 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCL: Collaborative Curriculum Learning for Sparse-Reward Multi-Agent Reinforcement Learning via Co-evolutionary Task Evolution
May 08, 2025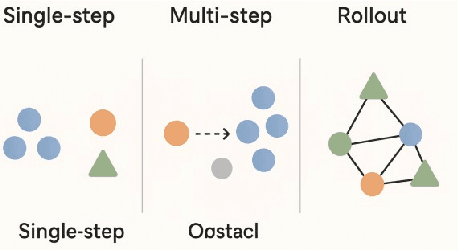
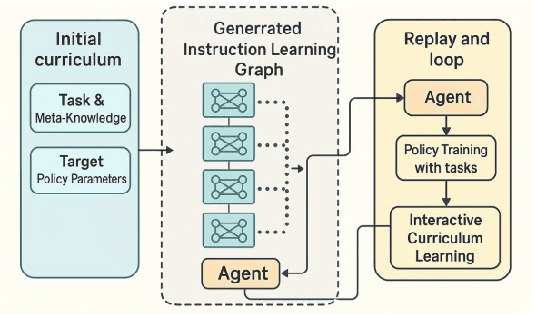
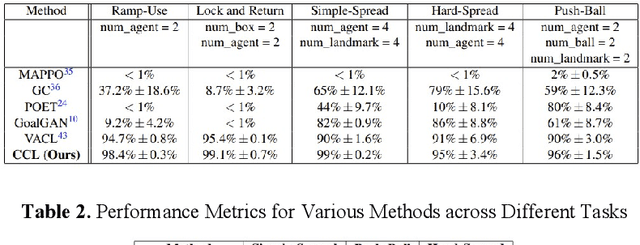
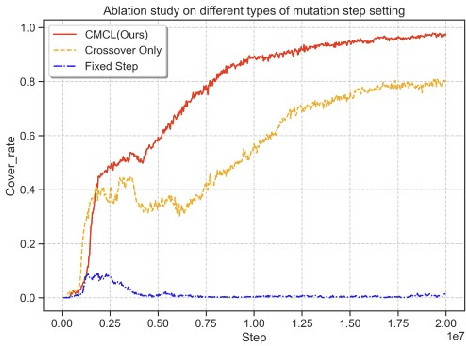
Sparse reward environments pose significant challenges in reinforcement learning, especially within multi-agent systems (MAS) where feedback is delayed and shared across agents, leading to suboptimal learning. We propose Collaborative Multi-dimensional Course Learning (CCL), a novel curriculum learning framework that addresses this by (1) refining intermediate tasks for individual agents, (2) using a variational evolutionary algorithm to generate informative subtasks, and (3) co-evolving agents with their environment to enhance training stability. Experiments on five cooperative tasks in the MPE and Hide-and-Seek environments show that CCL outperforms existing methods in sparse reward settings.
GaMNet: A Hybrid Network with Gabor Fusion and NMamba for Efficient 3D Glioma Segmentation
May 08, 2025Gliomas are aggressive brain tumors that pose serious health risks. Deep learning aids in lesion segmentation, but CNN and Transformer-based models often lack context modeling or demand heavy computation, limiting real-time use on mobile medical devices. We propose GaMNet, integrating the NMamba module for global modeling and a multi-scale CNN for efficient local feature extraction. To improve interpretability and mimic the human visual system, we apply Gabor filters at multiple scales. Our method achieves high segmentation accuracy with fewer parameters and faster computation. Extensive experiments show GaMNet outperforms existing methods, notably reducing false positives and negatives, which enhances the reliability of clinical diagnosis.
GAME: Learning Multimodal Interactions via Graph Structures for Personality Trait Estimation
May 05, 2025



Apparent personality analysis from short videos poses significant chal-lenges due to the complex interplay of visual, auditory, and textual cues. In this paper, we propose GAME, a Graph-Augmented Multimodal Encoder designed to robustly model and fuse multi-source features for automatic personality prediction. For the visual stream, we construct a facial graph and introduce a dual-branch Geo Two-Stream Network, which combines Graph Convolutional Networks (GCNs) and Convolutional Neural Net-works (CNNs) with attention mechanisms to capture both structural and appearance-based facial cues. Complementing this, global context and iden-tity features are extracted using pretrained ResNet18 and VGGFace back-bones. To capture temporal dynamics, frame-level features are processed by a BiGRU enhanced with temporal attention modules. Meanwhile, audio representations are derived from the VGGish network, and linguistic se-mantics are captured via the XLM-Roberta transformer. To achieve effective multimodal integration, we propose a Channel Attention-based Fusion module, followed by a Multi-Layer Perceptron (MLP) regression head for predicting personality traits. Extensive experiments show that GAME con-sistently outperforms existing methods across multiple benchmarks, vali-dating its effectiveness and generalizability.
Domain Adaptation for Underwater Image Enhancement
Aug 22, 2021



Recently, learning-based algorithms have shown impressive performance in underwater image enhancement. Most of them resort to training on synthetic data and achieve outstanding performance. However, these methods ignore the significant domain gap between the synthetic and real data (i.e., interdomain gap), and thus the models trained on synthetic data often fail to generalize well to real underwater scenarios. Furthermore, the complex and changeable underwater environment also causes a great distribution gap among the real data itself (i.e., intra-domain gap). However, almost no research focuses on this problem and thus their techniques often produce visually unpleasing artifacts and color distortions on various real images. Motivated by these observations, we propose a novel Two-phase Underwater Domain Adaptation network (TUDA) to simultaneously minimize the inter-domain and intra-domain gap. Concretely, a new dual-alignment network is designed in the first phase, including a translation part for enhancing realism of input images, followed by an enhancement part. With performing image-level and feature-level adaptation in two parts by jointly adversarial learning, the network can better build invariance across domains and thus bridge the inter-domain gap. In the second phase, we perform an easy-hard classification of real data according to the assessed quality of enhanced images, where a rank-based underwater quality assessment method is embedded. By leveraging implicit quality information learned from rankings, this method can more accurately assess the perceptual quality of enhanced images. Using pseudo labels from the easy part, an easy-hard adaptation technique is then conducted to effectively decrease the intra-domain gap between easy and hard samples.
Single Underwater Image Enhancement Using an Analysis-Synthesis Network
Aug 20, 2021



Most deep models for underwater image enhancement resort to training on synthetic datasets based on underwater image formation models. Although promising performances have been achieved, they are still limited by two problems: (1) existing underwater image synthesis models have an intrinsic limitation, in which the homogeneous ambient light is usually randomly generated and many important dependencies are ignored, and thus the synthesized training data cannot adequately express characteristics of real underwater environments; (2) most of deep models disregard lots of favorable underwater priors and heavily rely on training data, which extensively limits their application ranges. To address these limitations, a new underwater synthetic dataset is first established, in which a revised ambient light synthesis equation is embedded. The revised equation explicitly defines the complex mathematical relationship among intensity values of the ambient light in RGB channels and many dependencies such as surface-object depth, water types, etc, which helps to better simulate real underwater scene appearances. Secondly, a unified framework is proposed, named ANA-SYN, which can effectively enhance underwater images under collaborations of priors (underwater domain knowledge) and data information (underwater distortion distribution). The proposed framework includes an analysis network and a synthesis network, one for priors exploration and another for priors integration. To exploit more accurate priors, the significance of each prior for the input image is explored in the analysis network and an adaptive weighting module is designed to dynamically recalibrate them. Meanwhile, a novel prior guidance module is introduced in the synthesis network, which effectively aggregates the prior and data features and thus provides better hybrid information to perform the more reasonable image enhancement.