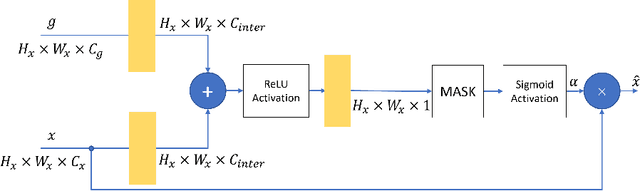
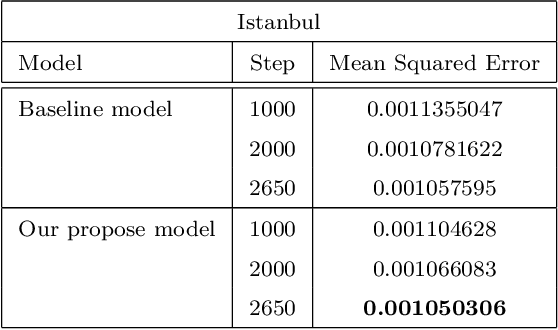
Because of increased urban complexity and growing populations, more and more challenges about predicting city-wide mobility behavior are being organized. Traffic Map Movie Forecasting Challenge 2020 is secondly held in the competition track of the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS). Similar to Traffic4Cast 2019, the task is to predict traffic flow volume, average speed in major directions on the geographical area of three big cities: Berlin, Istanbul, and Moscow. In this paper, we apply the attention mechanism on U-Net based model, especially we add an attention gate on the skip-connection between contraction path and expansion path. An attention gates filter features from the contraction path before combining with features on the expansion path, it enables our model to reduce the effect of non-traffic region features and focus more on crucial region features. In addition to the competition data, we also propose two extra features which often affect traffic flow, that are time and weekdays. We experiment with our model on the competition dataset and reproduce the winner solution in the same environment. Overall, our model archives better performance than recent methods.
ConTIG: Continuous Representation Learning on Temporal Interaction Graphs
Sep 27, 2021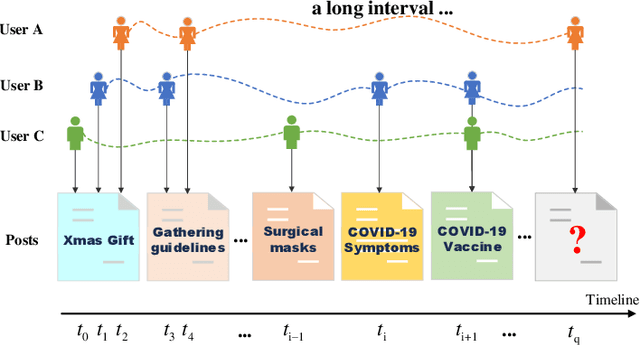
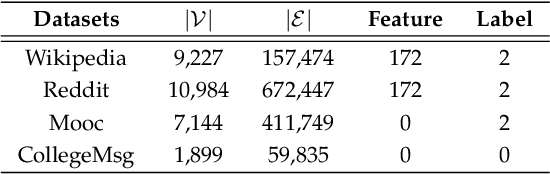
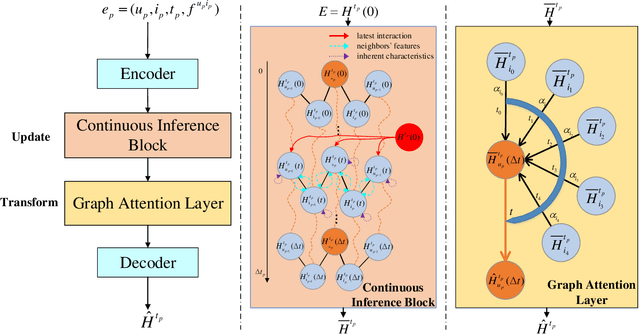
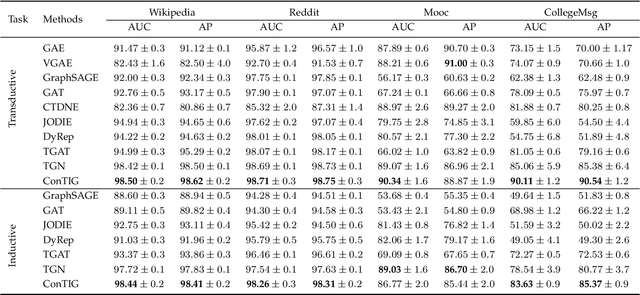
Representation learning on temporal interaction graphs (TIG) is to model complex networks with the dynamic evolution of interactions arising in a broad spectrum of problems. Existing dynamic embedding methods on TIG discretely update node embeddings merely when an interaction occurs. They fail to capture the continuous dynamic evolution of embedding trajectories of nodes. In this paper, we propose a two-module framework named ConTIG, a continuous representation method that captures the continuous dynamic evolution of node embedding trajectories. With two essential modules, our model exploit three-fold factors in dynamic networks which include latest interaction, neighbor features and inherent characteristics. In the first update module, we employ a continuous inference block to learn the nodes' state trajectories by learning from time-adjacent interaction patterns between node pairs using ordinary differential equations. In the second transform module, we introduce a self-attention mechanism to predict future node embeddings by aggregating historical temporal interaction information. Experiments results demonstrate the superiority of ConTIG on temporal link prediction, temporal node recommendation and dynamic node classification tasks compared with a range of state-of-the-art baselines, especially for long-interval interactions prediction.
QuTI! Quantifying Text-Image Consistency in Multimodal Documents
Apr 28, 2021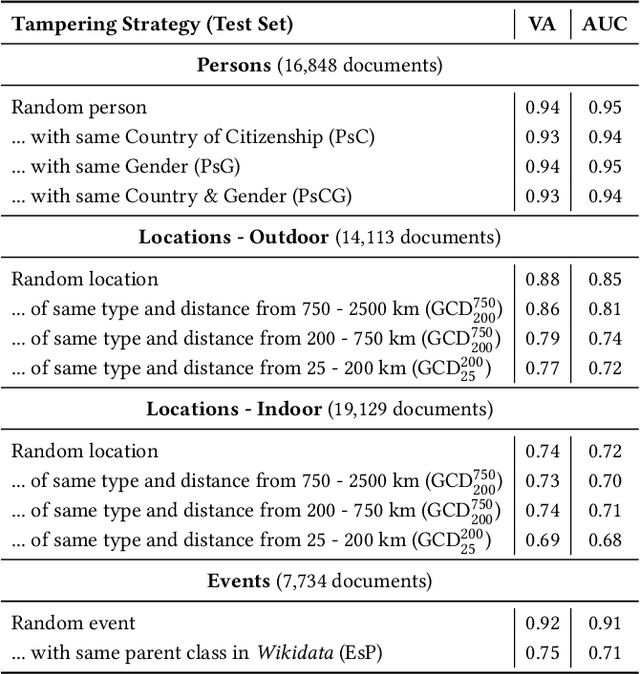
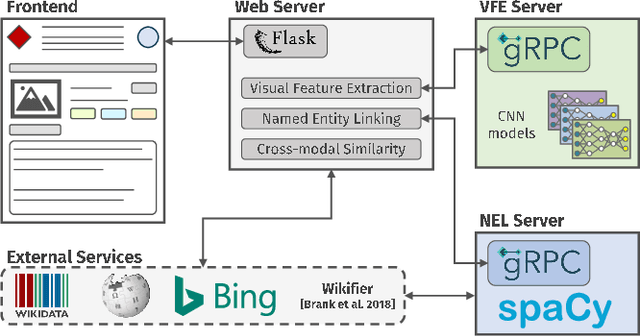
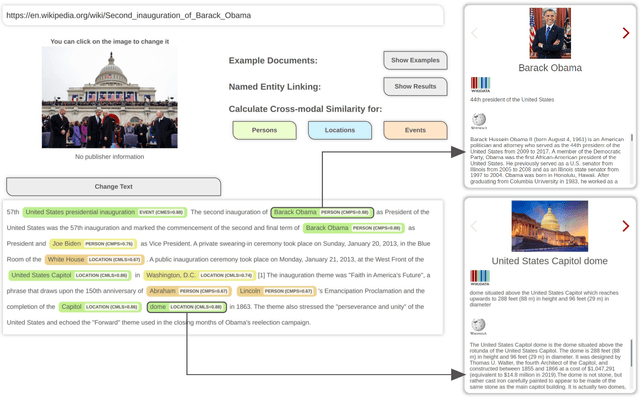
The World Wide Web and social media platforms have become popular sources for news and information. Typically, multimodal information, e.g., image and text is used to convey information more effectively and to attract attention. While in most cases image content is decorative or depicts additional information, it has also been leveraged to spread misinformation and rumors in recent years. In this paper, we present a Web-based demo application that automatically quantifies the cross-modal relations of entities (persons, locations, and events) in image and text. The applications are manifold. For example, the system can help users to explore multimodal articles more efficiently, or can assist human assessors and fact-checking efforts in the verification of the credibility of news stories, tweets, or other multimodal documents.
Assembly Planning by Recognizing a Graphical Instruction Manual
Jun 01, 2021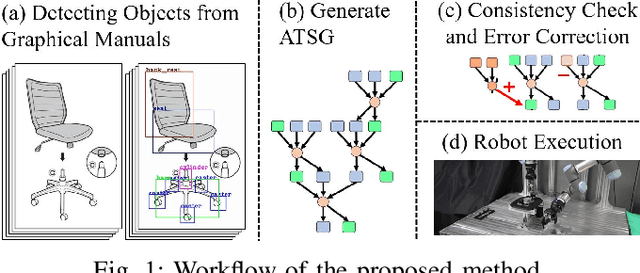
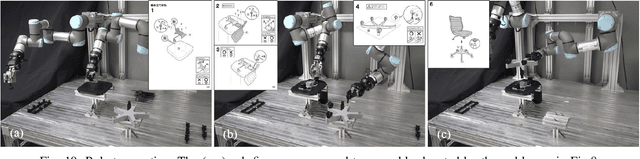
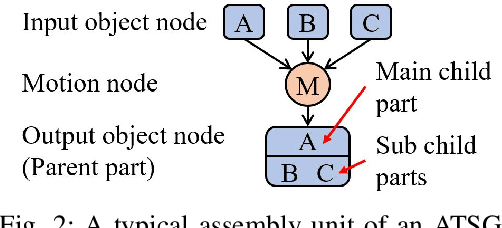
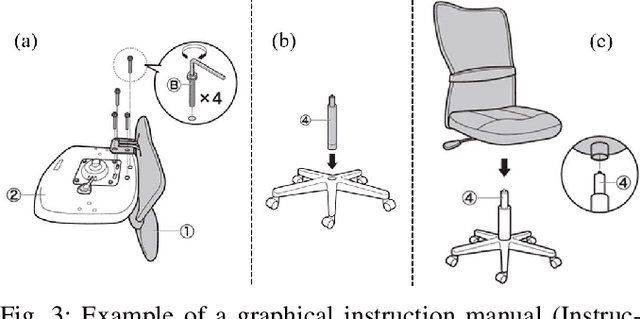
This paper proposes a robot assembly planning method by automatically reading the graphical instruction manuals design for humans. Essentially, the method generates an Assembly Task Sequence Graph (ATSG) by recognizing a graphical instruction manual. An ATSG is a graph describing the assembly task procedure by detecting types of parts included in the instruction images, completing the missing information automatically, and correcting the detection errors automatically. To build an ATSG, the proposed method first extracts the information of the parts contained in each image of the graphical instruction manual. Then, by using the extracted part information, it estimates the proper work motions and tools for the assembly task. After that, the method builds an ATSG by considering the relationship between the previous and following images, which makes it possible to estimate the undetected parts caused by occlusion using the information of the entire image series. Finally, by collating the total number of each part with the generated ATSG, the excess or deficiency of parts are investigated, and task procedures are removed or added according to those parts. In the experiment section, we build an ATSG using the proposed method to a graphical instruction manual for a chair and demonstrate the action sequences found in the ATSG can be performed by a dual-arm robot execution. The results show the proposed method is effective and simplifies robot teaching in automatic assembly.
Federated Learning for Big Data: A Survey on Opportunities, Applications, and Future Directions
Oct 17, 2021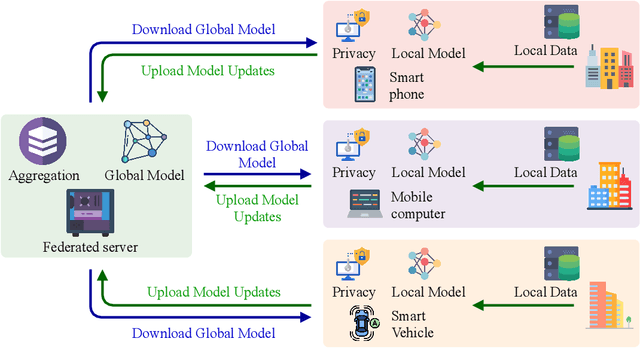
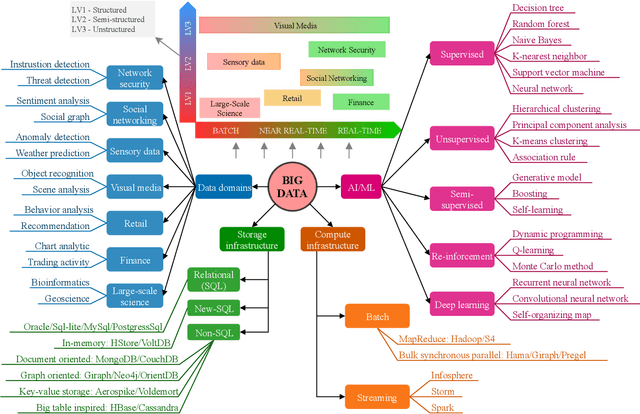
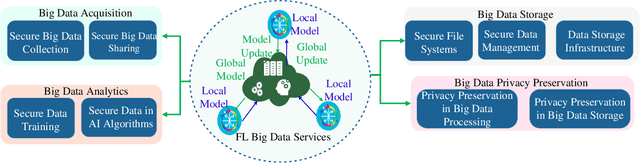
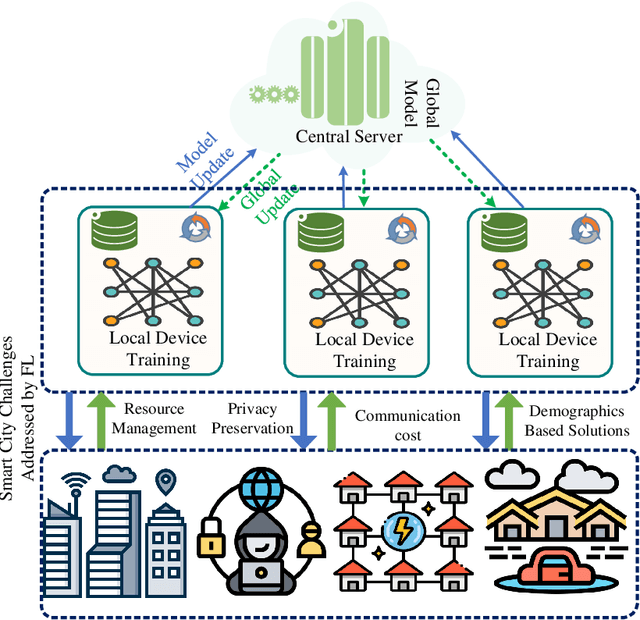
Big data has remarkably evolved over the last few years to realize an enormous volume of data generated from newly emerging services and applications and a massive number of Internet-of-Things (IoT) devices. The potential of big data can be realized via analytic and learning techniques, in which the data from various sources is transferred to a central cloud for central storage, processing, and training. However, this conventional approach faces critical issues in terms of data privacy as the data may include sensitive data such as personal information, governments, banking accounts. To overcome this challenge, federated learning (FL) appeared to be a promising learning technique. However, a gap exists in the literature that a comprehensive survey on FL for big data services and applications is yet to be conducted. In this article, we present a survey on the use of FL for big data services and applications, aiming to provide general readers with an overview of FL, big data, and the motivations behind the use of FL for big data. In particular, we extensively review the use of FL for key big data services, including big data acquisition, big data storage, big data analytics, and big data privacy preservation. Subsequently, we review the potential of FL for big data applications, such as smart city, smart healthcare, smart transportation, smart grid, and social media. Further, we summarize a number of important projects on FL-big data and discuss key challenges of this interesting topic along with several promising solutions and directions.
Single Underwater Image Enhancement Using an Analysis-Synthesis Network
Aug 20, 2021



Most deep models for underwater image enhancement resort to training on synthetic datasets based on underwater image formation models. Although promising performances have been achieved, they are still limited by two problems: (1) existing underwater image synthesis models have an intrinsic limitation, in which the homogeneous ambient light is usually randomly generated and many important dependencies are ignored, and thus the synthesized training data cannot adequately express characteristics of real underwater environments; (2) most of deep models disregard lots of favorable underwater priors and heavily rely on training data, which extensively limits their application ranges. To address these limitations, a new underwater synthetic dataset is first established, in which a revised ambient light synthesis equation is embedded. The revised equation explicitly defines the complex mathematical relationship among intensity values of the ambient light in RGB channels and many dependencies such as surface-object depth, water types, etc, which helps to better simulate real underwater scene appearances. Secondly, a unified framework is proposed, named ANA-SYN, which can effectively enhance underwater images under collaborations of priors (underwater domain knowledge) and data information (underwater distortion distribution). The proposed framework includes an analysis network and a synthesis network, one for priors exploration and another for priors integration. To exploit more accurate priors, the significance of each prior for the input image is explored in the analysis network and an adaptive weighting module is designed to dynamically recalibrate them. Meanwhile, a novel prior guidance module is introduced in the synthesis network, which effectively aggregates the prior and data features and thus provides better hybrid information to perform the more reasonable image enhancement.
Tribrid: Stance Classification with Neural Inconsistency Detection
Sep 14, 2021
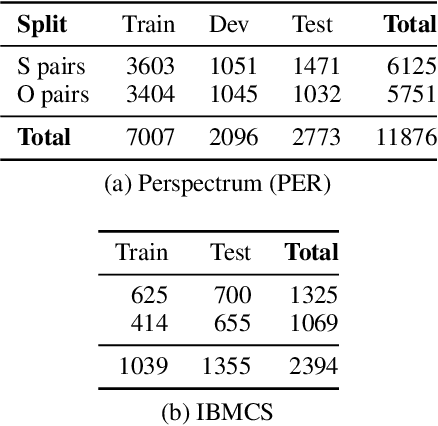
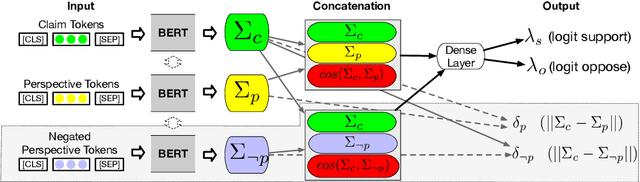
We study the problem of performing automatic stance classification on social media with neural architectures such as BERT. Although these architectures deliver impressive results, their level is not yet comparable to the one of humans and they might produce errors that have a significant impact on the downstream task (e.g., fact-checking). To improve the performance, we present a new neural architecture where the input also includes automatically generated negated perspectives over a given claim. The model is jointly learned to make simultaneously multiple predictions, which can be used either to improve the classification of the original perspective or to filter out doubtful predictions. In the first case, we propose a weakly supervised method for combining the predictions into a final one. In the second case, we show that using the confidence scores to remove doubtful predictions allows our method to achieve human-like performance over the retained information, which is still a sizable part of the original input.
CUTIE: Learning to Understand Documents with Convolutional Universal Text Information Extractor
Apr 04, 2019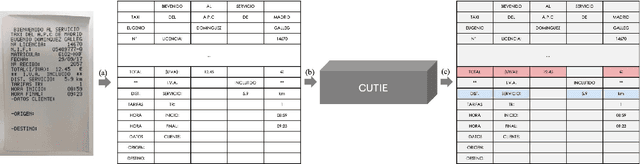
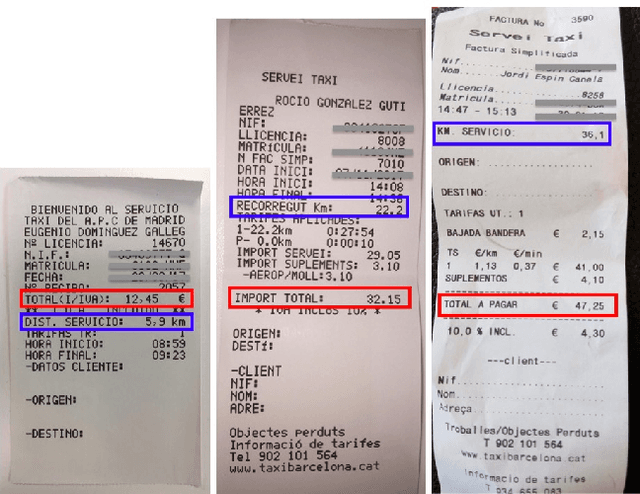

Extracting key information from documents, such as receipts or invoices, and preserving the interested texts to structured data is crucial in the document-intensive streamline processes of office automation in areas that includes but not limited to accounting, financial, and taxation areas. To avoid designing expert rules for each specific type of document, some published works attempt to tackle the problem by learning a model to explore the semantic context in text sequences based on the Named Entity Recognition (NER) method in the NLP field. In this paper, we propose to harness the effective information from both semantic meaning and spatial distribution of texts in documents. Specifically, our proposed model, Convolutional Universal Text Information Extractor (CUTIE), applies convolutional neural networks on gridded texts where texts are embedded as features with semantical connotations. We further explore the effect of employing different structures of convolutional neural network and propose a fast and portable structure. We demonstrate the effectiveness of the proposed method on a dataset with up to $4,484$ labelled receipts, without any pre-training or post-processing, achieving state of the art performance that is much higher than BERT but with only $1/10$ parameters and without requiring the $3,300$M word dataset for pre-training. Experimental results also demonstrate that the CUTIE being able to achieve state of the art performance with much smaller amount of training data.