 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-appearance-aided Differential Evolution for Motion Transfer
Oct 09, 2021

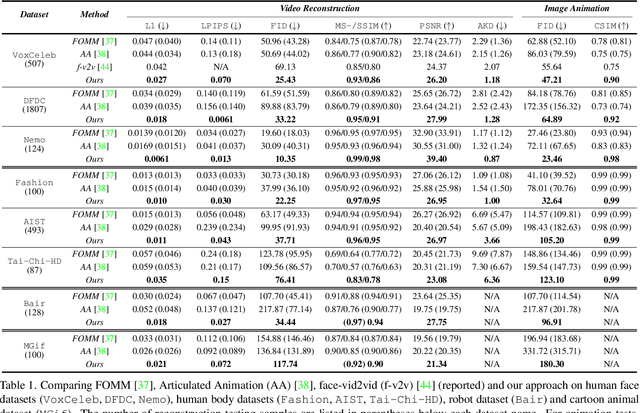
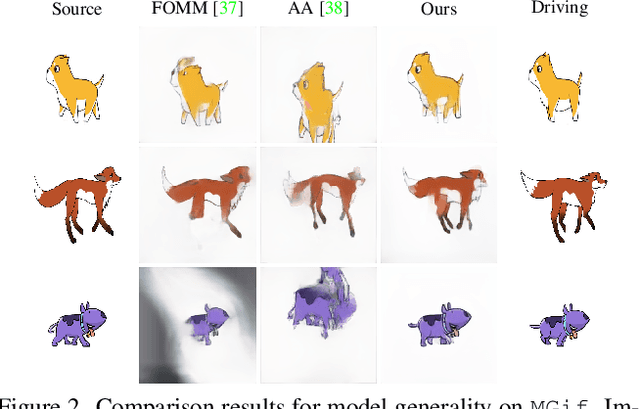
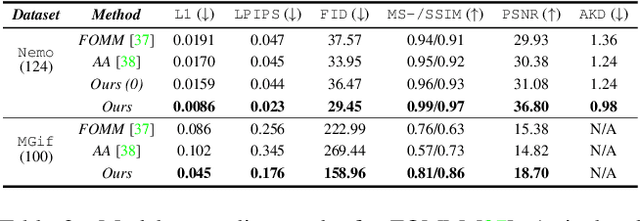
Image animation transfers the motion of a driving video to a static object in a source image, while keeping the source identity unchanged. Great progress has been made in unsupervised motion transfer recently, where no labelled data or ground truth domain priors are needed. However, current unsupervised approaches still struggle when there are large motion or viewpoint discrepancies between the source and driving images. In this paper, we introduce three measures that we found to be effective for overcoming such large viewpoint changes. Firstly, to achieve more fine-grained motion deformation fields, we propose to apply Neural-ODEs for parametrizing the evolution dynamics of the motion transfer from source to driving. Secondly, to handle occlusions caused by large viewpoint and motion changes, we take advantage of the appearance flow obtained from the source image itself ("self-appearance"), which essentially "borrows" similar structures from other regions of an image to inpaint missing regions. Finally, our framework is also able to leverage the information from additional reference views which help to drive the source identity in spite of varying motion state. Extensive experiments demonstrate that our approach outperforms the state-of-the-arts by a significant margin (~40%), across six benchmarks varying from human faces, human bodies to robots and cartoon characters. Model generality analysis indicates that our approach generalises the best across different object categories as well.
Assessing glaucoma in retinal fundus photographs using Deep Feature Consistent Variational Autoencoders
Oct 04, 2021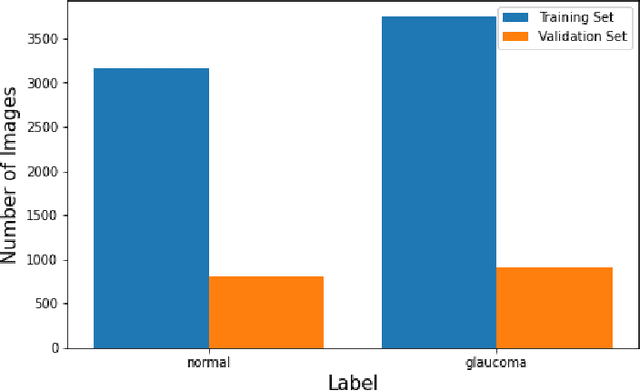
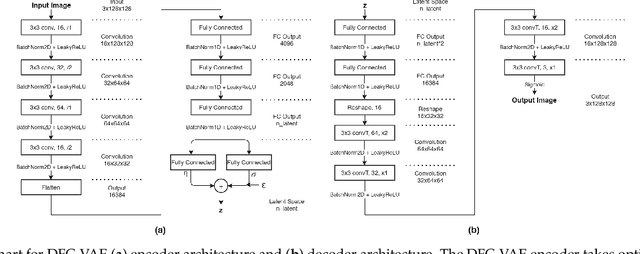
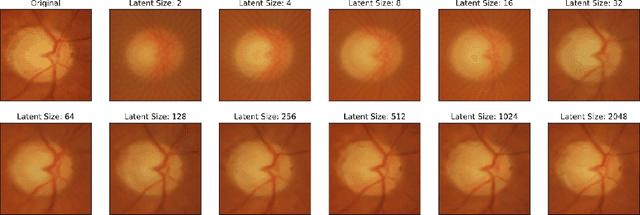
One of the leading causes of blindness is glaucoma, which is challenging to detect since it remains asymptomatic until the symptoms are severe. Thus, diagnosis is usually possible until the markers are easy to identify, i.e., the damage has already occurred. Early identification of glaucoma is generally made based on functional, structural, and clinical assessments. However, due to the nature of the disease, researchers still debate which markers qualify as a consistent glaucoma metric. Deep learning methods have partially solved this dilemma by bypassing the marker identification stage and analyzing high-level information directly to classify the data. Although favorable, these methods make expert analysis difficult as they provide no insight into the model discrimination process. In this paper, we overcome this using deep generative networks, a deep learning model that learns complicated, high-dimensional probability distributions. We train a Deep Feature consistent Variational Autoencoder (DFC-VAE) to reconstruct optic disc images. We show that a small-sized latent space obtained from the DFC-VAE can learn the high-dimensional glaucoma data distribution and provide discriminatory evidence between normal and glaucoma eyes. Latent representations of size as low as 128 from our model got a 0.885 area under the receiver operating characteristic curve when trained with Support Vector Classifier.
Near optimal sample complexity for matrix and tensor normal models via geodesic convexity
Oct 14, 2021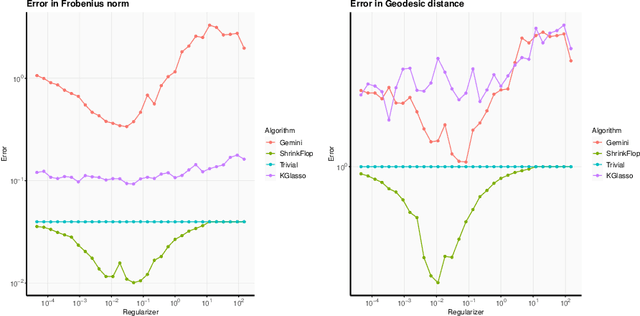
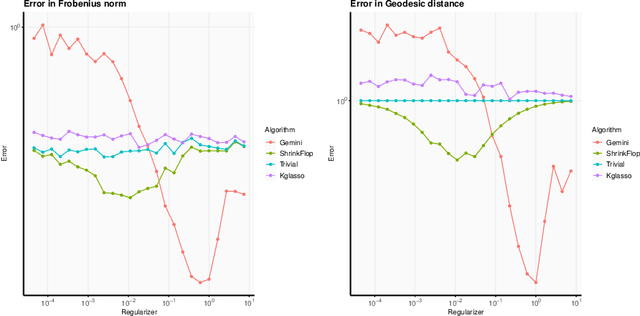
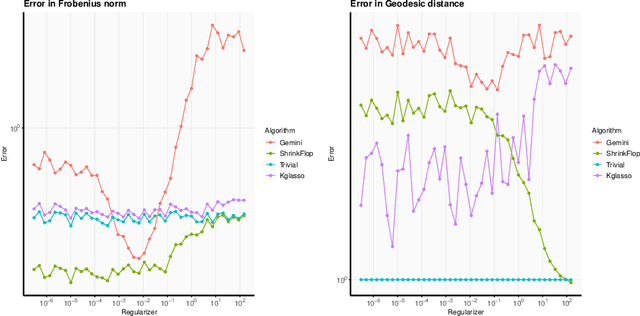
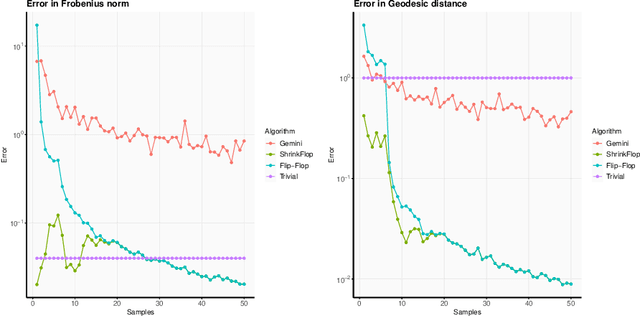
The matrix normal model, the family of Gaussian matrix-variate distributions whose covariance matrix is the Kronecker product of two lower dimensional factors, is frequently used to model matrix-variate data. The tensor normal model generalizes this family to Kronecker products of three or more factors. We study the estimation of the Kronecker factors of the covariance matrix in the matrix and tensor models. We show nonasymptotic bounds for the error achieved by the maximum likelihood estimator (MLE) in several natural metrics. In contrast to existing bounds, our results do not rely on the factors being well-conditioned or sparse. For the matrix normal model, all our bounds are minimax optimal up to logarithmic factors, and for the tensor normal model our bound for the largest factor and overall covariance matrix are minimax optimal up to constant factors provided there are enough samples for any estimator to obtain constant Frobenius error. In the same regimes as our sample complexity bounds, we show that an iterative procedure to compute the MLE known as the flip-flop algorithm converges linearly with high probability. Our main tool is geodesic strong convexity in the geometry on positive-definite matrices induced by the Fisher information metric. This strong convexity is determined by the expansion of certain random quantum channels. We also provide numerical evidence that combining the flip-flop algorithm with a simple shrinkage estimator can improve performance in the undersampled regime.
Self-explaining variational posterior distributions for Gaussian Process models
Sep 08, 2021
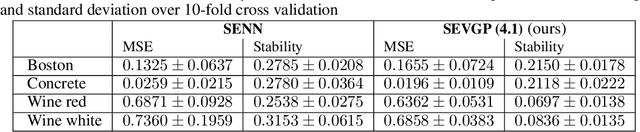
Bayesian methods have become a popular way to incorporate prior knowledge and a notion of uncertainty into machine learning models. At the same time, the complexity of modern machine learning makes it challenging to comprehend a model's reasoning process, let alone express specific prior assumptions in a rigorous manner. While primarily interested in the former issue, recent developments intransparent machine learning could also broaden the range of prior information that we can provide to complex Bayesian models. Inspired by the idea of self-explaining models, we introduce a corresponding concept for variational GaussianProcesses. On the one hand, our contribution improves transparency for these types of models. More importantly though, our proposed self-explaining variational posterior distribution allows to incorporate both general prior knowledge about a target function as a whole and prior knowledge about the contribution of individual features.
Learnable Reconstruction Methods from RGB Images to Hyperspectral Imaging: A Survey
Jun 30, 2021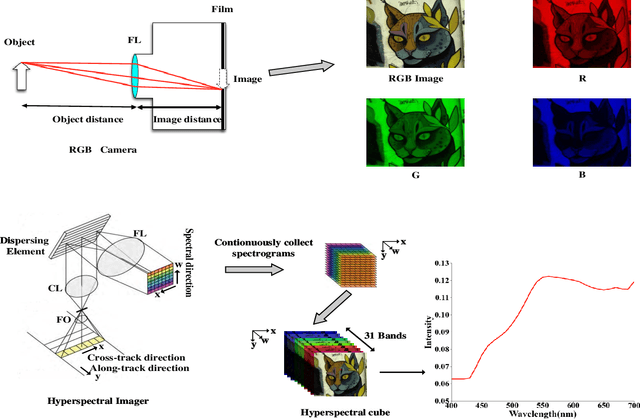
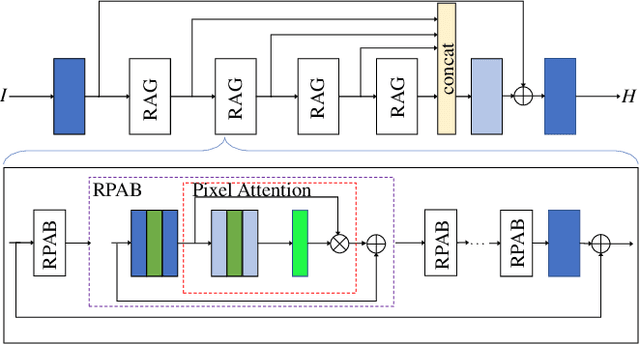
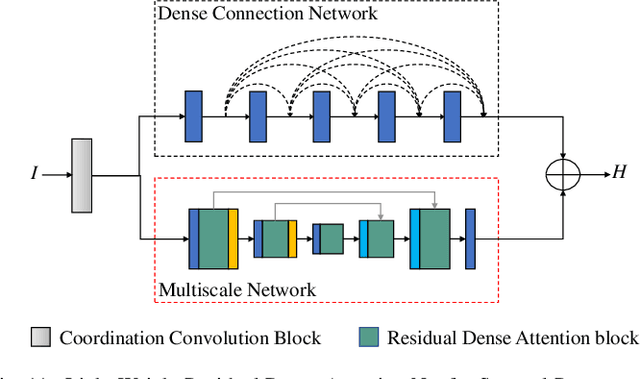
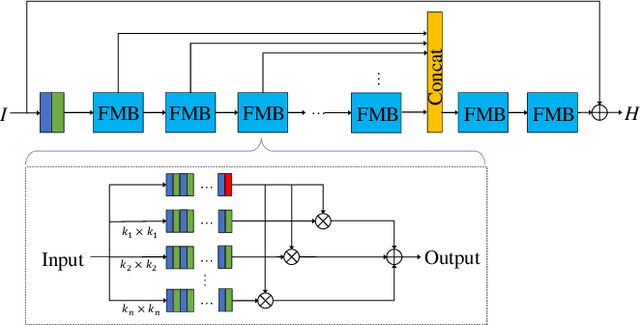
Hyperspectral imaging enables versatile applications due to its competence in capturing abundant spatial and spectral information, which are crucial for identifying substances. However, the devices for acquiring hyperspectral images are expensive and complicated. Therefore, many alternative spectral imaging methods have been proposed by directly reconstructing the hyperspectral information from lower-cost, more available RGB images. We present a thorough investigation of these state-of-the-art spectral reconstruction methods from the widespread RGB images. A systematic study and comparison of more than 25 methods has revealed that most of the data-driven deep learning methods are superior to prior-based methods in terms of reconstruction accuracy and quality despite lower speeds. This comprehensive review can serve as a fruitful reference source for peer researchers, thus further inspiring future development directions in related domains.
Sentence Semantic Regression for Text Generation
Aug 06, 2021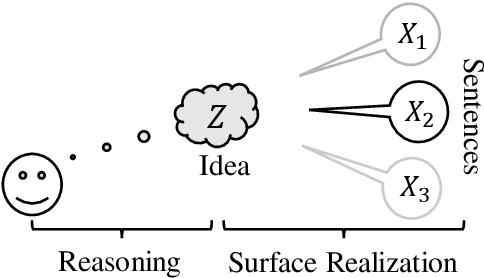
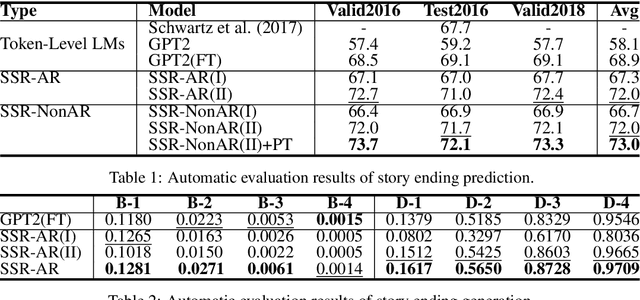
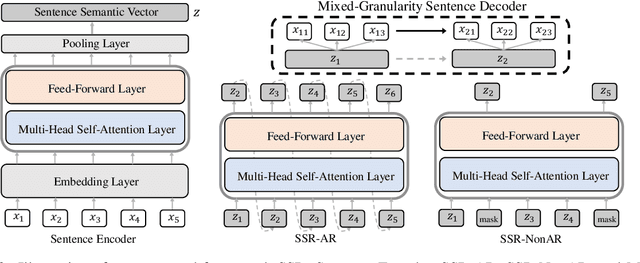
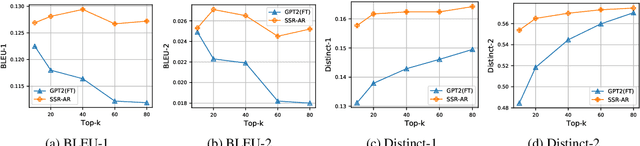
Recall the classical text generation works, the generation framework can be briefly divided into two phases: \textbf{idea reasoning} and \textbf{surface realization}. The target of idea reasoning is to figure out the main idea which will be presented in the following talking/writing periods. Surface realization aims to arrange the most appropriate sentence to depict and convey the information distilled from the main idea. However, the current popular token-by-token text generation methods ignore this crucial process and suffer from many serious issues, such as idea/topic drift. To tackle the problems and realize this two-phase paradigm, we propose a new framework named Sentence Semantic Regression (\textbf{SSR}) based on sentence-level language modeling. For idea reasoning, two architectures \textbf{SSR-AR} and \textbf{SSR-NonAR} are designed to conduct sentence semantic regression autoregressively (like GPT2/3) and bidirectionally (like BERT). In the phase of surface realization, a mixed-granularity sentence decoder is designed to generate text with better consistency by jointly incorporating the predicted sentence-level main idea as well as the preceding contextual token-level information. We conduct experiments on four tasks of story ending prediction, story ending generation, dialogue generation, and sentence infilling. The results show that SSR can obtain better performance in terms of automatic metrics and human evaluation.
Improving RNN-T ASR Performance with Date-Time and Location Awareness
Jun 11, 2021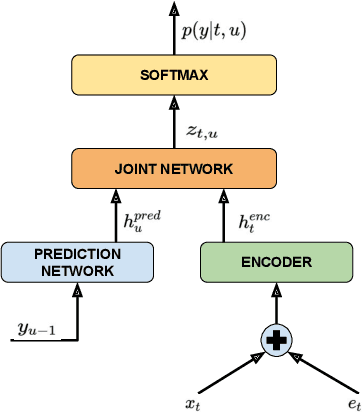
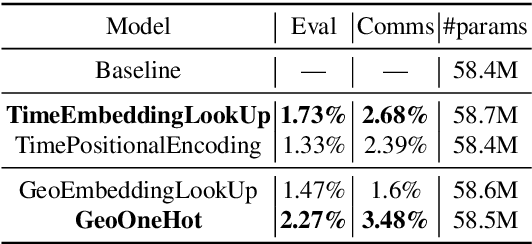
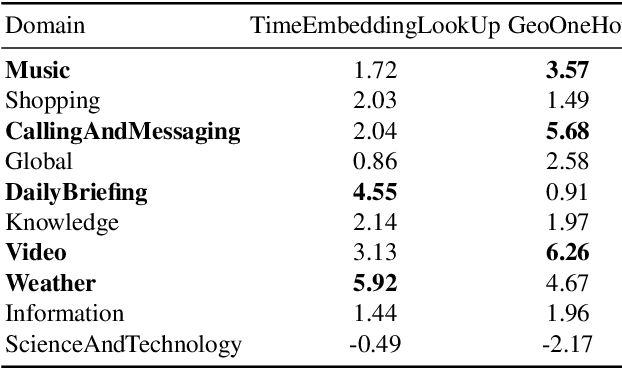

In this paper, we explore the benefits of incorporating context into a Recurrent Neural Network (RNN-T) based Automatic Speech Recognition (ASR) model to improve the speech recognition for virtual assistants. Specifically, we use meta information extracted from the time at which the utterance is spoken and the approximate location information to make ASR context aware. We show that these contextual information, when used individually, improves overall performance by as much as 3.48% relative to the baseline and when the contexts are combined, the model learns complementary features and the recognition improves by 4.62%. On specific domains, these contextual signals show improvements as high as 11.5%, without any significant degradation on others. We ran experiments with models trained on data of sizes 30K hours and 10K hours. We show that the scale of improvement with the 10K hours dataset is much higher than the one obtained with 30K hours dataset. Our results indicate that with limited data to train the ASR model, contextual signals can improve the performance significantly.
Don't read, just look: Main content extraction from web pages using visually apparent features
Oct 27, 2021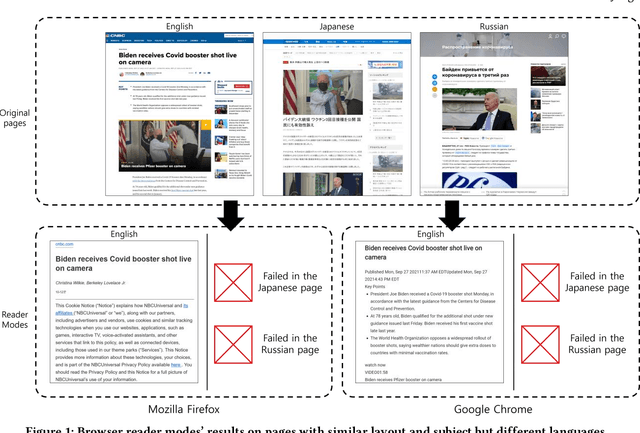
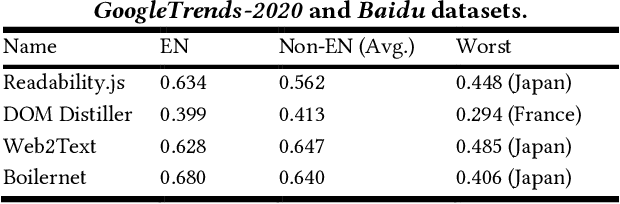
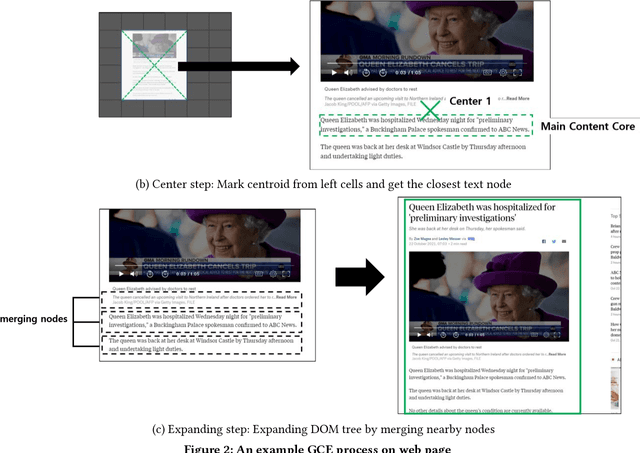
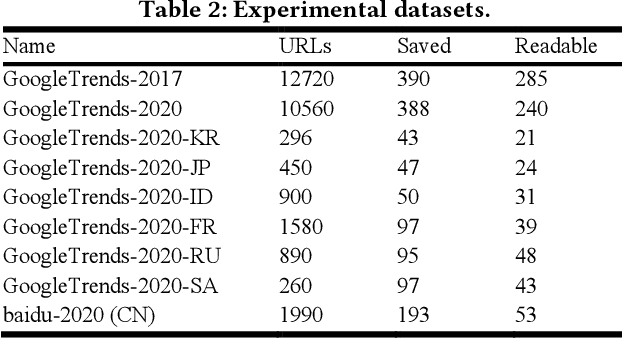
The extraction of main content provides only primary informative blocks by removing a web page's minor areas like navigation menu, ads, and site templates. It has various applications: information retrieval, search engine optimization, and browser reader mode. We tested the existing four main content extraction methods (Firefox Readability.js, Chrome DOM Distiller, Web2Text, and Boilernet) in web pages datasets of two English datasets from the global websites and seven non-English datasets from seven local regions each. It shows that the performance decreases by up to 40% in non-English datasets over English datasets. This paper proposes a multilingual main content extraction method that uses visually apparent features such as the elements' positions, size, and distances from the centers of the browser window and the web document. These are based on the authors' intention: the elements' placement and appearance in web pages have constraints because of humans' narrow central vision. Hence, our method, Grid-Center-Expand (GCE), finds the closest leaf node to the centroid of the web page from which minor areas have been removed. For the main content, the leaf node repeatedly ascends to the parent node of the DOM tree until this node fits one of the following conditions: <article> tag, containing specific attributes, or sudden width change. In the non-English datasets, our method performs better than up to 13% over Boilernet, especially 56% in the Japan dataset and 7% in the English dataset. Therefore, our method performs well regardless of the regional and linguistic characteristics of the web page. In addition, we create DNN models using Google's TabNet with GCE's features. The best of our models has similar performance to Boilernet and Web2text in all datasets. Accordingly, we show that these features can be useful to machine learning models for extracting main content.
Self-supervised Point Cloud Prediction Using 3D Spatio-temporal Convolutional Networks
Sep 28, 2021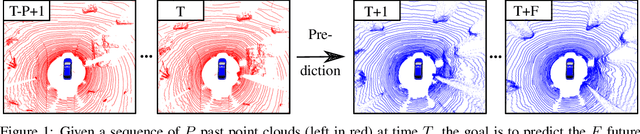
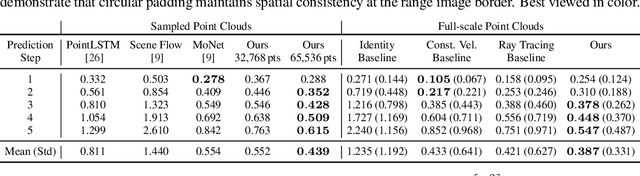
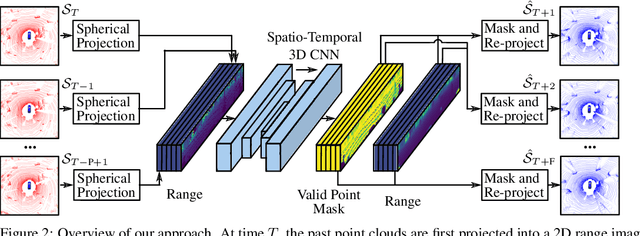
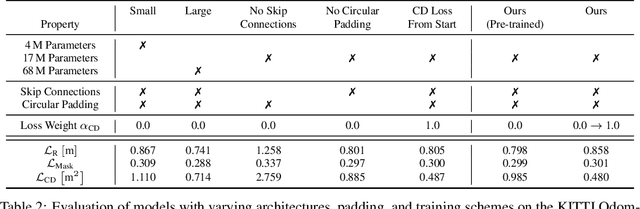
Exploiting past 3D LiDAR scans to predict future point clouds is a promising method for autonomous mobile systems to realize foresighted state estimation, collision avoidance, and planning. In this paper, we address the problem of predicting future 3D LiDAR point clouds given a sequence of past LiDAR scans. Estimating the future scene on the sensor level does not require any preceding steps as in localization or tracking systems and can be trained self-supervised. We propose an end-to-end approach that exploits a 2D range image representation of each 3D LiDAR scan and concatenates a sequence of range images to obtain a 3D tensor. Based on such tensors, we develop an encoder-decoder architecture using 3D convolutions to jointly aggregate spatial and temporal information of the scene and to predict the future 3D point clouds. We evaluate our method on multiple datasets and the experimental results suggest that our method outperforms existing point cloud prediction architectures and generalizes well to new, unseen environments without additional fine-tuning. Our method operates online and is faster than the common LiDAR frame rate of 10 Hz.
BERTChem-DDI : Improved Drug-Drug Interaction Prediction from text using Chemical Structure Information
Dec 21, 2020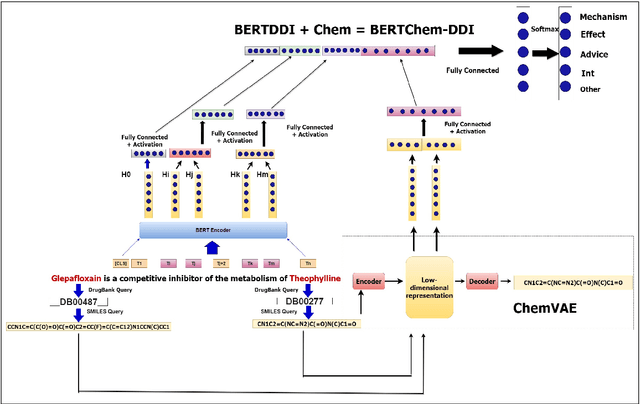
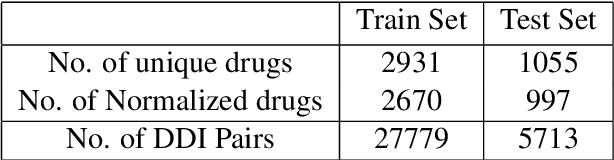


Traditional biomedical version of embeddings obtained from pre-trained language models have recently shown state-of-the-art results for relation extraction (RE) tasks in the medical domain. In this paper, we explore how to incorporate domain knowledge, available in the form of molecular structure of drugs, for predicting Drug-Drug Interaction from textual corpus. We propose a method, BERTChem-DDI, to efficiently combine drug embeddings obtained from the rich chemical structure of drugs along with off-the-shelf domain-specific BioBERT embedding-based RE architecture. Experiments conducted on the DDIExtraction 2013 corpus clearly indicate that this strategy improves other strong baselines architectures by 3.4\% macro F1-score.