 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Set Similarity for Dense Self-supervised Representation Learning
Jul 19, 2021
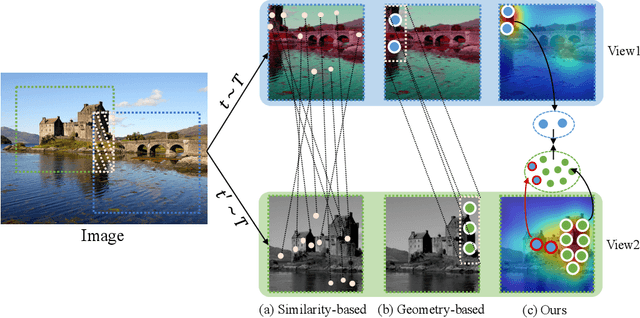
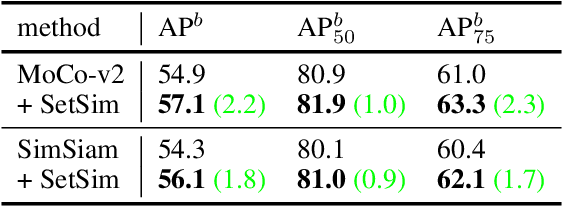
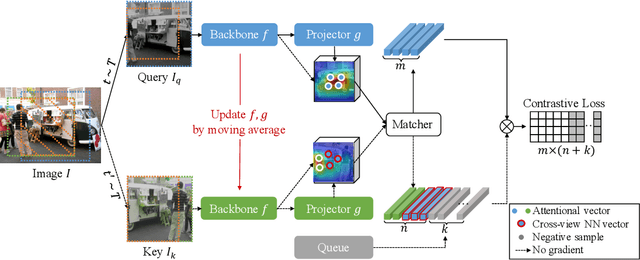
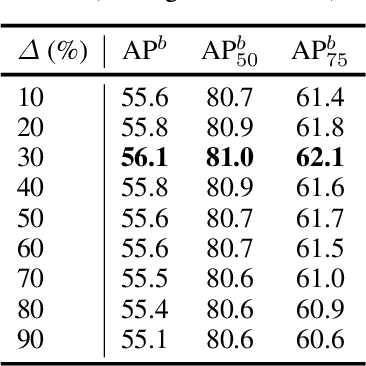
By considering the spatial correspondence, dense self-supervised representation learning has achieved superior performance on various dense prediction tasks. However, the pixel-level correspondence tends to be noisy because of many similar misleading pixels, e.g., backgrounds. To address this issue, in this paper, we propose to explore \textbf{set} \textbf{sim}ilarity (SetSim) for dense self-supervised representation learning. We generalize pixel-wise similarity learning to set-wise one to improve the robustness because sets contain more semantic and structure information. Specifically, by resorting to attentional features of views, we establish corresponding sets, thus filtering out noisy backgrounds that may cause incorrect correspondences. Meanwhile, these attentional features can keep the coherence of the same image across different views to alleviate semantic inconsistency. We further search the cross-view nearest neighbours of sets and employ the structured neighbourhood information to enhance the robustness. Empirical evaluations demonstrate that SetSim is superior to state-of-the-art methods on object detection, keypoint detection, instance segmentation, and semantic segmentation.
Chaining Mutual Information and Tightening Generalization Bounds
Jun 11, 2018
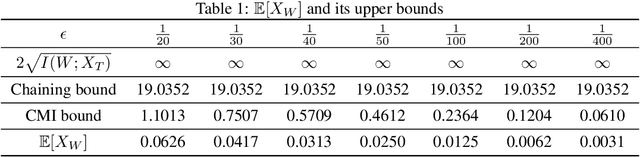
Bounding the generalization error of learning algorithms has a long history, that yet falls short in explaining various generalization successes including those of deep learning. Two important difficulties are (i) exploiting the dependencies between the hypotheses, (ii) exploiting the dependence between the algorithm's input and output. Progress on the first point was made with the chaining method, originating from the work of Kolmogorov and used in the VC-dimension bound. More recently, progress on the second point was made with the mutual information method by Russo and Zou '15. Yet, these two methods are currently disjoint. In this paper, we introduce a technique to combine chaining and mutual information methods, to obtain a generalization bound that is both algorithm-dependent and that exploits the dependencies between the hypotheses. We provide an example in which our bound significantly outperforms both the chaining and the mutual information bounds. As a corollary, we tighten Dudley inequality under the knowledge that a learning algorithm chooses its output from a small subset of hypotheses with high probability; an assumption motivated by the performance of SGD discussed in Zhang et al. '17.
Iterative Rule Extension for Logic Analysis of Data: an MILP-based heuristic to derive interpretable binary classification from large datasets
Oct 25, 2021
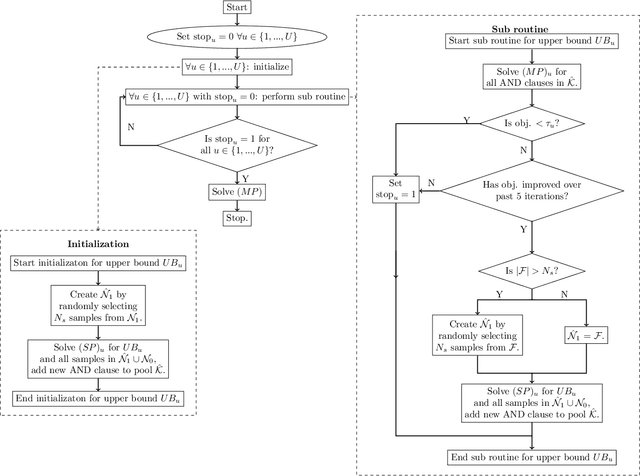
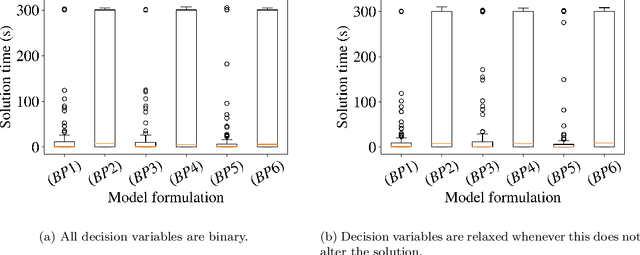
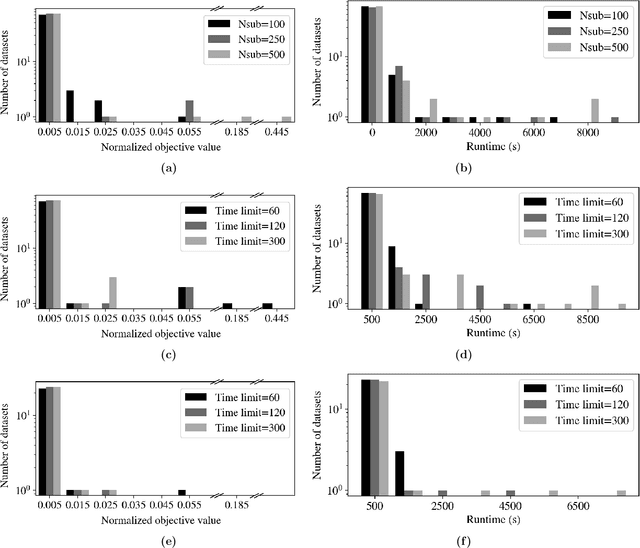
Data-driven decision making is rapidly gaining popularity, fueled by the ever-increasing amounts of available data and encouraged by the development of models that can identify beyond linear input-output relationships. Simultaneously the need for interpretable prediction- and classification methods is increasing, as this improves both our trust in these models and the amount of information we can abstract from data. An important aspect of this interpretability is to obtain insight in the sensitivity-specificity trade-off constituted by multiple plausible input-output relationships. These are often shown in a receiver operating characteristic (ROC) curve. These developments combined lead to the need for a method that can abstract complex yet interpretable input-output relationships from large data, i.e. data containing large numbers of samples and sample features. Boolean phrases in disjunctive normal form (DNF) are highly suitable for explaining non-linear input-output relationships in a comprehensible way. Mixed integer linear programming (MILP) can be used to abstract these Boolean phrases from binary data, though its computational complexity prohibits the analysis of large datasets. This work presents IRELAND, an algorithm that allows for abstracting Boolean phrases in DNF from data with up to 10,000 samples and sample characteristics. The results show that for large datasets IRELAND outperforms the current state-of-the-art and can find solutions for datasets where current models run out of memory or need excessive runtimes. Additionally, by construction IRELAND allows for an efficient computation of the sensitivity-specificity trade-off curve, allowing for further understanding of the underlying input-output relationship.
SWIPT with Intelligent Reflecting Surfaces under Spatial Correlation
Jun 09, 2021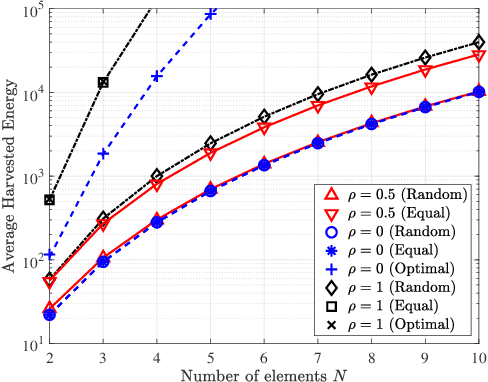
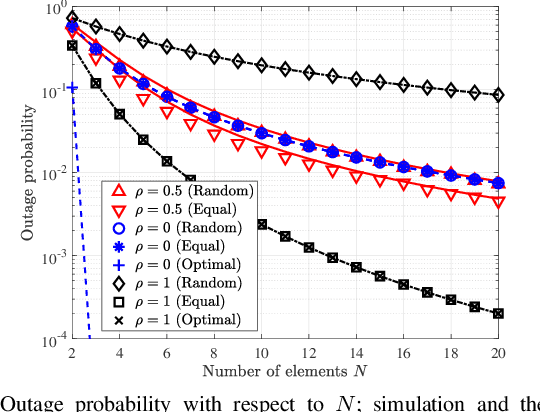
Intelligent reflecting surfaces (IRSs) can be beneficial to both information and energy transfer, due to the gains achieved by their multiple elements. In this work, we deal with the impact of spatial correlation between the IRS elements, in the context of simultaneous wireless information and power transfer. The performance is evaluated in terms of the average harvested energy and the outage probability for random and equal phase shifts. Closed-form analytical expressions for both metrics under spatial correlation are derived. Moreover, the optimal case is considered when the elements are uncorrelated and fully correlated. In the uncorrelated case, random and equal phase shifts provide the same performance. However, the performance of correlated elements attains significant gains when there are equal phase shifts. Finally, we show that correlation is always beneficial to energy transfer, whereas it is a degrading factor for information transfer under random and optimal configurations.
Context-Conditional Adaptation for Recognizing Unseen Classes in Unseen Domains
Jul 15, 2021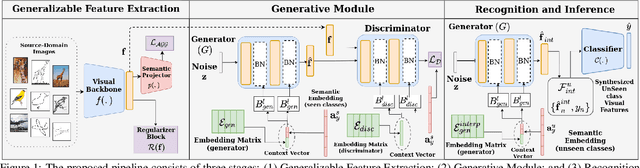
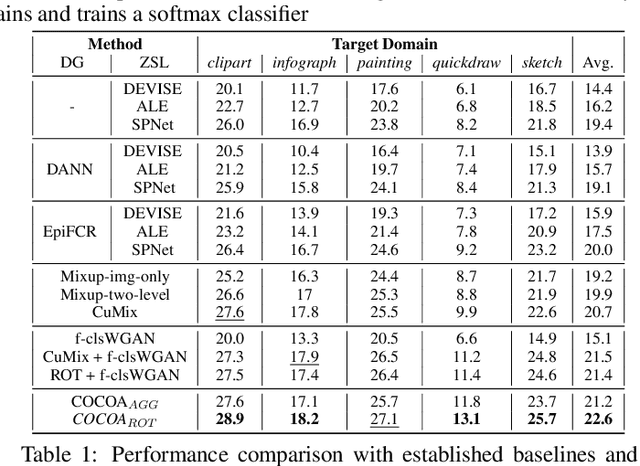
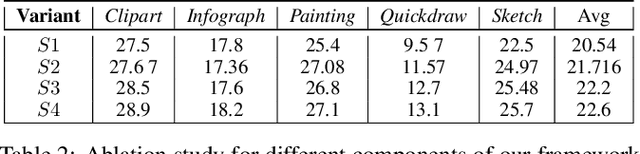
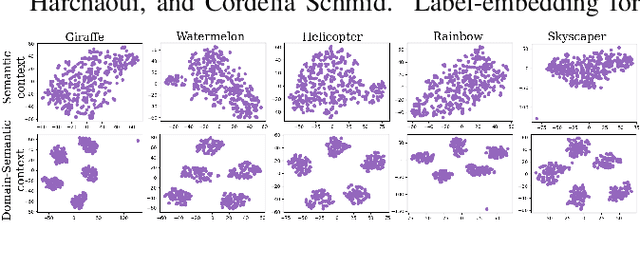
Recent progress towards designing models that can generalize to unseen domains (i.e domain generalization) or unseen classes (i.e zero-shot learning) has embarked interest towards building models that can tackle both domain-shift and semantic shift simultaneously (i.e zero-shot domain generalization). For models to generalize to unseen classes in unseen domains, it is crucial to learn feature representation that preserves class-level (domain-invariant) as well as domain-specific information. Motivated from the success of generative zero-shot approaches, we propose a feature generative framework integrated with a COntext COnditional Adaptive (COCOA) Batch-Normalization to seamlessly integrate class-level semantic and domain-specific information. The generated visual features better capture the underlying data distribution enabling us to generalize to unseen classes and domains at test-time. We thoroughly evaluate and analyse our approach on established large-scale benchmark - DomainNet and demonstrate promising performance over baselines and state-of-art methods.
Revealing unforeseen diagnostic image features with deep learning by detecting cardiovascular diseases from apical four-chamber ultrasounds
Oct 25, 2021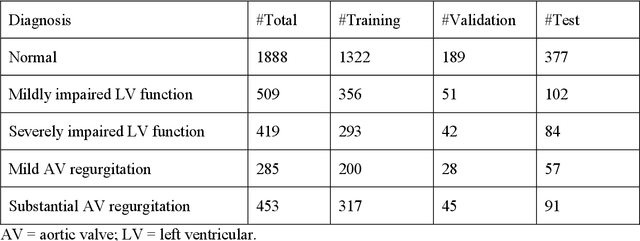
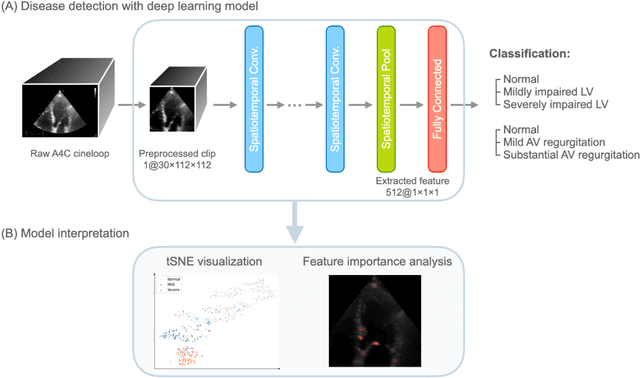
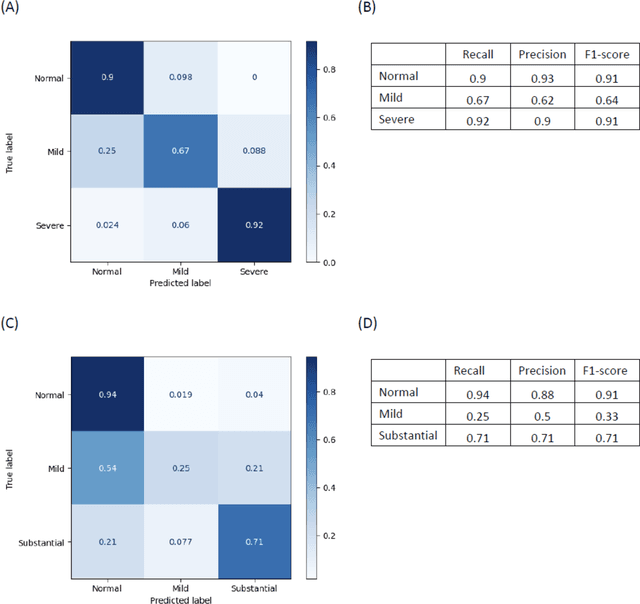
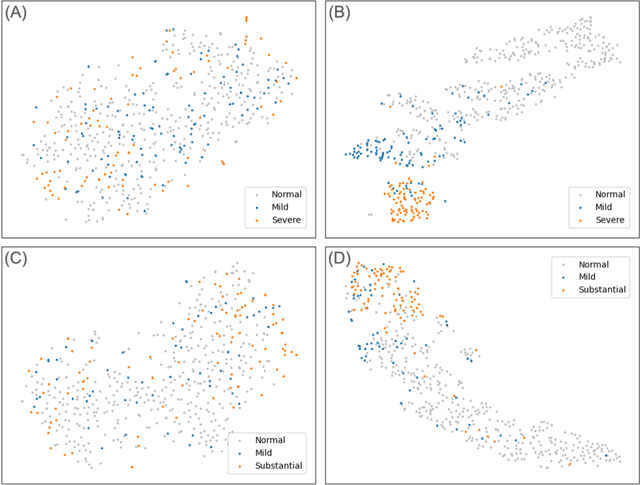
Background. With the rise of highly portable, wireless, and low-cost ultrasound devices and automatic ultrasound acquisition techniques, an automated interpretation method requiring only a limited set of views as input could make preliminary cardiovascular disease diagnoses more accessible. In this study, we developed a deep learning (DL) method for automated detection of impaired left ventricular (LV) function and aortic valve (AV) regurgitation from apical four-chamber (A4C) ultrasound cineloops and investigated which anatomical structures or temporal frames provided the most relevant information for the DL model to enable disease classification. Methods and Results. A4C ultrasounds were extracted from 3,554 echocardiograms of patients with either impaired LV function (n=928), AV regurgitation (n=738), or no significant abnormalities (n=1,888). Two convolutional neural networks (CNNs) were trained separately to classify the respective disease cases against normal cases. The overall classification accuracy of the impaired LV function detection model was 86%, and that of the AV regurgitation detection model was 83%. Feature importance analyses demonstrated that the LV myocardium and mitral valve were important for detecting impaired LV function, while the tip of the mitral valve anterior leaflet, during opening, was considered important for detecting AV regurgitation. Conclusion. The proposed method demonstrated the feasibility of a 3D CNN approach in detection of impaired LV function and AV regurgitation using A4C ultrasound cineloops. The current research shows that DL methods can exploit large training data to detect diseases in a different way than conventionally agreed upon methods, and potentially reveal unforeseen diagnostic image features.
Uplink Performance of Cell-Free Massive MIMO with Multi-Antenna Users Over Jointly-Correlated Rayleigh Fading Channels
Oct 11, 2021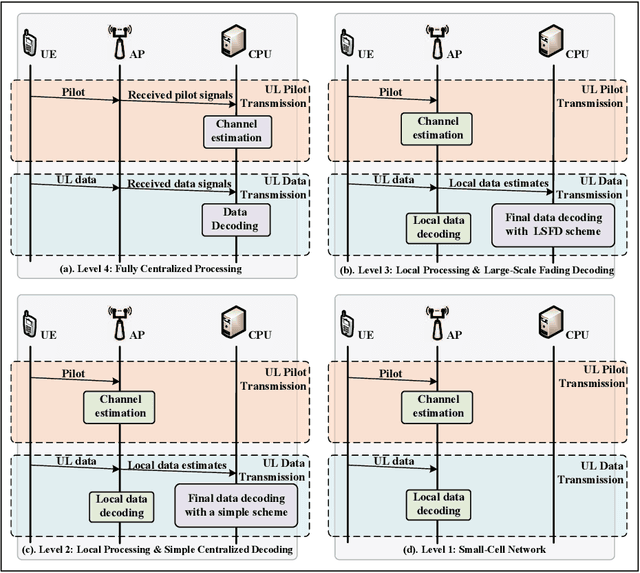
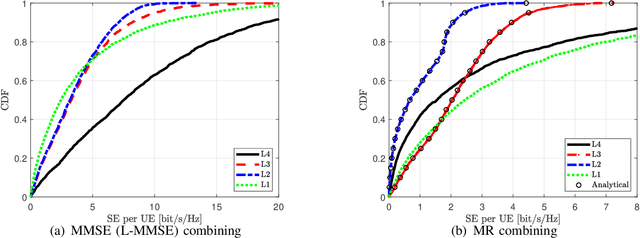
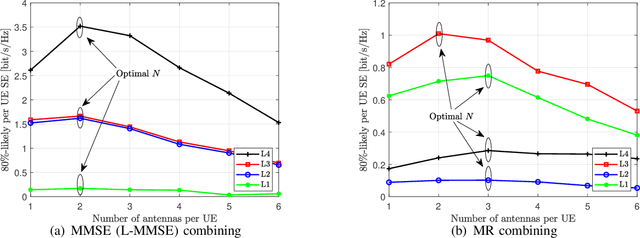
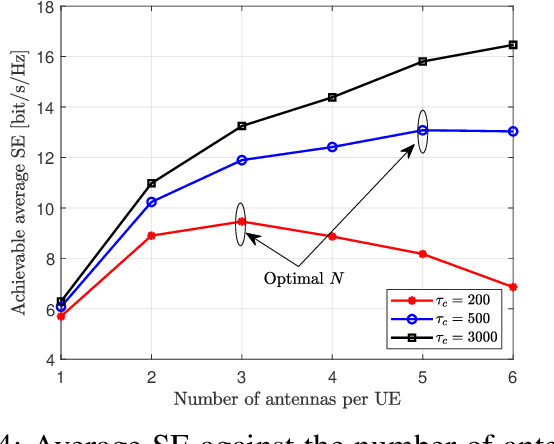
In this paper, we investigate a cell-free massive MIMO system with both access points (APs) and user equipments (UEs) equipped with multiple antennas over jointly correlated Rayleigh fading channels. We study four uplink implementations, from fully centralized processing to fully distributed processing, and derive achievable spectral efficiency (SE) expressions with minimum mean-squared error successive interference cancellation (MMSE-SIC) detectors and arbitrary combining schemes. Furthermore, the global and local MMSE combining schemes are derived based on full and local channel state information (CSI) obtained under pilot contamination, which can maximize the achievable SE for the fully centralized and distributed implementation, respectively. We study a two-layer decoding implementation with an arbitrary combining scheme in the first layer and optimal large-scale fading decoding in the second layer. Besides, we compute novel closed-form SE expressions for the two-layer decoding implementation with maximum ratio combining. We compare the SE of different implementation levels and combining schemes and investigate the effect of having additional UE antennas. Note that increasing the number of antennas per UE may degrade the SE performance and the optimal number of UE antennas maximizing the SE is related to the implementation levels, the length of the resource block, and the number of UEs.
Adaptive-Resolution Gaussian Process Mapping for Efficient UAV-based Terrain Monitoring
Sep 29, 2021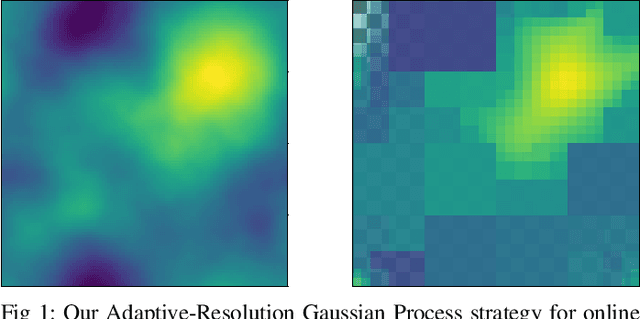
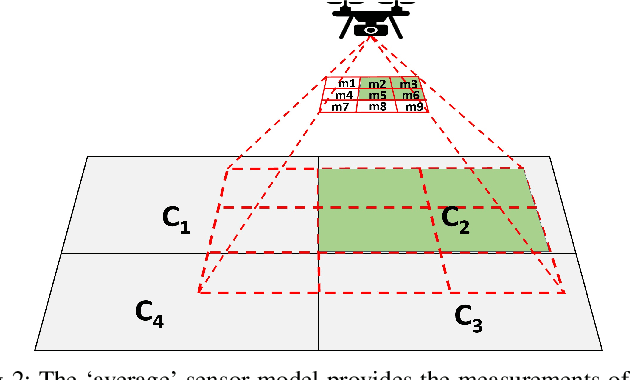
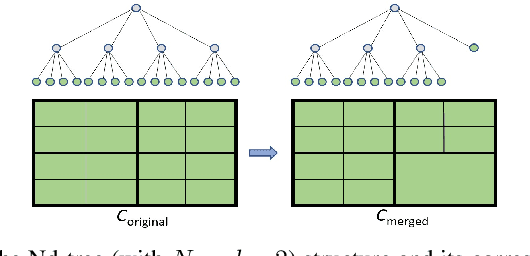
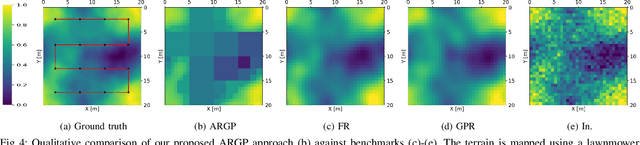
Unmanned aerial vehicles (UAVs) are rapidly gaining popularity in a variety of environmental monitoring tasks. A key requirement for autonomous operation is the ability to perform efficient environmental mapping and path planning online, given their limited on-board resources constraining operation time and computational capacity. To address this, we present an adaptive-resolution approach for terrain mapping based on the Nd-tree structure and Gaussian Processes (GPs). Our approach enables retaining details in areas of interest using higher map resolutions while compressing information in uninteresting areas at coarser resolutions to achieve a compact map representation of the environment. A key aspect of our approach is an integral kernel encoding spatial correlation of 2D grid cells, which enables merging uninteresting grid cells in a theoretically sound way. Results show that our approach is more efficient in terms of time and memory consumption without compromising on mapping quality. The resulting adaptive-resolution map accelerates the on-line adaptive path planning as well. Both performance enhancement in mapping and planning facilitate the efficiency of autonomous environmental monitoring with UAVs.
The Integrated Probabilistic Data Association Filter Adapted to Lie Groups
Aug 24, 2021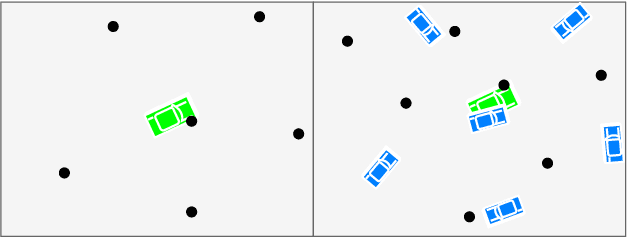
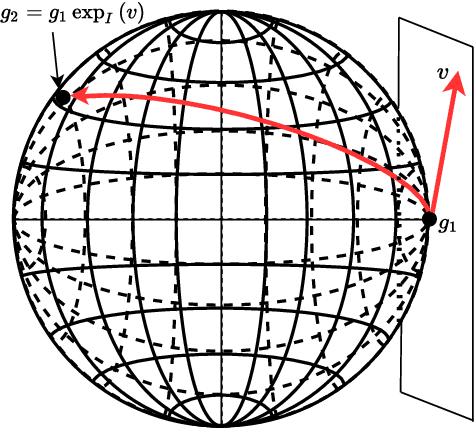
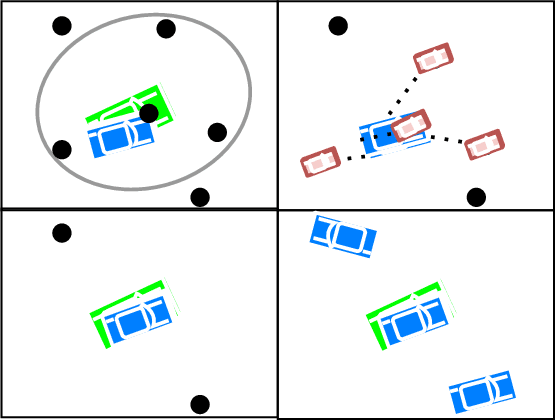
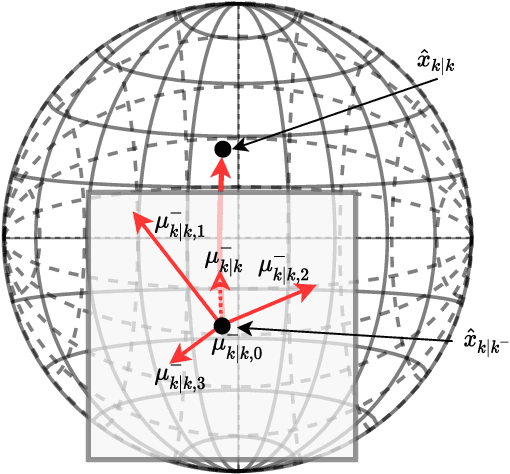
The Integrated Probabilistic Data Association Filter is a target tracking algorithm based on the Probabilistic Data Association Filter (PDAF) that calculates a statistical measure that indicates if a track should be rejected or confirmed to represent a target. The main contribution of this paper is to adapt the IPDA filter to target models that evolve on connected unimodular Lie groups, and where the measurements models also involve a Lie group. The paper contains a high level introduction to Lie groups, and then shows applications of the theory to tracking a car from an overhead UAV using camera information.
Learning Temporally-Consistent Representations for Data-Efficient Reinforcement Learning
Oct 11, 2021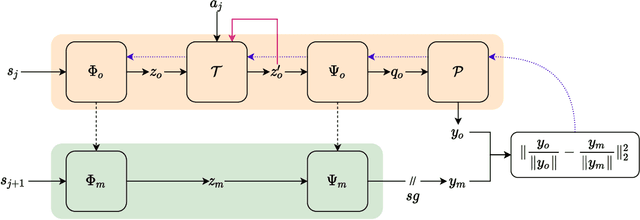
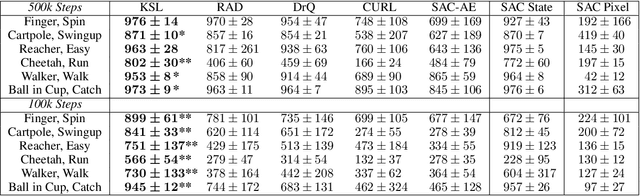
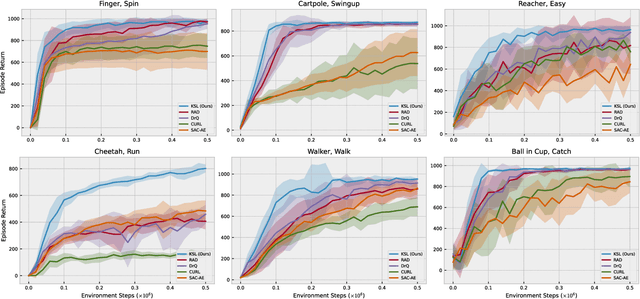
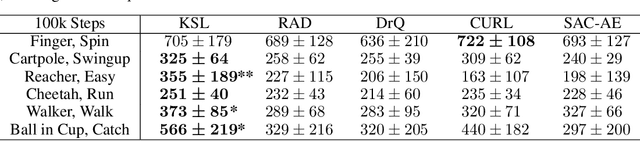
Deep reinforcement learning (RL) agents that exist in high-dimensional state spaces, such as those composed of images, have interconnected learning burdens. Agents must learn an action-selection policy that completes their given task, which requires them to learn a representation of the state space that discerns between useful and useless information. The reward function is the only supervised feedback that RL agents receive, which causes a representation learning bottleneck that can manifest in poor sample efficiency. We present $k$-Step Latent (KSL), a new representation learning method that enforces temporal consistency of representations via a self-supervised auxiliary task wherein agents learn to recurrently predict action-conditioned representations of the state space. The state encoder learned by KSL produces low-dimensional representations that make optimization of the RL task more sample efficient. Altogether, KSL produces state-of-the-art results in both data efficiency and asymptotic performance in the popular PlaNet benchmark suite. Our analyses show that KSL produces encoders that generalize better to new tasks unseen during training, and its representations are more strongly tied to reward, are more invariant to perturbations in the state space, and move more smoothly through the temporal axis of the RL problem than other methods such as DrQ, RAD, CURL, and SAC-AE.