 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based explanations for Gaussian Process regression and classification models
May 25, 2022
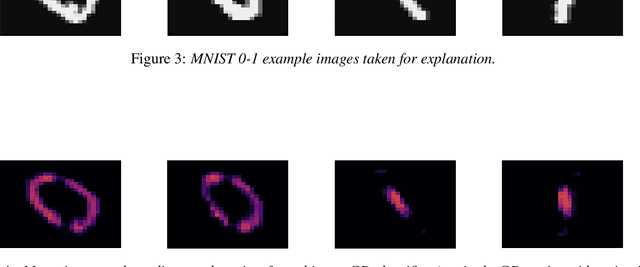
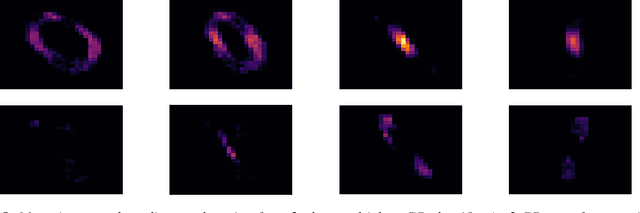
Gaussian Processes (GPs) have proven themselves as a reliable and effective method in probabilistic Machine Learning. Thanks to recent and current advances, modeling complex data with GPs is becoming more and more feasible. Thus, these types of models are, nowadays, an interesting alternative to Neural and Deep Learning methods, which are arguably the current state-of-the-art in Machine Learning. For the latter, we see an increasing interest in so-called explainable approaches - in essence methods that aim to make a Machine Learning model's decision process transparent to humans. Such methods are particularly needed when illogical or biased reasoning can lead to actual disadvantageous consequences for humans. Ideally, explainable Machine Learning should help detect such flaws in a model and aid a subsequent debugging process. One active line of research in Machine Learning explainability are gradient-based methods, which have been successfully applied to complex neural networks. Given that GPs are closed under differentiation, gradient-based explainability for GPs appears as a promising field of research. This paper is primarily focused on explaining GP classifiers via gradients where, contrary to GP regression, derivative GPs are not straightforward to obtain.
A piece-wise constant approximation for non-conjugate Gaussian Process models
Apr 22, 2022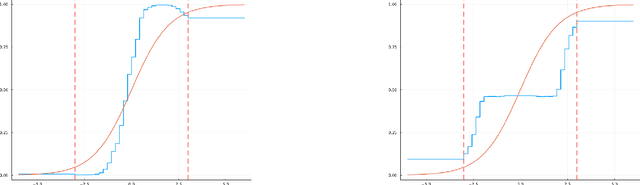

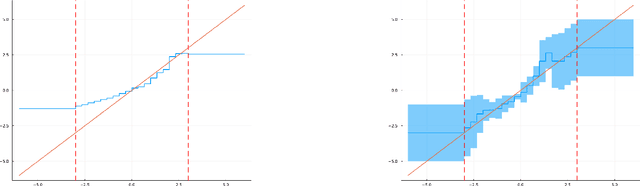
Gaussian Processes (GPs) are a versatile and popular method in Bayesian Machine Learning. A common modification are Sparse Variational Gaussian Processes (SVGPs) which are well suited to deal with large datasets. While GPs allow to elegantly deal with Gaussian-distributed target variables in closed form, their applicability can be extended to non-Gaussian data as well. These extensions are usually impossible to treat in closed form and hence require approximate solutions. This paper proposes to approximate the inverse-link function, which is necessary when working with non-Gaussian likelihoods, by a piece-wise constant function. It will be shown that this yields a closed form solution for the corresponding SVGP lower bound. In addition, it is demonstrated how the piece-wise constant function itself can be optimized, resulting in an inverse-link function that can be learnt from the data at hand.
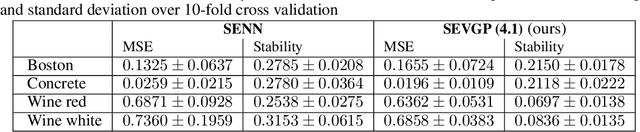
Self-explaining variational posterior distributions for Gaussian Process models
Sep 08, 2021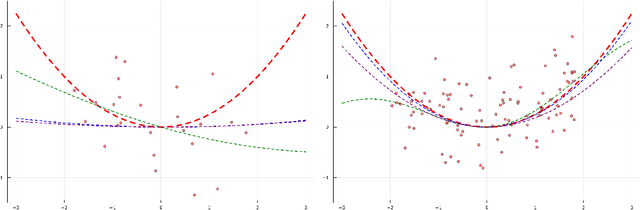
Bayesian methods have become a popular way to incorporate prior knowledge and a notion of uncertainty into machine learning models. At the same time, the complexity of modern machine learning makes it challenging to comprehend a model's reasoning process, let alone express specific prior assumptions in a rigorous manner. While primarily interested in the former issue, recent developments intransparent machine learning could also broaden the range of prior information that we can provide to complex Bayesian models. Inspired by the idea of self-explaining models, we introduce a corresponding concept for variational GaussianProcesses. On the one hand, our contribution improves transparency for these types of models. More importantly though, our proposed self-explaining variational posterior distribution allows to incorporate both general prior knowledge about a target function as a whole and prior knowledge about the contribution of individual features.
Mixtures of Gaussian Processes for regression under multiple prior distributions
Apr 19, 2021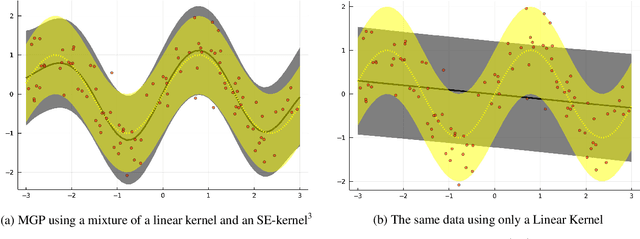
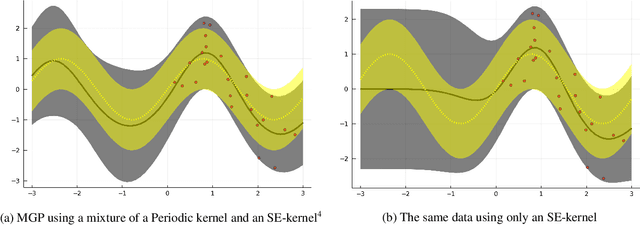
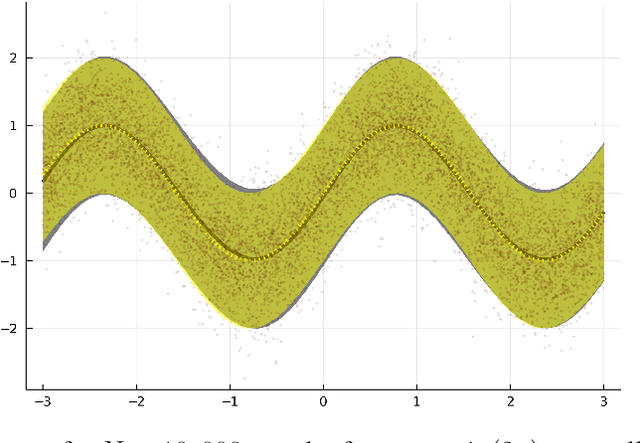
When constructing a Bayesian Machine Learning model, we might be faced with multiple different prior distributions and thus are required to properly consider them in a sensible manner in our model. While this situation is reasonably well explored for classical Bayesian Statistics, it appears useful to develop a corresponding method for complex Machine Learning problems. Given their underlying Bayesian framework and their widespread popularity, Gaussian Processes are a good candidate to tackle this task. We therefore extend the idea of Mixture models for Gaussian Process regression in order to work with multiple prior beliefs at once - both a analytical regression formula and a Sparse Variational approach are considered. In addition, we consider the usage of our approach to additionally account for the problem of prior misspecification in functional regression problems.